




原文作者:Matt Bornstein, Guido Appenzeller, and Martin Casado
原文来源:阿法兔研究笔记
原文翻译:阿法兔
A16Z最近又发了一篇有意思的文章,谈到他们认为的生成式 AI 价值捕获问题,比如说目前生成式 AI 在商业化落地存在哪些问题?价值捕获最大的部分在哪?笔者翻译后对部分内容进行了注解。
文章主要两部分:第一部分,包括A16Z对生成式 AI 整个目前赛道的观察,以及存在什么问题;第二部分除了问题之外,还讲解了到底哪块能捕获最大的价值,无疑,得基础设施者的天下(请注意:这些大部分都是A16Z的 Portofolio,请大家本着客观理性的态度阅读,本文不构成任何投资建议或者对项目的推荐)
*本文版权归A16Z所有,翻译仅为供大家学习使用。
什么是生成式AI?
生成式 AI是机器学习的一个类别,计算机可以根据用户的输入/提示,生成原创的新内容。目前这项技术最成熟的应用主要在文本和图像领域,不过几乎所有的创意领域都有类似的进步(生成式 AI 的技术应用),覆盖动画、声音效果、音乐,甚至是对具备完整个性的虚拟人物进行原创。
第一部分:观察和预测
人工智能应用正在迅速扩大规模,而留存并没有那么容易,并不是所有人都可以建立起来商业规模。
生成式 AI 技术的早期阶段已浮现:
比如说,数以百计的新兴 AI 创业公司正冲向市场,开始开发基础模型,构建 AI 原生应用程序、基础设施与工具。
当然,确实会有很多热门技术趋势,会出现过度炒作的情况。但生成式人工智能的蓬勃发展,已经能看到很多公司产生了实实在在的营收。
例如,像 Stable Diffusion 和 ChatGPT 这样的模型创造了用户增长的历史记录,有的应用在推出后不到一年,就达到了 1 亿美元的年营收,并且人工智能模型在部分任务中的表现要比人类的水平高几个数量级。
我们发现,技术范式转型正在发生。但是,需要研究的关键问题在于:整个市场中,哪些地方会产生价值?
过去一年里,我们和几十位生成式 AI 创业公司的创始人和大公司 AI 领域的专家。我们观察到目前为止,基础设施供应商很可能是这个市场上最大的赢家,因为基础设施可以获得经过整个生成式 AI 堆栈最多的流水和营收。
尽管主攻应用开发的公司收入增长非常快,但这部分公司往往在用户留存、产品差异化和毛利率方面存在弱势。而大多数模型供应商目前还没有掌握大规模的商业化能力。
再说的准确一点,那些能够创造最大价值的公司,比如说能够训练生成式人工智能模型,并将这种技术应用于新的应用程序,目前还没有完全抓住行业中的的大部分价值。所以,现在想要预测后面的行业趋势并不是那么容易。
但是,想办法了解整个行业堆栈的哪些部分能做到真正的差异化,和可防御化很重要,因为这部分可以对整个市场结构(即横向与纵向的公司发展)和长期价值驱动力(如利润率和用户留存率)产生重大影响。
但迄今为止,除了现有公司传统意义上的业务护城河,很难在(生成式人工智能的)堆栈上找到结构上可防御性。
我们看好生成式人工智能赛道,也坚信这个领域对各个行业产生巨大影响。这篇文章的撰写目的,主要是为了描绘市场的动态,回答一些关于生成性人工智能商业模式更为广泛的问题。
技术栈:基础设施、人工智能模型和应用程序
想要了解生成式人工智能赛道和市场是如何形成的,首先需要定义目前整个行业的堆栈:
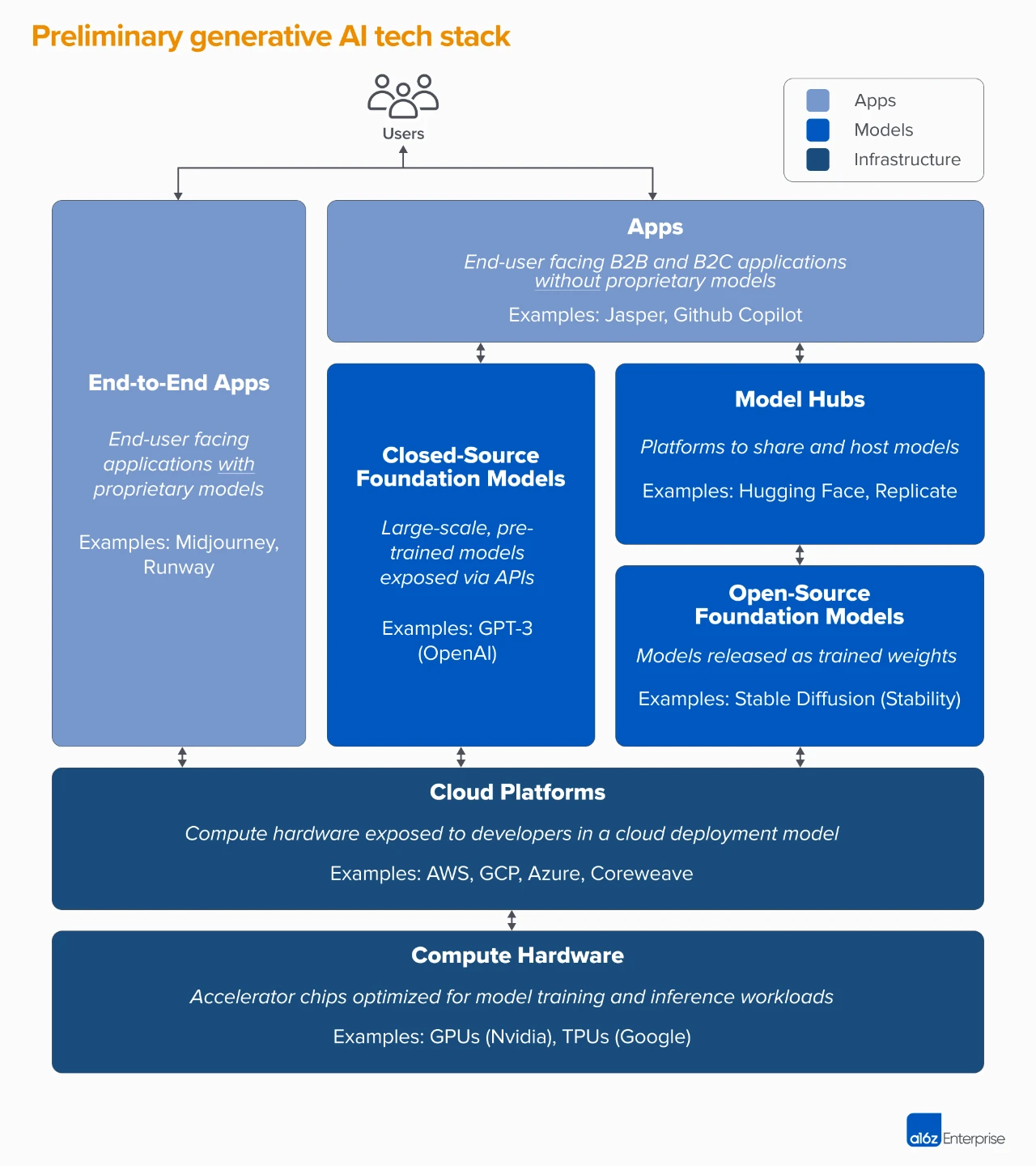
整个生成式人工智能的堆栈可分为三层:
1.将生成式 AI 模型,与面向用户的产品应用集成,这种通常是运行自己的模型管道(端到端应用),或者依赖第三方 API
(阿法兔研究笔记注释:这里我们说的模型管道,指的就是就是一个模型的输出作为下一个模型的输入)
2.为人工智能产品提供动力的模型,以专有 API 或开源检查点的形式提供(这反过来需要一个托管解决方案)
(注释:这块说的是,要么把整个模型的构建方式以及预训练的模型(又叫检查点)开放出来,要么需要把整个模型的构建方式以及预训练的模保密,只开放一个接口 API,如果是前者的话,你就要自己去跑训练/微调/推理,所以需要知道它能什么样的环境、什么样的硬件基础上跑,所以需要有人提供一个托管平台处理模型运行环境的事情)
3.为生成性人工智能模型运行训练和推理工作负载的基础设施供应商(即云平台和硬件制造商)
需要注意的是,这块我们讲的并不是整个市场的生态图,而是一个分析市场的框架,本文在每个类别中都列出了一些知名厂商的例子,不过没有囊括列出目前所有最厉害的AIGC应用,也没有深入讨论 MLops 或 LLMops 工具,因为这块还没有达到完全成熟的标准化,有机会我们会继续讨论。
第一波的生成式人工智能应用开始形成规模化,但在留存和差异化方面却不容易
在之前的技术周期中,传统意义上的观点会认为,想要建立大型的、独立的公司,就必须拥有终端客户,这里的终端客户包括个人消费者和 B 2B买家。
因为这种传统意义上的观点,大家很容易也认为:生成式人工智能中最大的机会也在于能够做面向终端用户的应用的公司。
但是到目前为止,其实情况并不一定会这样。
生成式人工智能应用的增长非常惊人,这种增长主要是由非常新颖和应用案例所驱动的,比如说图像生成、文案写作和代码编写,这三个产品类别的年收入已经超过了 1 亿美元。
但是,光增长还不足以构建持久的软件公司,关键在于,这种增长必须是有利润,也就是说,用户和客户一旦注册就可以产生利润(高毛利),并且这种利润还需要能够长期可持续(高留存率)。
如果公司之间不存在强大的技术差异化,B 2B和 B 2C应用程序只要通过网络效应,和数据优势,再或者构建愈发复杂的工作流程,从而获得成功。
但是,在生成式人工智能领域,上述假设未必成立。在我们调研的做生成式人工智能 APP 的创业公司中,毛利率的变化范围很广,少数公司能达到 90% ,多数公司毛利率低至 50-60% ,这块主要由模型成本影响。
尽管我们可以看到目前渠道顶端(Top-of-funnel )的增长,但是,还不清楚目前客户获取策略是否可以持续,因为已经看到了很多付费获取的效率和留存率开始下降。
目前市面上的很多应用程序也确实缺乏差异性,因为这些应用主要依赖于相似的底层人工智能模型,并没有发现明显能够具备独家网络效应、其他竞争对手很难复制的的杀手级应用和数据/工作流程。
因此,目前我们还不知道能够建立可持续的生成式人工智能商业化业务的最佳实践到底是什么,随着语言模型的竞争和效率的提高,利润率应该会提高。随着那波仅仅因为人工智能的热度才来的用户逐步冷却,离开市场,用户留存率大概率会增加。并且,我们认为垂直整合的应用在制造差异化方面具备优势,但是很多还需要接下来的实践证明。
展望未来,生成式 AI 应用会面临什么问题?
在垂直整合(模型+应用)方面
如果人工智能模型作为一种消费型服务,应用开发者可以用小团队模式快速迭代,并随着技术的进步,逐步更换模型供应商。但还有开发者不同意,他们认为,产品就是模型,从头开始训练是创造可防御性的唯一途径,这里指的是不断地对专有产品数据进行再训练(re-training)。但这就需要更高的资本,并且需要稳定的产品团队为代价的。
构建功能与应用程序
生成式人工智能产品具备很多形式:桌面应用,移动应用,Figma/Photoshop 插件,Chrome 扩展应用...甚至还包括 Discord 机器人。在用户已经在应用、有使用习惯的地方整合人工智能产品比较容易,因为用户界面较为简易。但是,这些公司里有哪些会成为独立的公司?哪些会被微软或谷歌人工智能巨头所吸纳?
会和 Gartner 公司发布的炒作周期(hyper cycle) 一致?
尚且不清楚当前的用户流失率,是不是都是早期人工智能产品所必须面对的,仅仅是我们当前这批人工智能产品所固有的。再或者,市场对生成式人工智能的兴趣,是否会随着市场炒作的消退而下降。这些问题,对开发 APP 应用程序公司存在重要的影响,包括何时选择融资的时机、设计用户获取策略、对于用户群的考虑有用户的优先度,以选择宣布产品市场匹配(Product Market Fit)时机。
第二部分:关于生成式人工智能的规模化商业落地
我们第一部分说了目前生成式 AI 的堆栈以及面临的部分问题。第二部分继续讲:
关于生成式人工智能的规模化商业落地
以及到底 Winner Takes All 价值捕获最大的,在哪部分?
还有上面其他问题?
目前行业的问题在哪?
尽管模型的发明,导致生成式人工智能技术广为人知,但目前还未达到大规模的商业落地的程度
倘若没有谷歌、OpenAI 和 Stability 等公司在研究方面的付出,以及这些公司将研究工程化,我们今天就无法见证如此成功的生成式人工智能技术。无论是我们看到的全新模型架构,还是扩展训练管道,主要得益于当前大型语言模型(LLMs)和图像模型的强大能力。
然而,如果我们去看这些公司的收入,和这么大的使用量和市场的热度比,收入并不是很高。在图像生成这块,Stable Diffusion 的社区出现爆炸性增长。但 Stability 公司的主要检查点是开放的,这也是 Stability 业务的核心宗旨。
在自然语言模型方面,OpenAI 以 GPT-3/3.5 和 ChatGPT 而闻名。但到目前为止,基于 OpenAI 构建的杀手级应用还是较少,而且价格已经下降过一次。(见下图)
(想想为什么降价?)
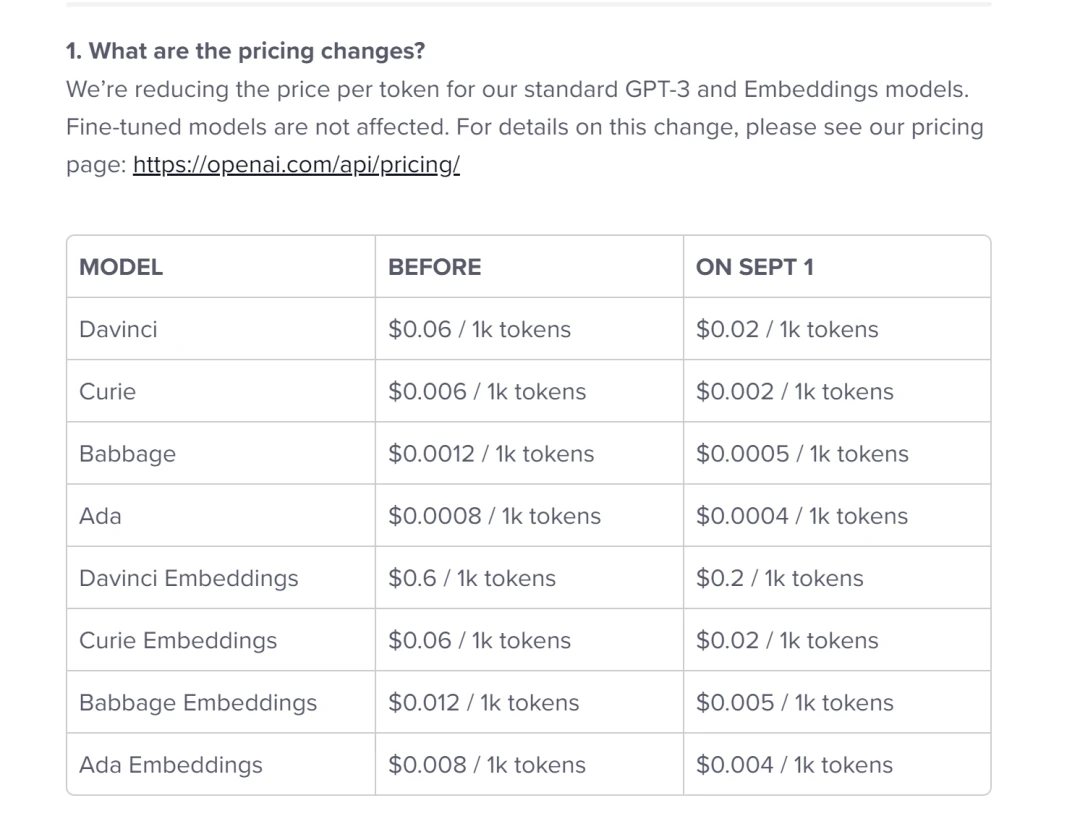
当然,目前这些可能只是暂时现象。Stability 是新型创业公司,没有把重点放在商业化上。OpenAI 有可能拥有海量业务,随着更多的杀手级应用的构建,OpenAI 可以赚取所有自然语言行业类别收入的很大一部分,特别是如果 OpenAI 与微软的产品组合的整合顺利进行,这些模型的高使用量会带来大规模收入。
但也存在隐患:
比如说,如果模型开源,那么它就可以由任何人托管,包括那些不承担大规模模型训练成本(这块高达数千或数亿美元)的其他公司。
而且目前还不清楚,闭源模型可以无限期地保持其优势。例如,比如说我们开始看到 Anthropic、Cohere 和 Character.ai 等公司建立的大模型 LLMs 接近 OpenAI 的性能水平,在类似的数据集(即互联网)上训练,采用类似的模型架构。
Stable Diffusion的例子表明,如果开源模型的性能和社区支持达到了一定水平,那么同一个赛道的其他替代品可能会发现竞争非常困难。
到目前为止,对模型提供方来说,最明显的收获也许是与托管有关的商业化(注释:这块就是指的是上篇提到的要么把整个模型的构建方式以及预训练的模型(又叫检查点)开放出来,要么需要把整个模型的构建方式以及预训练的模保密,只开放一个接口 API,如果是前者的话,你就要自己去跑训练/微调/推理,所以需要知道它能什么样的环境、什么样的硬件基础上跑,所以需要有人提供一个托管平台处理模型运行环境的事情);
以及对专有 API 的需求(例如来自 OpenAI)正在迅速增长。比如,开源模型的托管服务(如 Hugging Face 和 Replicate)出现,成为轻松分享和整合模型的枢纽,甚至在模型生产者和消费者之间,产生了间接的网络效应。还有有力的假设是,有可能通过微调和与企业客户的托管协议,来实现公司的盈利。
不过,模型供应方还面临着问题:
商业化。普遍观点认为,随着时间的推移,人工智能模型的性能将趋于一致。在与 APP 开发人员交谈时,目前这种性能一致的现象还没有发生,因为在文本和图像模型中都有排名靠前的选手。这些公司的优势,不在于独特模型架构,而是基于很高的高资本要求、专有的产品互动数据和稀缺的 AI 人才。
但是,这些能够成为一家公司长久可持续的优势吗?
脱离模型供应商的风险。依靠模型供应商是很多 APP 公司起步的途径,它们甚至靠供应商发展业务,但是,一旦达到规模,APP 开发商,就有动力建立和/或托管自己的模型。许多模型供应商的客户分布并不均衡,少数应用程序掌握了大部分的收入。如果这些客户不用供应商的模型,转向自己内部进行人工智能模型开发,怎么办?
资本会很重要吗?生成式人工智能的愿景太大了,以至于许多模型供应商已经开始将公共利益纳入其使命。这一点也没有妨碍他们的融资。但需要讨论的是,模型供应商是否真有意愿去获取价值,以及他们是否应该得到这些。
得基础设施得天下。
生成式人工智能中的所有,都会使用云托管的 GPU(或 TPU)服务。无论是模型供应方还是研究实验室,运行训练工作负载,还是托管公司运行推理/微调,FLOPS 是生成式人工智能的关键。
(阿法兔研究笔记注释:FLOPS 是 floating point operations per second 的缩写,意思是每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。通常我们去评价一个模型时,首先要看它的精确度,当精确度不行的时候,你和别人说我的模型预测的多么多么的快,部署的时候占的内存多么多么的小,都是白搭。但当你模型达到一定的精确度之后,就需要更进一步的评价指标来评价模型:
这里包括:
1 )前向传播时所需的计算力,它反应了对硬件如 GPU 性能要求的高低;
2 )参数个数,它反应所占内存大小。为什么要加上这两个指标呢?因为这事关你模型算法的落地。比如你要在手机和汽车上部署深度学习模型,对模型大小和计算力就有严格要求。模型参数想必大家都知道是什么怎么算了,而前向传播时所需的计算力可能还会带有一点点疑问。所以这里总计一下前向传播时所需的计算力。它正是由 FLOPs 体现。
参考资料:知乎阿柴本柴:https://zhuanlan.zhihu.com/p/137719986 )
因此,生成式人工智能领域的很多资金,最终都流向了基础设施公司。粗略估计的话,平均而言,应用程序公司在推理和每个客户的微调上花费了大约 20-40% 的收入。而这笔收入通常是直接支付给云供应商的计算实例或第三方模型供应商,供应商反过来又将大约一半的收入用于云基础设施。因此,我们可以推测:今天生成式人工智能总收入的 10-20% 是给了云供应商。
除此之外,训练自己的模型的初创公司,也已经融资数十亿美元的风险资本,而其中大部分(在早期轮次中高达 80-90% )通常也是花云供应商身上。许多科技公司每年在模型培训上花费数亿美元,它们要么与外部云供应商合作,要么直接与硬件制造商合作。
对于一个 AIGC 新生市场来说,其中大部分是花在三大云上:亚马逊云科技(AWS)、谷歌云(GCP)和微软 Azure,这些云供应商每年总共花费超过 1000 亿美元的资本支出,以确保拥有最全面、最可靠和最具成本竞争力的平台。
特别是在生成式人工智能这块,这几家云厂商可以优先获得稀缺的硬件(如 Nvidia A 100 和 H 100 GPU)
(阿法兔注释:A 100 就长下面那样
也可以读这篇文章:突发 | 关于美国停止英伟达对华销售部分产品的解读 20220901

于是乎,竞争出现,比如像甲骨文这样的挑战者,再或者如 Coreweave 和 Lambda Labs 这样的创业公司,已经通过专门针对大型模型开发商的解决方案迅速发展,在成本、可用性和个性化的支持方面进行竞争,这些公司还公开了更细化的资源抽象(即容器),而大型云由于 GPU 虚拟化的限制,只提供虚拟机实例。
【阿法兔研究笔记注释:举个例子,我们想在互联网上购物、发消息、使用网上银行,都是在和基于云的服务器进行交互。也就是说,当我们在用客户端(移动手机、电脑、Ipad )进行各种操作时,都需要向服务器发出请求,每个操作都需要对应的服务器要处理每个请求,之后返回响应。
成千上万个用户成同时进行的大量的请求和相应,需要很强的计算能力(想想我们在双十一购物的时候,无数用户同时疯狂下单,购物车会突然很卡),这时候,计算能力就很重要了。前面我们说过,虚拟机属于计算能力的一部分,在我们使用云服务商的云计算解决方案时,可以根据企业目前的能力和需求,选择使用虚拟机。
啥是虚拟机呢?
就是计算机系统的仿真器,可以在一个完全隔离的系统中,提供我们真实计算机的功能。系统虚拟机可以提供一个可以运行完整操作系统的完整系统平台,例如我们用的 Windows 系统。MAC OS 系统等。程序虚拟机就是,可以在仿真器里单独运行计算机程序。也就是说,如果购买了云服务商提供的虚拟机,就像从云服务商那里买了一块地,之后就可以在虚拟机上面安装各种软件和运行各种任务,就像我们在自己买来的土地上自由改造,盖房子一样。
什么是容器?容器,我们通常会理解为,饭碗、器皿等可以装东西的工具。IT 里常说的容器技术又是什么?其实, 这个词语来自于 Linux Container 翻译,在英文里,Container 这个单词有集装箱、容器的含义(在技术的比喻上,容器主要的含义是偏集装箱的)。但是由于容器在中文中读起来更顺口,我们就使用中文的容器作为常用词语。如果想要形象的理解 Linux Container 技术,读到这里的你,脑海中可以想象出海边货运码头的集装箱。

货运码头里的集装箱是运载货物用的,它是一种按规格标准化的钢制箱子。集装箱的特点是,都是方形的,并且格式划一,可以层层叠放。
这样一来,货物在集装箱内可以放入巨型货运轮船,需要运送货物的生产厂商就可以更加快捷方便地运送货物,集装箱的出现,为生产商提供更高效的运输服务。根据这种方便运输服务,为了在中文环境能够容易地使用,计算机世界里引用了容器这一形象的概念。 】
我们认为,迄今为止生成式 AI 的最大赢家,是负责运行绝大部分人工智能工作负载的英伟达 Nvidia。英伟达在 2023 财年第三季度的数据中心 GPU 收入为 38 亿美元,其中有很大一部分用于生成式 AI 的使用案例。
(GPU:图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器)
英伟达通过几十年以来对 GPU 生态的投资,和学术界的长期深入应用,围绕这一业务建立了强大的护城河。最近的分析发现,Nvidia 的 GPU 在研究论文中被引用的次数是顶级 AI 芯片初创公司的 90 倍。
当然,也存在其他硬件的选择确实存在,包括谷歌 TPU;AMD Instinct GPU;AWS Inferentia 和 Trainium 芯片;以及 Cerebras、Sambanova 和 Graphcore 等初创公司。
英特尔公司以自家高端 Habana 芯片和 Ponte Vecchio GPU 进入市场。但到目前为止,英特尔新芯片中很少有占据重要市场份额的。其他两个值得关注的例外是谷歌和台积电,前者的 TPU 已经在稳定扩散社区和一些大型 GCP 交易中获得牵引力,后者被认为制造这里列出的所有芯片,包括 Nvidia GPU(英特尔使用自己的工厂和台积电混合制造芯片)。
我们发现:基础设施是存在有利可图的、持久的、似乎可以防御的堆栈层
但是,基础设施公司需要回答的问题包括:
无状态工作负载这个怎么办?
这个意思就是说,无论你在哪里租用 Nvidia GPU 都是一样的。大多数人工智能工作负载是无状态的,即模型推理不需要附加数据库或存储(注释:它不需要外部的存储或者数据库,除了模型权重本身)。这意味着人工智能工作负载可能比传统的应用工作负载更容易在云端迁移。在这种情况下,云供应商如何创造粘性,防止客户跑到更便宜的选择?
芯片要是不稀缺了,咋办?
云提供商和 Nvidia 的定价,因为 GPU 稀缺供应而可以卖得很贵。有供应商告诉我们,A 100 的上市价格自推出以来,已经持续上升,而这对计算硬件来说是非常不寻常的。那么,当这种供应限制最终通过增加生产和/或采用新的硬件平台而消除时,对云供应商有啥影响?
新晋云能否突破重围?
我们认为垂直云将以更专业的产品从三巨头手中夺取市场份额。到目前为止,在人工智能领域,新来的云选手,已经通过适度的技术差异化和 Nvidia 的支持,获得了动力。比如说,现有的云供应商既是他们的最大客户,也是新兴的竞争对手。那么,对这些新兴云公司来说,长期的问题是,能否克服三大巨头的规模优势?
那么,价值到底在哪部分会累积最多?我们怎么投,可以捕获最大的价值?
目前还没有清晰的答案,但是,根据目前掌握的生成式 AI 早期数据,结合对早期 AI 和机器学习创业公司的经验,做出以下判断:
在今天的生成式 AI 中,几乎不存在任何意义上的系统性护城河。我们看到目前的应用程序,产品差异化不大,这种迹象非常明显。原因在于,这些应用使用的是类似的人工智能模型。所以,目前模型面临的,是无法判断它们在更长周期内的差异化到底在哪,它们是在类似的数据集和架构上训练的;而云供应商同样,大家的技术基本趋同,因为运行相同的 GPU;甚至硬件公司,也会在相同的工厂生产芯片。
当然,仍有标准护城河——规模护城河存在,比如说同样的创业公司,我比你更能融资,我的融资能力更强;或者供应链方面的护城河,我有 GPU,你没有;或者是生态系统护城河,比如说我软件的用户比你多,且开始的早,我有时间和用户规模壁垒;再或者算法护城河,比如说我的算法就是比你更强大。销售领域的护城河,我就是比你会卖货,我是渠道上的佼佼者;再或者就是数据这块的护城河,比如我收集的数据比你多。
但是,这些护城河都无法在长期上具备优势,且不可持久。而且,目前要判断强大的、直接的网络效应到底会在这些堆栈的那一层占据优势,目前还为时过早。
根据现有的数据,目前还无法判断在生成式人工智能领域,是否会出现长期的、赢家通吃的机会。
听起来有些奇怪,但对我们来说,这是好消息。
正是因为整个市场的潜在规模难以把握,它和软件和所有人的尝试均息息相关。我们预计会有很多参与这个市场的选手,大家会在生成式 AI 堆栈的各个层面进行良心竞争。我们期望,横向和纵向都能跑出来成功的公司。
但是,这是由终端市场和用户决定的。例如,如果终端产品的主要差异化在于人工智能技术本身,那么垂直化(即把面向用户的应用程序与本土模型紧密结合这块)领域很可能会胜出。
而如果人工智能是一个更大的、长尾的功能集的一部分,那么横向化也许才是真正的趋势。当然,随着时间的推移,我们也应看到更多传统的护城河的建立,甚至会出现一些全新的护城河。
无论怎样,可以肯定的一点是,生成式人工智能改变了行业。所有人都在持续学习,有大量的价值将被释放出来,而科技生态将因此而改变。所有人都在努力的路上。





