





模块化计算层 RaaS 平台 Lumoz 在刚刚结束的第三轮激励测试网中取得阶段性成果。市场层面,测试网活动获得超 100 万用户、 30 多个头部生态项目方等关注和支持,市场热度、讨论度、社区规模再创新高;技术层面,Lumoz 团队也同时对 ZK-POW 算法进行更深层次的优化,目前也取得有效突破,当前可以有效提升 ZKP 的证明效率约 50% 。
作为领先的 ZK AI 模块化计算层,Lumoz 可使用 PoW 挖矿机制有效为 Rollup、ZK-ML 和 ZKP 验证提供计算能力,其核心技术团队也一直为此不懈努力。而此次技术上的这一举措不仅有效地帮助其在当今激烈竞争的Web3 ZK 计算领域脱颖而出,同时也或为即将到来的 Lumoz ZK-POW 主网“埋下伏笔”。
以下为此次 Lumoz ZK-PoW 算法优化的具体内容:
现有验证流程改进
首先,Lumoz 所提出的两步提交算法与优化的 ZKP 生成方案在保证 ZK-PoW 机制的去中心化同时也显著提高了 ZK 证明的生成及验证效率。这在 Alpha 测试网期间已经得到了很好的验证。
而现在,经过一段时间的努力,Lumoz 团队在原有的两步提交模型基础上进行了优化,使用更加简洁的验证流程以减少验证时对于链上资源的消耗,也缩短了验证流程整体的时间。在当前流程中,整体的 Proof 验证方案仍然保留了原有的提交窗口和激励机制,但使用简化后的一次合约调用代替原有的两步验证流程。在简化后的流程中,工作者将不再需要通过 proof hash 进行身份以及任务的信息认证,而是将包含自身信息、任务信息的 proof id 聚合到生成的 zk proof 中,在合约内一次性完成验证。
通过这种方式,算力提供者只需要进行单次合约调用即可完成原有的两步验证流程,降低了 50% ~ 60% 的链上开销;同时,proof 的链上验证步骤也从原本的窗口期后提前到了窗口期开始时,达到信任状态的时间花费减少了约 30% 。
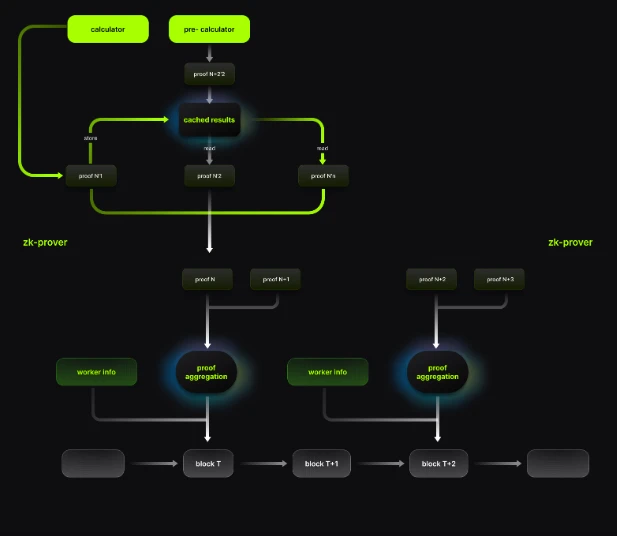
Proof 的递归与聚合
在 Plonky 系列算法的启发下,Lumoz 对 ZK-PoW 的证明生成方案进行了优化,尝试引入递归形式来提高整体证明的生成效率。在新方案中,多个证明任务的生成步骤可以并行执行,最终通过递归的方式逐步聚合为单个证明,从而以更精简的 proof、更低的验证开销对整个系统完成 ZK 验证。另一方面,通过递归形式,优化后的方案也能将单个任务进行更细粒度的划分,为更加合理、高效的算力分配提供了基础。
更合理的算力分配
在 ZK-PoW 的激励机制下,Lumoz 得以稳定维持大量 ZK 算力节点。因此,设计更加合理的算力分配机制将给网络整体的证明计算效率带来很大的提升。Lumoz 团队在这一方向也进行了研究与改进:
计算结果复用
在之前的版本中,每个证明任务的计算流程相对独立,仅仅依赖于系统当前的一些状态参数。在这个过程中,有大量计算流程是重复且冗余的。新方案使用递归的形式将单个证明任务进行成了更细粒度的划分,从而在相对独立的证明任务之间也能够找到可以相似的模块。对于这些模块,新方案将会对部分计算结果进行缓存,并在后续流程中直接复用,避免了这些大量的重复计算,极大提高了算力的利用率。
另一方面,在细粒度下,节点能够更好的对计算过程的中间值做保存,从而在异常的场景下也能够快速从断点恢复计算。
预计算
由于去中心化的性质,在 ZK-PoW 中算力的并不总是与供给完全相同。为了避免多余算力的浪费,算力节点并不总是需要等待证明任务产生之后才开始进行计算。在优化方案中,即使新的证明任务暂时没有发布,节点也会根据系统当前状态判断新的任务在更细粒度上是否可以执行一些预先的计算流程,并利用空闲资源进行计算。在证明任务发布后,节点会使用极小的开销验证预计算结果是否有效,再推进正常的计算流程。通过利用这些空闲的算力,证明的生成速度提高了 25%
总结
Lumoz 团队从三方面入手,多角度的对 ZK-PoW 方案进行了优化。对上层验证流程的改进降低了验证的链上开销,同时减少了到达信任状态的时间花费。对底层证明及算力利用方式的优化则大大减少了证明生成所需要的时间。新的优化方案在保留了原有的去中心化、市场化的 ZK 算力定价机制的同时,大幅度减少了矿工开销,并进一步提高了 ZKP 的生成效率。





