
Solidity编译器漏洞分析:ABI重编码的缺陷
总览
本文从源代码层面对 Solidity 编译器( 0.5.8<= version <0.8.16)在 ABIReencoding 过程中,由于对固定长度的 uint 和 bytes 32 类型数组的错误处理所导致的漏洞问题进行详细分析,并提出相关的解决方案及规避措施。
漏洞详情
ABI 编码格式是用在用户或合约对合约进行函数调用,传递参数时的标准编码方式。具体可以参考 Solidity 官方关于ABI 编码的详细表述。
在合约开发过程中,会从用户或其他合约传来的 calldata 数据中,获取需要的数据,之后可能会将获取的数据进行转发或 emit 等操作。限于 evm 虚拟机的所有 opcode 操作都是基于 memory、stack 和 storage,所以在 Solidity 中,涉及到需要对数据进行 ABI 编码的操作,都会将 calldata 中的数据根据新的顺序按照 ABI 格式进行编码,并存储到 memory 中。
该过程本身并没有大的逻辑问题,但是当和 Solidity 的cleanup 机制结合时,由于 Solidity 编译器代码本身的疏漏,就导致了漏洞的存在。
根据 ABI 编码规则,在去掉函数选择符之后,ABI 编码的数据分为 head 和 tail 两部分。当数据格式为固定长度的 uint 或 bytes 32 数组时,ABI 会将该类型的数据都存储在 head 部分。而 Solidity 对 memory 中 cleanup 机制的实现是在当前索引的内存被使用后,将下一个索引的内存置空,以防止下一索引的内存使用时被脏数据影响。并且,当 Solidity 对一组参数数据进行 ABI 编码时,是按照从左到右的顺序进行编码!!
为了便于后面的漏洞原理探索,考虑如下形式的合约代码:
contract Eocene {
event VerifyABI( bytes[], uint[ 2 ]);
function verifyABI(bytes[] calldata a, uint[ 2 ] calldata b) public {
emit VerifyABI(a, b); //Event 数据会按照 ABI 格式编码之后存储到链上
}
}
合约 Eocene 中 verifyABI 函数的作用,仅仅是将函数参数中的不定长 bytes[] a 和定长 uint[2 ] b 进行 emit。
这里需要注意,event 事件也会触发 ABI 编码。这里参数 a, b 会编码成 ABI 格式后再存储到链上。
我们使用 v 0.8.14 版本的 Solidity 对合约代码进行编译,通过 remix 进行部署,并传入verifyABI(['0x aaaaaa','0x bbbbbb'],[0x 11111, 0x 22222 ])。
首先,我们看一看对verifyABI(['0x aaaaaa','0x bbbbbb'],[0x 11111, 0x 22222 ])的正确编码格式:
0x 5 2c d 1 a 9 c // bytes 4(sha 3("verify(btyes[], uint[ 2 ])"))
0000000000000000000000000000000000000000000000000000000000000060 // index of a
0000000000000000000000000000000000000000000000000000000000011111 // b[0 ]
0000000000000000000000000000000000000000000000000000000000022222 // b[1 ]
0000000000000000000000000000000000000000000000000000000000000002 // length of a
0000000000000000000000000000000000000000000000000000000000000040 // index of a[0 ]
0000000000000000000000000000000000000000000000000000000000000080 // index of a[1 ]
0000000000000000000000000000000000000000000000000000000000000003 // length of a[0 ]
aaaaaa 0000000000000000000000000000000000000000000000000000000000 // a[0 ]
0000000000000000000000000000000000000000000000000000000000000003 // length of a[1 ]
bbbbbb 0000000000000000000000000000000000000000000000000000000000 // a[1 ]
如果 Solidity 编译器正常,当参数a, b被 event 事件记录到链上时,数据格式应该和我们发送的一样。让我们实际调用合约试试看,并对链上的 log 进行查看,如果想自己对比,可以查看该TX。
成功调用后,合约 event 事件记录如下:
!!震惊,紧跟 b[1 ]的,存储 a 参数长度的值被错误的删除了!!
0000000000000000000000000000000000000000000000000000000000000060 // index of a
0000000000000000000000000000000000000000000000000000000000011111 // b[0 ]
0000000000000000000000000000000000000000000000000000000000022222 // b[1 ]
0000000000000000000000000000000000000000000000000000000000000000 // length of a?? why become 0??
0000000000000000000000000000000000000000000000000000000000000040 // index of a[0 ]
0000000000000000000000000000000000000000000000000000000000000080 // index of a[1 ]
0000000000000000000000000000000000000000000000000000000000000003 // length of a[0 ]
aaaaaa 0000000000000000000000000000000000000000000000000000000000 // a[0 ]
0000000000000000000000000000000000000000000000000000000000000003 // length of a[1 ]
bbbbbb 0000000000000000000000000000000000000000000000000000000000 // a[1 ]
为什么会这样?
正如我们前面所说,在 Solidity 遇到需要进行 ABI 编码的系列参数时,参数的生成顺序是从左至,具体对 a, b 的编码逻辑如下
Solidity 先对 a 进行 ABI 编码,按照编码规则,a 的索引放在头部,a 的元素长度以及元素具体值均存放在尾部。
处理 b 数据,因为 b 数据类型为 uint[2 ]格式,所以数据具体值被存放在 head 部分。但是,由于 Solidity 自身的 cleanup 机制,在内存中存放了 b[1 ]之后,将 b[1 ]数据所在的后一个内存地址(被用于存放 a 元素长度的内存地址)的值置 0 。
ABI 编码操作结束,错误编码的数据存储到了链上,SOL-2022-6 漏洞出现。
在源代码层面,具体的错误逻辑也很明显,当需要从 calldata 获取定长 bytes 32 或 uint 数组数据到 memory 中时,Solidity 总是会在数据复制完毕后,将后一个内存索引数据置为 0 。又由于 ABI 编码存在 head 和 tail 两部分,且编码顺序也是从左至右,就导致了漏洞的存在。
具体漏洞的 Solidity 编译代码如下:
当源数据存储位置为 Calldata,且源数据类型为 ByteArray,String,或者源数组基础类型为 uint 或 bytes 32 时进入ABIFunctions::abiEncodingFunctionCalldataArrayWithoutCleanup()
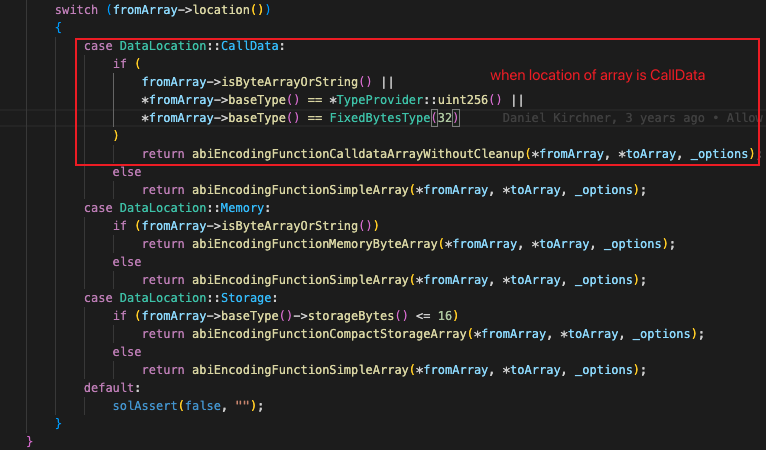
进入之后,会首先通过fromArrayType.isDynamicallySized()对源数据是否为定长数组来对源数据进行判断,只有定长数组才符合漏洞触发条件。
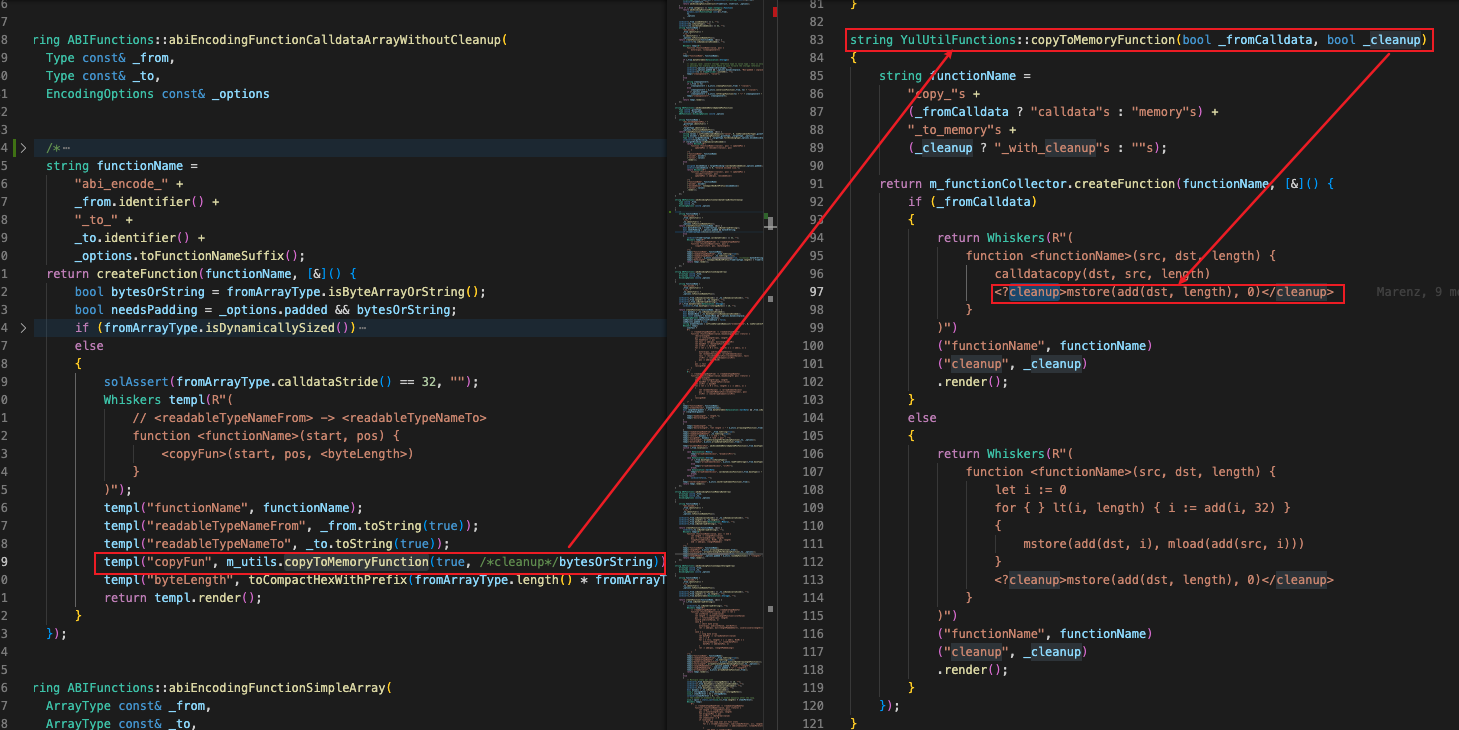
将isByteArrayOrString()判断结果传递给YulUtilFunctions::copyToMemoryFunction(), 根据判断结果来确定是否在 calldatacopy 操作完成后,对后一个索引位置进行 cleanup。
上诉几个约束条件结合,就只有位于 calldata 中的源数据格式为定长的 uint 或 bytes 32 的数组复制到内存时才能触发漏洞。也即是漏洞触发的约束条件产生的原因。
由于 ABI 进行参数编码时,总是从左到右的顺序,考虑到漏洞的利用条件,我们必须要明白,必须在定长的 uint 和 bytes 32 数组前,存在动态长度类型的数据被存储到 ABI 编码格式的 tail 部分,且定长的 uint 或 bytes 32 数组必须位于待编码参数的最后一个位置。
原因很明显,如果定长的数据没有位于最后一个待编码参数位置,那么对后一内存位置的置 0 不会有任何影响,因为下个编码参数会覆盖该位置。如果定长数据前面没有数据需要被存储到 tail 部分,那么即便后一内存位置被置 0 也没有关系,因为该位置并不背 ABI 编码使用。
另外,需要注意的是,所有的隐式或显示的 ABI 操作,以及符合格式的所有 Tuple(一组数据),都会受到该漏洞的影响。
具体的涉及到的操作如下:
event
error
abi.encode*
returns //the return of function
struct //the user defined struct
all external call
解决方案
当合约代码中存在上诉受影响的操作时,保证最后一个参数不为定长的 uint 或 bytes 32 数组
使用不受漏洞影响的 Solidity 编译器
寻求专业的安全人员的帮助,对合约进行专业的安全审计
关于我们
At Eocene Research, we provide the insights of intentions and security behind everything you know or don't know of blockchain, and empower every individual and organization to answer complex questions we hadn't even dreamed of back then.


