




ผู้เขียนต้นฉบับ: หยูซิง
บทความนี้มีวัตถุประสงค์เพื่อการสื่อสารและการเรียนรู้เท่านั้น และไม่ถือเป็นคำแนะนำในการลงทุนใดๆ

ความนิยมของ ChatGPT และ GPT-4 แสดงให้เราเห็นถึงพลังของปัญญาประดิษฐ์ เบื้องหลังปัญญาประดิษฐ์ นอกเหนือจากอัลกอริธึมแล้ว สิ่งที่สำคัญกว่าคือข้อมูลขนาดใหญ่ เราได้สร้างระบบที่ซับซ้อนขนาดใหญ่เกี่ยวกับข้อมูล ซึ่งส่วนใหญ่มาจากระบบธุรกิจอัจฉริยะ (ระบบธุรกิจอัจฉริยะ, BI) และปัญญาประดิษฐ์ (ปัญญาประดิษฐ์, AI) เนื่องจากปริมาณข้อมูลเติบโตอย่างรวดเร็วในยุคอินเทอร์เน็ต ความพยายามด้านโครงสร้างพื้นฐานข้อมูลและแนวปฏิบัติที่ดีที่สุดจึงมีการพัฒนาอย่างรวดเร็วเช่นกัน ในช่วงสองปีที่ผ่านมา ระบบหลักของกลุ่มเทคโนโลยีโครงสร้างพื้นฐานข้อมูลมีเสถียรภาพอย่างมาก และเครื่องมือและแอปพลิเคชันที่รองรับก็เติบโตอย่างรวดเร็วเช่นกัน
สถาปัตยกรรมโครงสร้างพื้นฐานข้อมูล Web2
คลังข้อมูลบนคลาวด์ (เช่น Snowflake ฯลฯ) กำลังเติบโตอย่างรวดเร็ว โดยมุ่งเน้นไปที่ผู้ใช้ SQL และสถานการณ์ผู้ใช้ระบบธุรกิจอัจฉริยะเป็นหลัก การนำเทคโนโลยีอื่นๆ มาใช้ก็กำลังเร่งตัวขึ้นเช่นกัน ลูกค้าของ Data Lake (เช่น Databricks) กำลังเติบโตในอัตราที่ไม่เคยเกิดขึ้นมาก่อน และความหลากหลายในกลุ่มเทคโนโลยีข้อมูลจะอยู่ร่วมกัน
ระบบข้อมูลหลักอื่นๆ เช่น การเก็บข้อมูลและการแปลง ได้รับการพิสูจน์แล้วว่ามีความทนทานไม่แพ้กัน สิ่งนี้เห็นได้ชัดเจนโดยเฉพาะอย่างยิ่งในโลกยุคใหม่ของ Data Intelligence การผสมผสานระหว่าง Fivetran และ dbt (หรือเทคโนโลยีที่คล้ายกัน) สามารถพบได้เกือบทุกที่ แต่ในระดับหนึ่ง สิ่งนี้ก็เกิดขึ้นจริงในระบบธุรกิจเช่นกัน การผสมผสานระหว่าง Databricks/Spark, Confluent/Kafka และ Astronomer/Airflow ก็เริ่มกลายเป็นมาตรฐานโดยพฤตินัยเช่นกัน
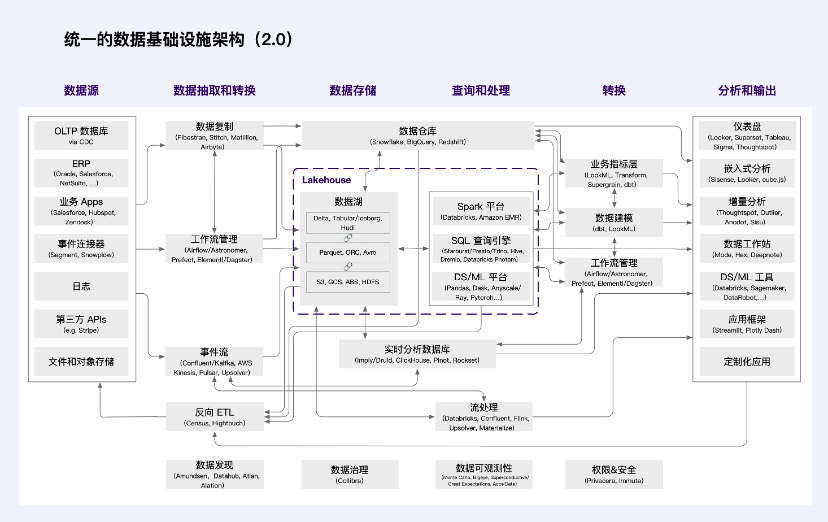
ที่มา: a16z
ใน,
แหล่งข้อมูลสร้างข้อมูลธุรกิจและธุรกิจที่เกี่ยวข้องบนเทอร์มินัล
การสกัดและการแปลงข้อมูลรับผิดชอบในการดึงข้อมูลจากระบบธุรกิจ (E) ส่งไปยังที่เก็บข้อมูล จัดรูปแบบระหว่างแหล่งข้อมูลและปลายทาง (L) และส่งข้อมูลวิเคราะห์กลับไปยังระบบธุรกิจตามที่ต้องการ
การจัดเก็บข้อมูลการจัดเก็บข้อมูลในรูปแบบที่สามารถสอบถามและประมวลผลได้นั้นจำเป็นต้องได้รับการปรับปรุงให้มีต้นทุนต่ำ ความสามารถในการขยายขนาดสูง และเวิร์กโหลดเชิงวิเคราะห์
แบบสอบถามและการประมวลผลแปลภาษาการเขียนโปรแกรมระดับสูง (โดยปกติคือ SQL, Python หรือ Java/Scala) ให้เป็นงานประมวลผลข้อมูลระดับล่าง ใช้การคำนวณแบบกระจายเพื่อดำเนินการสืบค้นและแบบจำลองข้อมูลตามข้อมูลที่เก็บไว้ รวมถึงการวิเคราะห์ในอดีต (อธิบายเหตุการณ์ที่เกิดขึ้นในอดีต) และการวิเคราะห์เชิงคาดการณ์ (อธิบายเหตุการณ์ที่คาดว่าจะเกิดขึ้นในอนาคต)
แปลงแปลงข้อมูลเป็นโครงสร้างที่ใช้สำหรับการวิเคราะห์และจัดการกระบวนการและทรัพยากร
การวิเคราะห์และผลลัพธ์โดยให้อินเทอร์เฟซแก่นักวิเคราะห์และนักวิทยาศาสตร์ข้อมูลที่สามารถติดตามข้อมูลเชิงลึกและทำงานร่วมกัน แสดงผลลัพธ์การวิเคราะห์ข้อมูลแก่ผู้ใช้ภายในและภายนอก และฝังโมเดลข้อมูลลงในแอปพลิเคชันที่มุ่งเน้นผู้ใช้
ด้วยการพัฒนาอย่างรวดเร็วของระบบนิเวศข้อมูล แนวคิดของ แพลตฟอร์มข้อมูล จึงถือกำเนิดขึ้น จากมุมมองของอุตสาหกรรม คุณลักษณะที่กำหนดของแพลตฟอร์มคือการพึ่งพาซึ่งกันและกันทางเทคโนโลยีและเศรษฐกิจของผู้ให้บริการแพลตฟอร์มที่มีอิทธิพลและนักพัฒนาบุคคลที่สามจำนวนมาก จากมุมมองของแพลตฟอร์ม กลุ่มเทคโนโลยีข้อมูลแบ่งออกเป็น “ส่วนหน้า” และ “ส่วนหลัง”
“แบ็กเอนด์” ในวงกว้างรวมถึงการแยกข้อมูล การจัดเก็บ การประมวลผล และการแปลงได้เริ่มรวมตัวกับผู้ให้บริการระบบคลาวด์จำนวนไม่มาก เป็นผลให้ข้อมูลลูกค้าถูกรวบรวมในชุดระบบมาตรฐาน และผู้จำหน่ายกำลังลงทุนมหาศาลในการทำให้นักพัฒนารายอื่นสามารถเข้าถึงข้อมูลนี้ได้อย่างง่ายดาย นี่เป็นหลักการออกแบบพื้นฐานของระบบต่างๆ เช่น Databricks และนำไปใช้ผ่านระบบต่างๆ เช่น มาตรฐาน SQL และ API การประมวลผลแบบกำหนดเอง เช่น Snowflake
วิศวกร ส่วนหน้า ใช้ประโยชน์จากการบูรณาการจุดเดียวนี้เพื่อสร้างแอปพลิเคชันใหม่ๆ ที่หลากหลายพวกเขาพึ่งพาข้อมูลที่สะอาดและบูรณาการในคลังข้อมูล/ทะเลสาบโดยไม่ต้องกังวลกับรายละเอียดพื้นฐานของวิธีการสร้างข้อมูล ลูกค้ารายเดียวสามารถสร้างและซื้อแอปพลิเคชันจำนวนมากนอกเหนือจากระบบข้อมูลหลักได้ เรายังเริ่มเห็นระบบองค์กรแบบเดิม เช่น การเงินหรือการวิเคราะห์ผลิตภัณฑ์ ได้รับการปรับโครงสร้างใหม่โดยใช้สถาปัตยกรรมแบบเนทิฟคลังสินค้า
ในขณะที่กลุ่มเทคโนโลยีข้อมูลค่อยๆ เติบโต การใช้งานข้อมูลบนแพลตฟอร์มข้อมูลก็แพร่หลายเช่นกัน ผลจากการกำหนดมาตรฐาน การนำแพลตฟอร์มข้อมูลใหม่ๆ มาใช้ไม่เคยมีความสำคัญเท่านี้มาก่อน และการดูแลรักษาแพลตฟอร์มตามนั้นจึงมีความสำคัญอย่างยิ่ง ในวงกว้าง แพลตฟอร์มสามารถมีคุณค่าอย่างยิ่ง ปัจจุบัน มีการแข่งขันที่รุนแรงระหว่างผู้จำหน่ายระบบข้อมูลหลัก ไม่ใช่แค่สำหรับธุรกิจปัจจุบันเท่านั้น แต่ยังรวมถึงสถานะแพลตฟอร์มในระยะยาวด้วย การประเมินมูลค่าที่น่าตกใจสำหรับบริษัทการได้มาและการแปลงข้อมูลจะเข้าใจได้ง่ายขึ้น หากคุณพิจารณาว่าโมดูลการได้มาและการแปลงข้อมูลเป็นส่วนสำคัญของแพลตฟอร์มข้อมูลที่เกิดขึ้นใหม่
อย่างไรก็ตาม กลุ่มเทคโนโลยีเหล่านี้ถูกสร้างขึ้นภายใต้แนวทางการใช้ข้อมูลซึ่งครอบงำโดยบริษัทขนาดใหญ่ เมื่อสังคมเข้าใจข้อมูลอย่างลึกซึ้งมากขึ้น ผู้คนก็เชื่อว่าข้อมูล เช่น ที่ดิน แรงงาน ทุน และเทคโนโลยี เป็นปัจจัยการผลิตที่ตลาดสามารถจัดสรรได้ ข้อมูลเป็นหนึ่งในปัจจัยการผลิตหลักห้าประการ และสิ่งที่สะท้อนให้เห็นเบื้องหลังคือมูลค่าทรัพย์สินของข้อมูล
เพื่อให้ทราบถึงการกำหนดค่าของตลาดองค์ประกอบข้อมูล กลุ่มเทคโนโลยีในปัจจุบันยังห่างไกลจากความต้องการ ในสาขา Web3 ซึ่งมีการบูรณาการอย่างใกล้ชิดกับเทคโนโลยีบล็อกเชน โครงสร้างพื้นฐานข้อมูลใหม่กำลังพัฒนาและพัฒนา โครงสร้างพื้นฐานเหล่านี้จะถูกฝังอยู่ในสถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลสมัยใหม่ เพื่อให้บรรลุถึงคำจำกัดความของสิทธิ์ในทรัพย์สินของข้อมูล ธุรกรรมการหมุนเวียน การกระจายรายได้ และการกำกับดูแลปัจจัย ประเด็นทั้งสี่นี้มีความสำคัญอย่างยิ่งจากมุมมองของหน่วยงานกำกับดูแลของรัฐบาล ดังนั้นจึงจำเป็นต้องได้รับการดูแลเป็นพิเศษ
สถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลไฮบริด Web3
ได้รับแรงบันดาลใจจากสถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลแบบรวม a16z (2.0) และบูรณาการความเข้าใจเกี่ยวกับสถาปัตยกรรมโครงสร้างพื้นฐาน Web3 เราขอเสนอสถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลไฮบริด Web3 ต่อไปนี้
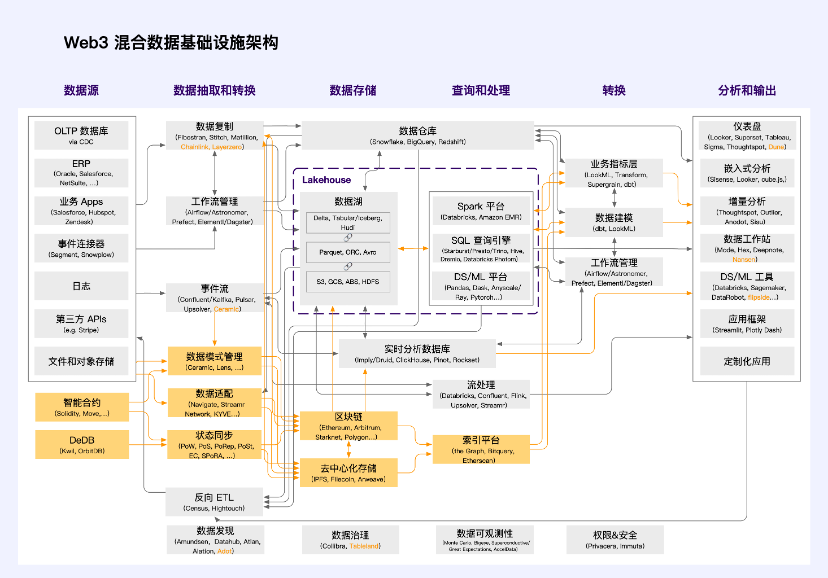
Orange เป็นหน่วยสแต็กเทคโนโลยีที่เป็นเอกลักษณ์ของ Web3 เนื่องจากเทคโนโลยีการกระจายอำนาจยังอยู่ในช่วงเริ่มต้นของการพัฒนา แอปพลิเคชันส่วนใหญ่ในสาขา Web3 ยังคงใช้สถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลแบบไฮบริดนี้ การใช้งานส่วนใหญ่ไม่ใช่ โครงสร้างส่วนบน อย่างแท้จริง โครงสร้างส่วนบนมีคุณลักษณะที่ไม่อาจหยุดยั้งได้ เป็นอิสระ มีคุณค่า ปรับขนาดได้ ไม่ได้รับอนุญาต มีปัจจัยภายนอกเชิงบวก และความเป็นกลางที่น่าเชื่อถือ มันมีอยู่ในฐานะสาธารณประโยชน์ในโลกดิจิทัลและเป็นโครงสร้างพื้นฐานสาธารณะของโลก Metaverse สิ่งนี้ต้องการสถาปัตยกรรมพื้นฐานที่มีการกระจายอำนาจอย่างสมบูรณ์เพื่อรองรับ
สถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลแบบดั้งเดิมได้รับการพัฒนาตามการพัฒนาธุรกิจขององค์กร a16z สรุปออกเป็นสองระบบ (ระบบการวิเคราะห์และระบบธุรกิจ) และสามสถานการณ์ (ระบบธุรกิจอัจฉริยะสมัยใหม่ การประมวลผลข้อมูลหลายรูปแบบ และปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง) นี่คือบทสรุปจากมุมมองขององค์กร - ข้อมูลรองรับการพัฒนาขององค์กร
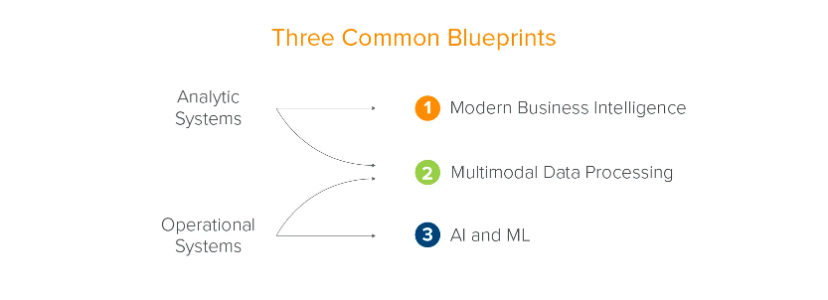
ที่มา: a16z
อย่างไรก็ตาม ไม่ใช่แค่ธุรกิจ สังคม และบุคคลเท่านั้นที่ควรได้รับประโยชน์จากประสิทธิภาพการทำงานที่เพิ่มขึ้นจากองค์ประกอบข้อมูล ประเทศต่างๆ ทั่วโลกได้นำเสนอนโยบายและกฎระเบียบทีละแห่ง โดยหวังว่าจะสร้างมาตรฐานการใช้ข้อมูลจากระดับกฎระเบียบและส่งเสริมการหมุนเวียนของข้อมูล ซึ่งรวมถึงธนาคารข้อมูลต่างๆ ที่พบเห็นได้ทั่วไปในญี่ปุ่น การแลกเปลี่ยนข้อมูลที่เพิ่งเกิดขึ้นในประเทศจีน และแพลตฟอร์มการซื้อขายที่ใช้กันอย่างแพร่หลายในยุโรปและสหรัฐอเมริกา เช่น BDEX (สหรัฐอเมริกา), Streamr (สวิตเซอร์แลนด์), DAWEX (ฝรั่งเศส) , คารูโซ ฯลฯ
เมื่อข้อมูลเริ่มกำหนดสิทธิในทรัพย์สิน ธุรกรรมการไหล การกระจายรายได้ และการกำกับดูแล ระบบและสถานการณ์จะไม่เพียงแต่เสริมศักยภาพในการตัดสินใจและการพัฒนาธุรกิจของบริษัทเท่านั้น ระบบและสถานการณ์เหล่านี้ต้องการความช่วยเหลือจากเทคโนโลยีบล็อกเชนหรือต้องอาศัยการกำกับดูแลนโยบายเป็นอย่างมาก
Web3 เป็นดินธรรมชาติสำหรับตลาดปัจจัยข้อมูล ในทางเทคนิคแล้ว จะช่วยลดความเป็นไปได้ของการโกง ลดแรงกดดันด้านกฎระเบียบอย่างมาก และช่วยให้ข้อมูลมีอยู่เป็นปัจจัยการผลิตจริงและได้รับการกำหนดค่าในลักษณะที่มุ่งเน้นตลาด
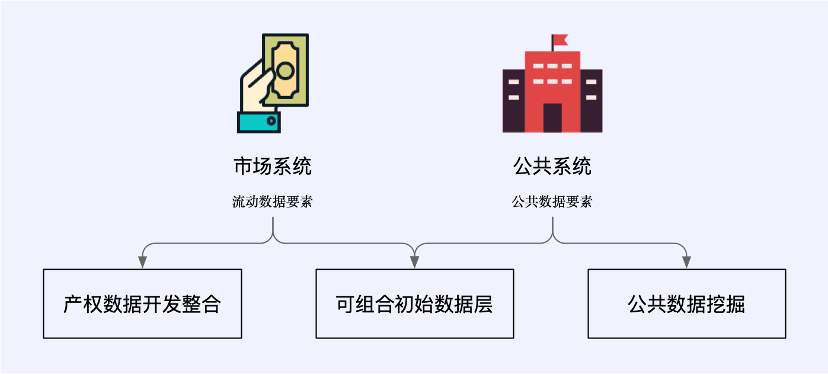
ในบริบทของ Web3 กระบวนทัศน์ใหม่ของการใช้ข้อมูลประกอบด้วยระบบตลาดที่มีองค์ประกอบข้อมูลที่ไหลลื่น และระบบสาธารณะที่จัดการองค์ประกอบข้อมูลสาธารณะ โดยครอบคลุมถึงสถานการณ์ทางธุรกิจข้อมูลใหม่สามสถานการณ์: การบูรณาการการพัฒนาข้อมูลสิทธิในทรัพย์สิน ชั้นข้อมูลเริ่มต้นที่ประกอบได้ และการขุดข้อมูลสาธารณะ
สถานการณ์เหล่านี้บางส่วนมีการบูรณาการอย่างใกล้ชิดกับโครงสร้างพื้นฐานข้อมูลแบบดั้งเดิมและเป็นของสถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลแบบไฮบริด Web3 บางส่วนถูกแยกออกจากสถาปัตยกรรมแบบดั้งเดิมและได้รับการสนับสนุนอย่างสมบูรณ์โดยเทคโนโลยีใหม่ที่มีต้นกำเนิดจาก Web3
Web3 และเศรษฐกิจข้อมูล
ตลาดเศรษฐกิจข้อมูลเป็นกุญแจสำคัญในการกำหนดค่าองค์ประกอบข้อมูล รวมถึงการพัฒนาและบูรณาการข้อมูลผลิตภัณฑ์และตลาดชั้นข้อมูลเริ่มแรกที่มีความสามารถในการประกอบ ในตลาดเศรษฐกิจข้อมูลที่มีประสิทธิภาพและเป็นไปตามข้อกำหนด ประเด็นต่อไปนี้มีความสำคัญมาก:
สิทธิ์ในทรัพย์สินของข้อมูลเป็นกุญแจสำคัญในการปกป้องสิทธิและผลประโยชน์และการใช้งานที่เป็นไปตามข้อกำหนด ควรมีการจัดสรรและกำจัดอย่างมีโครงสร้าง ขณะเดียวกัน การใช้ข้อมูลจำเป็นต้องยืนยันกลไกการอนุญาต ผู้เข้าร่วมแต่ละคนควรมีสิทธิและผลประโยชน์ที่เกี่ยวข้อง
ธุรกรรมหมุนเวียนจำเป็นต้องมีการบูรณาการทั้งในและนอกสถานที่ รวมถึงการปฏิบัติตามกฎระเบียบและประสิทธิภาพ ควรเป็นไปตามหลักการสี่ประการของแหล่งข้อมูลที่ยืนยันได้ ขอบเขตการใช้งานที่กำหนดได้ กระบวนการหมุนเวียนที่ติดตามได้ และความเสี่ยงด้านความปลอดภัยที่สามารถป้องกันได้
ระบบกระจายรายได้ต้องมีประสิทธิภาพและเป็นธรรม ตามหลักการของ ใครก็ตามที่ลงทุน ใครมีส่วนร่วม ใครได้รับประโยชน์ รัฐบาลยังสามารถมีบทบาทชี้แนะและกำกับดูแลในการกระจายรายได้จากองค์ประกอบข้อมูลได้
การกำกับดูแลปัจจัยมีความปลอดภัย ควบคุมได้ ยืดหยุ่น และครอบคลุมสิ่งนี้จำเป็นต้องสร้างนวัตกรรมกลไกการกำกับดูแลข้อมูลของรัฐบาลการสร้างระบบเครดิตตลาดองค์ประกอบข้อมูลและส่งเสริมให้องค์กรต่างๆมีส่วนร่วมอย่างแข็งขันในการสร้างตลาดองค์ประกอบข้อมูล โดยมุ่งเน้นไปที่แหล่งข้อมูล สิทธิ์ในทรัพย์สินของข้อมูล คุณภาพข้อมูล การใช้ข้อมูล ฯลฯ เราจำเป็นต้องส่งเสริมผู้จำหน่ายข้อมูลและองค์กรบริการระดับมืออาชีพของบุคคลที่สาม งบธุรกรรม การหมุนเวียนข้อมูลและระบบความมุ่งมั่น
หลักการข้างต้นเป็นหลักการพื้นฐานสำหรับหน่วยงานกำกับดูแลในการพิจารณาเศรษฐกิจข้อมูล ในสามสถานการณ์ของการพัฒนาและบูรณาการข้อมูลสิทธิในทรัพย์สิน ชั้นข้อมูลเริ่มต้นที่ประกอบได้ และการขุดข้อมูลสาธารณะ เราสามารถคิดตามหลักการเหล่านี้ เราจำเป็นต้องมีโครงสร้างพื้นฐานอะไรบ้างเพื่อรองรับ? โครงสร้างพื้นฐานเหล่านี้สามารถเก็บมูลค่าได้เท่าใดในขั้นตอนใด
สถานการณ์ที่ 1: การพัฒนาและบูรณาการข้อมูลสิทธิในทรัพย์สิน
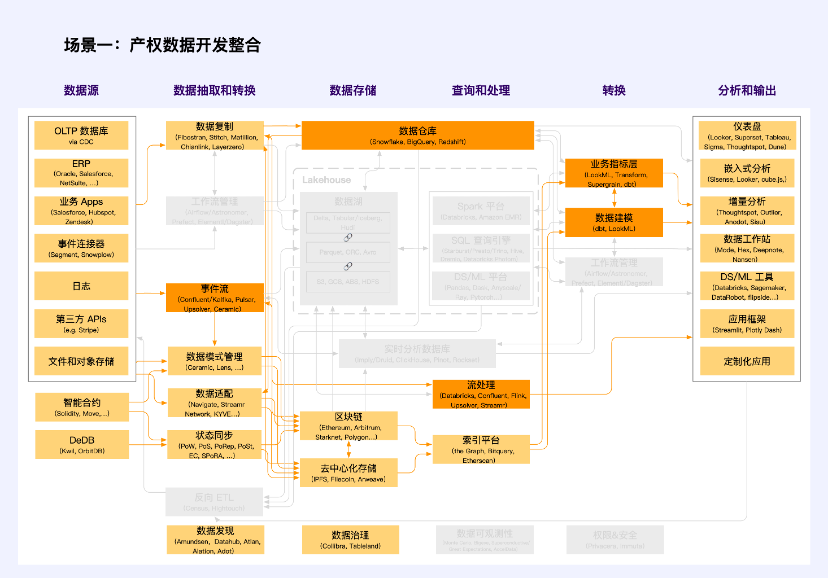
หมายเหตุ: สีส้มเป็นหน่วยที่ Web2 และ Web3 ตัดกัน
ในกระบวนการพัฒนาข้อมูลสิทธิในทรัพย์สิน จำเป็นต้องสร้างกลไกการยืนยันและการอนุญาตสิทธิ์แบบจำแนกและแบบลำดับชั้น เพื่อกำหนดความเป็นเจ้าของ สิทธิ์การใช้งาน และสิทธิ์ในการดำเนินงานของข้อมูลสาธารณะ ข้อมูลองค์กร และข้อมูลส่วนบุคคล ตามแหล่งข้อมูลและคุณลักษณะการสร้าง สิทธิ์ในทรัพย์สินของข้อมูลถูกกำหนดผ่าน การปรับข้อมูล ในโครงการทั่วไป ได้แก่ Navigate, Streamr Network และ KYVE เป็นต้น โครงการเหล่านี้บรรลุมาตรฐานคุณภาพข้อมูล การรวบรวมข้อมูลและการกำหนดมาตรฐานอินเทอร์เฟซผ่านวิธีการทางเทคนิค ยืนยันสิทธิ์ของข้อมูลนอกเครือข่ายในบางรูปแบบ และดำเนินการจำแนกข้อมูลและการอนุญาตตามลำดับชั้นผ่านสัญญาอัจฉริยะหรือระบบลอจิกภายใน
ประเภทข้อมูลที่เกี่ยวข้องในสถานการณ์นี้คือข้อมูลที่ไม่เปิดเผยต่อสาธารณะ กล่าวคือ ข้อมูลองค์กรและข้อมูลส่วนบุคคล คุณค่าขององค์ประกอบข้อมูลควรเปิดใช้งานในลักษณะที่มุ่งเน้นตลาดผ่าน การใช้ร่วมกันและผลประโยชน์ร่วมกัน
ข้อมูลองค์กรประกอบด้วยข้อมูลที่รวบรวมและประมวลผลโดยหน่วยงานตลาดต่างๆ ในการผลิตและกิจกรรมทางธุรกิจที่ไม่เกี่ยวข้องกับข้อมูลส่วนบุคคลและผลประโยชน์สาธารณะ หน่วยงานในตลาดมีสิทธิที่จะถือครอง ใช้ และรับรายได้ตามกฎหมายและข้อบังคับ เช่นเดียวกับสิทธิในการได้รับผลตอบแทนที่สมเหตุสมผลสำหรับค่าแรงและเงินสมทบปัจจัยอื่น ๆ
ข้อมูลส่วนบุคคลกำหนดให้ผู้ประมวลผลข้อมูลรวบรวม เก็บรักษา โฮสต์ และใช้ข้อมูลตามกฎหมายและข้อบังคับภายในขอบเขตของการอนุญาตส่วนบุคคล ใช้วิธีการทางเทคโนโลยีที่เป็นนวัตกรรมเพื่อส่งเสริมการไม่เปิดเผยข้อมูลส่วนบุคคลและรับรองความปลอดภัยของข้อมูลและความเป็นส่วนตัวส่วนบุคคลเมื่อใช้ข้อมูลส่วนบุคคล สำรวจกลไกสำหรับผู้ดูแลผลประโยชน์เพื่อเป็นตัวแทนผลประโยชน์ส่วนบุคคล และควบคุมดูแลการรวบรวม การประมวลผล และการใช้ข้อมูลส่วนบุคคลโดยหน่วยงานในตลาด สำหรับข้อมูลส่วนบุคคลพิเศษ ข้อมูลที่เกี่ยวข้องกับความมั่นคงของชาติ หน่วยงานที่เกี่ยวข้องสามารถได้รับอนุญาตให้ใช้ข้อมูลดังกล่าวได้ตามกฎหมายและข้อบังคับ
สถานการณ์ที่ 2: ชั้นข้อมูลเริ่มต้นที่ประกอบได้
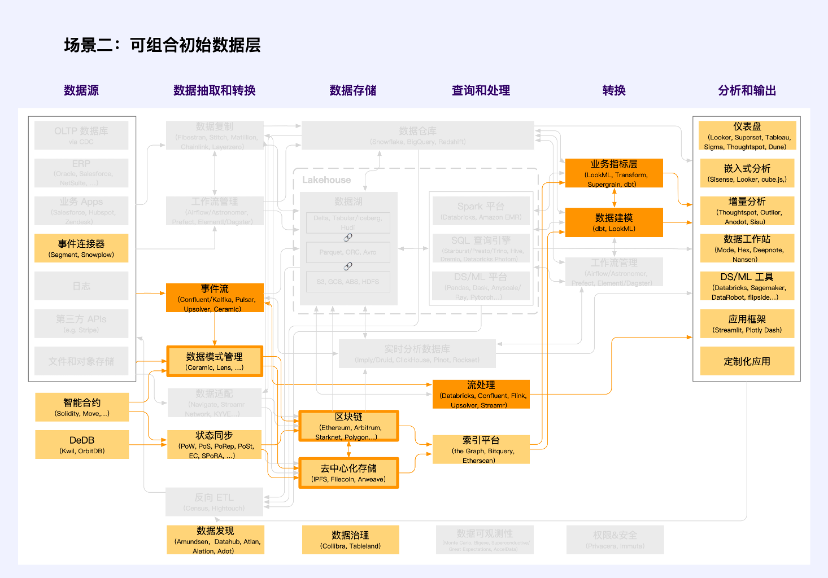
หมายเหตุ: สีส้มเป็นหน่วยที่ Web2 และ Web3 ตัดกัน
ชั้นข้อมูลเริ่มต้นที่ประกอบได้เป็นส่วนสำคัญของตลาดเศรษฐกิจข้อมูล แตกต่างจากข้อมูลสิทธิในทรัพย์สินทั่วไป คุณลักษณะที่ชัดเจนที่สุดของข้อมูลส่วนนี้คือความจำเป็นในการกำหนดรูปแบบมาตรฐานของข้อมูลผ่าน การจัดการสคีมาข้อมูล แตกต่างจากคุณภาพ การรวบรวม และมาตรฐานอินเทอร์เฟซของ การปรับข้อมูล จุดเน้นที่นี่คือการสร้างมาตรฐานของรูปแบบข้อมูล รวมถึงรูปแบบข้อมูลมาตรฐานและแบบจำลองข้อมูลมาตรฐาน Ceramic และ Lens เป็นผู้บุกเบิกในสาขานี้ ซึ่งรับประกันโหมดมาตรฐานสำหรับข้อมูลแบบ off-chain (การกระจายอำนาจ) และข้อมูล on-chain ตามลำดับ ทำให้สามารถประกอบข้อมูลได้
สร้างขึ้นจากเครื่องมือการจัดการสคีมาข้อมูลเหล่านี้คือชั้นข้อมูลเริ่มต้นที่เขียนได้ ซึ่งมักเรียกว่า ชั้นข้อมูล เช่น Cyberconnect, KNN 3 เป็นต้น
ชั้นข้อมูลเริ่มต้นที่จัดวางได้ไม่ค่อยเกี่ยวข้องกับสแต็กเทคโนโลยี Web2 แต่เครื่องมืออ่านข้อมูลร้อนที่ใช้ Ceramic ทำลายสิ่งนี้ ซึ่งจะเป็นการพัฒนาครั้งสำคัญอย่างยิ่ง ข้อมูลที่คล้ายกันจำนวนมากไม่จำเป็นต้องจัดเก็บไว้ในบล็อกเชน และเป็นเรื่องยากที่จะจัดเก็บไว้ในบล็อกเชน แต่จำเป็นต้องจัดเก็บไว้ในเครือข่ายแบบกระจายอำนาจ เช่น โพสต์ของผู้ใช้ การถูกใจและความคิดเห็น ฯลฯ ด้วยความถี่สูงและต่ำ ความหนาแน่นของค่า Data, Ceramic จัดทำกระบวนทัศน์การจัดเก็บข้อมูลสำหรับข้อมูลประเภทนี้
ข้อมูลเริ่มต้นที่รวบรวมได้ถือเป็นสถานการณ์สำคัญสำหรับนวัตกรรมในยุคใหม่ และเป็นสัญลักษณ์สำคัญของการสิ้นสุดของอำนาจครองข้อมูลและการผูกขาดข้อมูล สามารถแก้ปัญหา Cold Start ของสตาร์ทอัพในแง่ของข้อมูล และรวมชุดข้อมูลที่ครบกำหนดและชุดข้อมูลใหม่ ซึ่งช่วยให้สตาร์ทอัพสามารถสร้างความได้เปรียบในการแข่งขันด้านข้อมูลได้เร็วขึ้น ในเวลาเดียวกัน สตาร์ทอัพได้รับอนุญาตให้มุ่งเน้นไปที่มูลค่าของข้อมูลที่เพิ่มขึ้นและความใหม่ของข้อมูล ดังนั้นจึงได้รับความสามารถในการแข่งขันอย่างต่อเนื่องสำหรับแนวคิดเชิงนวัตกรรมของพวกเขา ด้วยวิธีนี้ ข้อมูลจำนวนมากจะไม่กลายเป็นอุปสรรคสำหรับบริษัทขนาดใหญ่
สถานการณ์ที่ 3: การทำเหมืองข้อมูลสาธารณะ
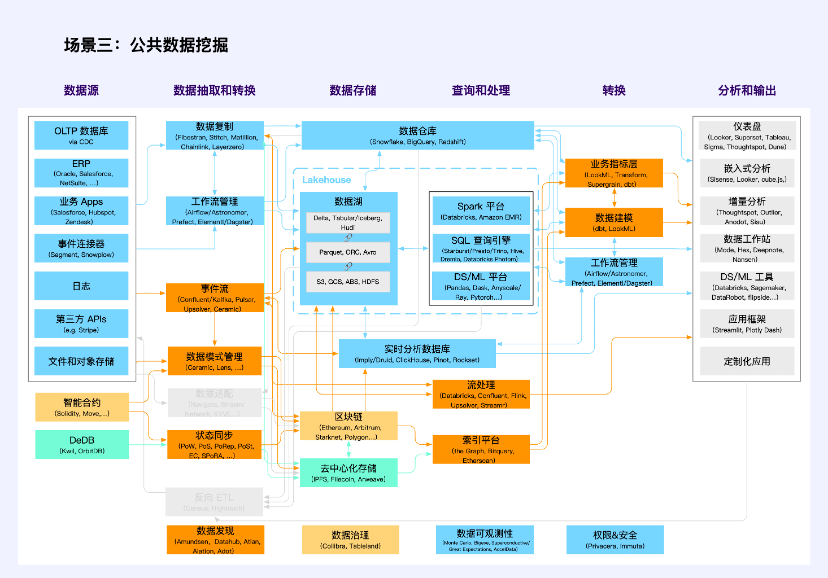
หมายเหตุ: สีส้มเป็นหน่วยทางแยกที่มีหลายหมวดหมู่
การทำเหมืองข้อมูลสาธารณะไม่ใช่สถานการณ์ใหม่ของแอปพลิเคชัน แต่ในกลุ่มเทคโนโลยี Web3 ได้รับการเน้นย้ำอย่างที่ไม่เคยมีมาก่อน
ข้อมูลสาธารณะแบบดั้งเดิมรวมถึงข้อมูลสาธารณะที่สร้างขึ้นโดยพรรคและหน่วยงานภาครัฐ องค์กร และสถาบัน เมื่อปฏิบัติหน้าที่ตามกฎหมายหรือให้บริการสาธารณะ หน่วยงานกำกับดูแลสนับสนุนให้มีการให้ข้อมูลดังกล่าวแก่สังคมในรูปแบบของแบบจำลอง การตรวจสอบ และผลิตภัณฑ์และบริการอื่น ๆ ตามข้อกำหนดของ ข้อมูลต้นฉบับไม่ออกจากโดเมนและข้อมูลมีอยู่และมองไม่เห็น บนสถานที่ตั้งของ ปกป้องความเป็นส่วนตัวและรับรองความปลอดภัยของสาธารณะ พวกเขาใช้สแต็คเทคโนโลยีแบบดั้งเดิม (สีน้ำเงินและสีส้มบางส่วน สีส้มแสดงถึงจุดตัดของสแต็คเทคโนโลยีหลายประเภท เหมือนด้านล่าง)
ใน Web3 ข้อมูลธุรกรรมและข้อมูลกิจกรรมบนบล็อกเชนเป็นข้อมูลสาธารณะอีกประเภทหนึ่งซึ่งมีลักษณะ พร้อมใช้งานและมองเห็นได้ ดังนั้นพวกเขาจึงขาดความเป็นส่วนตัวของข้อมูลความปลอดภัยของข้อมูลและความสามารถในการยืนยันการอนุญาตในการใช้ข้อมูลและเป็นอย่างแท้จริง สินค้าสาธารณะ. พวกเขาใช้กลุ่มเทคโนโลยี (สีเหลืองและสีส้มบางส่วน) โดยมีบล็อคเชนและสัญญาอัจฉริยะเป็นแกนหลัก
ข้อมูลบนพื้นที่จัดเก็บแบบกระจายอำนาจส่วนใหญ่เป็นข้อมูลแอปพลิเคชัน Web3 ที่ไม่ใช่ธุรกรรม ปัจจุบัน ส่วนใหญ่จะเป็นพื้นที่จัดเก็บไฟล์และอ็อบเจ็กต์ และกลุ่มเทคโนโลยีที่เกี่ยวข้องยังไม่สมบูรณ์ (สีเขียวและสีส้มบางส่วน) ปัญหาทั่วไปในการผลิตและการขุดข้อมูลสาธารณะดังกล่าว ได้แก่ การจัดเก็บข้อมูลร้อนและเย็น การทำดัชนี การซิงโครไนซ์สถานะ การจัดการสิทธิ์และการคำนวณ ฯลฯ
แอปพลิเคชันข้อมูลจำนวนมากเกิดขึ้นในสถานการณ์นี้ ซึ่งไม่ใช่โครงสร้างพื้นฐานของข้อมูล แต่เป็นเครื่องมือข้อมูลเพิ่มเติม รวมถึง Nansen, Dune, NFTScan, 0x Scope และอื่นๆ
กรณี: การแลกเปลี่ยนข้อมูล
การแลกเปลี่ยนข้อมูลหมายถึงแพลตฟอร์มสำหรับการซื้อขายข้อมูลในฐานะสินค้าโภคภัณฑ์ สามารถจำแนกประเภทและเปรียบเทียบตามวัตถุประสงค์ของธุรกรรม กลไกการกำหนดราคา การประกันคุณภาพ ฯลฯ DataStreamX, Dawex และ Ocean Protocol เป็นการแลกเปลี่ยนข้อมูลทั่วไปหลายอย่างในตลาด
Ocean Protocol (มูลค่าตลาด 200 ล้าน) เป็นโปรโตคอลโอเพ่นซอร์สที่ออกแบบมาเพื่อให้ธุรกิจและบุคคลสามารถแลกเปลี่ยนและสร้างรายได้จากข้อมูลและบริการที่อิงตามข้อมูล โปรโตคอลนี้ใช้บล็อกเชน Ethereum และใช้ datatoken เพื่อควบคุมการเข้าถึงชุดข้อมูล โทเค็นข้อมูลเป็นโทเค็น ERC 20 พิเศษที่แสดงถึงความเป็นเจ้าของหรือสิทธิ์การใช้งานชุดข้อมูลหรือบริการข้อมูล ผู้ใช้สามารถซื้อหรือรับโทเค็นข้อมูลเพื่อรับข้อมูลที่ต้องการได้
สถาปัตยกรรมทางเทคนิคของพิธีสารมหาสมุทรประกอบด้วยส่วนต่างๆ ดังต่อไปนี้เป็นหลัก:
ผู้ให้บริการ: หมายถึงซัพพลายเออร์ที่ให้บริการข้อมูลหรือข้อมูล พวกเขาสามารถออก และขายโทเค็นข้อมูลของตนเองผ่าน Ocean Protocol เพื่อหารายได้
ผู้บริโภค: หมายถึงผู้เรียกร้องที่ซื้อและใช้บริการข้อมูลหรือข้อมูล โดยสามารถซื้อหรือรับโทเค็นข้อมูลที่จำเป็นผ่าน Ocean Protocol เพื่อรับสิทธิ์ในการเข้าถึง
ตลาดซื้อขาย: หมายถึงตลาดซื้อขายข้อมูลที่เปิดกว้าง โปร่งใส และยุติธรรม ซึ่งจัดทำโดย Ocean Protocol หรือบุคคลที่สาม ซึ่งสามารถเชื่อมโยงผู้ให้บริการและผู้บริโภคทั่วโลก และจัดหาโทเค็นข้อมูลในประเภทและสาขาต่างๆ ตลาดสามารถช่วยให้องค์กรค้นพบโอกาสทางธุรกิจใหม่ๆ เพิ่มแหล่งรายได้ เพิ่มประสิทธิภาพการดำเนินงาน และสร้างมูลค่าเพิ่ม
เครือข่าย: หมายถึงเลเยอร์เครือข่ายแบบกระจายอำนาจที่จัดทำโดย Ocean Protocol ซึ่งสามารถรองรับการแลกเปลี่ยนข้อมูลประเภทและขนาดต่างๆ และรับประกันความปลอดภัย ความน่าเชื่อถือ และความโปร่งใสในกระบวนการธุรกรรมข้อมูล เลเยอร์เครือข่ายคือชุดของสัญญาอัจฉริยะที่ใช้ในการลงทะเบียนข้อมูล บันทึกข้อมูลการเป็นเจ้าของ อำนวยความสะดวกในการแลกเปลี่ยนข้อมูลที่ปลอดภัย และอื่นๆ
Curator หมายถึง บทบาทในระบบนิเวศที่รับผิดชอบในการคัดกรอง จัดการ และตรวจสอบชุดข้อมูล โดยมีหน้าที่ตรวจสอบแหล่งที่มา เนื้อหา รูปแบบ และข้อมูลใบอนุญาตของชุดข้อมูลเพื่อให้แน่ใจว่าชุดข้อมูลเป็นไปตามมาตรฐาน และสามารถ ได้รับความไว้วางใจและใช้งานโดยผู้ใช้รายอื่น
ผู้ตรวจสอบ: หมายถึงบทบาทในระบบนิเวศที่รับผิดชอบในการตรวจสอบและตรวจสอบธุรกรรมข้อมูลและบริการข้อมูล พวกเขาตรวจสอบและตรวจสอบธุรกรรมระหว่างผู้ให้บริการข้อมูลและผู้บริโภคเพื่อให้มั่นใจในคุณภาพ ความพร้อมใช้งาน และคุณภาพของบริการข้อมูล ความถูกต้อง
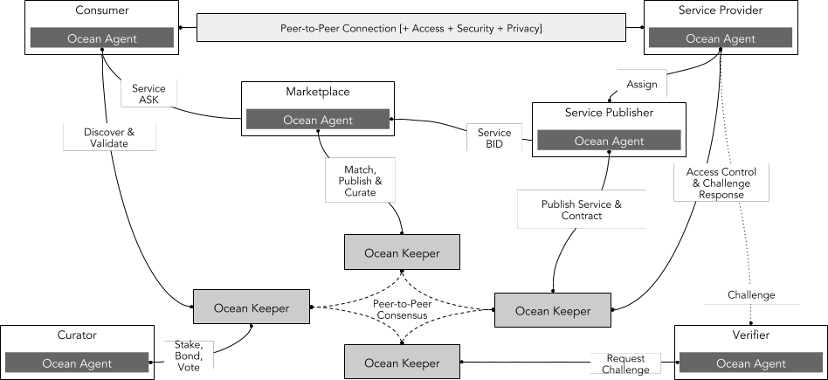
ที่มา: พิธีสารมหาสมุทร
บริการข้อมูล ที่สร้างขึ้นโดยผู้ให้บริการข้อมูล ได้แก่ ข้อมูล อัลกอริธึม การคำนวณ การจัดเก็บ การวิเคราะห์ และการดูแลจัดการ ส่วนประกอบเหล่านี้เชื่อมโยงกับข้อตกลงการดำเนินการของบริการ (เช่น ข้อตกลงระดับการให้บริการ) การคำนวณความปลอดภัย การควบคุมการเข้าถึง และการอนุญาต โดยพื้นฐานแล้ว นี่คือการควบคุมการเข้าถึง ชุดบริการคลาวด์ ผ่านสัญญาอัจฉริยะ
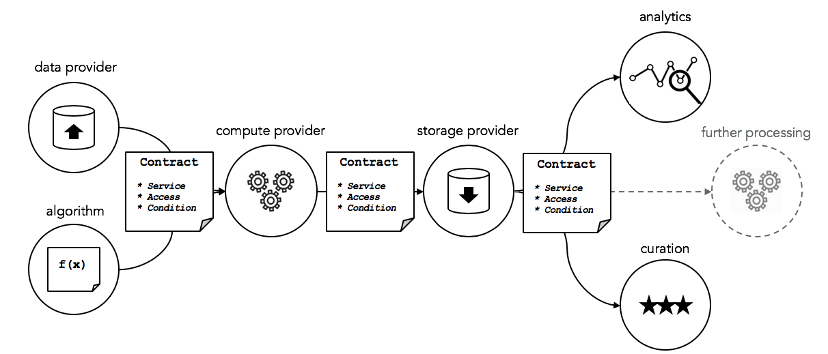
ที่มา: พิธีสารมหาสมุทร
ข้อดีคือ
โปรโตคอลโอเพ่นซอร์ส ยืดหยุ่นและขยายได้ช่วยให้องค์กรและบุคคลสร้างระบบนิเวศข้อมูลที่เป็นเอกลักษณ์ของตนเอง
เลเยอร์เครือข่ายแบบกระจายอำนาจที่ใช้เทคโนโลยีบล็อกเชนสามารถรับประกันความปลอดภัย ความน่าเชื่อถือ และความโปร่งใสในกระบวนการธุรกรรมข้อมูล ในขณะเดียวกันก็ปกป้องความเป็นส่วนตัวและสิทธิ์ของผู้ให้บริการและผู้บริโภคด้วย
ตลาดข้อมูลที่เปิดกว้าง โปร่งใส และยุติธรรมสามารถเชื่อมโยงผู้ให้บริการและผู้บริโภคทั่วโลก และมอบโทเค็นข้อมูลในหลายประเภทและสาขาต่างๆ
Ocean Protocol เป็นตัวอย่างทั่วไปของสถาปัตยกรรมไฮบริด ข้อมูลสามารถจัดเก็บไว้ในที่ต่างๆ ได้ รวมถึงบริการจัดเก็บข้อมูลบนคลาวด์แบบดั้งเดิม เครือข่ายการจัดเก็บแบบกระจายอำนาจ หรือเซิร์ฟเวอร์ของผู้ให้บริการข้อมูลเอง โปรโตคอลระบุและจัดการความเป็นเจ้าของข้อมูลและสิทธิ์การเข้าถึงผ่านโทเค็นข้อมูลและ NFT ข้อมูล นอกจากนี้ โปรโตคอลยังมีฟังก์ชันการคำนวณต่อข้อมูล ช่วยให้ผู้บริโภคข้อมูลสามารถวิเคราะห์และประมวลผลข้อมูลโดยไม่ต้องเปิดเผยข้อมูลต้นฉบับ
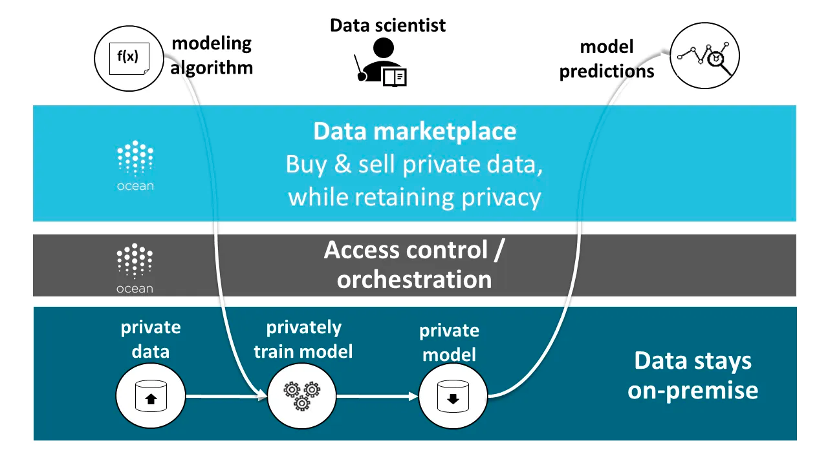
ที่มา: พิธีสารมหาสมุทร
แม้ว่า Ocean Protocol จะเป็นหนึ่งในแพลตฟอร์มการซื้อขายข้อมูลที่สมบูรณ์แบบที่สุดในตลาด ณ จุดนี้ แต่ก็ยังเผชิญกับความท้าทายมากมาย:
สร้างกลไกความไว้วางใจที่มีประสิทธิภาพเพื่อเพิ่มความไว้วางใจระหว่างผู้ให้บริการข้อมูลและผู้เรียกร้องและลดความเสี่ยงในการทำธุรกรรม ตัวอย่างเช่น สร้างระบบเครดิตตลาดองค์ประกอบข้อมูลเพื่อเก็บรักษาและตรวจสอบใบรับรองผ่านบล็อกเชนเพื่อระบุพฤติกรรมที่ไม่น่าเชื่อถือในการทำธุรกรรมข้อมูล สิ่งจูงใจที่น่าเชื่อถือ การลงโทษที่ไม่น่าเชื่อถือ การซ่อมแซมเครดิต การจัดการข้อโต้แย้ง ฯลฯ
สร้างกลไกการกำหนดราคาที่เหมาะสมเพื่อสะท้อนคุณค่าที่แท้จริงของผลิตภัณฑ์ข้อมูล กระตุ้นให้ผู้ให้บริการข้อมูลให้ข้อมูลคุณภาพสูง และดึงดูดความต้องการมากขึ้น
สร้างข้อกำหนดมาตรฐานที่เป็นหนึ่งเดียวเพื่อส่งเสริมการทำงานร่วมกันและความเข้ากันได้ระหว่างข้อมูลในรูปแบบ ประเภท แหล่งที่มา และการใช้งานที่แตกต่างกัน
กรณี: ตลาดโมเดลข้อมูล
ใน Data Universe นั้น Ceramic กล่าวถึงตลาดโมเดลข้อมูลแบบเปิดที่พวกเขาต้องการสร้าง ซึ่งสามารถเพิ่มประสิทธิภาพการทำงานได้อย่างมาก เนื่องจากข้อมูลจำเป็นต้องมีการทำงานร่วมกัน ตลาดโมเดลข้อมูลดังกล่าวเปิดใช้งานได้ด้วยความเห็นพ้องต้องกันที่เกิดขึ้นเกี่ยวกับโมเดลข้อมูล ซึ่งคล้ายกับมาตรฐานสัญญา ERC ใน Ethereum ซึ่งนักพัฒนาสามารถเลือกเป็นเทมเพลตการทำงานเพื่อให้มีแอปพลิเคชันที่สอดคล้องกับข้อมูลทั้งหมดของโมเดลข้อมูลนั้น ในขั้นตอนนี้ ตลาดดังกล่าวไม่ใช่ตลาดการค้า
สำหรับโมเดลข้อมูล ตัวอย่างง่ายๆ ก็คือ ในเครือข่ายโซเชียลแบบกระจายอำนาจ โมเดลข้อมูลสามารถลดความซับซ้อนลงได้ถึง 4 พารามิเตอร์ ได้แก่
PostList: เก็บดัชนีโพสต์ของผู้ใช้
โพสต์: เก็บโพสต์เดียว
โปรไฟล์: เก็บข้อมูลผู้ใช้
FollowList: เก็บรายการติดตามของผู้ใช้
แล้วแบบจำลองข้อมูลจะถูกสร้างขึ้น แบ่งปัน และนำกลับมาใช้ใหม่บน Ceramic ได้อย่างไร เพื่อให้สามารถทำงานร่วมกันของข้อมูลข้ามแอปพลิเคชันได้
Ceramic จัดเตรียม DataModels Registry ซึ่งเป็นพื้นที่เก็บข้อมูลแบบโอเพ่นซอร์สที่สร้างโดยชุมชนสำหรับโมเดลข้อมูลแอปพลิเคชันที่นำมาใช้ซ้ำได้สำหรับ Ceramic นี่คือจุดที่นักพัฒนาสามารถลงทะเบียน ค้นพบ และนำโมเดลข้อมูลที่มีอยู่กลับมาใช้ใหม่ได้อย่างเปิดเผย ซึ่งเป็นรากฐานสำหรับแอปพลิเคชันการปฏิบัติงานของลูกค้าที่สร้างจากโมเดลข้อมูลที่ใช้ร่วมกัน ปัจจุบันใช้พื้นที่เก็บข้อมูล Github และในอนาคตจะมีการกระจายอำนาจบน Ceramic
โมเดลข้อมูลทั้งหมดที่เพิ่มลงในรีจิสทรีจะถูกเผยแพร่ไปยังแพ็คเกจปลั๊กอิน npm ของ @datamodels โดยอัตโนมัติ นักพัฒนาคนใดก็ตามสามารถใช้ @datamodels/model-name เพื่อติดตั้งโมเดลข้อมูลตั้งแต่หนึ่งโมเดลขึ้นไป ทำให้พร้อมสำหรับจัดเก็บหรือดึงข้อมูล ณ รันไทม์โดยใช้ไคลเอนต์ IDX ใด ๆ รวมถึง DID DataStore หรือ Self.ID
นอกจากนี้ Ceramic ยังได้สร้างฟอรัม DataModels โดยใช้ Github แต่ละโมเดลในการลงทะเบียนโมเดลข้อมูลจะมีเธรดการสนทนาของตนเองในฟอรัมซึ่งชุมชนสามารถแสดงความคิดเห็นและหารือได้ นอกจากนี้ยังเป็นสถานที่สำหรับนักพัฒนาในการโพสต์แนวคิดเกี่ยวกับโมเดลข้อมูลเพื่อรับข้อมูลจากชุมชนก่อนที่จะเพิ่มลงในรีจิสทรี ขณะนี้ทุกอย่างยังอยู่ในช่วงเริ่มต้นและมีโมเดลข้อมูลไม่มากนักในรีจิสทรี โมเดลข้อมูลที่รวมอยู่ในรีจิสทรีควรได้รับการประเมินโดยชุมชนและเรียกว่ามาตรฐาน CIP เช่นเดียวกับมาตรฐานสัญญาอัจฉริยะของ Ethereum ซึ่งจัดให้มีความสามารถในการรวมข้อมูล
กรณี: คลังข้อมูลแบบกระจายอำนาจ
Space and Time เป็นคลังข้อมูลแบบกระจายอำนาจแห่งแรกที่เชื่อมต่อข้อมูลแบบออนไลน์และออฟไลน์เพื่อรองรับกรณีการใช้งานสัญญาอัจฉริยะรุ่นใหม่ Space and Time (SxT) มีบริการจัดทำดัชนีบล็อคเชนที่เติบโตมากที่สุดในอุตสาหกรรม คลังข้อมูล SxT ยังใช้การเข้ารหัสแบบใหม่ที่เรียกว่า Proof of SQL™ เพื่อสร้างผลลัพธ์ที่ป้องกันการงัดแงะที่ตรวจสอบได้ ข้อมูลลูกโซ่และนอกลูกโซ่ และโหลดผลลัพธ์โดยตรงไปยังสัญญาอัจฉริยะ ขับเคลื่อนการสืบค้นภายในไม่กี่วินาทีและการวิเคราะห์ระดับองค์กรในลักษณะป้องกันการงัดแงะอย่างสมบูรณ์และยึดกับบล็อคเชน
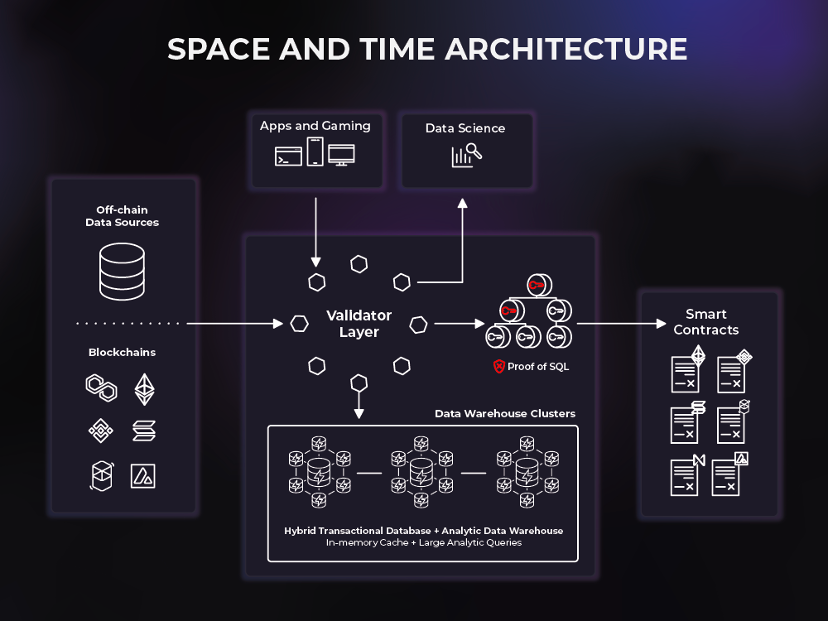
Space and Time เป็นเครือข่ายสองชั้นที่ประกอบด้วยชั้นตรวจสอบความถูกต้องและคลังข้อมูล ความสำเร็จของแพลตฟอร์ม SxT ขึ้นอยู่กับการทำงานร่วมกันอย่างราบรื่นของผู้ตรวจสอบและคลังข้อมูล เพื่ออำนวยความสะดวกในการสืบค้นข้อมูลแบบออนไลน์และออฟไลน์ที่ง่ายและปลอดภัย
คลังข้อมูลประกอบด้วยเครือข่ายฐานข้อมูลและคลัสเตอร์การประมวลผลที่ควบคุมและกำหนดเส้นทางไปยังเครื่องมือตรวจสอบพื้นที่และเวลา พื้นที่และเวลาใช้โซลูชันคลังสินค้าที่มีความยืดหยุ่นสูง: HTAP (การประมวลผลธุรกรรม/การวิเคราะห์แบบไฮบริด)
เครื่องมือตรวจสอบจะตรวจสอบ คำสั่ง และตรวจสอบบริการที่ได้รับจากคลัสเตอร์เหล่านี้ จากนั้นจัดลำดับการไหลของข้อมูลและการสืบค้นระหว่างผู้ใช้ปลายทางและคลัสเตอร์คลังข้อมูล เครื่องมือตรวจสอบความถูกต้องจัดเตรียมช่องทางสำหรับข้อมูลเพื่อเข้าสู่ระบบ (เช่น ดัชนีบล็อคเชน) และข้อมูลในการออกจากระบบ (เช่น สัญญาอัจฉริยะ)
การกำหนดเส้นทาง - ช่วยให้สามารถโต้ตอบธุรกรรมและการสืบค้นกับเครือข่ายคลังข้อมูลแบบกระจายอำนาจ
การสตรีม – ทำหน้าที่เป็นช่องทางสำหรับปริมาณงานการสตรีมลูกค้าที่มีปริมาณมาก (ขับเคลื่อนด้วยเหตุการณ์)
ฉันทามติ - ให้ความทนทานต่อข้อผิดพลาด Byzantine ที่มีประสิทธิภาพสูงสำหรับข้อมูลที่เข้าและออกจากแพลตฟอร์ม
หลักฐานการสืบค้น – จัดเตรียมการพิสูจน์ SQL ให้กับแพลตฟอร์ม
ที่ยึดโต๊ะ - ให้หลักฐานการจัดเก็บบนแท่นโดยการยึดโต๊ะไว้บนโซ่
Oracle - รองรับการโต้ตอบกับ Web3 รวมถึงการฟังเหตุการณ์สัญญาอัจฉริยะและการส่งข้อความ/การถ่ายทอดข้ามสายโซ่
ความปลอดภัย – ป้องกันการเข้าถึงแพลตฟอร์มโดยไม่ได้รับอนุญาตและไม่ได้รับอนุญาต
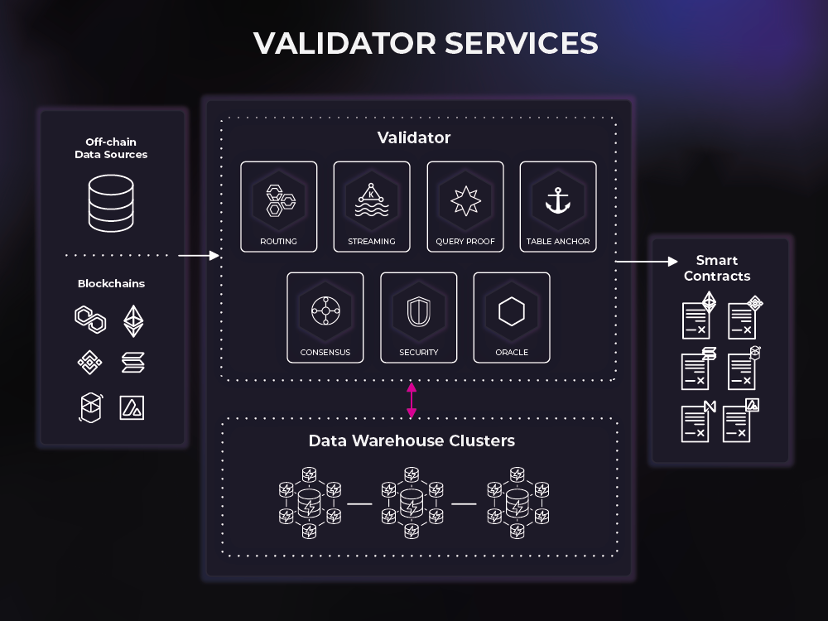
พื้นที่และเวลาเป็นแพลตฟอร์มเป็นโครงสร้างข้อมูลแบบกระจายอำนาจแห่งแรกของโลก ซึ่งเปิดตลาดที่ทรงพลังแต่ยังด้อยโอกาส: การแบ่งปันข้อมูล ภายในแพลตฟอร์ม Space and Time บริษัทต่างๆ สามารถแบ่งปันข้อมูลได้อย่างอิสระ และใช้สัญญาอัจฉริยะเพื่อแลกเปลี่ยนข้อมูลที่แบ่งปัน นอกจากนี้ ชุดข้อมูลสามารถสร้างรายได้จากลักษณะรวมผ่านการพิสูจน์ SQL โดยไม่ต้องให้ผู้บริโภคเข้าถึงข้อมูลดิบ ผู้ใช้ข้อมูลสามารถไว้วางใจได้ว่าการรวมกลุ่มมีความถูกต้องโดยไม่ต้องเห็นข้อมูล ดังนั้นผู้ให้บริการข้อมูลจึงไม่จำเป็นต้องเป็นผู้บริโภคข้อมูลอีกต่อไป ด้วยเหตุนี้เองที่การผสมผสานระหว่างการพิสูจน์ SQL และสกีมาโครงสร้างข้อมูลจึงมีศักยภาพในการทำให้การดำเนินงานข้อมูลเป็นประชาธิปไตย เนื่องจากใครๆ ก็สามารถมีส่วนร่วมในการนำเข้า การแปลง และการให้บริการชุดข้อมูลได้
การกำกับดูแลและการค้นพบข้อมูล Web3
ปัจจุบัน สถาปัตยกรรมโครงสร้างพื้นฐานข้อมูล Web3 ยังขาดโครงสร้างการกำกับดูแลข้อมูลที่ใช้งานได้จริงและมีประสิทธิภาพ อย่างไรก็ตาม โครงสร้างพื้นฐานการกำกับดูแลข้อมูลที่ใช้งานได้จริงและมีประสิทธิภาพถือเป็นสิ่งสำคัญในการกำหนดค่าองค์ประกอบข้อมูลตามความสนใจที่เกี่ยวข้องของผู้เข้าร่วมแต่ละราย
สำหรับแหล่งข้อมูลจำเป็นต้องได้รับความยินยอมและสิทธิ์ในการรับ คัดลอก และถ่ายโอนข้อมูลโดยอิสระ
สำหรับผู้ประมวลผลข้อมูล พวกเขาจำเป็นต้องมีอำนาจในการควบคุม ใช้ข้อมูล และรับผลประโยชน์โดยอัตโนมัติ
สำหรับอนุพันธ์ของข้อมูล จำเป็นต้องมีสิทธิ์ในการดำเนินงาน
ปัจจุบัน ความสามารถในการกำกับดูแลข้อมูล Web3 เป็นแบบเดี่ยว และสินทรัพย์และข้อมูล (รวมถึงเซรามิค) มักจะสามารถควบคุมได้โดยการควบคุมคีย์ส่วนตัวเท่านั้น โดยแทบไม่มีความสามารถในการกำหนดค่าการจำแนกประเภทแบบลำดับชั้นเลย เมื่อเร็วๆ นี้ กลไกที่เป็นนวัตกรรมของ Tableland, FEVM และ Greenfield สามารถบรรลุการกำกับดูแลข้อมูลที่ไม่น่าเชื่อถือได้ในระดับหนึ่ง เครื่องมือกำกับดูแลข้อมูลแบบเดิม เช่น Collibra โดยทั่วไปสามารถใช้ได้ภายในองค์กรเท่านั้นและมีความน่าเชื่อถือระดับแพลตฟอร์มเท่านั้น ขณะเดียวกัน เทคโนโลยีที่ไม่กระจายอำนาจยังทำให้ไม่สามารถป้องกันความชั่วร้ายส่วนบุคคลและความล้มเหลวจุดเดียวได้ ด้วยเครื่องมือกำกับดูแลข้อมูล เช่น Tableland จึงสามารถรับประกันเทคโนโลยีความปลอดภัย มาตรฐาน และโซลูชันที่จำเป็นสำหรับกระบวนการหมุนเวียนข้อมูลได้
กรณี: เทเบิลแลนด์
Tableland Network เป็นโปรโตคอล web3 แบบกระจายอำนาจสำหรับข้อมูลเชิงสัมพันธ์ที่มีโครงสร้าง เริ่มต้นด้วย Ethereum (EVM) และ L2 ที่เข้ากันได้กับ EVM ด้วย Tableland ตอนนี้คุณสามารถใช้ฟังก์ชันฐานข้อมูลเชิงสัมพันธ์ web2 แบบดั้งเดิมได้โดยใช้ประโยชน์จากเลเยอร์ blockchain สำหรับการควบคุมการเข้าถึง อย่างไรก็ตาม Tableland ไม่ใช่ฐานข้อมูลใหม่ - มันเป็นเพียงตารางเชิงสัมพันธ์ดั้งเดิมของ web3
Tableland มอบวิธีใหม่สำหรับ dapps ในการจัดเก็บข้อมูลเชิงสัมพันธ์ในเครือข่าย web3-native โดยไม่ต้องเสียการแลกเปลี่ยนเหล่านี้
สารละลาย
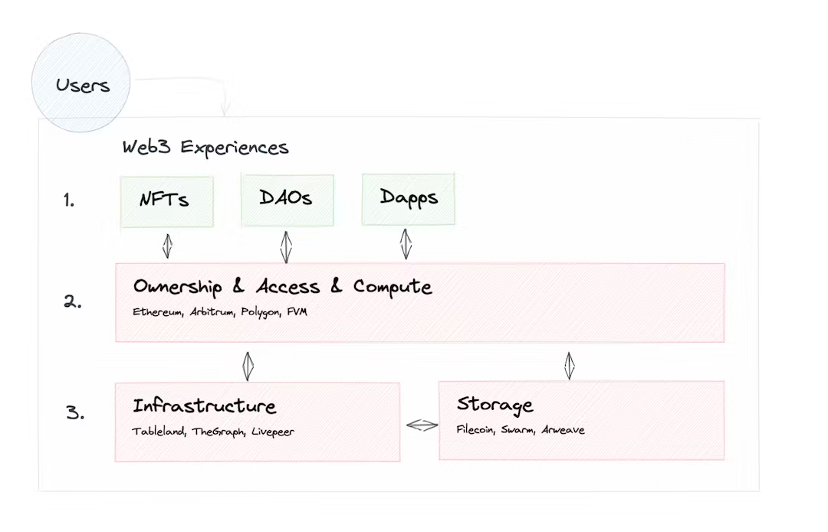
ด้วย Tableland คุณสามารถเปลี่ยนแปลงข้อมูลเมตาได้ (โดยใช้การควบคุมการเข้าถึงหากจำเป็น) สอบถาม (โดยใช้ SQL ที่คุ้นเคย) และเขียนได้ (กับตารางอื่นๆ บน Tableland) - ทั้งหมดนี้ในลักษณะการกระจายอำนาจโดยสมบูรณ์
Tableland แบ่งฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิมออกเป็นสององค์ประกอบหลัก: การลงทะเบียนออนไลน์ที่มีตรรกะการควบคุมการเข้าถึง (ACL) และตารางนอกเครือข่าย (กระจายอำนาจ) ทุกตารางใน Tableland จะถูกสร้างเป็นโทเค็น ERC 721 บนเลเยอร์ความเข้ากันได้ EVM พื้นฐาน ดังนั้นเจ้าของตารางแบบออนไลน์สามารถตั้งค่าการอนุญาต ACL บนตารางได้ ในขณะที่เครือข่าย Tableland แบบออฟไลน์จะจัดการการสร้างและการเปลี่ยนแปลงที่ตามมาของตารางเอง ลิงก์ระหว่าง on-chain และ off-chain ทั้งหมดได้รับการจัดการในระดับสัญญา ซึ่งเพียงชี้ไปที่เครือข่าย Tableland (โดยใช้ baseURI + tokenURI เหมือนกับโทเค็น ERC 721 ที่มีอยู่จำนวนมากที่ใช้เกตเวย์ IPFS หรือเซิร์ฟเวอร์โฮสต์สำหรับข้อมูลเมตา)
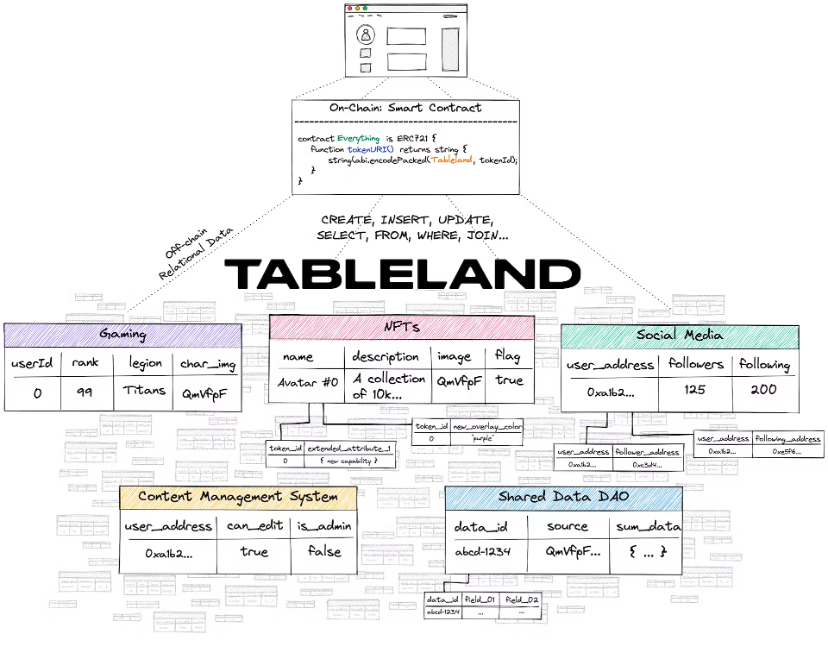 เฉพาะผู้ที่มีสิทธิ์ออนไลน์ที่เหมาะสมเท่านั้นที่สามารถเขียนลงในตารางเฉพาะได้ อย่างไรก็ตาม การอ่านตารางไม่จำเป็นต้องดำเนินการแบบออนไลน์และสามารถใช้เกตเวย์ Tableland ได้ ดังนั้น การสืบค้นการอ่านจึงไม่มีค่าใช้จ่ายและอาจมาจากคำขอส่วนหน้าแบบธรรมดา หรือแม้แต่จากบล็อกเชนที่ไม่ใช่ EVM อื่นๆ ตอนนี้เพื่อที่จะใช้ Tableland จะต้องสร้างตารางก่อน (เช่น minted on-chain เป็น ERC 721) ในตอนแรกที่อยู่การปรับใช้จะถูกตั้งค่าให้กับเจ้าของตาราง และเจ้าของนี้สามารถตั้งค่าสิทธิ์สำหรับผู้ใช้รายอื่นที่พยายามโต้ตอบกับตารางเพื่อทำการเปลี่ยนแปลงได้ ตัวอย่างเช่น เจ้าของสามารถตั้งกฎว่าใครสามารถอัปเดต/แทรก/ลบค่าได้ ข้อมูลใดบ้างที่พวกเขาสามารถเปลี่ยนแปลงได้ และแม้แต่ตัดสินใจว่าพวกเขายินดีที่จะโอนความเป็นเจ้าของตารางให้กับบุคคลอื่นหรือไม่ นอกจากนี้ การสืบค้นที่ซับซ้อนมากขึ้นยังสามารถรวมข้อมูลจากหลายตาราง (เป็นเจ้าของหรือไม่ได้เป็นเจ้าของ) เพื่อสร้างชั้นข้อมูลเชิงสัมพันธ์แบบไดนามิกและแบบเรียบเรียงได้อย่างสมบูรณ์
เฉพาะผู้ที่มีสิทธิ์ออนไลน์ที่เหมาะสมเท่านั้นที่สามารถเขียนลงในตารางเฉพาะได้ อย่างไรก็ตาม การอ่านตารางไม่จำเป็นต้องดำเนินการแบบออนไลน์และสามารถใช้เกตเวย์ Tableland ได้ ดังนั้น การสืบค้นการอ่านจึงไม่มีค่าใช้จ่ายและอาจมาจากคำขอส่วนหน้าแบบธรรมดา หรือแม้แต่จากบล็อกเชนที่ไม่ใช่ EVM อื่นๆ ตอนนี้เพื่อที่จะใช้ Tableland จะต้องสร้างตารางก่อน (เช่น minted on-chain เป็น ERC 721) ในตอนแรกที่อยู่การปรับใช้จะถูกตั้งค่าให้กับเจ้าของตาราง และเจ้าของนี้สามารถตั้งค่าสิทธิ์สำหรับผู้ใช้รายอื่นที่พยายามโต้ตอบกับตารางเพื่อทำการเปลี่ยนแปลงได้ ตัวอย่างเช่น เจ้าของสามารถตั้งกฎว่าใครสามารถอัปเดต/แทรก/ลบค่าได้ ข้อมูลใดบ้างที่พวกเขาสามารถเปลี่ยนแปลงได้ และแม้แต่ตัดสินใจว่าพวกเขายินดีที่จะโอนความเป็นเจ้าของตารางให้กับบุคคลอื่นหรือไม่ นอกจากนี้ การสืบค้นที่ซับซ้อนมากขึ้นยังสามารถรวมข้อมูลจากหลายตาราง (เป็นเจ้าของหรือไม่ได้เป็นเจ้าของ) เพื่อสร้างชั้นข้อมูลเชิงสัมพันธ์แบบไดนามิกและแบบเรียบเรียงได้อย่างสมบูรณ์
พิจารณาแผนภาพต่อไปนี้ ซึ่งสรุปการโต้ตอบของผู้ใช้ใหม่กับตารางที่ได้รับการปรับใช้กับ Tableland โดย dapp บางตัว:
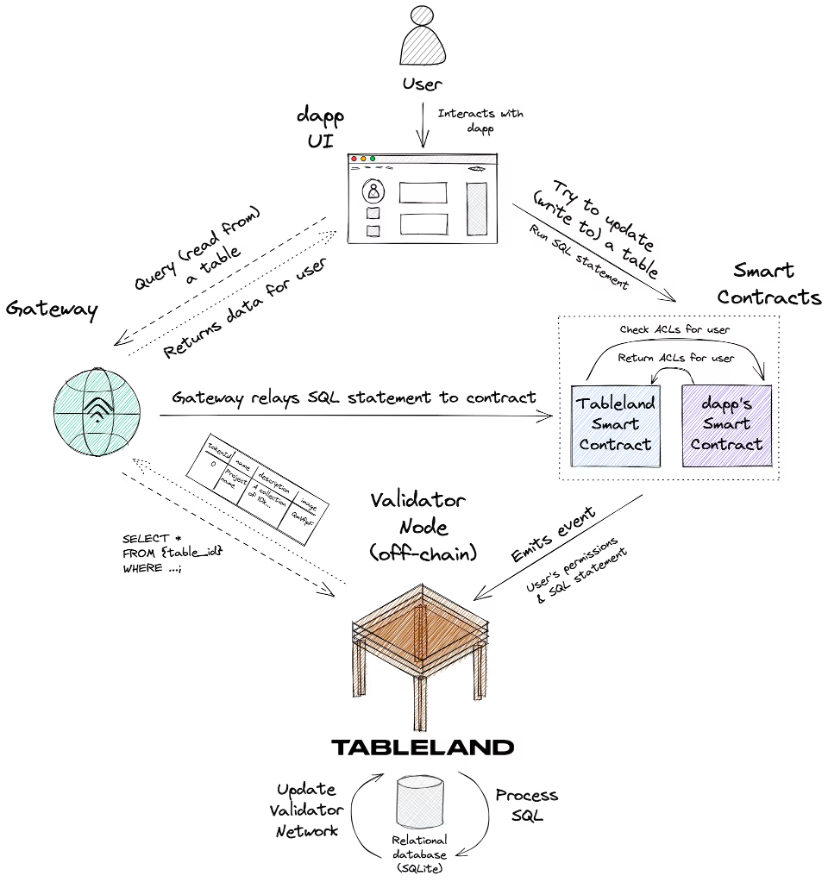
นี่คือการไหลของข้อมูลโดยรวม:
1. ผู้ใช้ใหม่โต้ตอบกับ UI ของ dapp และพยายามอัปเดตข้อมูลบางอย่างที่จัดเก็บไว้ในตาราง Tableland
2. dapp เรียกสัญญาอัจฉริยะการลงทะเบียน Tableland เพื่อรันคำสั่ง SQL นี้ และสัญญานี้จะตรวจสอบสัญญาอัจฉริยะของ dapp ซึ่งประกอบด้วย ACL ที่กำหนดเองซึ่งกำหนดสิทธิ์ของผู้ใช้ใหม่นี้ มีประเด็นที่ควรทราบ:
ACL แบบกำหนดเองใน Smart Contract ที่แยกจากกันของ dapp ถือเป็นกรณีการใช้งานขั้นสูงที่เป็นทางเลือกโดยสมบูรณ์ นักพัฒนาไม่จำเป็นต้องใช้ ACL แบบกำหนดเองและสามารถใช้นโยบายเริ่มต้นของ Smart Contract ของรีจิสทรี Tableland ได้ (เฉพาะเจ้าของเท่านั้นที่มีสิทธิ์เต็มรูปแบบ)
คุณยังสามารถใช้เกตเวย์เพื่อเขียนแบบสอบถามแทนการเรียกสัญญาอัจฉริยะของ Tableland โดยตรงได้ มีตัวเลือกเสมอสำหรับ dapps ที่จะโทรหาสัญญาอัจฉริยะของ Tableland โดยตรง แต่คำถามใดๆ ก็สามารถส่งผ่านเกตเวย์ได้ ซึ่งจะส่งต่อคำถามไปยังสัญญาอัจฉริยะเองในลักษณะที่ได้รับเงินอุดหนุน
3. สัญญาอัจฉริยะของ Tableland ได้รับคำสั่ง SQL และการอนุญาตของผู้ใช้ และรวมสิ่งเหล่านี้ไว้ในเหตุการณ์ที่ปล่อยออกมาซึ่งอธิบายการดำเนินการที่ใช้ SQL ที่จะต้องดำเนินการ
4. โหนด Tableland Validator จะรับฟังเหตุการณ์เหล่านี้ จากนั้นดำเนินการอย่างใดอย่างหนึ่งต่อไปนี้:
หากผู้ใช้มีสิทธิ์ที่ถูกต้องในการเขียนลงในตาราง เครื่องมือตรวจสอบจะรันคำสั่ง SQL ตามนั้น (เช่น แทรกแถวใหม่ลงในตารางหรืออัปเดตค่าที่มีอยู่) และเผยแพร่ข้อมูลการยืนยันไปยังเครือข่าย Tableland
หากผู้ใช้ไม่มีสิทธิ์ที่ถูกต้อง Validator จะไม่ดำเนินการใดๆ บนโต๊ะ
หากคำขอเป็นการสืบค้นแบบอ่านธรรมดาข้อมูลที่เหมาะสมจะถูกส่งกลับ Tableland เป็นเครือข่ายข้อมูลเชิงสัมพันธ์แบบเปิดโดยสมบูรณ์ซึ่งใคร ๆ ก็สามารถทำการสืบค้นแบบอ่านอย่างเดียวบนตารางใดก็ได้
5. dapp จะสามารถสะท้อนถึงการอัปเดตใด ๆ ที่เกิดขึ้นบนเครือข่าย Tableland ผ่านทางเกตเวย์
(สถานการณ์การใช้งาน) สิ่งที่ควรหลีกเลี่ยง
ข้อมูลที่สามารถระบุตัวบุคคลได้ - Tableland เป็นเครือข่ายแบบเปิดและทุกคนสามารถอ่านข้อมูลจากตารางใดก็ได้ ดังนั้นข้อมูลส่วนบุคคลไม่ควรถูกเก็บไว้ใน Tableland
การเขียนความถี่สูงในเสี้ยววินาที เช่น บอทการซื้อขายความถี่สูง
เก็บทุกการโต้ตอบของผู้ใช้ในแอปพลิเคชัน - อาจไม่สมเหตุสมผลที่จะบันทึกข้อมูลนี้ในตาราง web3 เช่น การกดแป้นพิมพ์หรือการคลิก ความถี่ในการเขียนส่งผลให้มีต้นทุนสูง
ชุดข้อมูลขนาดใหญ่มาก - ควรหลีกเลี่ยงและจัดการได้ดีที่สุดผ่านพื้นที่จัดเก็บไฟล์ โดยใช้โซลูชัน เช่น IPFS, Filecoin หรือ Arweave อย่างไรก็ตาม ตัวชี้ไปยังตำแหน่งเหล่านี้และข้อมูลเมตาที่เกี่ยวข้องนั้นเป็นกรณีการใช้งานที่ดีสำหรับตาราง Tableland
ความคิดในการจับคุณค่า
หน่วยต่างๆ มีบทบาทที่ไม่สามารถถูกแทนที่ได้ในสถาปัตยกรรมโครงสร้างพื้นฐานข้อมูลทั้งหมด มูลค่าที่จับได้ส่วนใหญ่จะสะท้อนให้เห็นในมูลค่าตลาด/การประเมินค่า และรายได้โดยประมาณ สามารถสรุปได้ดังต่อไปนี้:
แหล่งข้อมูลคือโมดูลที่มีการจับค่ามากที่สุดในสถาปัตยกรรมทั้งหมด
การจำลองข้อมูล การแปลง การสตรีม และคลังข้อมูลคือก้าวต่อไป
ชั้นการวิเคราะห์อาจมีกระแสเงินสดที่ดี แต่จะมีการจำกัดมูลค่าในการประเมินมูลค่า
พูดง่ายๆ ก็คือ การจับมูลค่าของบริษัท/โครงการทางด้านซ้ายของแผนภาพโครงสร้างทั้งหมดมีแนวโน้มที่จะมากกว่า
ความเข้มข้นของอุตสาหกรรม
จากการวิเคราะห์ทางสถิติที่ไม่สมบูรณ์ สามารถตัดสินความเข้มข้นของอุตสาหกรรมได้ดังนี้:
โมดูลสองโมดูลที่มีความเข้มข้นสูงสุดในอุตสาหกรรมคือการจัดเก็บข้อมูล และการสืบค้นและประมวลผลข้อมูล
การกระจุกตัวของอุตสาหกรรมขนาดกลางคือการสกัดและการเปลี่ยนแปลงข้อมูล
โมดูลทั้งสองที่มีความเข้มข้นในอุตสาหกรรมต่ำกว่าคือแหล่งข้อมูล การวิเคราะห์ และเอาต์พุต
การกระจุกตัวของแหล่งข้อมูล การวิเคราะห์ และอุตสาหกรรมเอาท์พุตอยู่ในระดับต่ำ การตัดสินเบื้องต้นคือสถานการณ์ทางธุรกิจที่แตกต่างกันนำไปสู่การเกิดขึ้นของผู้นำสถานการณ์แนวตั้งในแต่ละสถานการณ์ทางธุรกิจ เช่น Oracle ในด้านฐานข้อมูล Stripe ในบริการของบุคคลที่สาม และ บริการระดับองค์กร Salesforce, Tableau สำหรับการวิเคราะห์แดชบอร์ด, Sisense สำหรับการวิเคราะห์แบบฝัง และอื่นๆ
สำหรับโมดูลการแยกและการแปลงข้อมูลที่มีความเข้มข้นของอุตสาหกรรมขนาดกลางนั้น ในตอนแรกจะมีการตัดสินว่าสาเหตุนั้นเนื่องมาจากลักษณะทางธุรกิจที่มุ่งเน้นเทคโนโลยี มิดเดิลแวร์รูปแบบโมดูลาร์ยังทำให้ต้นทุนการเปลี่ยนค่อนข้างต่ำอีกด้วย
โมดูลการจัดเก็บข้อมูลและการสืบค้นข้อมูลและการประมวลผลมีความเข้มข้นสูงสุดในอุตสาหกรรม การตัดสินเบื้องต้นคือเนื่องจากสถานการณ์ทางธุรกิจเดียว เนื้อหาทางเทคนิคสูง ค่าใช้จ่ายในการเริ่มต้นที่สูง และค่าใช้จ่ายในการเปลี่ยนที่ตามมา บริษัท / โครงการจึงมีผู้เสนอญัตติรายแรกที่แข็งแกร่ง ได้เปรียบและมีผลกระทบต่อเครือข่าย
รูปแบบธุรกิจโปรโตคอลข้อมูลและเส้นทางออก
เมื่อพิจารณาจากเวลาก่อตั้งและรายการ
บริษัท/โครงการส่วนใหญ่ที่จัดตั้งขึ้นก่อนปี 2010 เป็นบริษัท/โครงการแหล่งข้อมูล อินเทอร์เน็ตบนมือถือยังไม่เกิดขึ้นและปริมาณข้อมูลก็มีไม่มากนัก นอกจากนี้ยังมีโครงการจัดเก็บข้อมูลและการวิเคราะห์ข้อมูลบางส่วน ซึ่งส่วนใหญ่เป็นแดชบอร์ด
ตั้งแต่ปี 2010 ถึง 2014 ก่อนอินเทอร์เน็ตบนมือถือจะเติบโตขึ้น โครงการจัดเก็บข้อมูลและการสืบค้น เช่น Snowflake และ Databricks ก็ถือกำเนิดขึ้น โครงการสกัดและแปลงข้อมูลก็เริ่มปรากฏให้เห็น ชุดโซลูชันเทคโนโลยีการจัดการข้อมูลขนาดใหญ่ที่เป็นผู้ใหญ่ค่อยๆ ปรับปรุงให้ดีขึ้น ในช่วงเวลานี้ มีโปรเจ็กต์ประเภทเอาต์พุตการวิเคราะห์จำนวนมาก ซึ่งส่วนใหญ่เป็นประเภทแดชบอร์ด
ตั้งแต่ปี 2558 ถึง 2563 โครงการสืบค้นและประมวลผลมีจำนวนเพิ่มมากขึ้น และโครงการแยกและแปลงข้อมูลจำนวนมากก็ได้เกิดขึ้นเช่นกัน ช่วยให้ผู้คนสามารถใช้ประโยชน์จากพลังของข้อมูลขนาดใหญ่ได้ดีขึ้น
ตั้งแต่ปี 2020 ฐานข้อมูลการวิเคราะห์แบบเรียลไทม์และโซลูชัน Data Lake ใหม่ๆ ได้เกิดขึ้น เช่น Clickhouse และ Tabular
การปรับปรุงโครงสร้างพื้นฐานเป็นข้อกำหนดเบื้องต้นสำหรับสิ่งที่เรียกว่า การยอมรับจำนวนมาก ในช่วงระยะเวลาของการใช้งานขนาดใหญ่ ยังคงมีโอกาสใหม่ ๆ แต่โอกาสเหล่านี้เกือบจะเป็นของ มิดเดิลแวร์ เท่านั้น ในขณะที่คลังข้อมูล แหล่งข้อมูล และโซลูชันอื่น ๆ ที่เป็นพื้นฐานแทบจะเป็นสถานการณ์ที่ชนะได้ทั้งหมด เว้นแต่จะมี สารทางเทคนิค เจริญทางเพศ ไม่เช่นนั้นจะเติบโตได้ยาก
โครงการผลลัพธ์เชิงวิเคราะห์เป็นโอกาสสำหรับโครงการของผู้ประกอบการในช่วงเวลาใดก็ได้ แต่ก็ยังมีการทำซ้ำและสร้างสรรค์สิ่งใหม่ ๆ อย่างต่อเนื่องโดยทำสิ่งใหม่ ๆ ตามสถานการณ์ใหม่ Tableau ซึ่งปรากฏก่อนปี 2010 ครอบครองเครื่องมือวิเคราะห์แดชบอร์ดบนเดสก์ท็อปส่วนใหญ่แล้วสถานการณ์ใหม่ ๆ ก็ปรากฏขึ้น เช่น เครื่องมือ DS/ML ที่เน้นความเป็นมืออาชีพมากขึ้น เวิร์กสเตชันข้อมูลที่ครอบคลุมมากขึ้นและการวิเคราะห์แบบฝังที่เน้น SaaS มากขึ้น ฯลฯ
ดูโปรโตคอลข้อมูลปัจจุบันของ Web3 จากมุมมองนี้:
สถานะของแหล่งข้อมูลและโครงการจัดเก็บข้อมูลไม่แน่นอน แต่ผู้นำเริ่มปรากฏให้เห็นแล้ว การจัดเก็บสถานะ On-chain นำโดย Ethereum (มูลค่าตลาด 220 พันล้าน) ในขณะที่การจัดเก็บข้อมูลแบบกระจายอำนาจนำโดย Filecoin (มูลค่าตลาด 2.3 พันล้าน) และ Arweave (มูลค่าตลาด 280 ล้าน) เป็นไปได้ว่าจะมีการเกิดขึ้นของ Greenfield อย่างกะทันหัน —— การจับที่มีมูลค่าสูงสุด
ยังมีพื้นที่สำหรับนวัตกรรมในโครงการสกัดและแปลงข้อมูล data oracle Chainlink (มูลค่าตลาด 3.8 พันล้าน) เป็นเพียงจุดเริ่มต้น เซรามิค โครงสร้างพื้นฐานสตรีมเหตุการณ์และการประมวลผลสตรีมและโครงการอื่น ๆ จะปรากฏขึ้น แต่มีไม่มาก ห้อง. - การจับค่าปานกลาง
สำหรับการสอบถามและการประมวลผลโครงการ กราฟ (มูลค่าตลาด 1.2 พันล้าน) สามารถตอบสนองความต้องการส่วนใหญ่ได้ และประเภทและจำนวนโครงการยังไม่ถึงขั้นระเบิด - การจับค่าปานกลาง
โครงการวิเคราะห์ข้อมูล ซึ่งส่วนใหญ่เป็น Nansen และ Dune (มูลค่า 1 พันล้าน) ต้องใช้สถานการณ์ใหม่จึงจะมีโอกาสใหม่ NFTScan และ NFTGo ค่อนข้างคล้ายกับสถานการณ์ใหม่ แต่เป็นเพียงการอัปเดตเนื้อหา ไม่ใช่ระดับตรรกะ/กระบวนทัศน์การวิเคราะห์ . ——การเก็บมูลค่าปานกลางและกระแสเงินสดจำนวนมาก
แต่ Web3 ไม่ใช่แบบจำลองของ Web2 และไม่ใช่วิวัฒนาการของ Web2 ทั้งหมด Web3 มีภารกิจและสถานการณ์ดั้งเดิมมาก จึงทำให้เกิดสถานการณ์ทางธุรกิจที่แตกต่างอย่างสิ้นเชิงจากเมื่อก่อน (สามสถานการณ์แรกเป็นนามธรรมทั้งหมดที่สามารถทำได้ในปัจจุบัน)





