
LUCIDA: 多要素戦略を使用して強力な暗号資産ポートフォリオを構築する方法 (データ前処理)
序文
前章に引き続き、公開しましたシリーズの最初の記事「多要素戦略を使用した強力な暗号資産ポートフォリオの構築」 - 理論的基礎, この記事は 2 番目の記事、データの前処理です。
因子データを計算する前/後、および単一因子の有効性をテストする前に、関連するデータを処理する必要があります。特定のデータの前処理には、重複値、外れ値/欠損値/極値の処理、標準化、およびデータ頻度が含まれます。
1. 値の重複
データ関連の定義:
キー: 一意のインデックスを表します。例: すべてのトークンとすべての日付を含むデータの場合、キーは「token_id/contract_address - date」です。
値: キーによってインデックス付けされたオブジェクトは「値」と呼ばれます。
重複値を診断するには、まずデータがどのように「あるべき」かを理解する必要があります。通常、データは次の形式になります。
時系列データ。鍵となるのは「時間」です。例: 単一トークンの 5 年間の価格データ
断面データ (Cross Section)。鍵となるのは「個」です。例:2023.11.01 その日の暗号通貨市場のすべてのトークンの価格データ
パネルデータ (パネル)。鍵となるのは「個と時間」の組み合わせだ。例: 2019.01.01 から 2023.11.01 までの 4 年間のすべてのトークンの価格データ。
原則: データのインデックス (キー) が決定されると、データのどのレベルで重複値があってはならないかを知ることができます。
確認方法:
pd.DataFrame.duplicated(subset=[key 1, key 2, ...])
重複する値の数を確認します: pd.DataFrame.duplicated(subset=[key 1, key 2, ...]).sum()
重複サンプルを確認するためのサンプリング: df[df.duplicated(subset=[...])].sample() サンプルを見つけた後、df.loc を使用してインデックスに対応するすべての重複サンプルを選択します。
pd.merge(df 1, df 2, on=[key 1, key 2, ...], indicator=True, validate='1: 1')
水平マージ関数では、インジケーター パラメーターを追加すると _merge フィールドが生成されます。マージ後のさまざまなソースからのサンプル数を確認するには、dfm[_merge].value_counts() を使用します。
validate パラメーターを追加すると、マージされたデータ セット内のインデックスが期待どおりであるかどうかを検証できます (1 対 1、1 対多、または多対多、最後のケースは実際には検証が必要ないことを意味します)。期待どおりにならない場合、マージ プロセスはエラーを報告し、実行を中止します。
2. 外れ値/欠損値/極値
外れ値の一般的な原因:
極端な場合。たとえば、トークンの価格が 0.000001 ドルである場合、またはトークンの市場価値が 500,000 ドルしかない場合、少し変動すると、数十倍のリターンが発生します。
データの特性。たとえば、トークン価格データのダウンロードが 2020 年 1 月 1 日に開始された場合、前日の終値がないため、2020 年 1 月 1 日のリターン データを計算することは当然不可能です。
データエラー。データプロバイダーは、トークンあたり 12 元をトークンあたり 1.2 元として記録するなど、間違いを犯すことは避けられません。
外れ値と欠損値を処理するための原則:
消去。合理的に修正または修正できない外れ値は、削除の対象となる場合があります。
交換する。通常は、ウィンゾライズや対数の取得などの極値を処理するために使用されます (一般的には使用されません)。
充填。のために欠損値合理的な方法で記入することも検討できます。一般的な方法としては次のようなものがあります。平均(または移動平均)、補間(Interpolation)、0を入力してくださいdf.fillna(0)、前方 df.fillna(ffill)/後方充填 df.fillna(bfill) など。充填が依存する前提が一貫しているかどうかを考慮する必要があります。
機械学習では、先読みバイアスのリスクがあるため、後方充填は注意して使用してください。
極端な値に対処する方法:
1. パーセンタイル法。
小さいものから大きいものへと順序を並べることにより、最小および最大の比率を超えるデータが重要なデータに置き換えられます。履歴データが豊富なデータの場合、この方法は比較的大雑把であまり適用できず、一定割合のデータを強制的に削除すると一定割合の損失が発生する可能性があります。
2.3σ/3標準偏差法

データ範囲内のすべての要素に対して次の調整を行います。
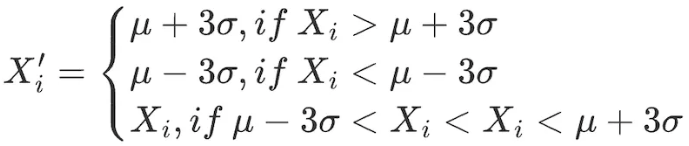
この方法の欠点は、株価やトークン価格などの定量分野で一般的に使用されるデータが、正規分布の仮定に従わない、ピークと裾の太い分布を示すことが多いことです。 3 σ 法では、大量のデータが誤って異常値として識別されます。
3. 中央値絶対偏差 (MAD) 法
この方法は中央値と絶対偏差に基づいており、処理されたデータは極値や外れ値の影響を受けにくくなります。平均偏差と標準偏差に基づく方法よりも堅牢です。
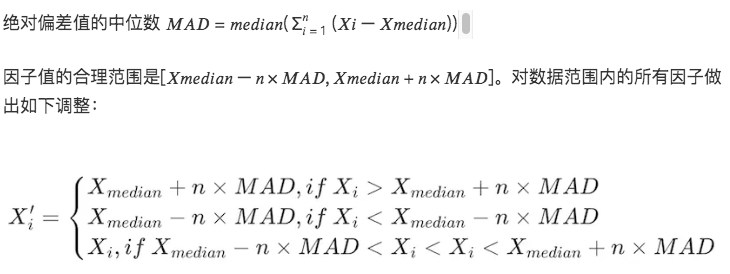
# 因子データの極端な値の状況を処理する
class Extreme(object):
def __init__(s, ini_data):
s.ini_data = ini_data
def three_sigma(s, n= 3):
mean = s.ini_data.mean()
std = s.ini_data.std()
low = mean - n*std
high = mean + n*std
return np.clip(s.ini_data, low, high)
def mad(s, n= 3):
median = s.ini_data.median()
mad_median = abs(s.ini_data - median).median()
high = median + n * mad_median
low = median - n * mad_median
return np.clip(s.ini_data, low, high)
def quantile(s, l = 0.025, h = 0.975):
low = s.ini_data.quantile(l)
high = s.ini_data.quantile(h)
return np.clip(s.ini_data, low, high)
3. 標準化
1.Zスコアの標準化

2. 最大値と最小値の差の標準化(Min-Max Scaling)
各因子データを(0,1)区間のデータに変換し、サイズや範囲の異なるデータを比較できますが、データ内の分布は変化せず、合計が1になることはありません。
最大値と最小値を考慮するため、外れ値に敏感です
ディメンションを統一すると、異なるディメンションのデータの比較が容易になります。
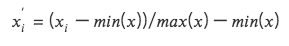
3. ランクスケーリング
データの特徴をランキングに変換し、これらのランキングを 0 から 1 までのスコア (通常はデータ セット内のパーセンタイル) に変換します。 *
この方法は、ランキングが外れ値の影響を受けないため、外れ値の影響を受けません。
データ内のポイント間の絶対的な距離は維持されず、相対的なランキングに変換されます。
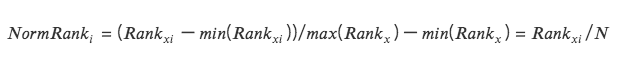
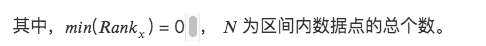
# 標準化された因子データクラス Scale(object):
def __init__(s, ini_data, date):
s.ini_data = ini_data
s.date = date
def zscore(s):
mean = s.ini_data.mean()
std = s.ini_data.std()
return s.ini_data.sub(mean).div(std)
def maxmin(s):
min = s.ini_data.min()
max = s.ini_data.max()
return s.ini_data.sub(min).div(max - min)
def normRank(s):
# 指定された列をランク付けします。method=min は、同じ値が平均順位ではなく同じ順位になることを意味します。
ranks = s.ini_data.rank(method='min')
return ranks.div(ranks.max())
4. データ頻度
場合によっては、取得されたデータが分析に必要な頻度ではないことがあります。たとえば、分析のレベルが月次で、元のデータの頻度が日次の場合は、「ダウンサンプリング」を使用する必要があります。つまり、集計されたデータは月次です。
ダウンサンプリング
参照コレクション内のデータを 1 行のデータに集約しますたとえば、日次データは月次データに集計されます。このとき、各集計指標の特性を考慮する必要があり、一般的な操作は次のとおりです。
最初の値/最後の値
平均/中央値
標準偏差
アップサンプリング
月次分析に使用される年次データなど、1 行のデータを複数行のデータに分割することを指します。通常、この状況では単純な繰り返しが必要ですが、場合によっては、年次データを比例して各月に集計する必要があります。


