




原文作者:Mohit Pandit, IOSG Ventures

摘要
GPU 短缺是现实,供需紧张,但未充分利用的 GPU 数量可以满足当今供应紧缺的需求。
需要一个激励层来促进云计算的参与,然后最终协调用于推理或训练的计算任务。DePIN 模型正好适合这一用途。
因为供应方的激励,因为计算成本较低,需求方发现这很吸引人。
并非一切都是美好的,选择Web3云时必须做出某些权衡:比如‘延迟’。相对于传统的 GPU 云,面临的权衡还包括保险、服务水平协议 (Service Level Agreements) 等。
DePIN 模型有潜力解决 GPU 可用性问题,但碎片化模型不会使情况变得更好。对于需求呈指数级增长的情况,碎片化供应和没有供应一样。
考虑到新市场参与者的数量,市场聚合是不可避免的。
引言
我们正处于机器学习和人工智能的新时代边缘。虽然 AI 已经以各种形式存在一段时间(AI 是被告知执行人类可以做的事情的计算机设备,如洗衣机),但我们现在见证了复杂认知模型的出现,这些模型能够执行需要智能人类行为的任务。显著的例子包括 OpenAI 的 GPT-4 和 DALL-E 2 ,以及谷歌的 Gemini。
在迅速增长的人工智能(AI)领域,我们必须认识到发展的双重方面:模型训练和推理。推理包括 AI 模型的功能和输出,而训练包括构建智能模型所需的复杂过程(包括机器学习算法、数据集和计算能力)。
以 GPT-4 为例,最终用户关心的只是推理:基于文本输入从模型获取输出。然而,这种推理的质量取决于模型训练。为了训练有效的 AI 模型,开发者需要获得全面的基础数据集和巨大的计算能力。这些资源主要集中在包括 OpenAI、谷歌、微软和 AWS 在内的行业巨头手中。
公式很简单:更好的模型训练 >> 导致 AI 模型的推理能力增强 >> 从而吸引更多用户 >> 带来更多收入,用于进一步训练的资源也随之增加。
这些主要玩家能够访问大型基础数据集,更关键的是控制着大量计算能力,为新兴开发者创造了进入壁垒。因此,新进入者经常难以以经济可行的规模和成本获得足够的数据或利用必要的计算能力。考虑到这种情况,我们看到网络在民主化资源获取方面具有很大价值,主要是与大规模获取计算资源以及降低成本有关。
GPU 供应问题
NVIDIA 的 CEO Jensen Huang 在 2019 年 CES 上说“摩尔定律已经结束”。今天的 GPU 极度未充分利用。即使在深度学习/训练周期中,GPU 也没有被充分利用。
以下是不同工作负载的典型 GPU 利用率数字:
空闲(刚刚启动进入 Windows 操作系统): 0-2%
一般生产任务(写作、简单浏览): 0-15%
视频播放: 15 - 35%
PC 游戏: 25 - 95%
图形设计/照片编辑主动工作负载(Photoshop、Illustrator): 15 - 55%
视频编辑(主动): 15 - 55%
视频编辑(渲染): 33 - 100%
3D渲染(CUDA / OptiX): 33 - 100% (常被 Win 任务管理器错误报告 - 使用 GPU-Z)
大多数带 GPU 的消费设备属于前三类。
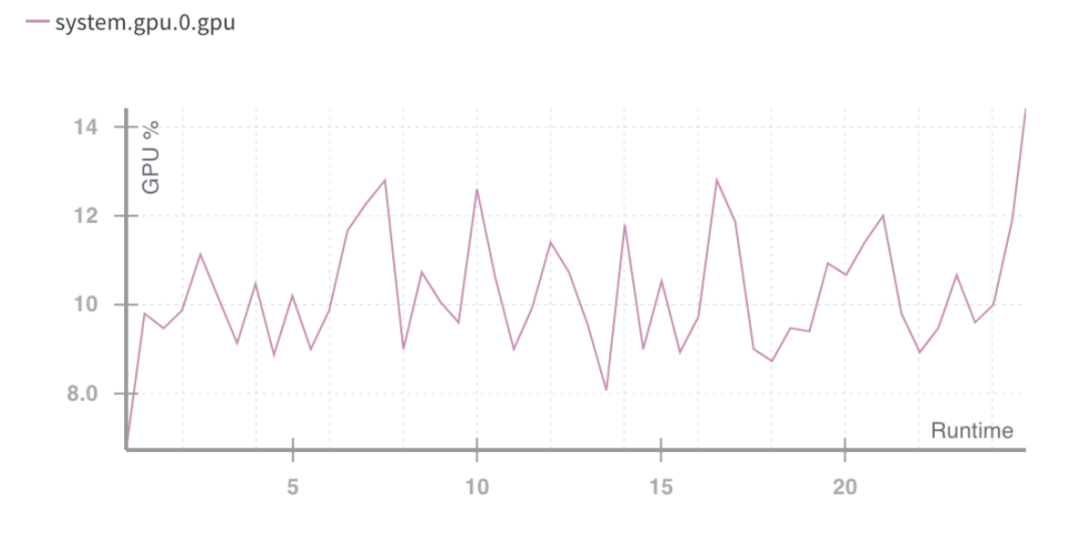
GPU 运行时利用率%。Source: Weights and Biases
上述情况指向一个问题:运算资源利用不良。
需要更好地利用消费者 GPU 的容量,即使在 GPU 利用率出现高峰时,也是次优的。这明确了未来要进行的两件事情:
资源(GPU)聚合
训练任务的并行化
可以使用的硬件类型方面,现在有 4 种类型用于供应:
· 数据中心 GPU(例如,Nvidia A 100 s)
· 消费者 GPU(例如,Nvidia RTX 3060)
· 定制 ASIC(例如,Coreweave IPU)
· 消费者 SoCs(例如,苹果 M 2)
除了 ASIC(因为它们是为特定目的而构建的),其他硬件可以被汇集以最有效地利用。随着许多这样的芯片掌握在消费者和数据中心手中,聚合供应方的 DePIN 模型可能是可行的道路。
GPU 生产是一个体量金字塔;消费级 GPU 产量最高,而像 NVIDIA A 100 s 和 H 100 s 这样的高级 GPU 产量最低(但性能更高)。生产这些高级芯片的成本是消费者 GPU 的 15 倍,但有时并不提供 15 倍的性能。
整个云计算市场今天价值约 4830 亿美元,预计未来几年将以约 27% 的复合年增长率增长。到 2023 年,将有大约 130 亿小时的 ML 计算需求,按照当前标准费率,这相当于 2023 年 ML 计算的约 560 亿美元支出。这整个市场也在迅速增长,每 3 个月增长 2 倍。
GPU 需求
计算需求主要来自 AI 开发者(研究人员和工程师)。他们的主要需求是:价格(低成本计算)、规模(大量 GPU 计算)和用户体验(易于访问和使用)。在过去两年中,由于对基于 AI 的应用程序的需求增加以及 ML 模型的发展,GPU 需求量巨大。开发和运行 ML 模型需要:
大量计算(来自访问多个 GPU 或数据中心)
能够执行模型训练、微调 ( fine tuning) 以及推理,每个任务都部署在大量 GPU 上并行执行
计算相关硬件支出预计将从 2021 年的 170 亿美元增长到 2025 年的 2850 亿美元(约 102% 的复合年增长率),ARK 预计到 2030 年计算相关硬件支出将达到 1.7 万亿美元(43% 的复合年增长率)。
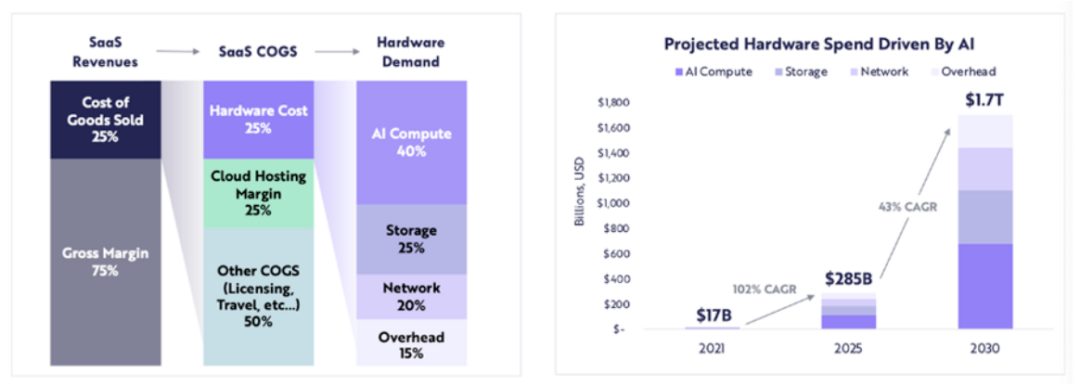
ARK Research
随着大量 LLM 处于创新阶段,竞争驱动对更多参数的计算需求,以及重新训练,我们可以预期在未来几年内对高质量计算的持续需求。
随着新的 GPU 供应紧缩,区块链在哪里发挥作用?
当使用资源不足的时候,DePIN 模型就会提供出其帮助:
启动供应方,创建大量供应
协调和完成任务
确保任务正确完成
为完成工作的提供者正确奖励
聚合任何类型的 GPU(消费者、企业、高性能等)可能会在利用方面出现问题。当计算任务被分割时,A 100 芯片不应该执行简单的计算。GPU 网络需要决定他们认为应该包括在网络中的 GPU 类型,根据他们的市场进入策略。
当计算资源本身分散(有时是全球性的)时,需要由用户或协议本身做出选择,决定将使用哪种类型的计算框架。提供者像 io.net 允许用户从 3 种计算框架中选择:Ray、Mega-Ray 或部署 Kubernetes 集群在容器中执行计算任务。还有更多分布式计算框架,如 Apache Spark,但 Ray 是最常用的。一旦所选 GPU 完成了计算任务,将重构输出以给出训练有素的模型。
一个设计良好的代币模型将为 GPU 提供者补贴计算成本,许多开发者(需求方)会发现这样的方案更有吸引力。分布式计算系统本质上具有延迟。存在计算分解和输出重构。所以开发者需要在训练模型的成本效益和所需时间之间做出权衡。
分布式计算系统需要有自己的链吗?
网络有两种运作方式:
按任务(或计算周期)收费或按时间收费
按时间单位收费
第一种方法,可以构建一个类似于 Gensyn 所尝试的工作证明链,其中不同 GPU 分担“工作”并因此获得奖励。为了更无信任的模型,他们有验证者和告密者的概念,他们因保持系统的完整性而获得奖励,这是基于解算者生成的证明。
另一个工作证明系统是 Exabits,它不是任务分割,而是将其整个 GPU 网络视为单个超级计算机。这种模型似乎更适合大型 LLM。
Akash Network 增加了 GPU 支持,并开始聚合 GPU 进入这一领域。他们有一个底层L1来就状态(显示 GPU 提供者完成的工作)达成共识,一个市场层,以及容器编排系统,如 Kubernetes 或 Docker Swarm 来管理用户应用程序的部署和扩展。
一个系统如果要是无信任,工作证明链模型将最有效。这确保了协议的协调和完整性。
另一方面,像 io.net 这样的系统并没有将自己构建为一个链。他们选择解决 GPU 可用性的核心问题,并按时间单位(每小时)向客户收费。他们不需要可验证性层,因为他们本质上是“租用”GPU,在特定租赁期内随意使用。协议本身没有任务分割,而是由开发者使用像 Ray、Mega-Ray 或 Kubernetes 这样的开源框架完成。
Web2与Web3 GPU 云
Web2在 GPU 云或 GPU 即服务领域有很多参与者。这一领域的主要玩家包括 AWS、CoreWeave、PaperSpace、Jarvis Labs、Lambda Labs、谷歌云、微软 Azure 和 OVH 云。
这是一个传统的云业务模型,客户需要计算时可以按时间单位(通常是一小时)租用 GPU(或多个 GPU)。有许多不同的解决方案适用于不同的用例。
Web2和Web3 GPU 云之间的主要区别在于以下几个参数:
1. 云设置成本
由于代币激励,建立 GPU 云的成本显著降低。OpenAI 正在筹集 1 万亿美元用于计算芯片的生产。看来在没有代币激励的情况下,打败市场领导者需要至少 1 万亿美元。
2. 计算时间
非Web3 GPU 云将会更快,因为已租用的 GPU 集群位于地理区域内,而Web3模型可能有一个更广泛分布的系统,延迟可能来自于低效的问题分割、负载平衡,最重要的是带宽。
3. 计算成本
由于代币激励,Web3计算的成本将显著低于现有的Web2模型。
计算成本对比:
当有更多供应和利用集群提供这些 GPU 时,这些数字可能会发生变化。Gensyn 声称以低至每小时 0.55 美元的价格提供 A 100 s(及其等价物),Exabits 承诺类似的成本节省结构。
4. 合规性
在无许可系统中,合规性并不容易。然而,像 io.net、Gensyn 等Web3系统并不将自己定位为无许可系统。在 GPU 上线、数据加载、数据共享和结果共享阶段处理了 GDPR 和 HIPAA 等合规性问题。
生态系统
Gensyn、io.net、Exabits、Akash
风险
1. 需求风险
我认为顶级 LLM 玩家要么会继续积累 GPU,要么会使用像 NVIDIA 的 Selene 超级计算机这样的 GPU 集群,后者的峰值性能为 2.8 exaFLOP/s。他们不会依赖消费者或长尾云提供商汇集 GPU。当前,顶级 AI 组织在质量上的竞争大于成本。
对于非重型 ML 模型,他们将寻求更便宜的计算资源,像基于区块链的代币激励 GPU 集群可以在优化现有 GPU 的同时提供服务(以上是假设:那些组织更喜欢训练自己的模型,而不是使用 LLM)
2. 供应风险
随着大量资本投入 ASIC 研究,以及像张量处理单元(TPU)这样的发明,这个 GPU 供应问题可能会自行消失。如果这些 ASIC 可以提供良好的性能:成本权衡,那么大型 AI 组织囤积的现有 GPU 可能会重新回归市场。
基于区块链的 GPU 集群是否解决了一个长期问题?虽然区块链可以支持除 GPU 之外的任何芯片,但需求方的所作所为将完全决定这一领域内项目的发展方向。
结论
拥有小型 GPU 集群的碎片化网络不会解决问题。没有“长尾”GPU 集群的位置。GPU 提供商(零售或较小的云玩家)将倾向于更大的网络,因为网络的激励更好。会是良好代币模型的功能,也是供应方支持多种计算类型的能力。
GPU 集群可能会像 CDN 一样看到类似的聚合命运。如果大型玩家要与 AWS 等现有领导者竞争,他们可能会开始共享资源,以减少网络延迟和节点的地理接近性。
如果需求方增长得更大(需要训练的模型更多,需要训练的参数数量也更多),Web3玩家必须在供应方业务发展方面非常积极。如果有太多的集群从相同的客户群中竞争,将会出现碎片化的供应(这使整个概念无效),而需求(以 TFLOPs 计)呈指数级增长。
Io.net 已经从众多竞争者中脱颖而出,以聚合器模型起步。他们已经聚合了 Render Network 和 Filecoin 矿工的 GPU,提供容量,同时也在自己的平台上引导供应。这可能是 DePIN GPU 集群的赢家方向。





