
浅析Pyth Network白皮书:参与者交互方式、HUMAN协议和参与者激励
原文作者:Pyth Chinese
原文来源:Medium

2022 年 1 月 18 日,Pyth Network 白皮书正式发布。随着白皮书的发布,我们将为 Pythian 们提供一个白皮书的摘要总结。
DeFi 项目的快速成长需要依赖直接从数据源头获取的高保真的、时间敏感的、真实世界的数据,并让这些数据可以在任何 L1 区块链上使用。然而,金融市场的数据通常只有有限的机构和用户才可以访问。传统市场通常对实时以及历史的价格信息数据保持严格的控制权和获取资格。因此,只有被选定的部分用户才能获得最及时、准确和有价值的信息。
Pyth Network 是下一代的预言机解决方案,旨在将有价值的金融市场数据提供给大众。Pyth Network 通过激励市场参与者 — — 交易机构、造市商和交易所 — — 来让他们共享日常运营中收集到的现有的价格数据。Pyth 聚合第一方价格数据并将数据上链,让这些数据可用于链上或链外的应用程序。
Pyth 数据的终端用户(End-users)可以选择支付数据使用费用(data fees),来保护他们免受预言机可能出现的故障造成的损失。委托人(Delegators)通过选择支持哪个产品(价格数据)以及特定的数据发布者,以赚取数据使用费(如果由于数据提供者的错误导致数据不准确,委托人将损失质押的通证)。
这个激励系统通过 Pyth Network 参与者质押 PYTH 通证、自愿向数据发布者支付数据使用费用来运转。这样设计的目的是使 Pyth Network 能够自我完成持续闭环和去中心化。
网络参与者
在 Pyth 网络中,3 类不同的利益相关方将会交互:
数据发布者(Publishers):发布价格数据来赚取部分数据使用费。数据发布者通常是市场参与者,能够获得准确、及时的价格信息。Pyth 协议根据数据发布者提供的新价格信息的数量对其进行奖励。
数据使用者(Consumers):读取价格数据,将数据融入到智能合约或去中心化应用中,并选择自愿支付数据使用费用。数据使用者既可以是链上协议,也可以是链外应用。
委托人(Delegators):将通证质押在特定的价格产品和数据发布者上,来获得部分数据使用费用。如果预言机发布数据不准确,委托人可能会失去他们质押的通证。
任何参与者都可以在网络中拥有多个角色。例如,数据发布者(或使用者)可能会决定同时成为委托人,质押通证以赚取额外的数据使用费用。
参与者如何在 Pyth 中进行交互?
Pyth 协议包含 4 种核心的链上机制:
价格聚合机制(Price aggregation):将单个数据发布者报告的价格和置信区间合并成一个单一的价格数据和一个特定产品的置信区间数据(例如 BTC/USD 价格数据)。这一机制旨在输出稳健的价格数据 — — 使这些价格数据不会受到少部分价格发布者的显著影响。
数据质押机制(Data staking):允许委托人(delegator)质押通证以赚取数据使用费用。总体上,委托人还通过其质押在特定数据发布者上的通证权重决定了每个发布者对聚合价格的影响水平。此外,这一机制同时也决定了委托人质押的通证是否会被惩罚削减。最后,这个机制从数据使用者那里收集数据使用费用,并将部分分配给委托人(最初设置为80%)。剩下的 20% 将进入奖励池,分配给数据发布者。
奖励分配机制(Reward distribution):决定了每个数据发布者所获得的奖励份额。每个价格产品都有一个委托人可以质押通证的奖励池。奖励分配机制优先向那些提供高质量的价格数据的发布者提供奖励,从而降低了信息不完善的数据发布者获得奖励的可能性。
治理机制(Governance):将使用通证投票系统来帮助决定上述三种机制的高级参数。参数包括哪些类型的通证可用于支付数据使用费用;哪些价格产品在 Pyth 中上线;分配给数据发布者、委托人和其他用途的数据使用费用份额;数据发布者必须质押的 PYTH 通证额度或支持针对价格产品提出索赔的 PYTH 通证的数量等等。
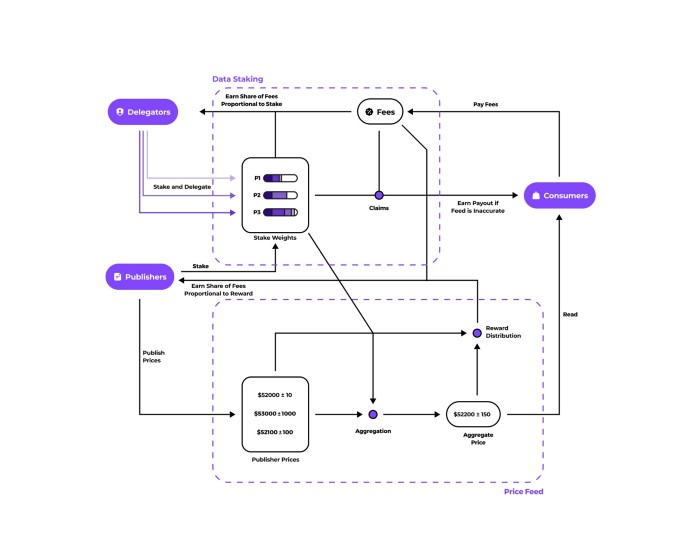
描述参与者(紫色椭圆)及其与各种机制(紫色圆圈)的交互的 Pyth 协议概述
索赔过程:HUMAN 协议
人们应该能够预料到,有时 Pyth Network 必须验证和解决链上聚合的市场价格与真实世界参考价格之间的明显不一致问题,与真实世界的参考价格相比,这些价格可能被认为是错误的。
一个看起来很明显但又很微妙的问题是:当一个数据发布者(或一系列数据发布者)给出一个异常值,然后生成一个数据使用者认为是错误的聚合价格时,Pyth Network 必须确定是否将会向那些质押通证来对冲风险终端用户协议支付赔偿。如果聚合价格被认为是错误的,那么错误的发布者就会被识别出来,他们所质押的通证就会被削减,并支付给终端用户。
总的来说,索赔的过程将决定是否发生赔偿。这个过程的目的是验证一个产品的聚合价格和置信区间与一些真实的链外数据相比是不正确的。这一过程将使用 HUMAN 协议 — — 这是一个由 Pyth 提供的开源软件包 — — 从公正的法官那里收集必要的链外信息,然后将这些信息输入确定索赔结果的预定算法中。最后,PYTH 通证持有者将投票批准算法的输出,如果索赔被确认,支付过程将会被触发。
任何人都可以针对协议提出索赔(可能的)来触发支付(通过绑定在成功批准的索赔后返回的 PYTH 通证;这个要求是用来可防止垃圾邮件攻击的)。
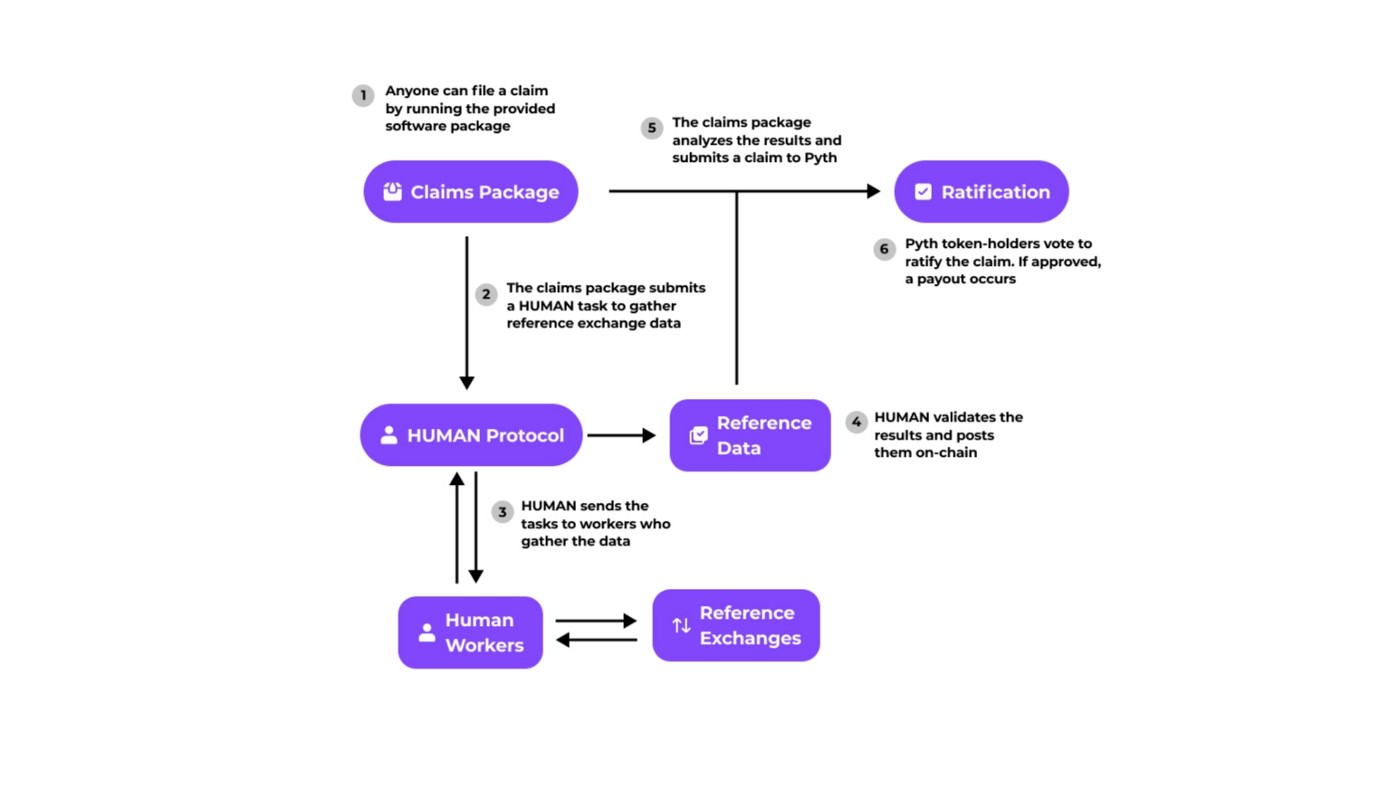
索赔过程的流程图
参与者激励
这个模块总结了 Pyth Network 给到利益相关方的激励方式:
数据发布者被激励质押 PYTH 通证来参与到协议中,并获得部分奖励。数据发布者从他们定价的产品中获得一定份额的数据使用费。产品的数据使用费用可能会随着价格使用者对价格数据的使用而增长。将错误数据(无论出于故意与否)发布到网络上可能会导致数据发布者的质押通证被削减。
数据使用者基于两个原因愿意支付数据使用费。首先,支付数据使用费使应用程序能够减少使用 Pyth 价格数据的风险,因为一旦数据出现错误,它们将获得一笔补偿款。其次,支付数据使用费用会吸引更多的数据发布者提供价格数据,这提高了价格数据的稳定性。
委托人被激励参与协议来赚取数据费用(来自数据使用者支付的数据使用费用)。委托人最初会获得一个有吸引力的报酬,但随着市场变得更有效率,委托人之间的竞争会逐渐减少其获得的报酬。
DeFi 的未来是光明的。为了让这一领域蓬勃发展,我们需要一个真正去中心化的预言机解决方案,以亚秒级的时间尺度将真实世界的数据带到链上(以前无论是链上还是链外数据都无法实现)。Pyth Network 是直接从数据源发送数据,而不需要中间商或中介。这就是数据发布者网络(publisher network)相较于记者(reporter network)网络的意义所在。
一个链上构建的预言机,可以向全世界提供更完整、更快、更有信心的数据。这就是选择使用 Pyth 数据构建程序的原因。
如果你正在构建一个 DeFi 项目,或者对去中心化金融的未来感到兴奋,请阅读我们的白皮书,访问我们的网站或文档了解更多细节,并在 Discord 或 Twitter 上加入我们,向我们提供反馈。


