




原文来源:阿法兔研究笔记

Cloudflare是一家于2019年上市的CDN和安全服务公司,不过2022年6月21日(周二)因为它的服务暂时中断,影响了大量的服务和平台正常运营。包括FTX,Discord,Omegle,DoorDash等等。
本篇文章,会讲一下什么是CloudFlare,到底是个什么公司,CloudFlare和Web3的缘起,以及从技术上解释一下本次故障的原因。
本文结构
1.事件背景
2022年6月底(本周二)发生了什么?
2.什么是CDN(内容分发网络)
什么是CDN
什么是路由
CDN公司通常都是安全公司?
3.Cloudflare是个什么公司?
4.Cloudflare和Web3的缘起
IPFS以太坊
5.Cloudflare为什么会发生服务中断?(技术分析部分)
和架构转型有关
本次服务终端的时间线和背景
补救和后续步骤
结论
事件背景
6月21日(周二)发生了一件事,就是因为Cloudflare的服务暂时中断,影响了大量的服务和平台正常运营。包括FTX,Discord,Omegle,DoorDash,Crunchyroll,NordVPN和Feedly等等、还有Zeroda,Medium.com,新闻媒体Register,Groww,Buffer,iSpirt,Upstox和Social Blade的,用户无法访问这些网站,甚至Coinbase,Shopify和英雄联盟也受到了部分影响。
本篇文章,会讲一下什么是CloudFlare,到底是个什么公司,CloudFlare和Web3的缘起,以及从技术上解释一下本次故障的原因。
什么是CDN(内容分发网络)
在讲Cloudflare之前,我们先普及一个概念(CDN)
什么是CDN?
CDN,全称为Content Distribute Network(内容分发网络 )或者Content Delivery Network;那么,什么是内容分发网络呢?是可以通过互联网互相连接的电脑网络系统,利用最近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。
形象的说,CDN有点类似于京东物流模式,通过在全国各地建立物流点(缓存服务器),当有人从京东购买货物时(用户资源请求),京东上次可以根据用户的收货地址(CDN进行用户域名解析)找最近的或者最快的一个物流点进行派送(将访问用户连接到最近的缓存服务器进行资源传输)。
CDN服务可用于确保快速可靠地分发静态内容,这些内容可以缓存,最适合在网速庞大的网络中存储和分发,这样就能把主干网络通道空出来给必须实时传输的动态内容,比如网络直播,降低时延。
我们举个例子,比如有一家英国公司,主要客户也在英国,如果给这家公司建立网站,那么,通常会把网站服务器放在英国。但是,会存在延迟这样的情况,影响用户们的网站访问体验,不过,如果延迟是由于网络阻塞导致的,那么这种延迟是可以改善的。具体怎么改善呢?
主要是通过提高点到点之间的带宽、优化网络路由来解决这些问题。举个例子,比如从伦敦到牛津,增加这两地之间光纤的数量,就是最容易的提高带宽方法。
注意,这里光纤数量主要是我们建设基础设施如海底光缆、铁路和高速公路的时候,同时铺设的。因此,这些年我们用的带宽一直在增加,你可以把增加网络贷款理解为拓宽交通公路,就是个花钱铺设的事情。
路由
我们前面提到过网络路由,路由是啥呢?其实路由解决的主要问题,就是两点之间的通信,究竟走什么线路的问题。举个例子,一旦伦敦到牛津的出现网络堵塞,系统还可以选择其他路由。有点像智慧交通,互联网的路由优化也类似。所以这些年,尽管流量越来越大,但是网络性能也是一直在改善的。
通俗一点讲,就是给网站加速,部分网站由于原因使得打开变得极为缓慢,这就需要用CDN来进行加速。
CDN也是一类较为先进网络技术,解决内容在互联网上的分发问题。什么是内容分发网络呢?这与交通网络类似,也就是说,再快的飞机,也是有速度上限的,距离越远,延迟越长。网络也一样,如果距离远,就会出现网络延迟的情况。
所以如果某个欧洲用户想要访问美国网站的内容,CDN就是在欧洲建立一个服务器,把美国的内容翻译到这个服务器。当欧洲用户进入域名访问时,由于CDN运营商知道这个用户访问来自欧洲系统,就把欧洲服务器的IP地址给这个用户,用户自然就访问到欧洲的服务器了。
CDN公司通常都是安全公司?
属于CDN一个重要特点,是CDN天生具备安全属性,因为cdn对哪些人在访问用户的网络非常清楚,因此,可以帮助客户阻挡网站攻击。网络安全是cdn公司的一项增值服务,尽管cdn的出现,远远早于云计算,但是目前大家已经把cdn归类成云计算,原因是用户通常会根据使用量,来对cdn服务进行按月付费和按照流量付费,这其实属于典型的云计算订阅模式,同时cdn的服务器也不一定就是传统的物理服务器,这些服务器可能也是来自公有云运营商的虚拟机,所以现在你完全可以把CDN看成一个云计算的IaaS服务。
注:本部分关于CDN的解释内容,部分来自于Youtube博主老科谈科技股
Cloudflare是个什么公司?
2010年,Cloudflare正式创立,总部位于美国旧金山。是一家以其 CDN 和安全服务为主营业务的公司,Cloudflare公司的主营业务是向客户提供基于反向代理的内容分发网络及分布式域名解析服务(Distributed Domain Name Server)。从2009年开始,该公司由Union Square Ventures等风险投资参投,百度也参与了Cloudflare的D轮融资,2019年8月15日,Cloudflare正式IPO。
除此之外,Cloudflare收购了一系列网络服务和安全公司,2014年收购StopTheHacker 、CryptoSeal;2016年收购Eager Platform Co.;17年及以后收购Neumob、S2 Systems、Linc、Zaraz;今年收购了Vectrix和Area 1 Security.
Cloudflare和Web3的缘起
Cloudflare是比较早就开始支持Web3开发的CDN公司,它的官网是这么说的:Cloudflare是用户通往Web3的门户,通过Cloudflare,可以轻松访问IPFS和Ethereum网络。并且,官网提到,Web 1.0让世界有了快速传播信息的能力,而Web 2.0则让这些信息具有互动性。Web 3.0,或Web3,被认为是互联网的下一次迭代,建立在IPFS和以太坊等去中心化的技术之上。

图片来自Cloudflare官网
Cloudflare具备 IPFS Gateway,客户可以在继续使用HTTP协议的时候,同时享受IPFS的好处。

Cloudflare以太坊网关允许客户使用自己的域,可以通过 HTTP 的 JSON RPC 查询发送到自定义域名。Cloudflare可以管理、维护和监控Web3基础设施,构建者可以专注于重要的事情:构建Dapp。Cloudflare可以通过行业内领先的全球网络,创建基于Web3技术的安全、可靠和快速服务。
Cloudflare为什么会发生服务中断?
2022年6月21日的Cloudflare服务中断事件的官方解释:
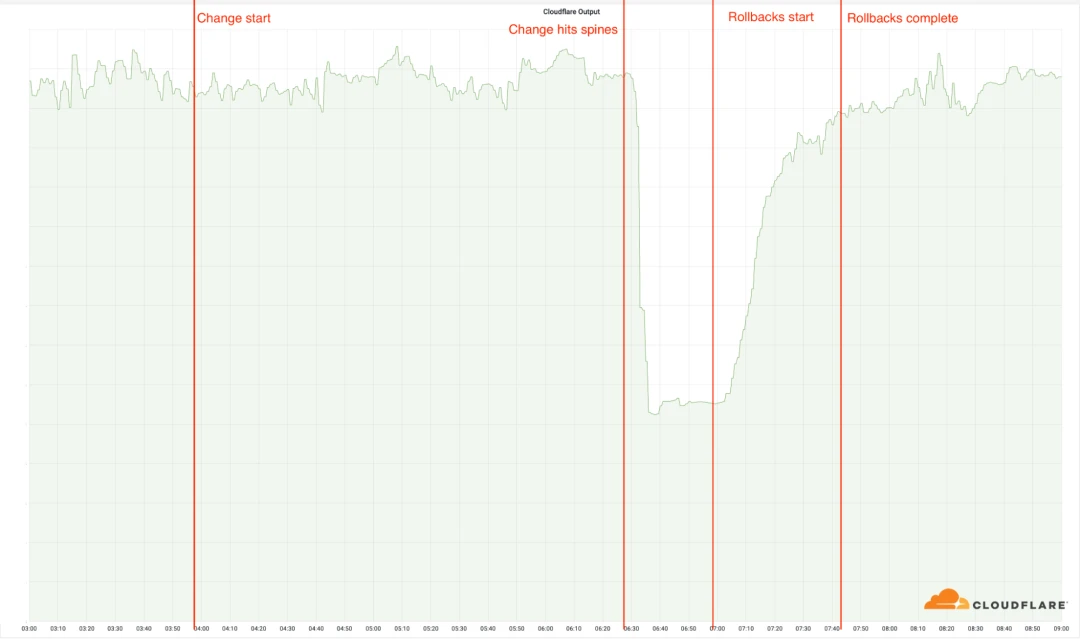
2022 年 6 月 21 日,Cloudflare 服务中断,影响了 19 个数据中心的正常运行,而不幸的是,这19个地点处理了Cloudflare很大一部分全球数据。这次服务中断是由一个长期运行项目出现的问题引起的,这个项目主要是想提高最繁忙数据中心的弹性而发起的。是因为,更改了部分位置的网络配置,而导致服务中断,中断的具体时间是从UTC 时间 06:27 开始,到了 06:58 UTC,第一个数据中心重新开始工作,到 07:42 UTC,所有数据中心都可以正常工作。根据用户在世界上的不同位置,可能无法访问依赖 Cloudflare为基础设施的网站和服务,不过在其他没有受影响的地点,Cloudflare继续正常运行。
对此次中断,Cloudflare 深表歉意,这是Cloudflare 的错误,而不是因为攻击或其他恶意活动的。
本次架构转型的背景
在过去 18 个月,Cloudflare 一直致力于将所有最繁忙的数据中心的架构转型,让它们更为灵活、且更具弹性。目前,已经有19个数据中心,成功转换为此架构,Cloudflare内部称其为Multi-Colo PoP(MCP);这19个数据中心分别位于:阿姆斯特丹,亚特兰大,阿什本,芝加哥,法兰克福,伦敦,洛杉矶,马德里,曼彻斯特,迈阿密,米兰,孟买,纽瓦克,大阪,圣保罗,圣何塞,新加坡,悉尼和东京。
这个新架构被设计成Clos网络,它的一个关键部分是增加了一个额外的路由层(见下图),创造了一个网状的连接。这个网状结构使我们能够轻松地禁用和启用数据中心的部分内部网络,以便进行维护或处理问题。这一层由下图中标识为的Spine部分表示。
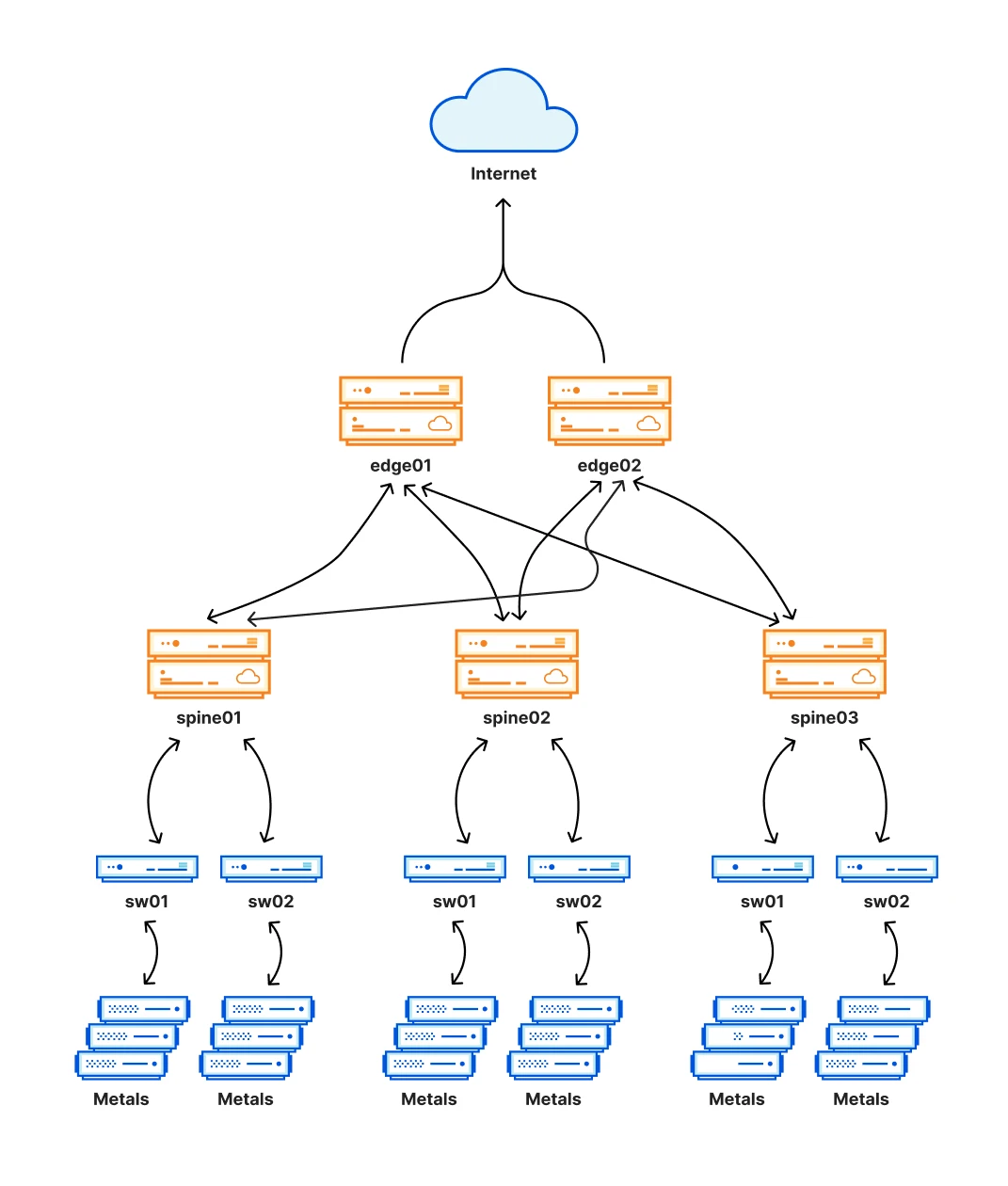
注:Clos network是一种多级交换网络,由Charles Clos于1953年首次正式使用该术语,它代表了实际多级电话交换系统的理想化表示。当物理电路交换的需求超过了单crossbar switch的最大可实现容量的时候需要使用Clos network。Clos network的主要优势点在于:所需的交叉点数量远小于整个交换系统使用一个大的Crossbar Switch来实现所需的交叉点数量。
这种新的架构显著改善了Cloudflare的可靠性,可以使Cloudflare能够在这些地方进行维护,并且不中断客户流量。不过,由于这些地点同时也承载着Cloudflare流量的很大部分,任何这里的问题都会产生非常广泛的影响,不幸的是,这就是6月21日Cloudflare服务终端的原因所在。
服务中断的时间线和影响
Cloudflare应用了名为BGP的协议(边界网关协议,Border Gateway Protocol,是运行于 TCP 上的一种自治系统的路由协议 )。该协议的由运营商定义政策,决定有哪些前缀(相邻IP地址的集合)会被广播给对等的节点(他们连接的其他网络)。这些策略有单独的组成部分,按顺序进行评估。最终的结果是,任何给定的前缀要么被广播,要么不被广播。政策的变化可能意味着以前会广播的前缀不再被广播,被称为 撤销,这些IP地址将不再能在互联网上正常运行。
运营商制定了某种策略,决定某些路由前缀可以被广播(这里的广播指的是,路由可以被其他边缘bgp路由器学习到,进而其他的bgp网络知道这些路由变化,前缀就是prefix,是用来唯一地标识着连入Internet的一个网络号)
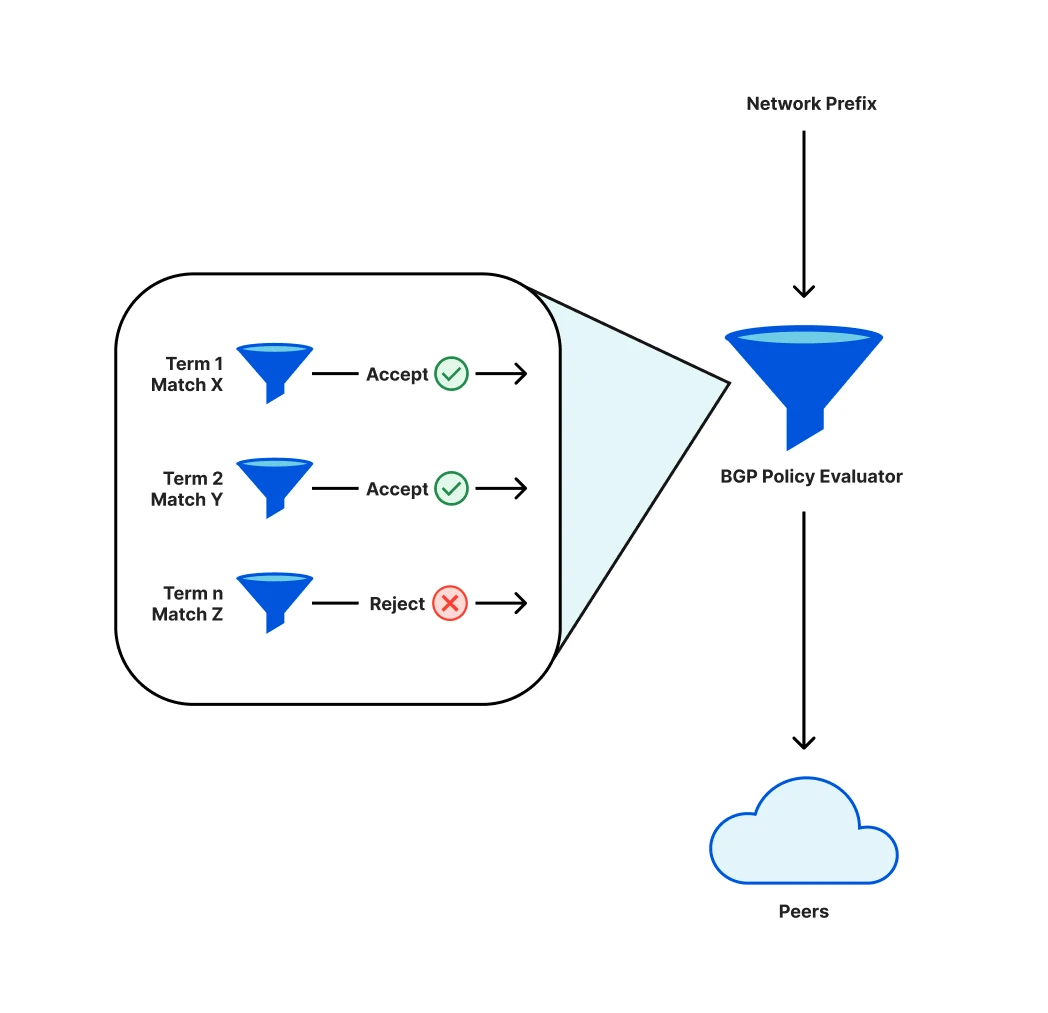
前缀通告策略更改时,术语的重新编排,导致Cloudflare必须撤回前缀的关键子集。
政策的变化可能意味着以前会广播的前缀不再被广播,Cloudflare工程师在受影响的数据中心,对有问题部分进行恢复时,就遇到了额外困难,不过Cloudflare有处理此类问题的备份程序。
03:56 UTC:Cloudflare将更改部署到第一个(数据中心)位置,所有位置都没有受到此次更改的影响,因为这些位置使用的旧的架构。
06:17:部署更改到Cloudflare最繁忙的地点,但是没有部署到具备 MCP(Multi-Colo PoP) 体系结构的位置。
06:27:部署到达了启用 MCP (Multi-Colo PoP)的位置,并且更改已部署到关键部位。这是服务中断事件开始的时候,这个时候,19个数据中心迅速离线。
06:32:Cloudflare内部宣布本次服务中断事件。
06:51:在路由器上进行的首次更改,以验证根本原因。
06:58:排查故障,找出根本原因,还原出现问题的部分
07:42:最后一次还原已完成,网络工程师开始检查对方的更改,还原状态,此时问题偶尔重新出现,因此延迟了一点。
08:00:服务中断事件结束。
这些数据中心的重要性,可以从下图全球范围内处理的成功HTTP请求的数量中清楚地看出:
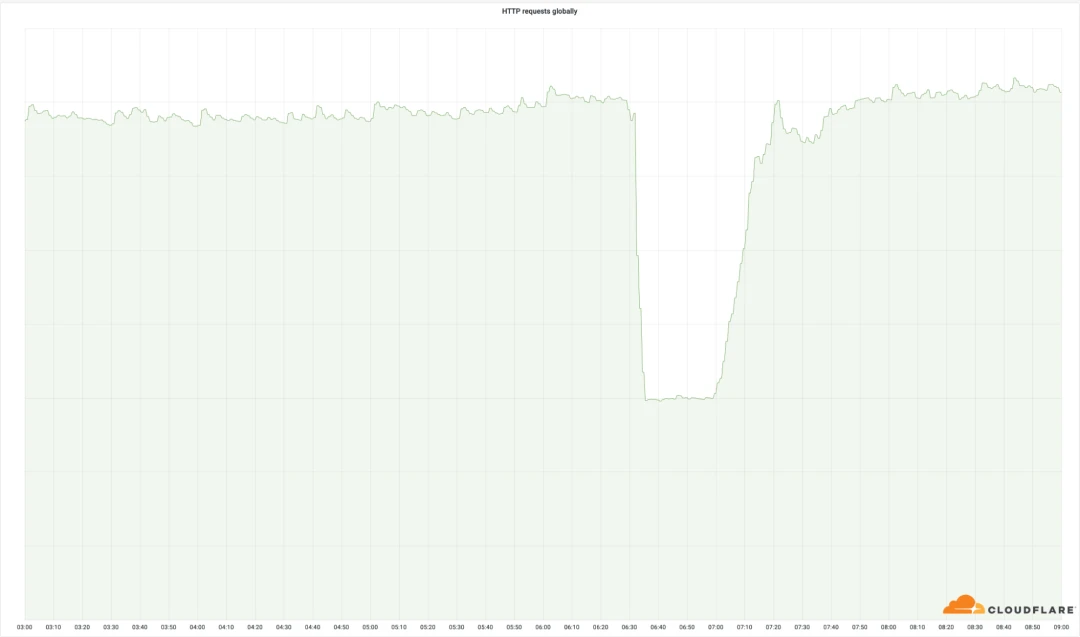
尽管这些出问题的数据中心,仅占Cloudflare总网络的 4%,但这次中断影响了总请求的 50%;
(本部分有小部分代码,此处略去,感兴趣的网络工程小伙伴可查看原文:
https://blog.cloudflare.com/cloudflare-outage-on-june-21-2022/)
补救和后续步骤
本次服务终端事件造成了广泛且严重的影响,Cloudflare一贯对可用性是非常重视,目前已经提出了几个需要改进的领域,而后将继续努力,发现可能潜在导致服务终端的所有问题。
流程:虽然 MCP 计划旨在提高可用性,但我们在更新这些数据中心方面的程序性差距,导致造成了严重影响。虽然Cloudflare确实为设计了交错策略,但是它并不完美,部署过程和自动化中,需要包含 MCP 的测试和具体部署过程,以确保不会产生意外后果。
架构:路由器配置的错误会阻止正确的路由广播,从而阻止了正常流量和基础设施的运行。Cloudflare将会重新设计路由广播的策略语句,防止排序的错误。
自动化:Cloudflare自动化套件中有可以降低此事件负面影响的部分。Cloudflare将专注于自动化改进,为网络配置的推出强制实施改进的交错策略,并提供自动 提交-确认 回滚。前者将大大降低整体影响,后者将大幅度减少事件中的解决时间。
结论
尽管Cloudflare在MCP架构设计上投入了大量资金,提高服务可用性,但在本次服务中断事件中,让客户失望了。对于服务中断期间,无法访问互联网和数字资产的客户,以及所有用户,Cloudflare深表歉意,已经开始着手进行所有的改进和优化,努力确保类似情况不会再次发生。





