




Author: Steven, E2M Researcher
Preface
Ethereum VS Celestia + Cosmos, the trade-offs are probably the following: legitimacy + high security + high degree of decentralization VS high scalability (low cost + good performance + easy iteration) + good interactivity. Why? The project can be recognized by many users. In the early stage, it was mainly determined by the bilateral needs of project parties with smaller scale and shorter development time and users:
Users: In the perception of many users, many general users have greater demand for whether the product is easy to use and affordable than for security (whether it is Web2 or Web3);
Early project parties: need good scalability to make strategic adjustments at any time, and lower costs to make the project have longer vitality. Therefore, it is difficult to directly say that modular blockchains such as Celestia are Ethereum killers, but a large part of the population has demand for high-performance, cost-effective, and scalable Web3 public chains. Ethereum’s legitimacy, security, and head-effects are still unshakable, but this does not prevent users from having other choices in certain scenarios.
1. Background
The Cancun upgrade is coming soon, and it is expected to further reduce the gas fee of Layer 2 after EIP-4844 Proto Danksharding.
Ethereum will complete the sharding solution DankSharding in the next few years (Cancun upgrade, EIP-4844 are just one of them).
However, with the launch of the Celestia mainnet at 2:00 on October 31, 2023, and the high probability of seeing Avail (formerly Polygon Avail, which has been separated into a separate project) in the first quarter of this year, the third-party consensus layer + DA The layer has completely overtaken it, achieving the modularization goal that Ethereum can only achieve in the next few years ahead of schedule. It has significantly reduced the cost of Layer 2 before the Cancun upgrade, becoming the choice of many Layer 2 DA layers, cannibalizing the DA belonging to Ethereum. Layers of cake.
In addition, modular blockchain provides more diversified services for future public chains, and Raas service providers such as Altlayer and Caldera have become beneficiaries. It is hoped that more vertical public chains (application chains) will emerge. , creating better soil for Web 3.0 applications.
This article mainly dismantles the blockchain, initially learns about the modular blockchain project Celestia, and has a deeper understanding of the Blob in the Ethereum Cancun upgrade.
1.1 Origin
The earliest concept of modular blockchain was Data Availability Sampling and Fraud Proof co-authored by Celestia co-founders Mustafa Albasan and Vitalik in 2018 (Data Availability Sampling and Fraud Proofs). This paper focuses on how to solve the scalability problem without sacrificing Ethereum’s security and decentralization. What is unexpected is that it provides technical solutions not only for Ethereum, but also for other third-party DA layers.
The general logic is that full nodes are responsible for producing blocks, while light nodes are responsible for verification.
What is Data Availability Sampling (DAS)?
PS: This technology is at the core of Celestia technology and inadvertently provides a solution for third-party DA layers.
Content translated and adapted from: Paradigm-joachimneuData Availability Sampling: From Basics to Open Problems》
Refer to the following small black room model:
There is a bulletin board in the darkroom (see comic below). First, the block producer enters the room and has the opportunity to write some information on the bulletin board. When a block producer exits, it can provide validators with a small piece of information (the size of which does not scale linearly with the original data). You enter the room with a flashlight that has a very narrow beam and a very low battery, so you can only read the text in a very few different places on the bulletin board. Your goal is to convince yourself that the block producer actually left enough information on the bulletin board so that if you turned on the light and read the entire bulletin board, you would be able to recover the file.
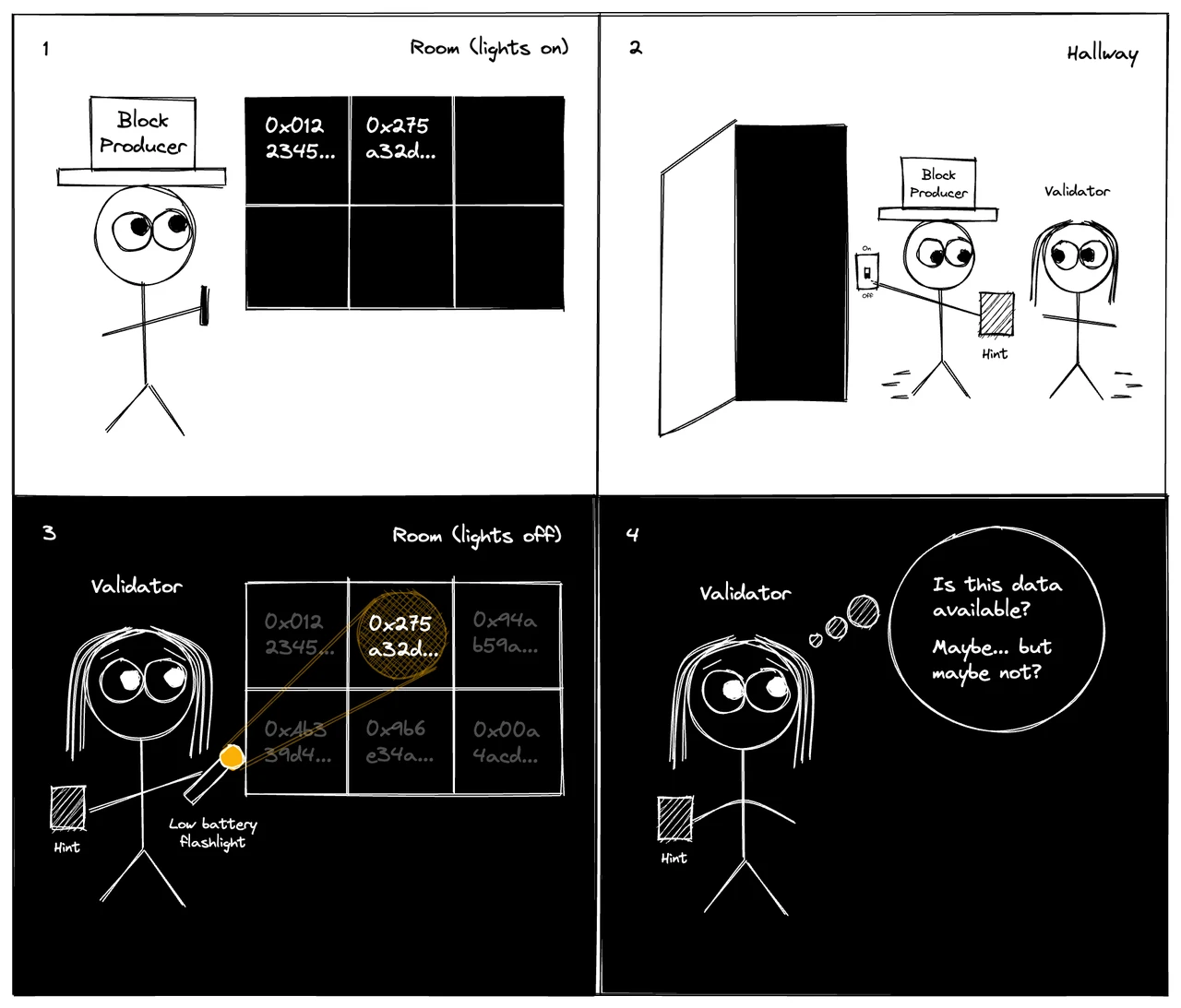
This model is naturally suitable for Ethereum and does not require much optimization, because Ethereum has enough validators (verification nodes). However, for other public chains with relatively few verification nodes, higher fees and more complex verification methods are required to ensure security.
So for projects with fewer verification nodes, they will face two situations: either the producer behaves honestly and writes a complete file, or the producer behaves inappropriately and leaves out a small part of the information, causing the entire file to be unavailable. The two cases cannot be reliably distinguished by examining bulletin boards at only a few locations.
One solution is: Erasure Correcting Reed-Solomon codes
Erasure coding works as follows: k blocks of information are encoded into a longer vector n coded blocks. The ratio r=k/n The redundancy of a code measures the redundancy introduced by the code. Subsequently, from some subset of the encoded blocks, we can decode the original information blocks.
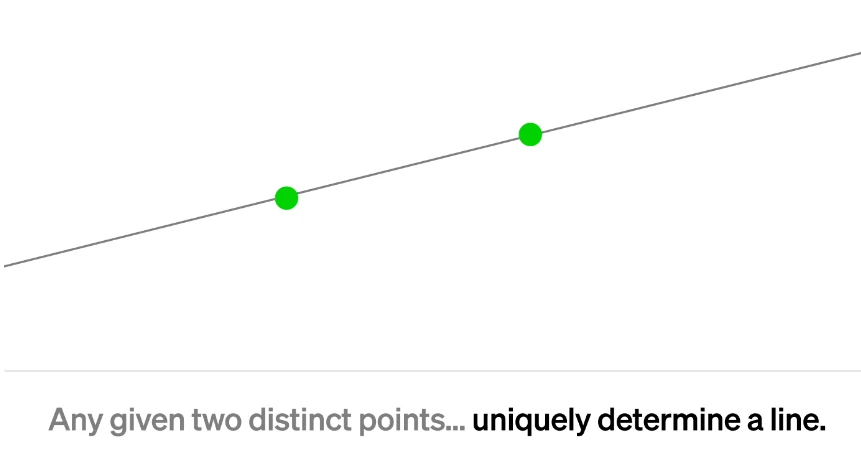
To put it simply, it is like two points determining a straight line. When r, k, and n are all determined initially, the straight line is determined. Then if you want to restore this straight line, you only need to know the two points on the straight line. .
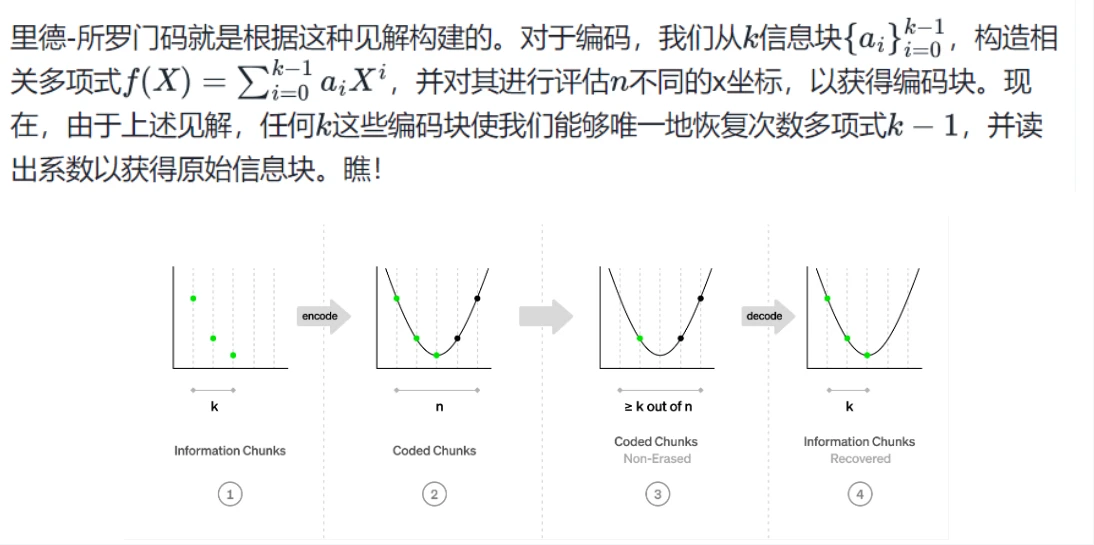
Reed-Solomon codes are further complicated by this logic, in that once the different positions of the evaluation of a polynomial are known, its evaluation can be obtained at any other position (by first recovering the polynomial and then evaluating it).
Back to our data availability problem: instead of requiring the block producer to write the original file on the bulletin board, we ask it to cut the file into blocks, encode them using Reed-Solomon codes, such as rate, and write out the Coding blocks are posted to the bulletin board. For now lets assume that block producers at least follow the encoding honestly - well see later how to eliminate this assumption. Again consider two scenarios: either the producer behaves honestly and writes all blocks, or the producer behaves inappropriately and wants to keep the file unavailable. Recall that we can encode blocks from any block outside of . Therefore, in order to keep the file unavailable, the block producer can write at most one large block. In other words, at least for now, more than half of the encoded blocks will be lost!
But now the two cases, a full bulletin board, and a half empty bulletin board, are easy to distinguish: you check the numbers on the bulletin board at small random sample locations, and if each sample location has its own block , the file is considered available, and if any sampling location is empty, the file is considered unavailable.
What are Fraud Proofs?
One way to exclude invalid encoding. This approach relies on the fact that some sampling nodes are powerful enough to sample so many blocks that they can detect inconsistencies in the block encoding and issue invalid encoding fraud proofs to mark the files in question as unavailable use. This effort aims to minimize the number of blocks that nodes must examine (and forward as part of the fraud proof) to detect fraud.
This solution ultimately sacrifices a small part of security, and in extreme cases data will be lost.
Interestingly, this plan laid the foundation for the birth of third-party DA layer projects Celestia and Avail, and Ethereum created competitors for itself.
In 2019, Mustafa Albasan wrote “LazyLegder》The responsibilities of the blockchain were simplified, only sorting and ensuring data availability were required, and other modules were responsible for execution and verification (it was not divided into different layers at the time), thus solving the scalability problem of the blockchain. This white paper should be regarded as the prototype of modular blockchain. Mustafa Albasan is also one of the co-founders of Celestia.
Celestia is the first modular blockchain solution. In its early days, it existed as an execution layer public chain, allowing smart contracts to be executed on it. Rollups expansion solution further clarifies the concept of the execution layer. Smart contracts are executed off-chain, and the execution results are compressed in batches into certificates and uploaded to the execution layer.
A small addition to the Rollup proof
A fraud proof (fraud proof) is a system that accepts the results of calculations. You can ask people with pledged deposits to sign a message of the following form: I prove that if you calculate C using input X, you will get output Y. You will trust the message by default, but others with staked deposits will have the opportunity to challenge the calculation. They can sign a message saying I disagree, the output should be Z, not Y. After only initiating the challenge, All nodes will perform calculations. An error by either of these two parties will result in loss of deposit and all calculations based on incorrect calculations will be redone.
ZK-SNARKs are a form of cryptographic proof that can directly verify that after inputting X, performing calculation C, Y will be output. At the cryptographic level, this verification mechanism is reliable because if after inputting Even though running the computation C itself takes a lot of time, the proof can be verified very quickly. ZK means that proof and verification can be completed more efficiently, so Vitalik also highly recommends ZK-Rollup. However, like sharding, the technical difficulty is far greater than that of fraud proof, and it will take many years to achieve. At the same time, it may be more efficient. bring additional costs.
1.2 Trade-offs in the impossible triangle problem of blockchain
The impossible triangle of blockchain: scalability, decentralization, and security.
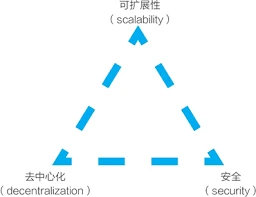
To simply define a measurement standard,
Scalability: Scalability (good) = TPS (high) + Gas fee (low) + verification difficulty (low)
Decentralization and security: Decentralization (high) + security (good) = number of nodes (large) + single node hardware requirements (low)
The two generally can only choose to meet one condition, sacrificing the other to a certain extent, which is why the development of Ethereum in scalability is extremely slow; Vitalik and the Ethereum Foundation are very concerned about both security and decentralization. This feature has the highest priority.
Like some traditional high-performance Layer 1, such as Solana (1,777 validators) and Aptos (127 validators), they began to pursue scalability when the number of validators was less than the number of Ethereum nodes (5,000+) The cost is high threshold requirements for nodes and expensive operating costs; on the other hand, Ethereum only began to pursue scalability when it had hundreds of thousands of validators (currently 900k+) and ensured absolute decentralization and security. It is enough to see how much the Ethereum Foundation attaches importance to these two characteristics.
Number of Solana validators:
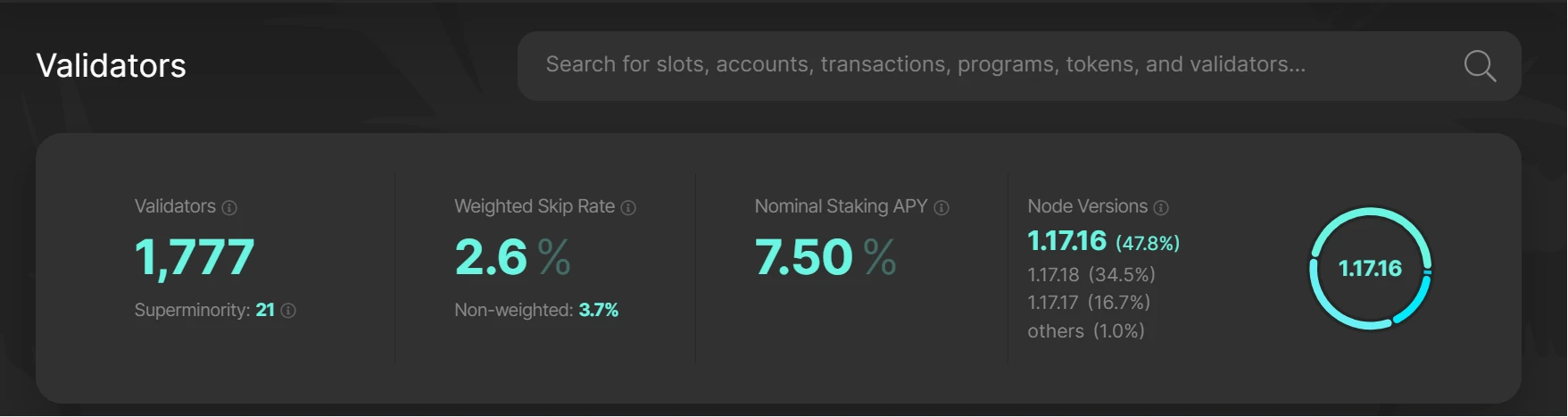
Data Sources:https://solanabeach.io/validators
Number of Ethereum validators:
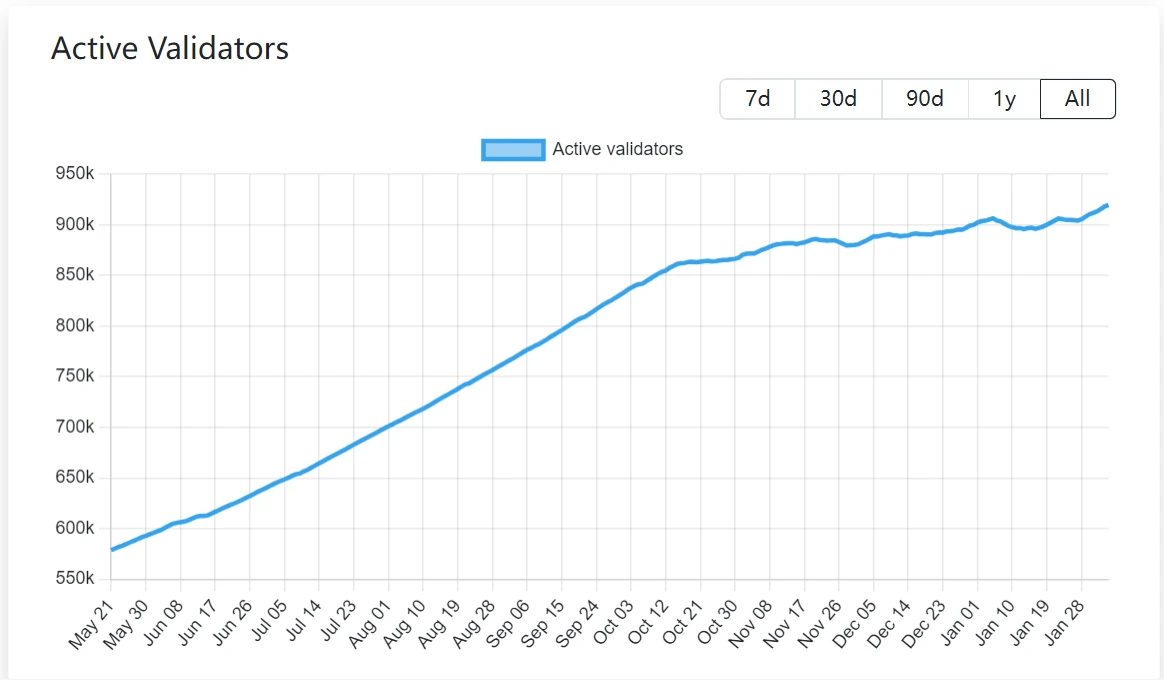
Data Sources:https://www.validatorqueue.com/
In addition, compared with high-performance Layer 1’s stringent requirements for nodes and centralized verifiers, future upgrades of Ethereum will further reduce the verification difficulty of verifiers, thereby further reducing the requirements for users to become verifiers.
1.3 Importance of data availability
Usually, when a transaction is submitted to the chain, it will first enter the Mempool, where it will be selected by miners, packaged into a block, and the block will be spliced into the blockchain. The block containing this transaction will be broadcast to all nodes in the network. Other full nodes will download this new block, perform complex calculations, and verify each transaction to ensure that the transaction is authentic and valid. Complex calculations and redundancy are the foundation of Ethereum’s security, and they also bring problems.
1.3.1 Data availability
There are usually two types of nodes:
Full node - download and verify all block information and transaction data.
Light node - a non-fully verified node, easy to deploy, and only verifies the block header (data digest). First, ensure that when a new block is generated, all data in the block has indeed been published so that other nodes can verify it. If the full node does not publish all the data in the block, other nodes cannot detect whether the block hides malicious transactions.
The node needs to obtain all transaction data within a certain period of time and verify that there is no confirmed but unverified transaction data. This is data availability in the usual sense. If a full node conceals some transaction data, other full nodes will refuse to follow this block after verification. However, light nodes that only download the block header information will not be able to verify and will continue to follow this forked block, affecting Safety. Although the blockchain usually forfeits the deposit of the full node, this will also cause losses to the users who pledged to the node. And when the income from concealing data exceeds the cost of forfeiture, nodes will have an incentive to conceal it. At that time, the actual victims will only be the staking users and other users of the chain.
On the other hand, if the full node deployment gradually becomes centralized, there is a possibility of collusion between nodes, which will endanger the security of the entire chain.
Data availability is attracting more and more attention, on the one hand because of the Ethereum PoS merger, and on the other hand the development of Rollup. Currently Rollup will run the centralized sequencer (Sequencer). Users transact on Rollup, and the sequencer sorts, packages, and compresses the transactions, publishes them to the Ethereum main network, and all main network nodes verify the data through fraud proof (Optimistic) or validity proof (ZK). As long as all the data of the block submitted by the sequencer is truly available, the Ethereum main network can track, verify, and reconstruct the Rollup state accordingly to ensure data authenticity and user property security.
1.3.2 State explosion and centralization
State explosion means that Ethereum full nodes accumulate more and more historical and status data, and the storage resources required to run full nodes are increasing, and the operating threshold is increased, leading to the centralization of network nodes.
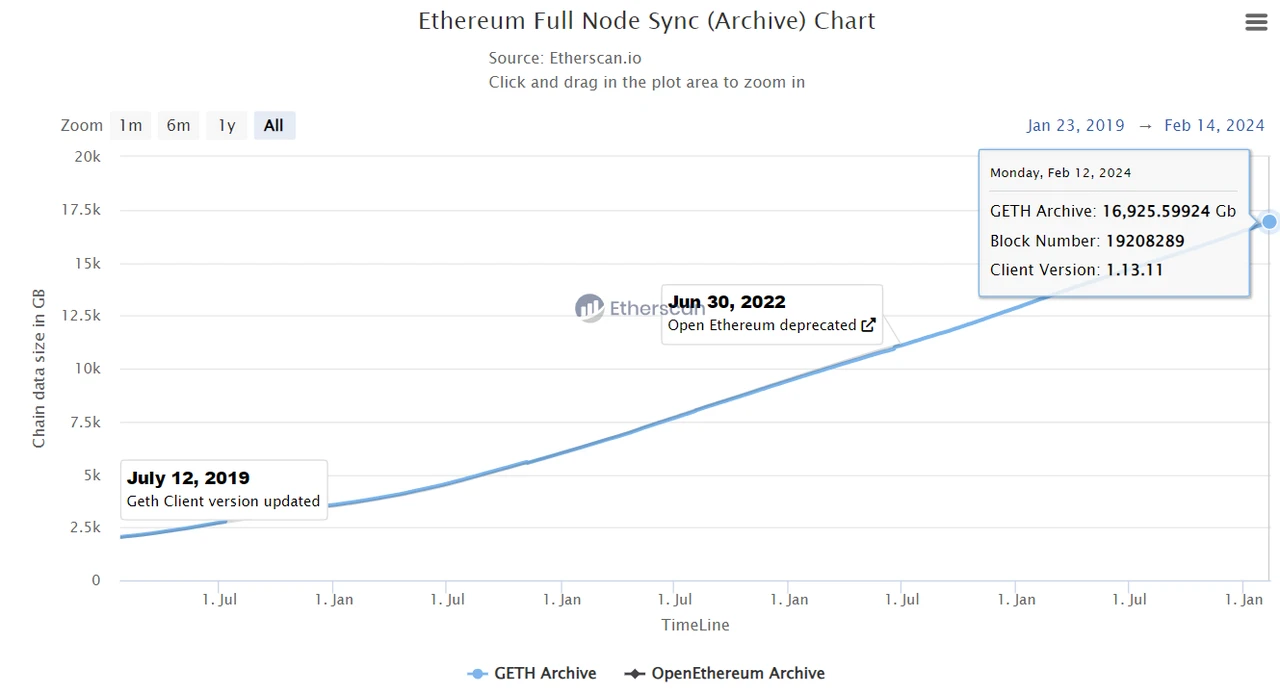 Image Source:https://etherscan.io/chartsync/chainarchive
Image Source:https://etherscan.io/chartsync/chainarchive
Therefore, there is a need for a way so that the full node does not need to download all the data when synchronizing and verifying the block data, but only needs to download some redundant fragments of the block.
At this point, we understand that data availability is important. So, how to avoid the tragedy of the commons? That is to say, everyone knows the importance of data availability, but there still needs to be some practical benefit drivers for everyone to use a separate data availability layer.
Just like everyone knows that protecting the environment is important, but when seeing garbage on the roadside, why should I pick it up? Why not someone else? What benefits will I get from picking up the trash?
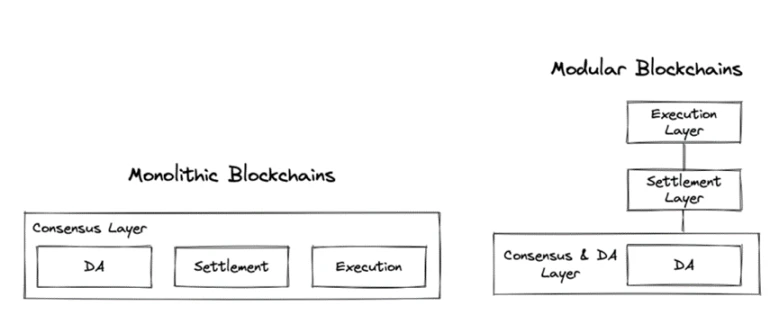
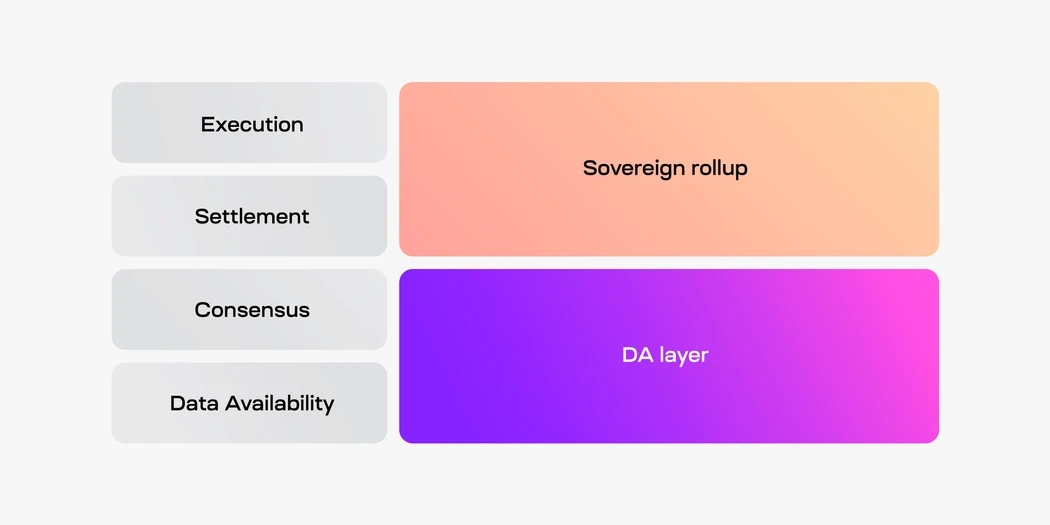
1.4 Simple splitting of blockchain
When on-chain actions occur (for example: Swap, Stake, Transactions...), the following 4 steps must be taken
Execution: Start trading
Settlement: verify data, handle issues
Consensus: All nodes agree
Data availability: synchronize data to the chain
Based on this, LazyLedger proposes to modularize the blockchain, while Celestia standardizes the modular blockchain:

Execution Layer
Responsibilities: Responsible for executing smart contracts and processing transactions, and handing the execution results to the settlement layer in the form of proof; it is also the place where various applications for users are deployed.
Corresponding projects: various Stacks, Op stack, ZK Stack, Cosmos Stack, Layer 2 on Ethereum
Settlement Layer
Responsibilities: Responsible for providing global consensus and security, verifying the correctness of L2 execution results, and updating user status; for example: changes in the asset status of user accounts; updates to the status of the chain itself (Token transfer, new contract deployment)
Corresponding projects: Ethereum, BTC
PS: The more nodes there are, the higher the security.
Consensus Layer
Responsibilities: Responsible for the consistency of the entire node, ensuring that newly added blocks are valid and determining the order of transactions in the memepool
Corresponding projects: Ethereum (beacon chain), Dymension
Data Availability Layer, Data Availability Layer
Responsibilities: Responsible for ensuring the availability of data so that the execution layer and settlement layer can run separately; all original transactions of the execution layer are ensured to be stored here, and the settlement layer is verified by the DA layer
Corresponding projects: Celestia, Polygon Avail, EigenDA (DA made by Eigenlayer), Eth Blob + future Danksharding, Near, centralized DA
Celestia is a Layer 1 blockchain focusing on data availability and consensus layers; Optimism and Arbitrum are Layer 2 blockchains focusing on the execution layer; Dymension is focusing on the settlement layer.
2. Ethereum modularization progress
2.1 Current architecture
One picture to summarize, no need to go into details.
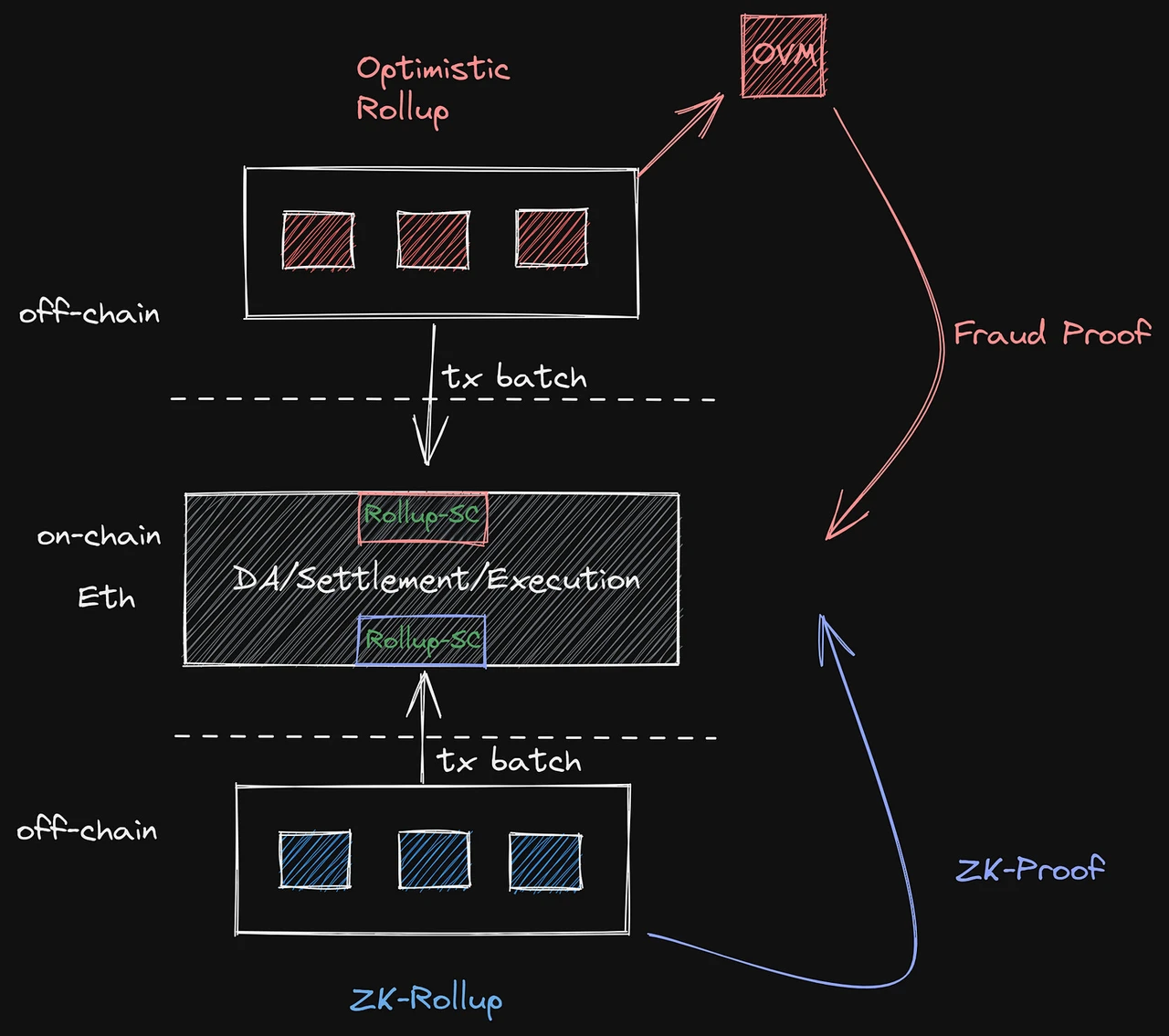
2.2 Long-term development - sharding into multiple work chains
Ethereum has been gradually modularizing itself since the Paris upgrade (and Merge).
Consensus layer/settlement layer: beacon chain
Execution layer: (fully outsourced to) Rollup
DA layer: Calldata (present)/Blob (after Cancun upgrade)/Danksharding (future/endgame)
One of the cores of Vitaliks current Ethereum expansion plan in the future is Rollup-Centric. The potential outcome can be referred to the following figure:
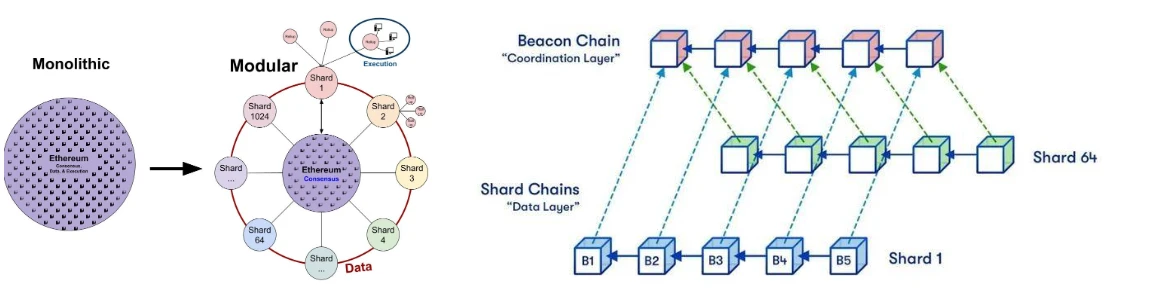
It is fragmented into multiple work chains with different expertise. The consensus, security and settlement layers all inherit from Ethereum. Each chain has a corresponding Rollup responsible for the execution layer.
According to current research, there is little public information on the technical difficulty of sharding. The Ethereum Foundation believes that it will take several years to complete complete sharding.
2.3 Sharding transition plan—EIP-4844 Proto-Danksharding/Cancun upgrade
The Dencun hard fork has been confirmed to be on March 13, 2024. The specific results can be roughly concluded regarding the reduction of gas fees and the improvement of TPS.
The most important thing about the Cancun upgrade is the addition of a new transaction mode, Blob.
Some characteristics of Blob:
One transaction 2 blobs, 258 kb
A block can have a maximum of 16 blobs, 2 mb, but Ethereum has a gas fee baseline. When it is greater than 1 mb, this will cause the next blockchain fee to increase; the ideal state is 8 blobs, that is, 1 mb
Blob security is equivalent to L1 because it is also stored and updated by full nodes.
It will be automatically deleted after 30 days
Blob uses KZG Hashmmitment as Hash for data verification, similar to Merkle. Understood as a download certificate status
The cache space occupies relatively few network resources. The Ethereum Foundation has set a relatively low Gas fee for blob through EIP-1559 (separating gas fees for different types of transactions). Blob can be understood as each block in Ethereum. Several cache packages are plugged in, and the transaction data is stored in them for verification and challenge by the full node. Then it will disappear after 30 days. Finally, a KSG is uploaded to prove that it has been verified and consensus reached.
Data source: https://etherscan.io/chart/blocksize
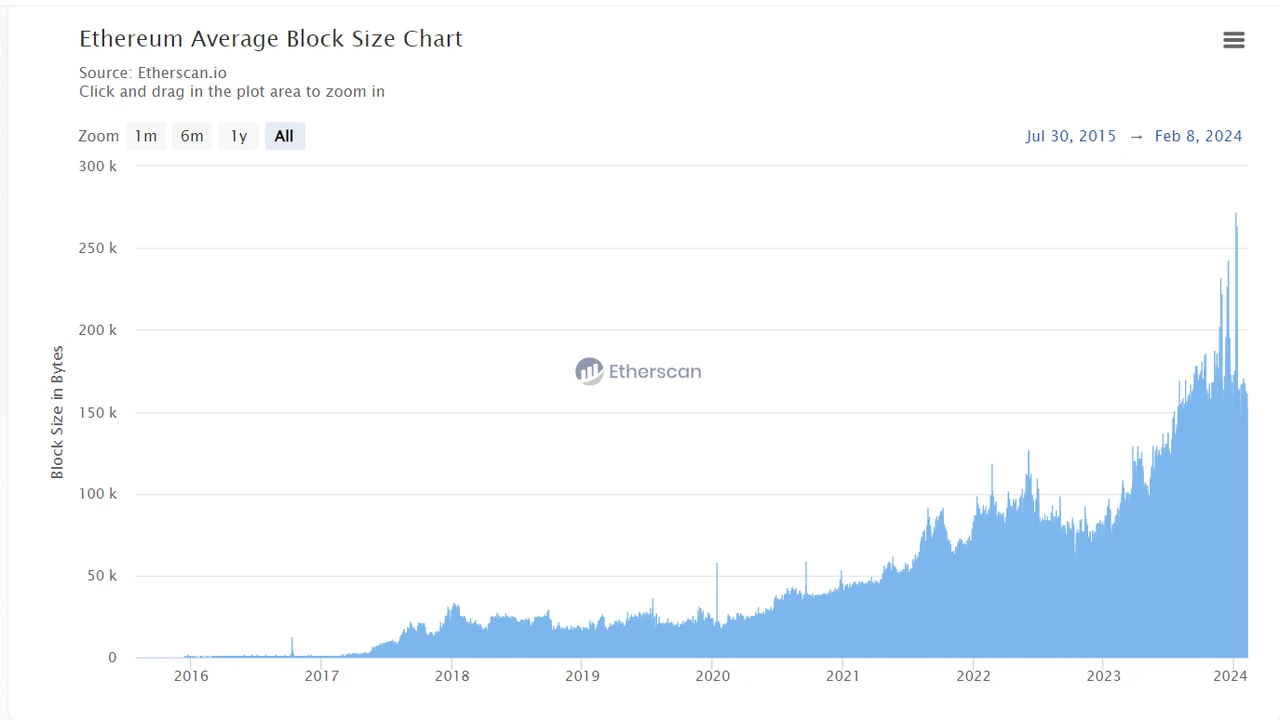
How to understand?
A block is now about 150 kb, a blob is 128 kb, and the space of 8 blobs is about 1 M, which has been expanded by 6 or 7 times. In addition, the gas fee has been reduced through EIP-1559; the transaction data to be uploaded for a single transaction has become less. The number of transactions carried by a single block increases, which ultimately leads to an increase in TPS and a decrease in gas fees.
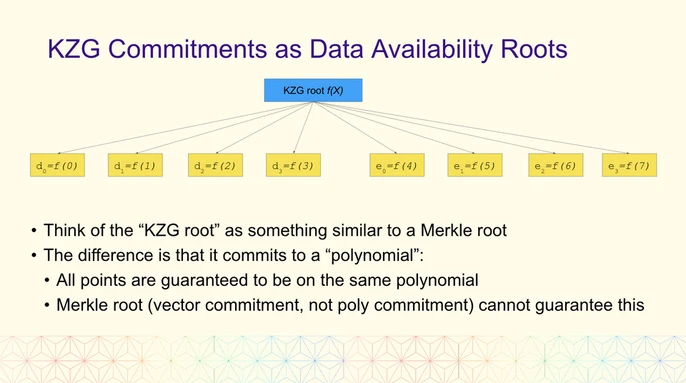
KZG Commitments
The KZG proof is somewhat similar to the Merkle tree (which records the state of Ethereum), which records the state of transaction data.
KZG Polynomial Commitment (KZG Polynomial Commitment), also known as the Carter polynomial commitment scheme, was published by Kate, Zaverucha and Goldberg. In a polynomial scheme, the prover computes the commitment of a polynomial and can open it at any point of the polynomial. The commitment scheme proves that the value of the polynomial at a specific position is consistent with a specified value.
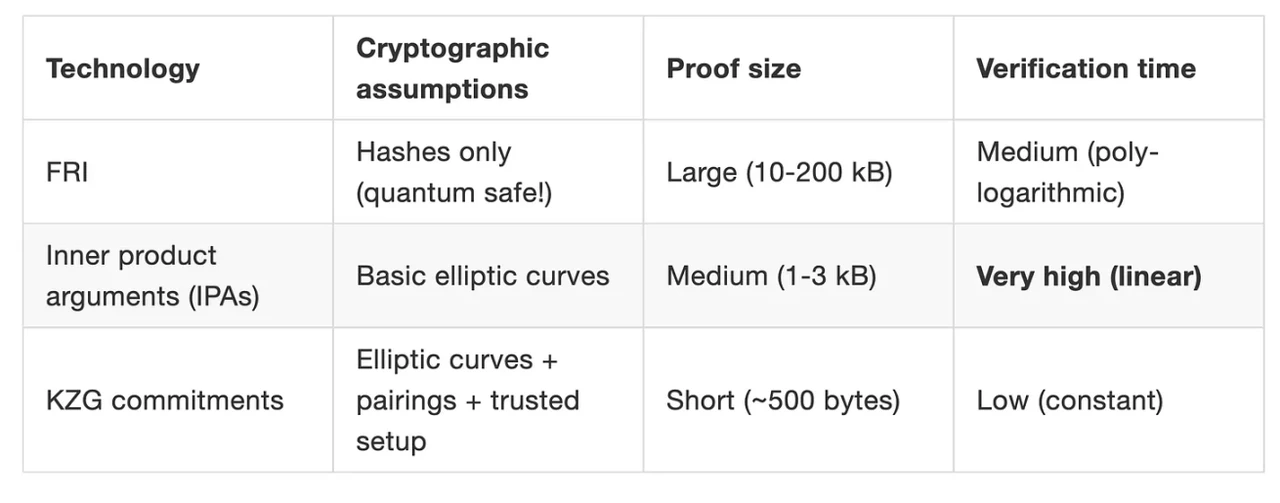
FRI is the polynomial commitment scheme adopted by Starkware, which can achieve quantum-level security, but the amount of data proved is the largest; IPA is the default polynomial commitment scheme of Bulletproof and Halo 2 zero-knowledge algorithms. The verification time is relatively long, and the projects used are: Monero, zcash, etc., the first two do not require initial trusted settings.
In terms of proof size and verification time, KZG polynomial commitment has greater advantages. KZG commitment is also the most widely used polynomial commitment method currently.
2.4 Summary
Changes before and after the process Rollup was originally going to package and compress transactions: the most important thing is that the transaction data that originally occupied a relatively large space was turned into a KSG proof that occupied a small space and had a fast verification time.
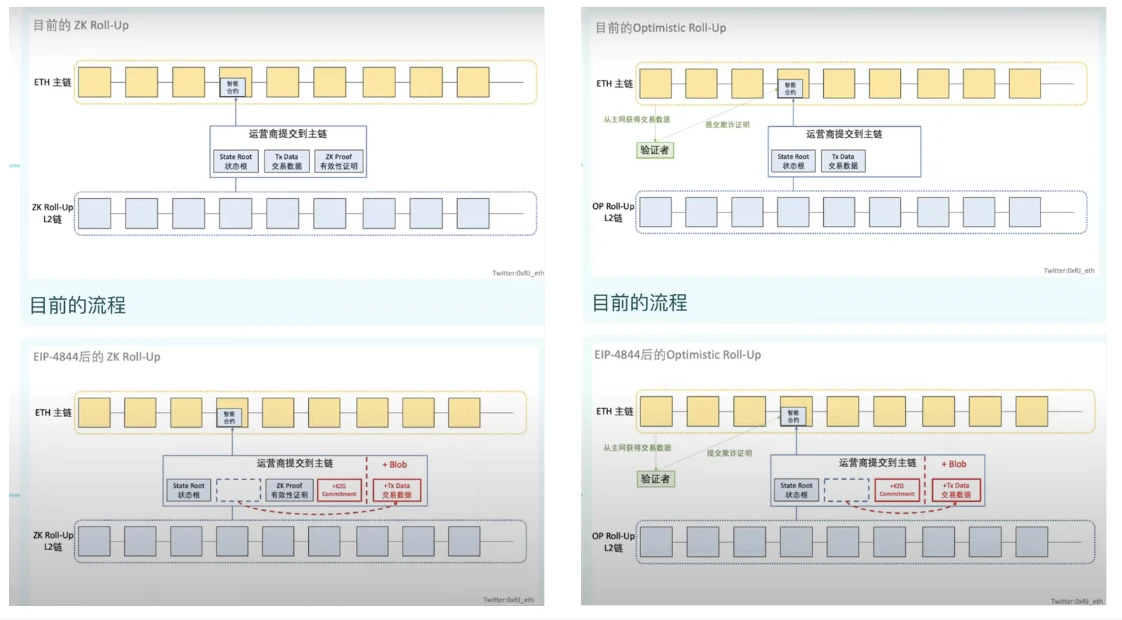
2.5 Other perspectives
The following is quoted from:https://twitter.com/0x Ning 0x/status/1758473103930482783
Will the gas fee of Ethereum L2 really be reduced by more than 10 times after the Cancun upgrade?
There is a consensus in the market today: After the Cancun upgrade, the average gas fee of Ethereum L2 will be reduced by 10 times or even higher.
After the deployment of the Cancun upgraded core protocol EIP 4844, the Ethereum mainnet will add three new Blob spaces dedicated to saving L2 transactions and status data, and these Blobs have independent Gas Fee markets. It is estimated that the maximum size of state data stored in 1 Blob space is approximately equal to 1 mainnet block, which is ~ 1.77 M.
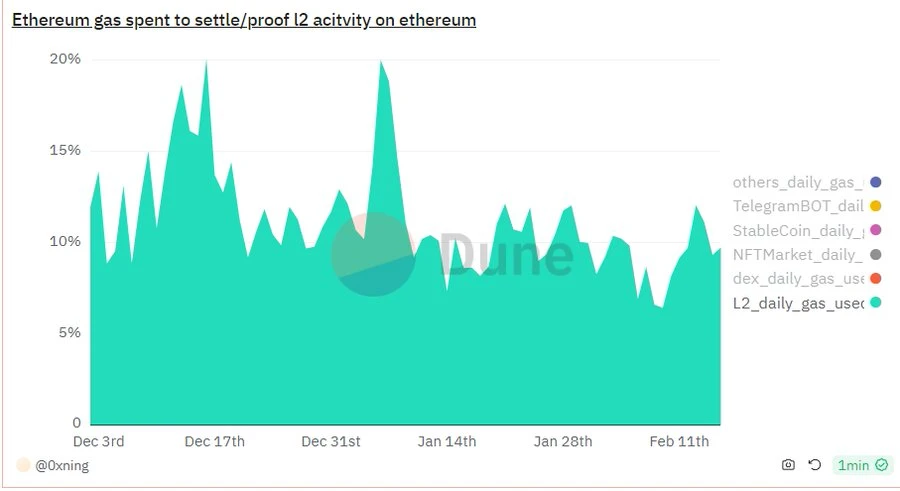
The current daily gas consumption of the Ethereum main network is 107.9 b, and the gas consumption of Rollup L2 accounts for ~10%.
According to the economic supply and demand curve:
Price = total demand/total supply,
Assuming that the total Gas demand of Rollup L2 remains unchanged after the Cancun upgrade, and the block space that Ethereum can sell to L2 changes from ~10% of the current 1 block to 3 complete Blob blocks, this is equivalent to the area If the total supply of block space is expanded by 30 times, the price of Gas will be reduced to 1/30 of the original value.
However, this conclusion is not reliable because it presupposes too many linear relationship assumptions and abstracts away too many detailed factors that should be included in calculations and considerations, especially the competition between Rollup L2 for Blob space and the effect of game strategy on Gas. price impact.
The Gas fee consumption of Rollup L2 is mainly composed of two parts: data availability storage fee (state data storage fee) + data availability verification fee. Among them, data availability storage costs currently account for ~ 90%.
After the Cancun upgrade, for Rollup L2 people, the three new Blob blocks are equivalent to three new public lands. According to Coases commons theory, in a market environment of complete free competition in the Ethereum Blob space, there is a high probability that the currently leading Rollup L2 players will abuse the Blob space. This can ensure their market position on the one hand, and squeeze the living space of competitors on the other.
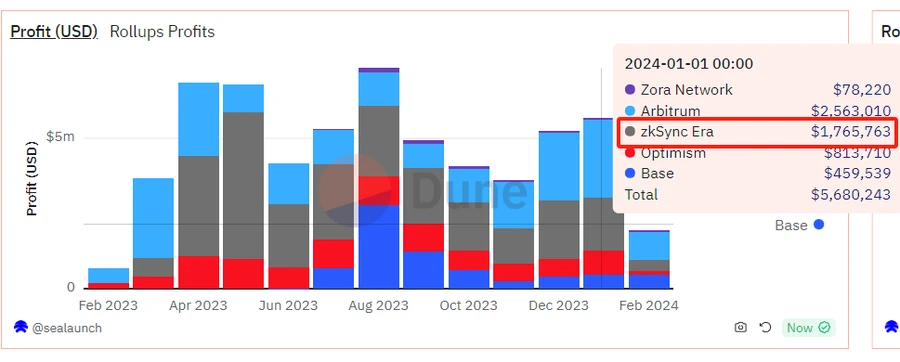
The figure below shows the 1-year profit statistics of five Rollup L2 companies. It can be found that their monthly profit scale shows obvious seasonal changes, but there is no obvious overall growth trend.
In such an involution market with ceiling restrictions, Rollup L2s are in a highly tense zero-sum game, competing fiercely for developers, funds, users and DApps. After the upgrade of Cancun, they are fiercely competing for three additional blob spaces.
In the market situation of there is only so much meat, if someone else eats one more bite, you will eat one less bite, it is difficult for Rollup L2 to achieve a Pareto-optimal ideal situation.
So how will the leading Rollup L2s abuse Blob space?
My personal guess is that the leading Rollup L2s will modify the Batch frequency of the Sequencer and shorten the Batch from once every few minutes to once every 12 seconds to keep pace with the block production speed of the Ethereum main network. This can not only improve the quick confirmation of transactions on your own L2, but also occupy more blob space to suppress competitors.
Under this competitive strategy, the verification fees and Batch fees in the Gas fee consumption structure of Rollup L2 will surge. This will limit the positive impact of the additional blob space on L2 gas fee reduction.
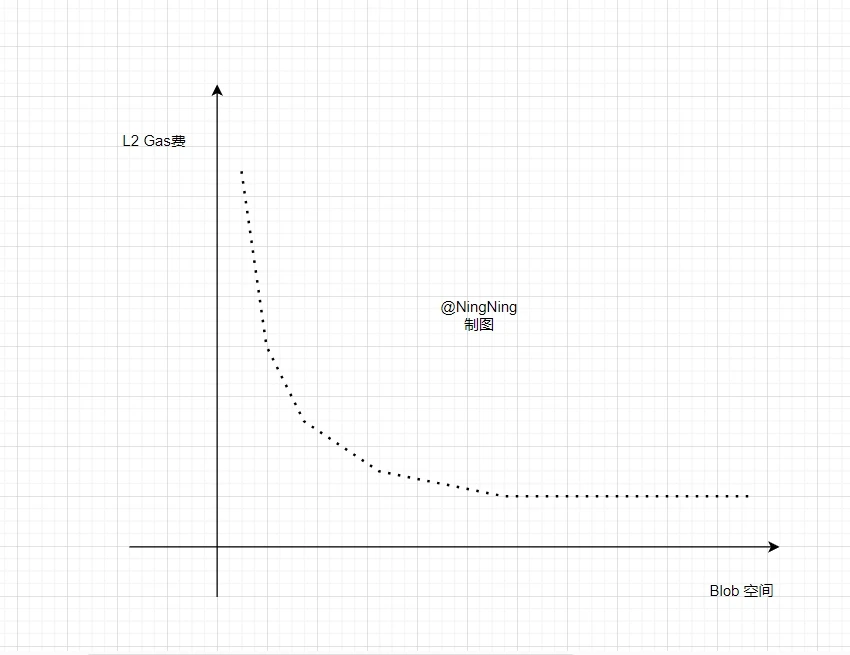
The results are shown in the figure above. When the Blob space increases, the positive impact on L2 Gas fee reduction will decrease marginally. And after reaching a certain threshold, it will almost fail.
Based on the above analysis, I personally judge that the gas fee of Ethereum L2 will decrease after the Cancun upgrade, but the decrease will be less than market expectations.
above. Looking forward to more discussions.
3. Celestia
Celestia provides an accessible data availability layer and consensus for other Layer 1 and Layer 2, and is built based on the Cosmos Tendermint consensus and Cosmos SDK.
Celestia is a Layer 1 protocol that is compatible with EVM chains and Cosmos application chains. It will support all types of Rollups in the future. These chains can directly use Celestia as the data availability layer. Block data will be stored, called, verified through Celestia, and then returned to itself. There is an agreement to liquidate.
Celestia also supports native Rollup, and Layer 2 can be built directly on it, but it does not support smart contracts, so dApp cannot be built directly.
3.1 Development history
Mustafa Al-Bassam — Co-founder and CEO, holds a BA in Computer Science from Kings College London and a PhD in Computer Science from University College London. Al-Bassam was the founder and core member of the famous hacker organization LulzSec when he was 16 years old, and has been engaged in hacking activities for a long time. In August 2018, Al-Bassam co-founded the blockchain expansion research team Chainspace. In 2019, the team was acquired by Facebook.
In May 2019, he published the LazyLedger paper, and founded LazyLedger (later renamed Celestia) in September of the same year, and has served as CEO to this day.
On March 3, 2021, it raised US$1.5 million in seed round financing, with investors including Binance Labs and others.
Updated to Celestia on June 15, 2021, and released a minimum viable product, a data availability sampling light client; the development network was launched on December 14, 2021; the Mamaki test network was launched on May 25, 2022
Sovereign rollup plan Optimint launched on August 3, 2022
Raised US$55 million on October 19, 2022, led by Bain Capital and Polychain Capital, with participation from Placeholder, Galaxy, Delphi Digital, Blockchain Capital, Spartan Group, Jump Crypto and others.
The newly developed testnet Arabica and testnet Mocha will be launched on December 15, 2022.
The modular Rollup framework Rolkit was launched on February 21, 2023.
The incentivized test network Jiahua Blockspace Race will be launched on February 28, 2023; the new test network Oolong will be launched on July 5.
The governance token TIA will be released on September 26, 2023.
3.2 Celestia composition
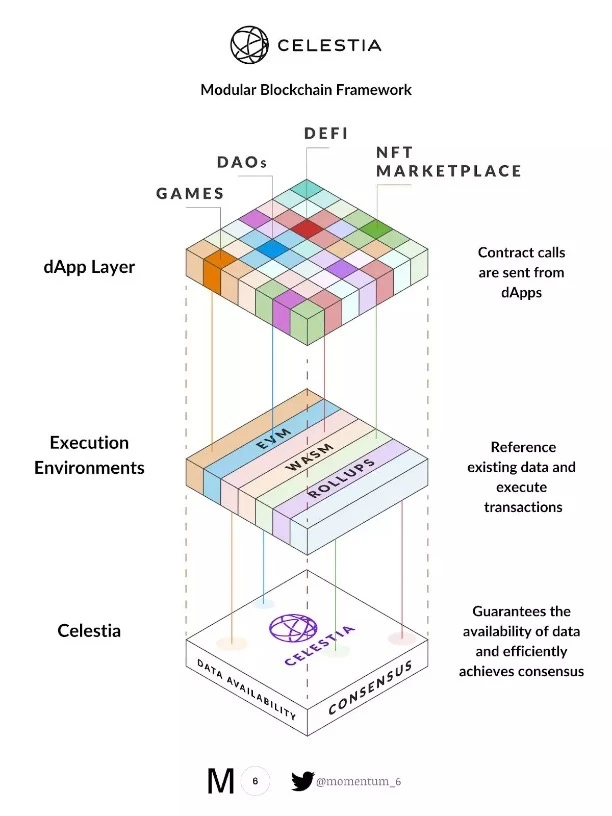
Celestia mainly consists of three components; Optimint, Celestia-app and Celestia-node.
The Celestia-node component is tasked with achieving consensus and networking for this blockchain. This component determines how light nodes and full nodes generate new blocks, sample data from blocks, and synchronize new blocks and block headers.
Using Optimint, Cosmos Zone is deployed directly on Celestia as a Rollup. Rollup collects transactions into blocks and then publishes them to Celestia for data availability and consensus. The chains state machine resides in the Celestia application, which is the application that handles transaction processing and staking.
On Optimint, improvements will be made in synchronized blocks, data availability layer integration, common tools, and index transactions. Within the Celestia application, the team will work on the implementation of transaction fees and evaluate upgrades to ABCI++. Ultimately, the team hopes to make its network services more robust on Celestia nodes and improve light node and bad coding fraud proofing.
How to interact with Rollup?
Celestia divides Rollup into its own native version and Ethereum native version. The former is very simple. Rollup can directly deal with Celestia, upload the data first, and then let Celestia check the data availability. Finally, Rollup will verify it after seeing the new status. Celestia can be said to be very leisurely during the whole process, and it even uploads to Rollup. The data represents nothing (because it only has sliced samples), and Rollup looks to it for data availability only because it is cheaper and has better performance.
Interaction case:
There is a stack where the execution layer does not publish block data directly to the settlement layer, but directly to Celestia. In this case, the execution layer simply publishes its block header to the settlement layer, which then checks whether all the data for a certain block is included in the DA layer. This is done through a contract on the settlement layer, which receives a Merkle tree of transaction data from Celestia. This is what we call data proof.
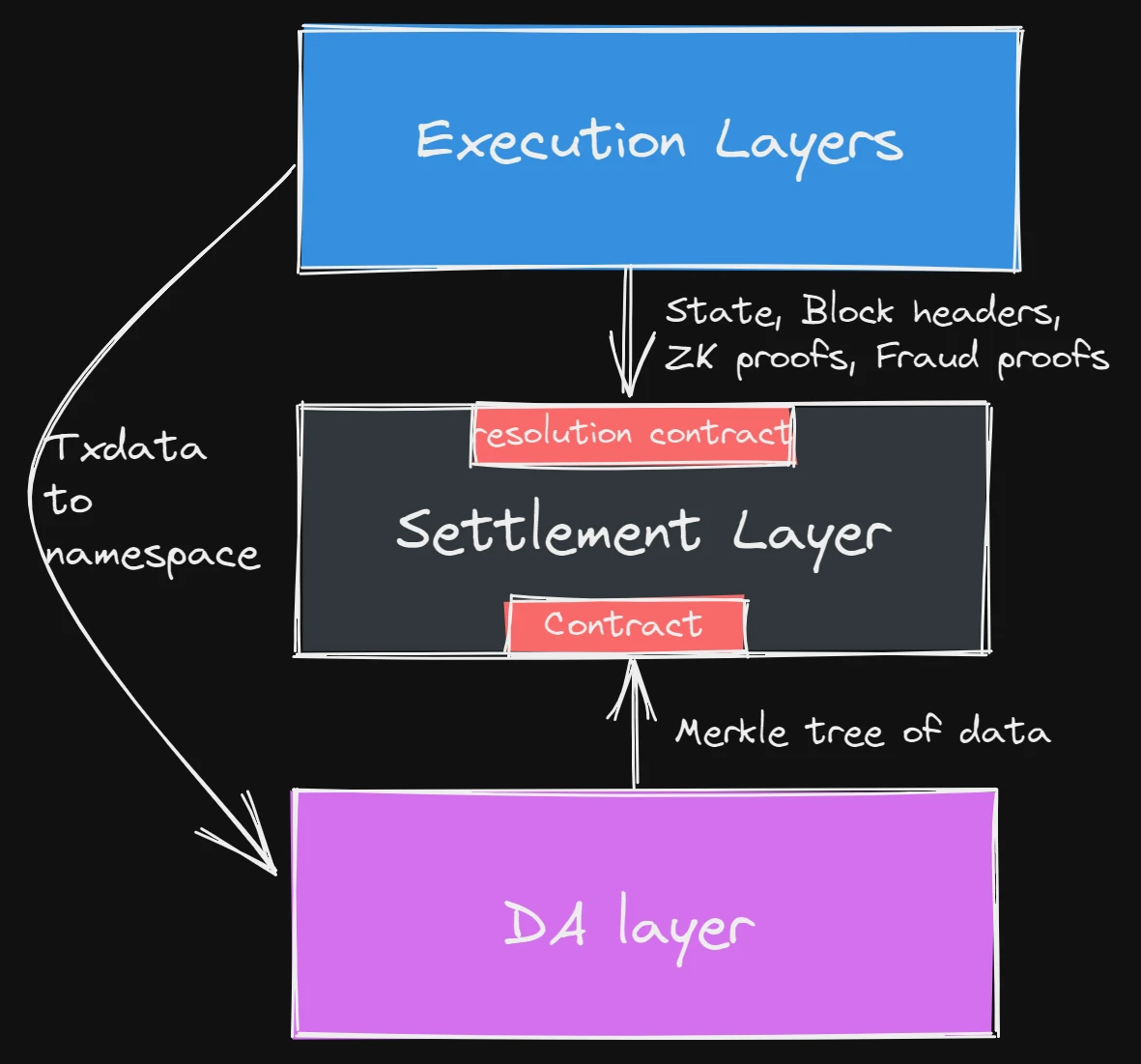
In Ethereum, the situation is a bit more complicated. First of all, Ethereum currently does not have sharding and DAS, but even if Rollups cannot bear the cost of on-chain processing, they can still move to off-chain and let the most famous third-party audit agency in the industry For data availability, the cost can even be so low as to be negligible. In fact, ZK 2.0 is already doing this, not to mention the likes of StarkEx and Plasma. Of course, in Celestia’s view, off-chain verification is centralized after all, and the possibility of evil cannot be ruled out. But even if these institutions do evil, all these off-chain validators can do is freeze transactions for a period of time.
The plan of ZK 2.0 is to provide users with more choices. If users can tolerate the high cost, it is better to put data availability on Ethereum. If users can accept the assumption that transactions will be frozen in the worst case, then ZK 2.0 can Give a super low gas out.
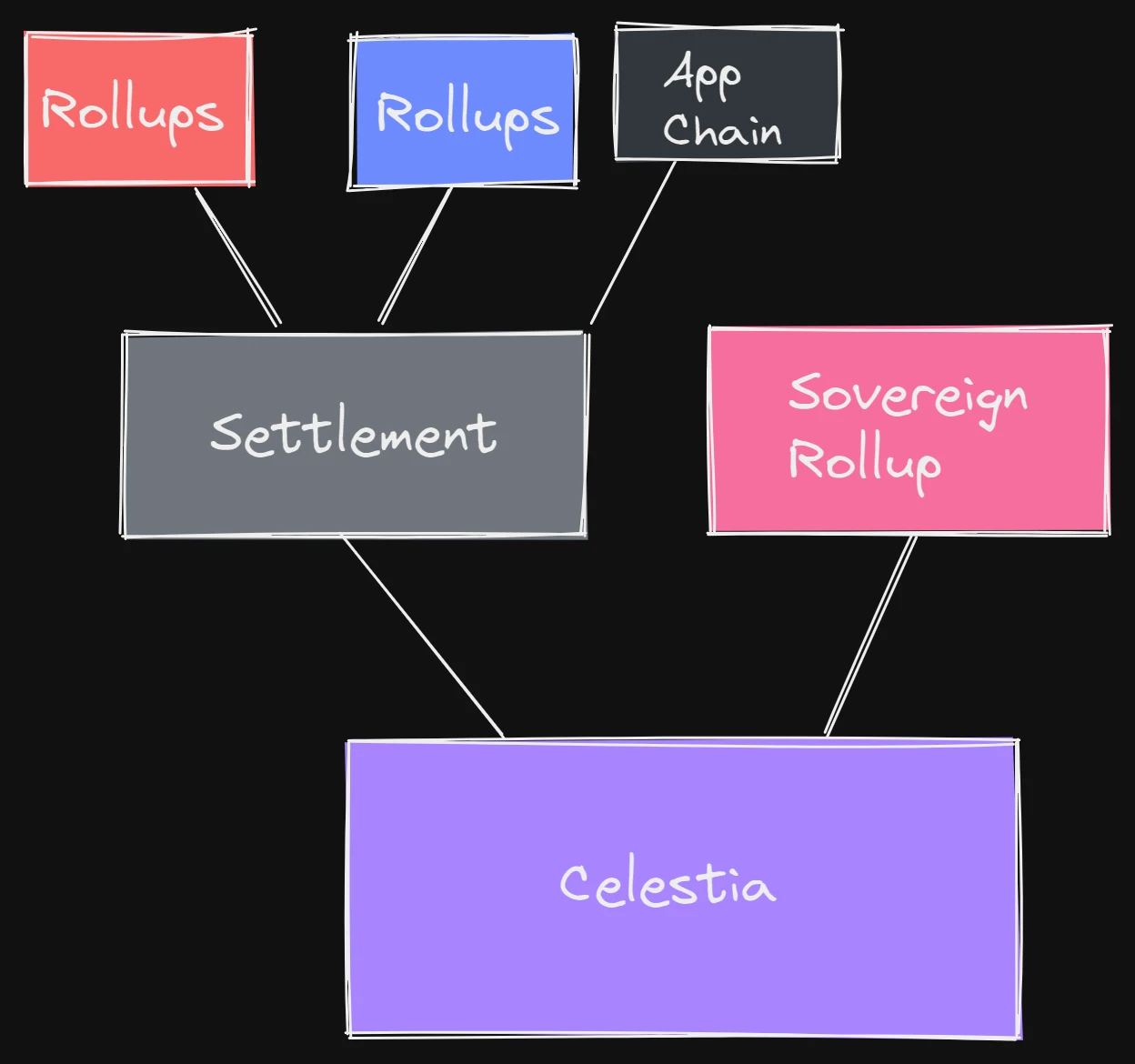
Overall structure
Celestia will serve as a shared consensus and data availability layer between all the various types of rollups running in the modular stack. The settlement layer exists to facilitate bridging and liquidity between the various rollups on it. It is also possible to see sovereign rollups operating independently, without a settlement layer.
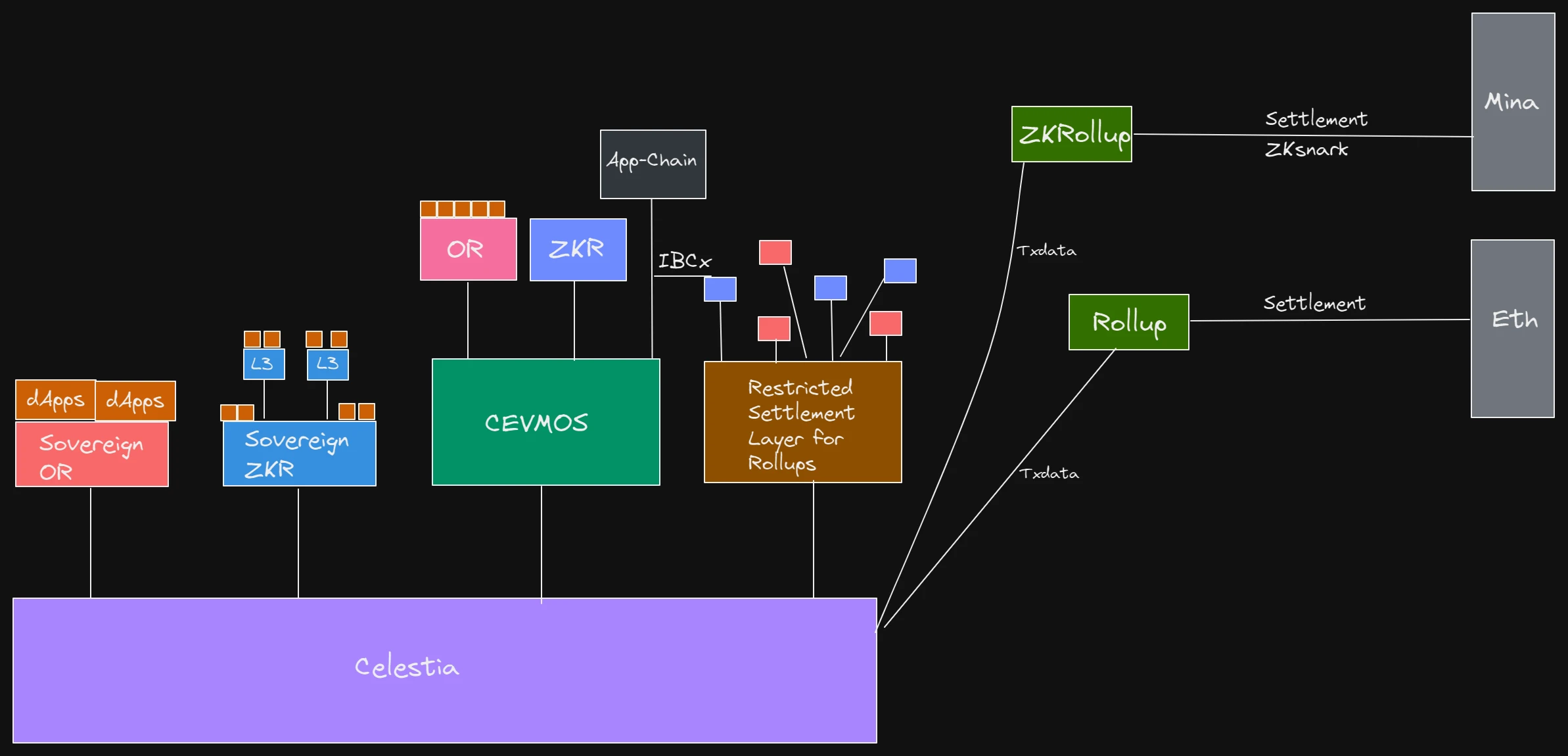
3.3 How to implement light node verification while ensuring security
Two key functions of its DA layer are data availability sampling (DAS) and namespace Merkle trees (NMT).
DAS enables light nodes to verify data availability without downloading the entire block. Light nodes cannot verify data availability because they only download the block header. Celestia uses the 2-dimensional Reed-Solomon encoding scheme to re-encode the block data to implement DAS for light nodes. Data Availability Sampling (DAS) works by having light nodes conduct multiple rounds of random sampling of small portions of block data. As light nodes complete more rounds of block data sampling, the confidence that the data is available increases. Data is considered available once a light node successfully reaches a predetermined confidence level (e.g., 99%).
NMT enables the execution and settlement layers on Celestia to download only the transactions relevant to them. Celestia divides the data in the block into multiple namespaces. Each namespace corresponds to applications such as rollup built on Celestia. Each application only needs to download data related to itself to improve network efficiency.
Celestia can be verified with light nodes. We all know that the more nodes there are, the more secure the network will be. Another advantage of light nodes is that the more nodes there are, the faster the network will be and the lower the cost will be.
Celestia is also key to Celestias ability to reduce costs by identifying blocks that conceal transaction data, primarily through data availability and erasure coding.
3.3.1 Data Availability Sampling (DAS) and Erasure Coding
This technical solution solves the verification problem of data availability, allowing Celestia to perform light node verification.
Also makes the cost of Celestia sublinear.
Generally speaking, light nodes in the blockchain network will only download the block header containing the block data (i.e. transaction list) commitment (i.e. Merkle root), which makes the light node unable to know the actual content of the block data, thus Unable to verify data availability.
However, after applying the 2-dimensional RS erasure coding scheme (2-dimensional Reed-Solomon encoding scheme), it becomes possible to use light nodes for data availability sampling:
First, the data of each block will be divided into kk blocks and arranged in a kk matrix. Then by applying RS erasure code multiple times, such a kk matrix containing block data can be expanded into a 2 k 2 k matrix.
Celestia will then calculate 4k individual Merkle roots for the rows and columns of this 2k*2k matrix as the block data commitment in the block header.
Finally, during the process of verifying data availability, Celestias light node will sample 2 k* 2 k data blocks. Each light node will randomly select a set of unique coordinates in this matrix and query the data in all nodes. The block content and the corresponding Merkle proof at the coordinates indicate that if the node receives a valid response to each sampling query, it proves that the block has a high probability of data availability.
In addition, every data block that receives a correct Merkle root proof will be propagated to the network, so as long as the light nodes can sample enough data blocks together (i.e., at least k*k unique data blocks), the complete block The data can be restored by honest full nodes.
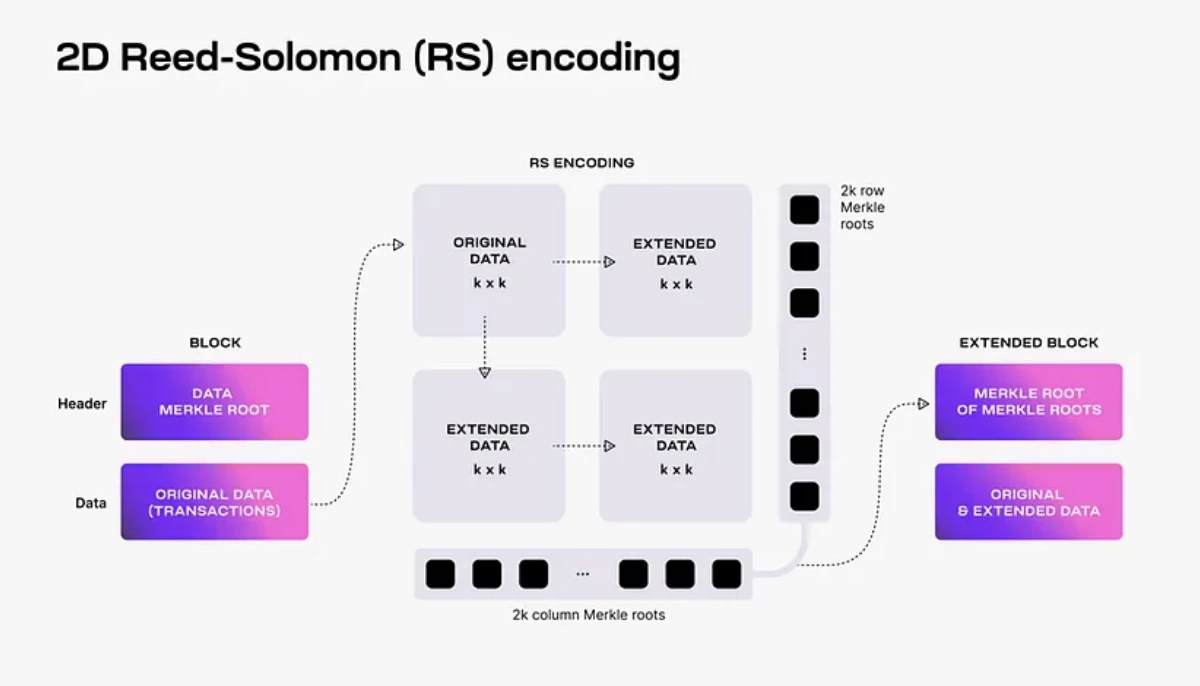
Two-dimensional RS erasure coding scheme
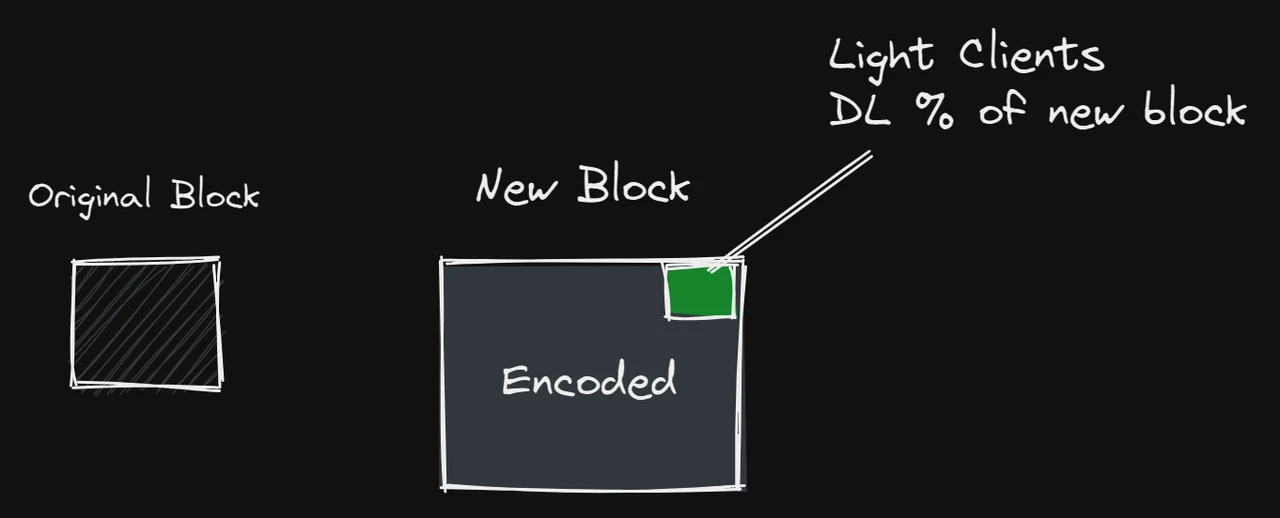
The implementation of data availability sampling ensures the scalability of Celestia as a data availability layer. Because each light node will only need to sample a portion of the block data, this reduces the cost of running the light node and the entire network. The more light nodes that participate in sampling at the same time, the more data they can download and store together, which means that the TPS of the entire network will also increase as the number of light nodes increases.
Scalability through light nodes
The more light nodes participate in data availability sampling, the more data the network can handle. This scalability feature is critical to maintaining efficiency as the network grows.
There are two decisive factors for scalability: the amount of data sampled centrally (the amount of data that can be sampled) and the target block header size of light nodes (the block header size of light nodes directly affects the performance and scalability of the overall network).
In response to the above two factors, Celestia utilizes the principle of collective sampling, that is, through many nodes participating in partial sampling of the data, it can support larger data blocks (i.e., higher transaction processing per second, tps). This approach can expand network capacity without sacrificing security. Furthermore, in the Celestia system, the block header size of a light node grows proportionally to the square root of the block size. This means that if they are to maintain nearly the same security as a full node, a light node will face a bandwidth cost proportional to the square root of the block size.
The cost of Rollup verification blocks increases linearly, and the cost will increase or decrease with the interaction demand of Ethereum.
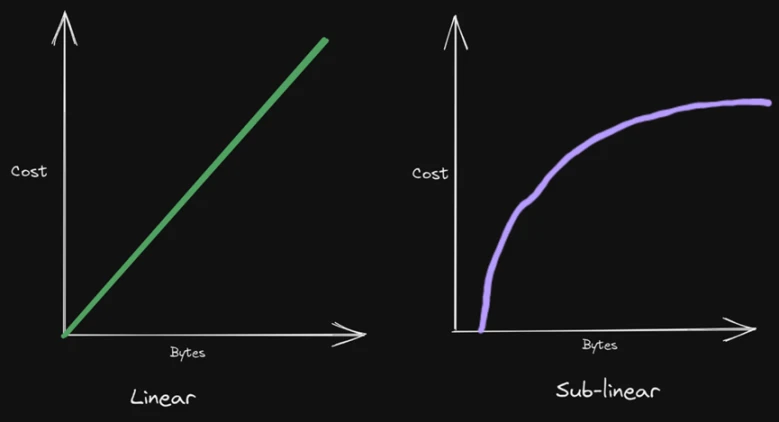
The cost of Celestia is sub-linear, and the cost will eventually approach a value that is far lower than the current cost of Ethereum. After the EIP-4844 upgrade is deployed, the Rollup data storage will change from Calldata to Blob, and the cost will be reduced, but it is still more expensive than Celestia.
In addition, the characteristics of erasure coding enable the transaction data to be restored in the hands of light nodes in the event of a large-scale failure of all Celestia nodes, ensuring that the data is still accessible.
3.3.2 Name-Spaced Merkle Tree
This technical solution reduces costs at the execution and settlement levels.
A simple understanding of Celestias namespace Merkle tree sorting allows any rollup on Celestia to download only the data related to its chain, while ignoring the data of other rollups.
Namespace Merkle Trees (NMT) enable summary nodes to retrieve all summary data they query without having to parse the entire Celestia or summary chain. Additionally, they allow validating nodes to prove that all data has been correctly included in Celestia.
Celestia divides the data in the block into multiple namespaces. Each namespace corresponds to the execution layer and settlement layer that are using Celestia as the data availability layer, so that each execution layer and settlement layer only need to download their own related Data can realize the functions of the network. To put it bluntly, Celestia creates a separate folder for each user who uses it as the underlying layer, and then uses Merkle trees to index folders for these users to help these users find and use their own files.
This kind of Merkle tree that can return all data in a given namespace is called a namespace Merkle tree. The leaves of this Merkle tree will be ordered by namespace identifier, and the hash function is modified so that each node in the tree contains the namespace scope of all its descendants.
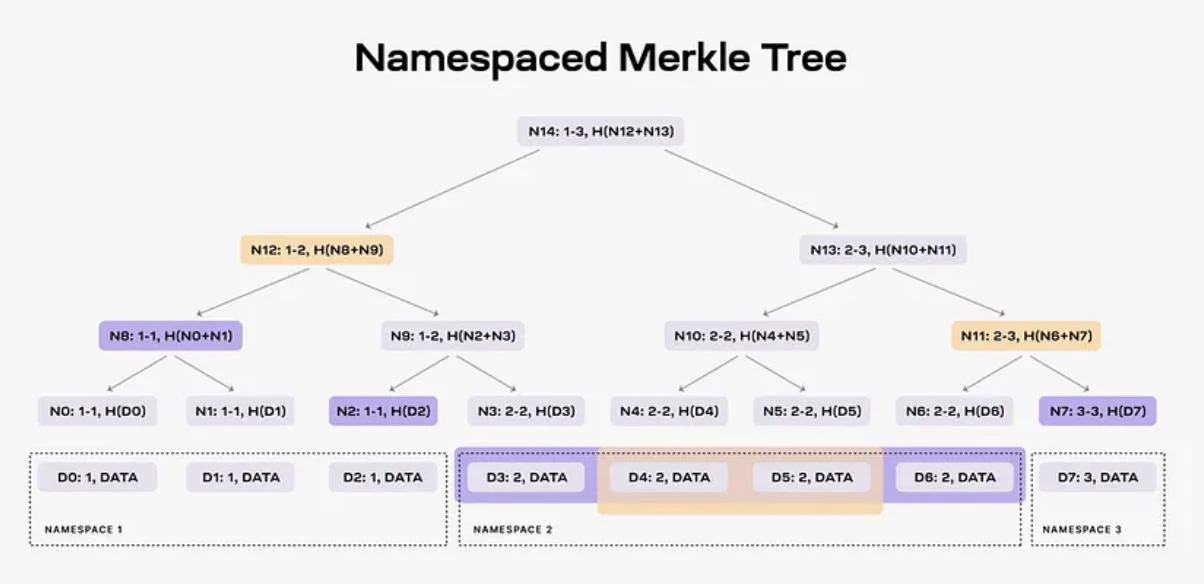
Namespace Merkle tree example
Looking at the namespace Merkle tree example, the Merkle tree containing eight data blocks is divided into three namespaces.
When data in namespace 2 is requested, the data availability layer, that is, Celestia will submit the D 3 , D 4 , D5 and D 6 data blocks to it, and let nodes N 2 , N 7 and N 8 submit the corresponding Proof to ensure the data availability of the requested data. In addition, the application can also verify that all data for namespace 2 has been received. Since the data block must correspond to the nodes attestation, it can identify the integrity of the data by checking the namespace scope of the corresponding node. Looking at the namespace Merkle tree example, the Merkle tree containing eight data blocks is divided into three namespaces.
When data in namespace 2 is requested, the data availability layer, that is, Celestia will submit the D 3 , D 4 , D5 and D 6 data blocks to it, and let nodes N 2 , N 7 and N 8 submit the corresponding Proof to ensure the data availability of the requested data. In addition, the application can also verify that all data for namespace 2 has been received. Since the data block must correspond to the nodes attestation, it can identify the integrity of the data by checking the namespace scope of the corresponding node.
3.3.3 Sovereign Rollup
Rollups based on Celestia are basically Sovereign Rollups.
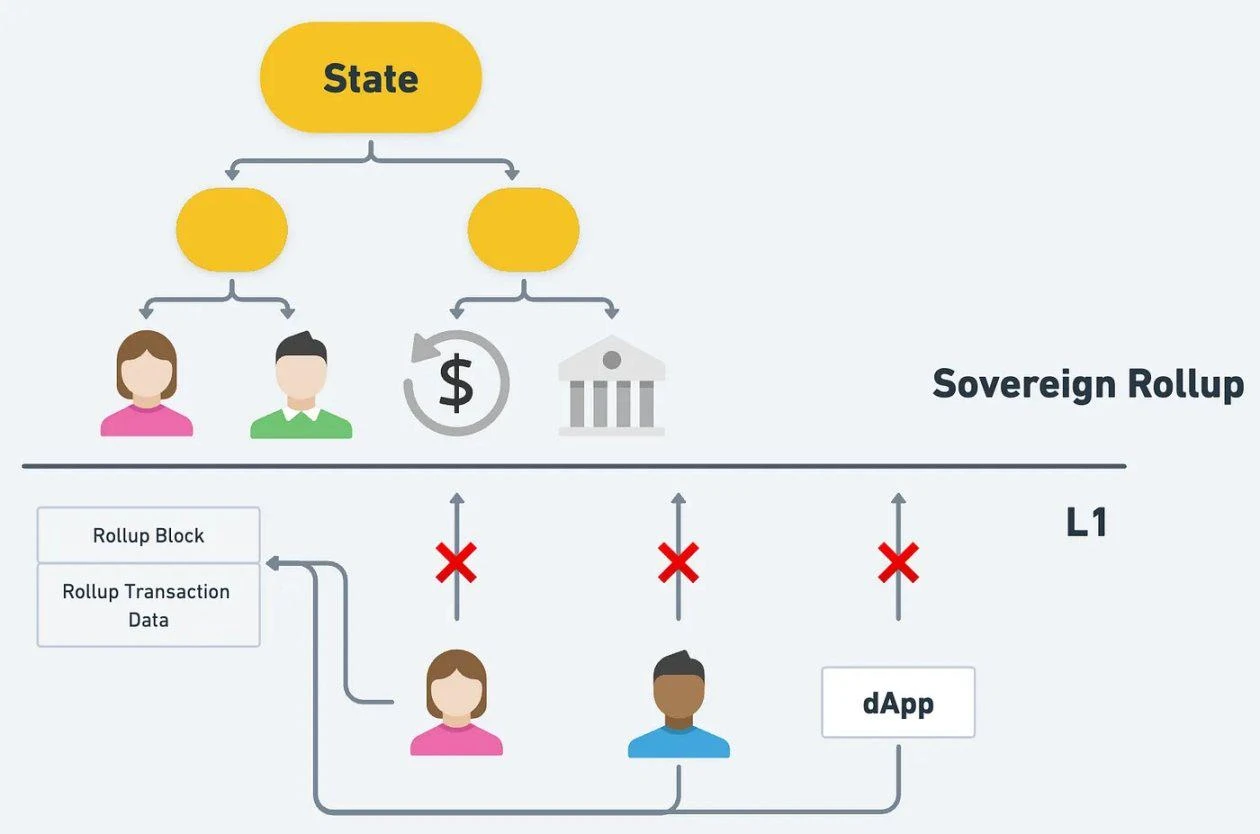
Definition: A Rollup that only uploads materials to L1 (treating L1 as a database) is called a Sovereign Rollup. In other words, traditional rollup is only responsible for execution, and settlement, consensus, and data availability are all handed over to L1. Sovereign rollup is responsible for component execution and settlement, and consensus and data availability are handed over to L1.
Advantages - freedom to upgrade
Since there is no communication information or assets with Layer 1, Rollup will not be affected by L1 (such as L1 upgrade or attack), and its own expansion and upgrade no longer need to worry about L1 (such as hard fork).
Disadvantage – security cost
There are higher security risks, such as DA layer laziness
In addition, the cost of Sovereign Rollup is lower and adopts light node verification (just mentioned in the previous part)
Specific reference to the following sections:An introduction to sovereign rollups,Learn about the classification of Rollup in one article
Smart contract rollup
We call Layer 2 smart contract rollup like Arbitrum, Optimism, StarkNet, etc. They publish all block data to the settlement layer (like Ethereum) and write the status of L2 (the balance of each address in L2) to L1. . The task of the settlement layer is to sort blocks, check data availability, and verify transaction correctness.
For example, Ethereum: the responsibility of modular stack and smart contract rollup is to execute, and then offload other work to Ethereum (including consensus, data availability, settlement).
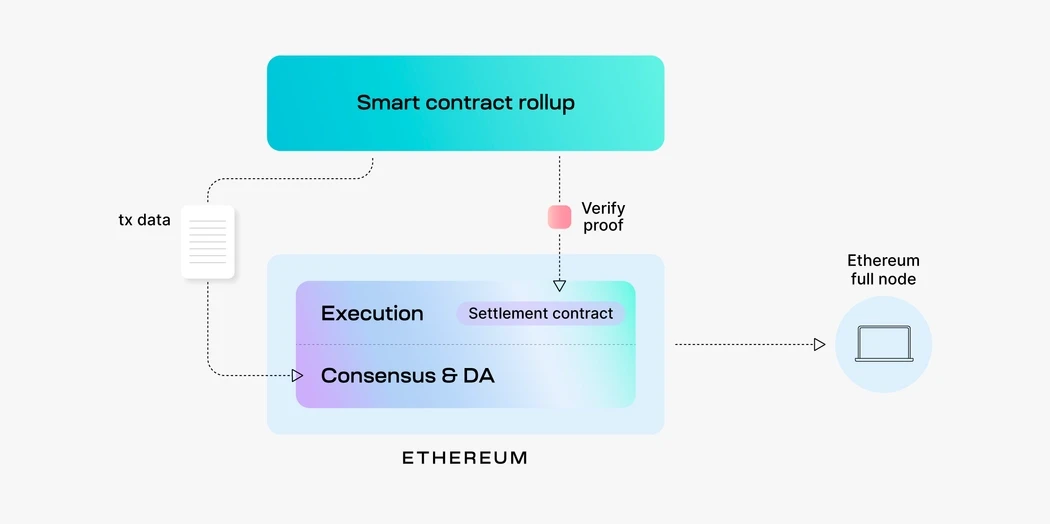
The purpose of this is that L2 and L1 can exchange information and assets: L1/L2s dApp can synchronize information and cooperate, L1s ETH can safely flow between L1/L2, and L2s ARB/OP can also safely Flow between L1/L2.
Smart contract rollup relies on the contract at the settlement layer for validation. The smart contract on the settlement layer becomes the basis for verifying the correctness of new transactions on the smart contract rollup.
Therefore the smart contract rollup has a minimum level of trust with the settlement layer.
Sovereign rollup
Sovereign Rollup is to remove the Settlement Layer (or turn itself into a Settlement Layer) and simply use L1 as the Data Availability Layer.
Sovereign rollup publishes the transaction on another public chain, which is responsible for DA and sorting, and then controls the settlement layer itself.
So sovereign rollup depends on the correctness of the chain itself, not the DA layer, so there needs to be stronger trust.
Compared
The verification methods are different: the transactions of smart contract rollup are verified through the smart contract of the settlement layer; the transactions of Sovereign rollup are verified through its own node.
Sovereignty with upgrades: The upgrade of the smart contract rollup depends on the smart contract of the settlement layer. Upgrading the rollup requires changing the smart contract (the upgrade of Arbitrium needs to depend on the iteration of the Ethereum smart contract). It is very common for teams to use multi-signature to control upgrades, so There are many constraints.
L1 itself has limited capabilities: Maybe L1 itself does not support complex operations to record the Rollup state and use this state to communicate with information assets. For example, on Celestia, it can only simply put data on it, or on Bitcoin. It can only perform operations with limited capabilities, so L1 cannot become a Settlement Layer; perhaps the Rollup itself does not need another chain to serve as a Settlement Layer. It has its own native token and ecology, and does not need to exchange assets with L1.
Expansion - How Sovereign Rollup works, why upgrades such as hard forks are more convenient
Sovereign Rollup simply uses L1 as the Data Availability Layer, uploads data to L1, and relies on L1 to ensure that the data is available and the data sorting will not change.
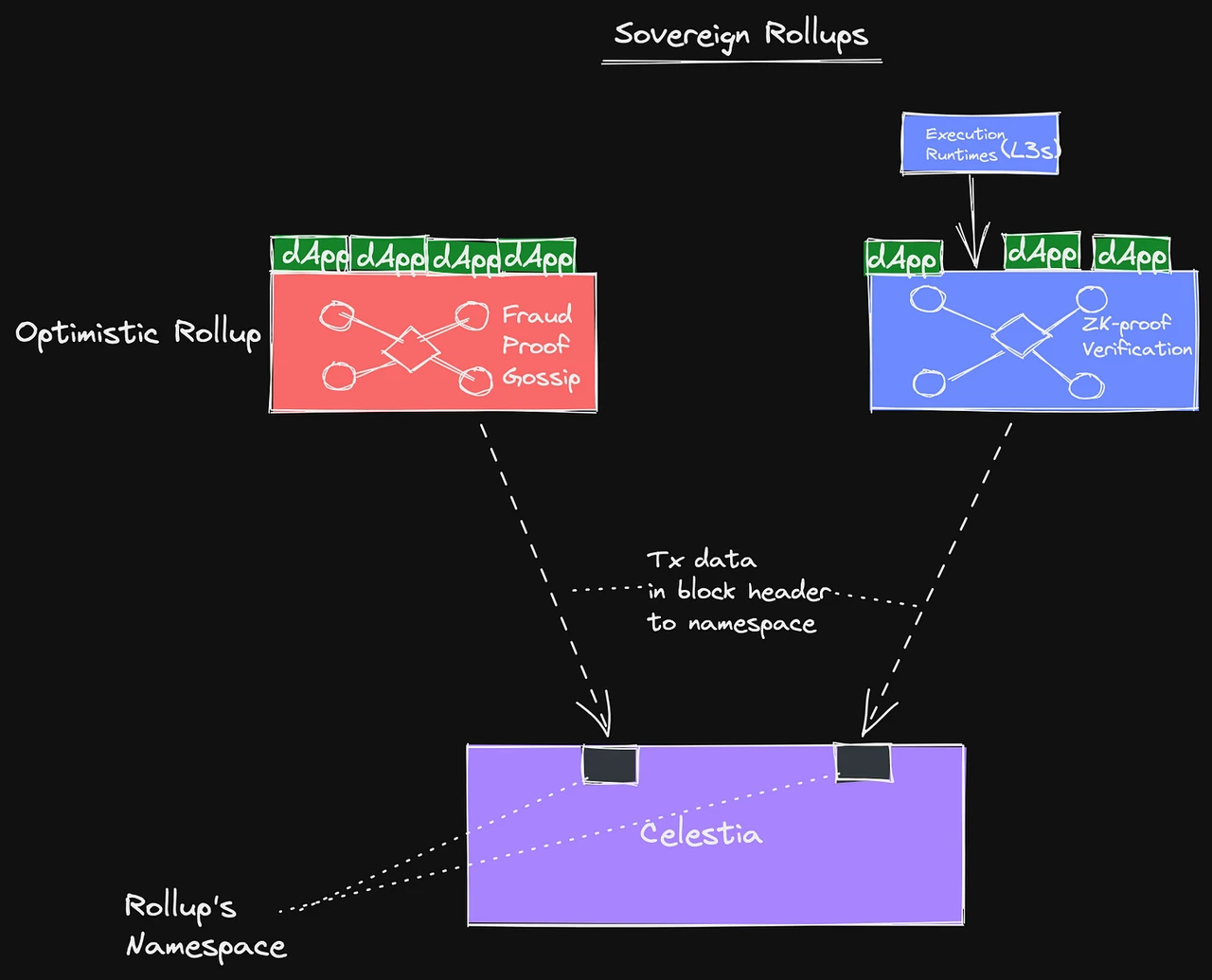
Image Source:https://www.maven11.com/publication/the-modular-world
The nodes of the Sovereign Rollup rely on reading and interpreting the data on L1 to calculate the latest status of the Sovereign Rollup (the smart contract Rollup can directly obtain the status). Interpretation and calculation actually represent the consensus rules of Sovereign Rollup. (State Transition Function: How to filter out blocks and transactions that comply with the Sovereign Rollup format and rules from L1 data, how to verify these blocks and transactions after filtering, and how to execute these transactions after verification to calculate the latest state.)
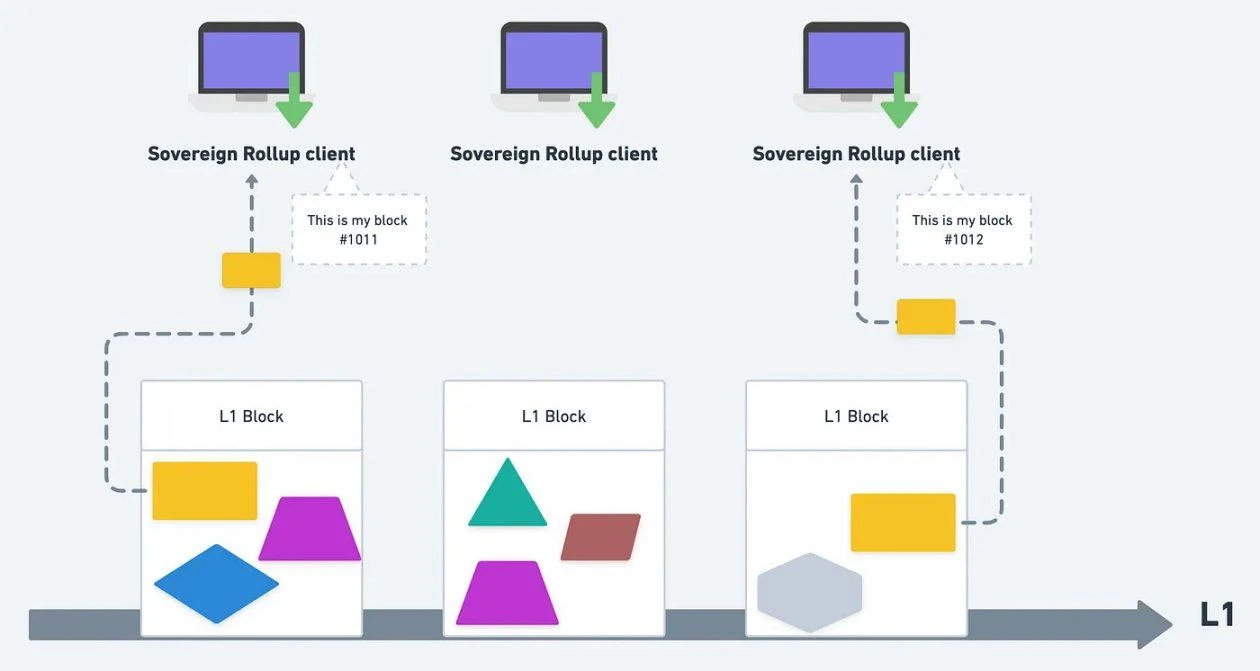
Sovereign Rollup nodes filter out their own blocks from L1 data, interpret and calculate the latest status.
If the two Sovereign Rollup nodes are of different versions, they may interpret different data or calculate different latest statuses. Therefore, the two nodes will not be on the same chain. What they each see is actually One of two forked chains. (For example: Ethereum became ETC and ETH before and after the hard fork)
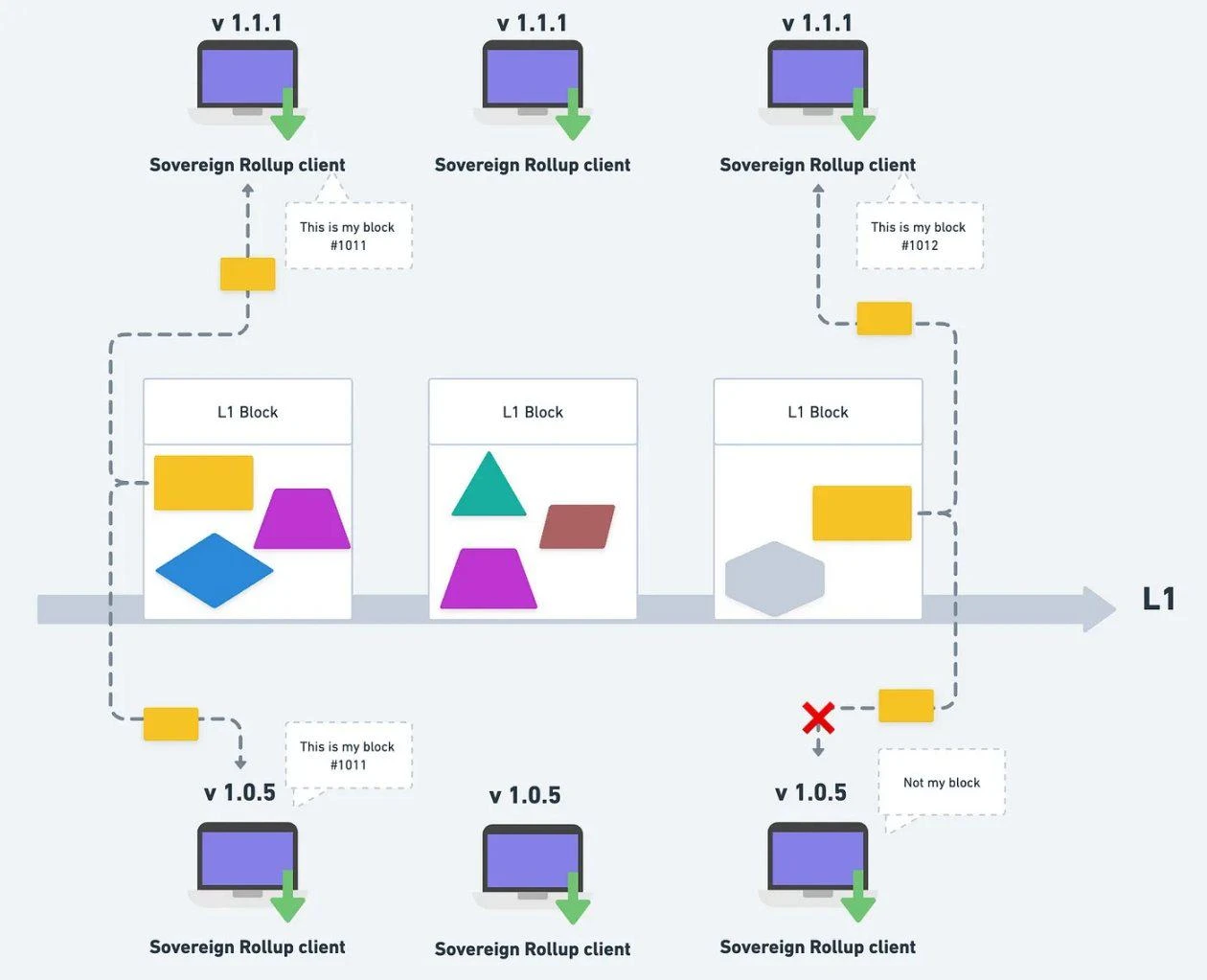
Nodes of different versions may get different states, which will fork to different chains.
This is actually the same as running different versions of Ethereum nodes. The two versions may not be the same chain. For example, after a hard fork, people who forget to update the node version or are unwilling to update the node version will naturally stay on the original chain (such as ETC, ETHPoW), while those who update the node version will stay on the new chain (ETH ).
Therefore, in Sovereign Rollup, everyone can choose the node version and interpret the data according to the (social) consensus of their own group. If there is a disagreement like ETHPoW vs ETH in the Sovereign Rollup community today, it will be that everyone goes their own way and chooses different node versions to interpret the data, but the data is still the same and has not changed.
Of course, after the fork, the nodes of their respective versions will upload data that conforms to their own rules to L1, and both parties will directly filter out the data uploaded by the other party.
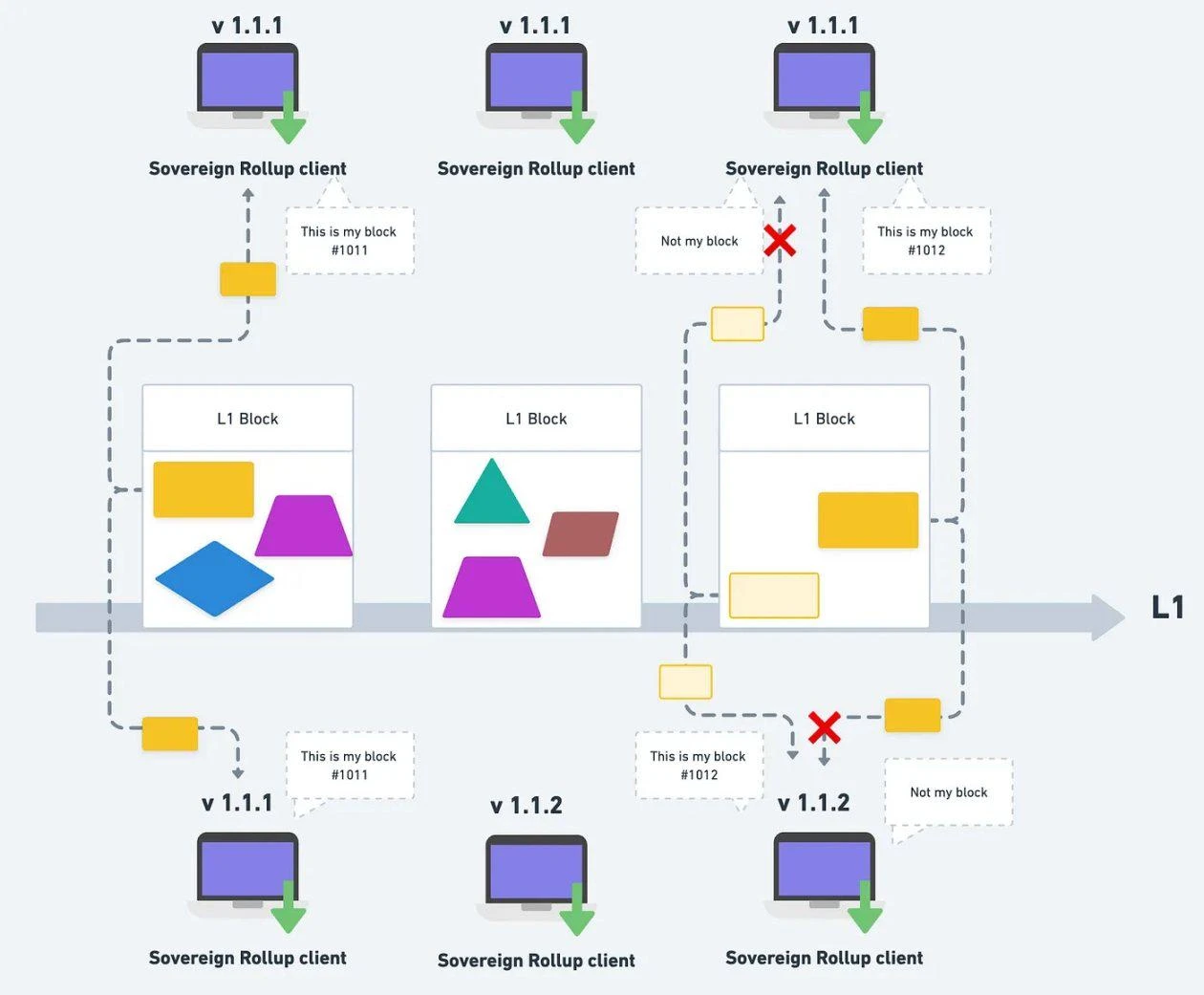
At the middle point in time, the nodes below forked to version v1.1.2, and then the blocks were completely separated from each other.
3.3.4 Node requirements
Benefiting from Celestias network architecture, Celestias light node operation hardware requirements are low, requiring at least a 2 GB RAM memory, a single-core CPU, an SSD hard drive of more than 25 GB, and an upload and download bandwidth of 56 Kbps. In addition to light nodes, Celestias requirements for bridge nodes, full nodes, verification nodes and consensus nodes are not high compared to other public chains. Therefore, after the Celestia mainnet is launched in the future, it is expected that the number of nodes of various types in the network will further increase, and the degree of decentralization of the network will also be further improved.

3.4 Economic model
From the perspective of token economics, Celestia’s token allocation investors and team will receive more than half of the tokens, and 33% of these tokens will be unlocked after one year.
Celestias token demand is basically in line with the design ideas of a normal public chain token. TIA will assume the functions of consensus, fees and governance, and will also be issued in the form of inflation.
At present, it seems that the design of this token is relatively neutral, and the token itself cannot provide more empowerment for the network.
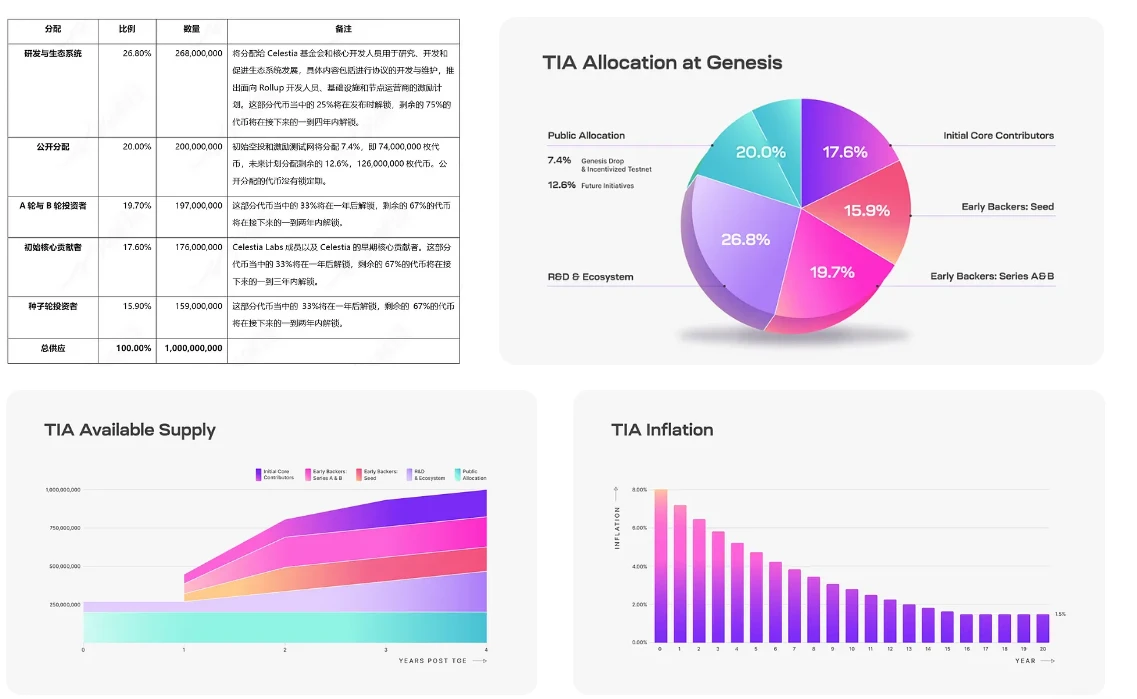
3.5 Business model
Celestia generates revenue in two main ways:
Pay for blob space: Rollup uses $TIA to publish data to Celestias blob space.
Pay gas fees: Developers use TIA as the gas token for Rollup, similar to ETH based on Ethereum Rollup.
3.6 Data cost comparison
Numia Data recently published an article titled “The impact of Celestia’s modular DA layer on Ethereum L2s: a first look》 report, which compares the costs incurred by different Layer 2 (L2) solutions to publish CallData on Ethereum over the past six months, and the costs they might incur if they used Celestia as the data availability (DA) layer (in For this calculation, the TIA price is assumed to be $12). This report clearly demonstrates the huge economic benefits of a dedicated DA layer like Celestias in reducing L2 Gas expenses by comparing the cost difference between the two scenarios.
Rollup cost breakdown:
fixed cost
Proof cost (in case of zk rollups) = Gas range, usually based on rollup provider
Status write cost = 20,000 Gas
Ethereum base transaction cost = 21,000 Gas
Variable costs
Gas fee per transaction publishing calldata to Ethereum = (16 Gas per byte of data) * (Average transaction size in bytes)
L2 Gas Fee = Usually quite cheap, within a fraction of the gas unit.
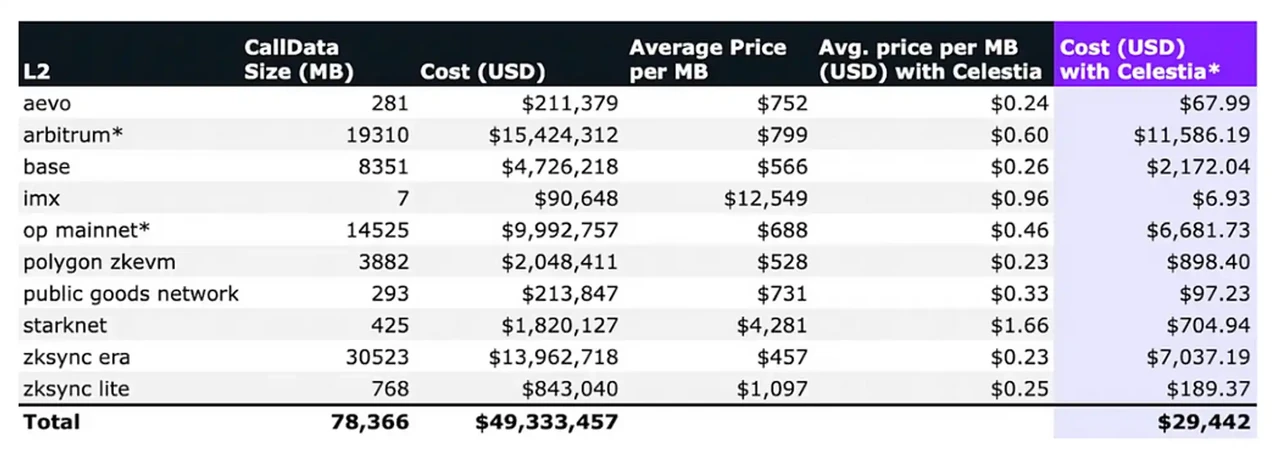
Data source: https://medium.com/@numia.data/the-impact-of-celestias-modular-da-layer-on-ethereum-l2s-a-first-look-8321 bd 41 ff 25
4. Others
4.1 Celestia Ecology

4.2 Composition of different projects
Celestia = Tendermint (cosmos) + 2d erasure code + fraud proof + Namespace merkle tree + IPFS infrastructure (IPFS Blockstore for data storage, IPFS Lib p2p and bitswap for transmission network, IPFS Ipld for data model)
Polygon Avail = Substrate(Polkadot) + 2d erasure code + KZG polynomial commitment + IPFS infrastructure
ETHprotoDankSharding = Blobs data (storage of data availability, replacing existing calldata) + 2d erasure code + KZG polynomial commitment (undecided, the plan is still under discussion) + ETH infrastructure
5. Think
Overall, Celestia attaches great importance to scalability, interactivity and flexibility. Ethereum, like a huge listed company, cannot do whatever startups like Celestia do, and can only walk on thin ice and iterate slowly; while the modular blockchain gives many vertical projects the opportunity to catch up.
However, like many public chains, the current innovation in the encryption world is in a state of stagnation. Most project parties rely on economic models, and may not have enough demand for the performance of the underlying products. As a result, everyone does not have enough need for Celestia, and its own economy The inability of the model to circulate forward is also a potential risk, and it will eventually become a ghost chain.
appendix
https://celestia.org/learn/sovereign-rollups/an-introduction/
About E2M Research
From the Earth to the Moon
E2M Research focuses on research and learning in the fields of investment and digital currency.
Article collection:https://mirror.xyz/0x80894DE3D9110De7fd55885C83DeB3622503D13B
Follow on Twitter :https://twitter.com/E2mResearch️
Audio Podcast:https://e2m-research.castos.com/
Small universe link:https://www.xiaoyuzhoufm.com/podcast/6499969a932f350aae20ec6d
DC link:https://discord.gg/WSQBFmP772





