




原文作者:Messari - Sami Kassab
原创编译:BlockTurbo
过去两周,生成式人工智能 (AI) 领域是毫无疑问的热点,突破性的新版本和尖端集成不断涌现。 OpenAI 发布了备受期待的 GPT-4 模型,Midjourney 发布了最新的 V 5 模型,Stanford 发布了 Alpaca 7 B 语言模型。与此同时,谷歌在其整个 Workspace 套件中推出了生成式人工智能,Anthropic 推出了其人工智能助手 Claude,而微软则将其强大的生成式人工智能工具 Copilot 集成到了 Microsoft 365 套件中。
随着企业开始意识到人工智能和自动化的价值以及采用这些技术以保持市场竞争力的必要性,人工智能开发和采用的步伐愈发加快。
尽管人工智能发展看似进展顺利,但仍有一些潜在的挑战和瓶颈需要解决。随着越来越多的企业和消费者接受人工智能,计算能力方面的瓶颈正在出现。人工智能系统所需的计算量每隔几个月就会翻一番,而计算资源的供应却难以跟上步伐。此外,训练大规模人工智能模型的成本持续飙升,过去十年每年增长约 3100% 。
开发和训练尖端人工智能系统所需的成本上升和资源需求增加的趋势正在导致集中化,只有拥有大量预算的实体才能进行研究和生产模型。然而,一些基于加密技术的项目正在构建去中心化解决方案,以使用开放计算和机器智能网络解决这些问题。
人工智能(AI)和机器学习(ML)基础
AI 领域可能令人望而生畏,深度学习、神经网络和基础模型等技术术语增加了其复杂性。现在,就让我们简化这些概念以便于理解。
人工智能是计算机科学的一个分支,涉及开发算法和模型,使计算机能够执行需要人类智能的任务,例如感知、推理和决策制定;
机器学习 (ML) 是 AI 的一个子集,它涉及训练算法以识别数据中的模式并根据这些模式进行预测;
深度学习是一种涉及使用神经网络的 ML,神经网络由多层相互连接的节点组成,这些节点协同工作以分析输入数据并生成输出。
基础模型,例如 ChatGPT 和 Dall-E,是经过大量数据预训练的大规模深度学习模型。这些模型能够学习数据中的模式和关系,使它们能够生成与原始输入数据相似的新内容。 ChatGPT 是一种用于生成自然语言文本的语言模型,而 Dall-E 是一种用于生成新颖图像的图像模型。
AI 和 ML 行业的问题
人工智能的进步主要由三个因素驱动:
算法创新:研究人员不断开发新的算法和技术,让人工智能模型能够更高效、更准确地处理和分析数据。
数据:人工智能模型依赖大型数据集作为训练的燃料,使它们能够从数据中的模式和关系中学习。
计算:训练 AI 模型所需的复杂计算需要大量的计算处理能力。
然而,有两个主要问题阻碍了人工智能的发展。回到 2021 年,获取数据是人工智能企业在人工智能发展过程中面临的首要挑战。去年,与计算相关的问题超越了数据成为挑战,特别是由于高需求驱动下无法按需访问计算资源。
第二个问题与算法创新效率低下有关。虽然研究人员通过在以前的模型的基础上继续对模型进行增量改进,但这些模型提取的智能或模式总是会丢失。
让我们更深入地研究这些问题。
计算瓶颈
训练基础机器学习模型需要大量资源,通常需要长时间使用大量 GPU。例如,Stability.AI 需要在 AWS 的云中运行 4, 000 个 Nvidia A 100 GPU 来训练他们的 AI 模型,一个月花费超过 5000 万美元。另一方面,OpenAI 的 GPT-3 使用 1, 000 个 Nvidia V1 00 GPU 进行训练,耗资 1, 200 万美元。
人工智能公司通常面临两种选择:投资自己的硬件并牺牲可扩展性,或者选择云提供商并支付高价。虽然大公司有能力选择后者,但小公司可能没有那么奢侈。随着资本成本的上升,初创公司被迫削减云支出,即使大型云提供商扩展基础设施的成本基本保持不变。
人工智能的高昂计算成本给追求该领域进步的研究人员和组织造成了重大障碍。目前,迫切需要一种经济实惠的按需无服务器计算平台来进行 ML 工作,这在传统计算领域是不存在的。幸运的是,一些加密项目正在致力于开发可以满足这一需求的去中心化机器学习计算网络。
效率低下和缺乏协作
越来越多的人工智能开发是在大型科技公司秘密进行的,而不是在学术界。这种趋势导致该领域内的合作减少,例如微软的 OpenAI 和谷歌的 DeepMind 等公司相互竞争并保持其模型的私密性。
缺乏协作导致效率低下。例如,如果一个独立的研究团队想要开发一个更强大的 OpenAI 的 GPT-4 版本,他们将需要从头开始重新训练模型,基本上是重新学习 GPT-4 训练的所有内容。考虑到仅 GPT-3 的培训成本就高达 1200 万美元,这让规模较小的 ML 研究实验室处于劣势,并将人工智能发展的未来进一步推向大型科技公司的控制。
但是,如果研究人员可以在现有模型的基础上构建而不是从头开始,从而降低进入壁垒;如果有一个激励合作的开放网络,作为一个自由市场管理的模型协调层,研究人员可以在其中使用其他模型训练他们的模型,会怎么样呢?去中心化机器智能项目 Bittensor 就构建了这种类型的网络。
机器学习的分散式计算网络
去中心化计算网络通过激励 CPU 和 GPU 资源对网络的贡献,将寻求计算资源的实体连接到具有闲置计算能力的系统。由于个人或组织提供其闲置资源没有额外成本,因此与中心化提供商相比,去中心化网络可以提供更低的价格。
存在两种主要类型的分散式计算网络:通用型和专用型。通用计算网络像分散式云一样运行,为各种应用程序提供计算资源。另一方面,特定用途的计算网络是针对特定用例量身定制的。例如,渲染网络是一个专注于渲染工作负载的专用计算网络。
尽管大多数 ML 计算工作负载可以在分散的云上运行,但有些更适合特定用途的计算网络,如下所述。
机器学习计算工作负载
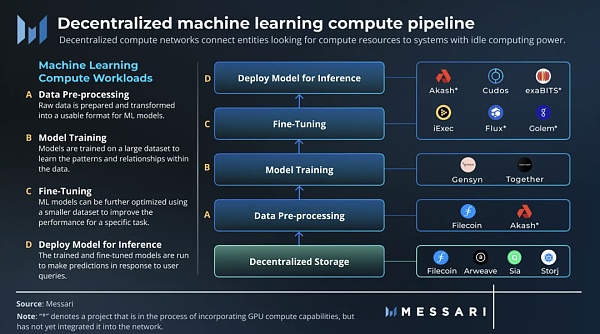
机器学习可以分为四种主要的计算工作负载:
数据预处理:准备原始数据并将其转换为 ML 模型可用的格式,这通常涉及数据清理和规范化等活动。
训练:机器学习模型在大型数据集上进行训练,以学习数据中的模式和关系。在训练期间,调整模型的参数和权重以最小化误差。
微调:可以使用较小的数据集进一步优化 ML 模型,以提高特定任务的性能。
推理:运行经过训练和微调的模型以响应用户查询进行预测。
数据预处理、微调和推理工作负载非常适合在 Akash、Cudos 或 iExec 等去中心化云平台上运行。然而,去中心化存储网络 Filecoin 由于其最近的升级而特别适合数据预处理,从而启用了 Filecoin 虚拟机(FVM)。 FVM 升级可以对存储在网络上的数据进行计算,为已经使用它进行数据存储的实体提供更高效的解决方案。
机器学习专用计算网络
由于围绕并行化和验证的两个挑战,训练部分需要一个特定用途的计算网络。
ML 模型的训练依赖于状态,这意味着计算的结果取决于计算的当前状态,这使得利用分布式 GPU 网络变得更加复杂。因此,需要一个专为 ML 模型并行训练而设计的特定网络。
更重要的问题与验证有关。要构建信任最小化的 ML 模型训练网络,网络必须有一种方法来验证计算工作,而无需重复整个计算,否则会浪费时间和资源。
Gensyn
Gensyn 是一种特定于 ML 的计算网络,它已经找到了以分散和分布式方式训练模型的并行化和验证问题的解决方案。该协议使用并行化将较大的计算工作负载拆分为任务,并将它们异步推送到网络。为了解决验证问题,Gensyn 使用概率学习证明、基于图形的精确定位协议以及基于抵押和削减的激励系统。
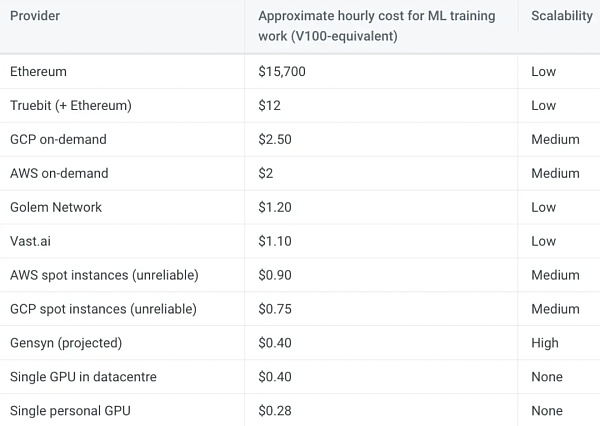
尽管 Gensyn 网络尚未上线,但该团队预测其网络上 V1 00 等效 GPU 的每小时成本约为 0.40 美元。这一估计是基于以太坊矿工在 Merge 之前使用类似 GPU 每小时赚取 0.20 至 0.35 美元。即使这个估计有 100% 的偏差,Gensyn 的计算成本仍将大大低于 AWS 和 GCP 提供的按需服务。
Together
Together 是另一个专注于构建专门用于机器学习的去中心化计算网络的早期项目。在项目启动之初,Together 开始整合来自斯坦福大学、苏黎世联邦理工学院、Open Science Grid、威斯康星大学麦迪逊分校和 CrusoeCloud 等不同机构未使用的学术计算资源,从而产生总计超过 200 PetaFLOP 的计算能力。他们的最终目标是通过汇集全球计算资源,创造一个任何人都可以为先进人工智能做出贡献并从中受益的世界。
Bittensor:去中心化机器智能
Bittensor 解决了机器学习中的低效率问题,同时通过使用标准化的输入和输出编码来激励开源网络上的知识生产,从而改变研究人员的协作方式,以实现模型互操作性。
在 Bittensor 上,矿工因通过独特的 ML 模型为网络提供智能服务而获得网络的本地资产 TAO 的奖励。在网络上训练他们的模型时,矿工与其他矿工交换信息,加速他们的学习。通过抵押 TAO,用户可以使用整个 Bittensor 网络的智能并根据他们的需要调整其活动,从而形成 P2P 智能市场。此外,应用程序可以通过网络的验证器构建在网络的智能层之上。
Bittensor 是如何工作的
Bittensor 是一种开源 P2P 协议,它实现了分散的专家混合 (MoE),这是一种 ML 技术,结合了专门针对不同问题的多个模型,以创建更准确的整体模型。这是通过训练称为门控层的路由模型来完成的,该模型在一组专家模型上进行训练,以学习如何智能地路由输入以产生最佳输出。为实现这一目标,验证器动态地在相互补充的模型之间形成联盟。稀疏计算用于解决延迟瓶颈。
Bittensor 的激励机制吸引了专门的模型加入混合体,并在解决利益相关者定义的更大问题中发挥利基作用。每个矿工代表一个独特的模型(神经网络),Bittensor 作为模型的自我协调模型运行,由未经许可的智能市场系统管理。
该协议与算法无关,验证者只定义锁并允许市场找到密钥。矿工的智能是唯一共享和衡量的组成部分,而模型本身仍然是私有的,从而消除了衡量中的任何潜在偏见。
验证者
在 Bittensor 上,验证器充当网络 MoE 模型的门控层,充当可训练的 API 并支持在网络之上开发应用程序。他们的质押支配着激励格局,并决定了矿工要解决的问题。验证者了解矿工提供的价值,以便相应地奖励他们并就他们的排名达成共识。排名较高的矿工获得更高份额的通货膨胀区块奖励。
验证者也被激励去诚实有效地发现和评估模型,因为他们获得了他们排名靠前的矿工的债券,并获得了他们未来奖励的一部分。这有效地创造了一种机制,矿工在经济上将自己“绑定”到他们的矿工排名。该协议的共识机制旨在抵制高达 50% 的网络股份的串通,这使得不诚实地对自己的矿工进行高度排名在财务上是不可行的。
矿工
网络上的矿工接受训练和推理,他们根据自己的专业知识有选择地与同行交换信息,并相应地更新模型的权重。在交换信息时,矿工根据他们的股份优先处理验证者请求。目前有 3523 名矿工在线。
矿工之间在 Bittensor 网络上的信息交换允许创建更强大的 AI 模型,因为矿工可以利用同行的专业知识来改进他们自己的模型。这实质上为 AI 空间带来了可组合性,不同的 ML 模型可以在其中连接以创建更复杂的 AI 系统。
复合智能
Bittensor 通过新市场解决激励低效问题,从而有效地实现机器智能的复合,从而提高 ML 培训的效率。该网络使个人能够为基础模型做出贡献并将他们的工作货币化,无论他们贡献的规模或利基如何。这类似于互联网如何使利基贡献在经济上可行,并在 YouTube 等内容平台上赋予个人权力。本质上,Bittensor 致力于将机器智能商品化,成为人工智能的互联网。
总结
随着去中心化机器学习生态系统的成熟,各种计算和智能网络之间很可能会产生协同效应。例如 Gensyn 和 Together 可以作为 AI 生态的硬件协调层,而 Bittensor 可以作为智能协调层。
在供应方面,以前开采 ETH 的大型公共加密矿工对为去中心化计算网络贡献资源表现出极大的兴趣。例如,在他们的网络 GPU 发布之前,Akash 已经从大型矿工那里获得了 100 万个 GPU 的承诺。此外,较大的私人比特币矿工之一的 Foundry 已经在 Bittensor 上进行挖矿。
本报告中讨论的项目背后的团队不仅仅是为了炒作而构建基于加密技术的网络,而是 AI 研究人员和工程师团队,他们已经意识到加密在解决其行业问题方面的潜力。
通过提高训练效率、实现资源池化并为更多人提供为大规模 AI 模型做出贡献的机会,去中心化 ML 网络可以加速 AI 发展,让我们在未来更快解锁通用人工智能。





