





In our blog series on advanced formal verification of zero-knowledge proofs , we have discussed how to verify ZK instructions and a deep dive into two ZK vulnerabilities . By formally verifying every zkWasm instruction, we found and fixed every single vulnerability, allowing us to fully verify the technical safety and correctness of the entire zkWasm circuit, as shown in the public report and code repository .
Although we have shown the process of verifying a zkWasm instruction and introduced the initial concepts of the project, readers familiar with formal verification may be interested in understanding the uniqueness of zkVM compared to other smaller ZK systems or other types of bytecode VMs in verification. In this article, we will discuss in depth some technical points encountered when verifying the zkWasm memory subsystem. Memory is the most unique part of zkVM, and handling it well is critical to verifying all other zkVMs.
Formal Verification: Virtual Machine (VM) vs. ZK Virtual Machine (zkVM)
Our ultimate goal is to verify the correctness of zkWasm similar to the correctness theorems of a normal bytecode interpreter (VM, such as the EVM interpreter used by Ethereum nodes). That is, each execution step of the interpreter corresponds to a legal step based on the operational semantics of the language. As shown in the figure below, if the current state of the bytecode interpreters data structure is SL, and this state is marked as state SH in the high-level specification of the Wasm machine, then when the interpreter steps to state SL, there must be a corresponding legal high-level state SH, and the Wasm specification stipulates that SH must step to SH.

Similarly, zkVM has a similar correctness theorem: each new row in the zkWasm execution table corresponds to a legal step based on the operational semantics of the language. As shown in the figure below, if the current state of a row of the execution table data structure is SR, and this state is represented as state SH in the high-level specification of the Wasm machine, then the next row of the execution table state SR must correspond to a high-level state SH, and the Wasm specification stipulates that SH must step to SH.
![]() It can be seen that the specifications of the high-level state and Wasm steps are consistent in both VM and zkVM, so previous verification experience of programming language interpreters or compilers can be used for reference. The special feature of zkVM verification lies in the type of data structure that constitutes the low-level state of the system.
It can be seen that the specifications of the high-level state and Wasm steps are consistent in both VM and zkVM, so previous verification experience of programming language interpreters or compilers can be used for reference. The special feature of zkVM verification lies in the type of data structure that constitutes the low-level state of the system.
First, as we described in a previous blog post , zk provers are essentially integer arithmetic modulo large primes, and the Wasm spec and normal interpreters deal with 32-bit or 64-bit integers. Much of the zkVM implementation deals with this, so the verification needs to handle this as well. However, this is a local problem: each line of code becomes more complex because it needs to handle arithmetic operations, but the overall structure of the code and proof does not change.
Another major difference is how dynamically sized data structures are handled. In a regular bytecode interpreter, memory, data stack, and call stack are all implemented as mutable data structures. Similarly, the Wasm specification represents memory as a data type with get/set methods. For example, Geths EVM interpreter has a `Memory` data type that is implemented as a byte array representing physical memory and is written and read through `Set 32` and `GetPtr` methods. To implement a memory store instruction , Geth calls `Set 32` to modify the physical memory.
func opMstore(pc *uint 64, interpreter *EVMInterpreter, scope *ScopeContext) ([]byte, error) {
// pop value of the stack
mStart, val := scope.Stack.pop(), scope.Stack.pop()
scope.Memory.Set 32(mStart.Uint 64(), val)
return nil, nil
}
In the correctness proof of the above interpreter, it is relatively easy to prove that the high-level state matches the low-level state after assigning values to the concrete memory in the interpreter and the abstract memory in the specification.
However, with zkVM, things get more complicated.
zkWasms memory table and memory abstraction layer
In zkVM, the execution table has columns for fixed-size data (similar to registers in a CPU), but it cannot handle dynamically sized data structures, which are accessed through auxiliary tables. The zkWasm execution table has an EID column with values of 1, 2, 3, etc., and two auxiliary tables, the memory table and the jump table, for representing memory data and the call stack, respectively.
The following is an example implementation of a withdrawal program:
int balance, amount;
void main () {
balance = 100;
amount = 10;
balance -= amount; // withdraw
}
The contents and structure of the execution table are fairly simple. It has 6 execution steps (EIDs 1 to 6), each with a row listing its operation code (opcode) and, if the instruction is a memory read or write, its address and data:
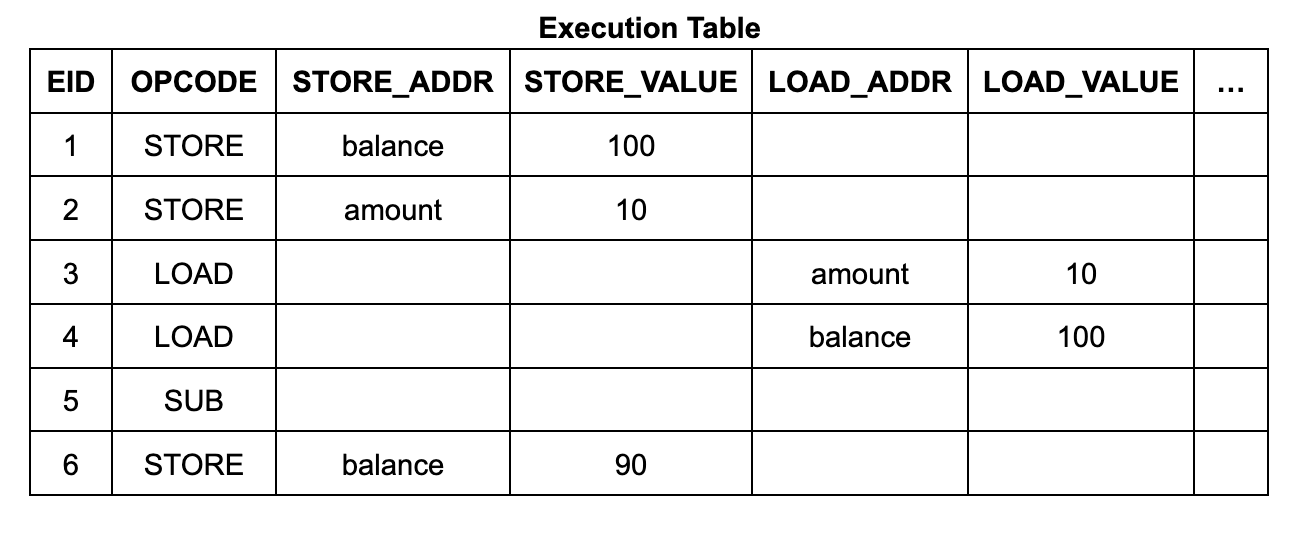
Each row in the memory table contains an address, data, a start EID, and an end EID. The start EID is the EID of the execution step that wrote the data to that address, and the end EID is the EID of the next execution step that will write to that address. (It also contains a count, which we will discuss in detail later.) For the Wasm memory read instruction circuit, it uses a lookup constraint to ensure that there is a suitable table entry in the table so that the EID of the read instruction is in the range from start to end. (Similarly, each row of the jump table corresponds to a frame of the call stack, and each row is labeled with the EID of the call instruction step that created it.)
This memory system is very different from a regular VM interpreter: the memory table is not a mutable memory that is updated gradually, but contains the history of all memory accesses in the entire execution trace. In order to simplify the programmers work, zkWasm provides an abstraction layer implemented through two convenient entry functions. They are:
alloc_memory_table_lookup_write_cell
and
Alloc_memory_table_lookup_read_cell
Its parameters are as follows:

For example, the code implementing the memory store instruction in zkWasm contains a call to the write alloc function:
let memory_table_lookup_heap_write1 = allocator
.alloc_memory_table_lookup_write_cell_with_value(
store write res 1,
constraint_builder,
eid,
move |____| constant_from!(LocationType::Heap as u 64),
move |meta| load_block_index.expr(meta), // address
move |____| constant_from!(0), // is 32-bit
move |____| constant_from!( 1), // (always) enabled
);
let store_value_in_heap1 = memory_table_lookup_heap_write1.value_cell;
The `alloc` function is responsible for handling the lookup constraints between the tables and the arithmetic constraints that associate the current `eid` with the memory table entry. Thus, the programmer can treat these tables as normal memory, and after the code executes, the value of `store_value_in_heap1` has been assigned to the `load_block_index` address.
Similarly, memory read instructions are implemented using the `read_alloc` function. In the example execution sequence above, each load instruction has a read constraint and each store instruction has a write constraint, and each constraint is satisfied by an entry in the memory table.
mtable_lookup_write(row 1.eid, row 1.store_addr, row 1.store_value)
⇐ (row 1.eid= 1 ∧ row 1.store_addr=balance ∧ row 1.store_value= 100 ∧ ...)
mtable_lookup_write(row 2.eid, row 2.store_addr, row 2.store_value)
⇐ (row 2.eid= 2 ∧ row 2.store_addr=amount ∧ row 2.store_value= 10 ∧ ...)
mtable_lookup_read(row 3.eid, row 3.load_addr, row 3.load_value)
⇐ ( 2<row 3.eid≤ 6 ∧ row 3.load_addr=amount ∧ row 3.load_value= 100 ∧ ...)
mtable_lookup_read(row 4.eid, row 4.load_addr, row 4.load_value)
⇐ ( 1<row 4.eid≤ 6 ∧ row 4.load_addr=balance ∧ row 4.load_value= 10 ∧ ...)
mtable_lookup_write(row 6.eid, row 6.store_addr, row 6.store_value)
⇐ (row 6.eid= 6 ∧ row 6.store_addr=balance ∧ row 6.store_value= 90 ∧ ...)
The structure of the formal verification should correspond to the abstractions used in the software being verified, so that the proof can follow the same logic as the code. For zkWasm, this means that we need to verify the memory table circuit and the alloc read/write cell function as a module, with an interface like mutable memory. Given such an interface, verification of each instruction circuit can be done in a similar way to a regular interpreter, with the additional ZK complexity encapsulated in the memory subsystem module.
In the verification, we specifically implemented the idea that the memory table can actually be regarded as a mutable data structure. That is, we wrote a function `memory_at type`, which completely scans the memory table and builds the corresponding address data mapping. (Here, the value range of the variable `type` is three different types of Wasm memory data: heap, data stack, and global variables.) Then, we proved that the memory constraints generated by the alloc function are equivalent to the data changes made to the corresponding address data mapping using the set and get functions. We can prove that:
For each eid, if the following constraints hold
memory_table_lookup_read_cell eid type offset value
but
get (memory_at eid type) offset = Some value
And if the following constraints hold
memory_table_lookup_write_cell eid type offset value
but
memory_at (eid+ 1) type = set (memory_at eid type) offset value
After this, verification of each instruction can be based on get and set operations on the address-data mapping, similar to a non-ZK bytecode interpreter.
zkWasms memory write counting mechanism
However, the above simplified description does not reveal the full contents of the memory table and jump table. Under the framework of zkVM, these tables may be manipulated by an attacker, who can easily manipulate the memory load instruction to return an arbitrary value by inserting a row of data.
Taking the withdrawal program as an example, an attacker has the opportunity to inject false data into the account balance by forging a memory write operation of $110 before the withdrawal operation. This process can be achieved by adding a row of data to the memory table and modifying the values of existing cells in the memory table and execution table. This will result in a free withdrawal operation, because the account balance will still remain at $100 after the operation.
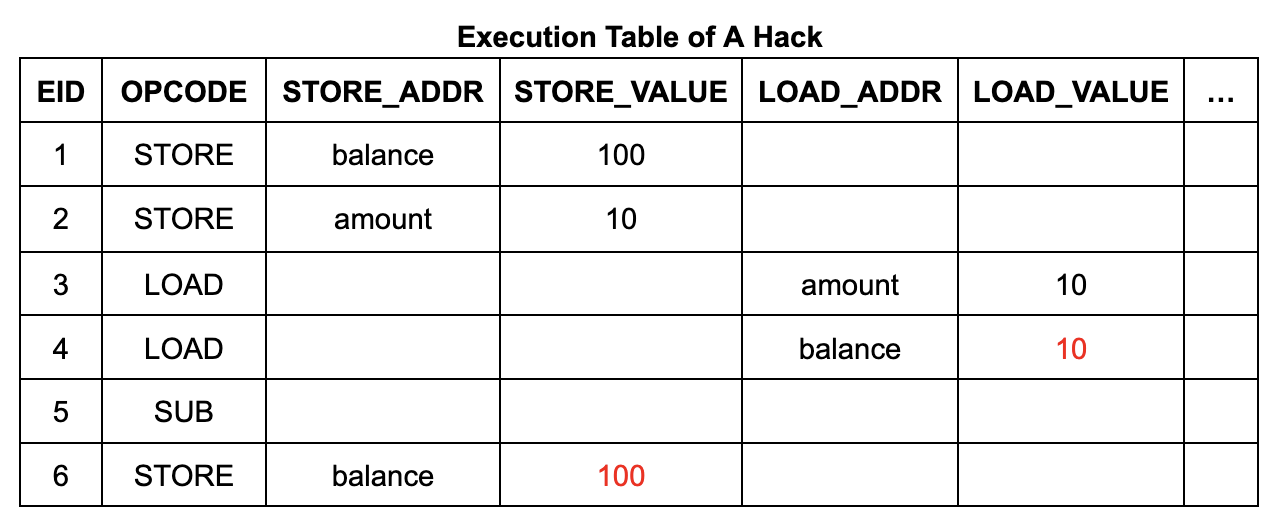
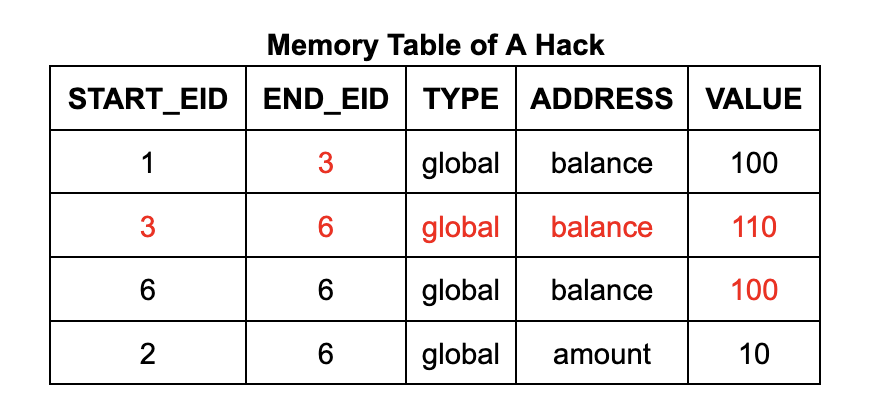
To ensure that the memory table (and jump table) only contain valid entries generated by memory writes (and calls and returns) that are actually executed, zkWasm uses a special counting mechanism to monitor the number of entries. Specifically, the memory table has a dedicated column that keeps track of the total number of memory write entries. At the same time, the execution table also contains a counter that counts the number of memory write operations expected for each instruction. An equality constraint is set to ensure that the two counts are consistent. The logic of this approach is very intuitive: every time a memory write operation is performed, it is counted once, and there should be a corresponding record in the memory table. Therefore, an attacker cannot insert any additional entries into the memory table.
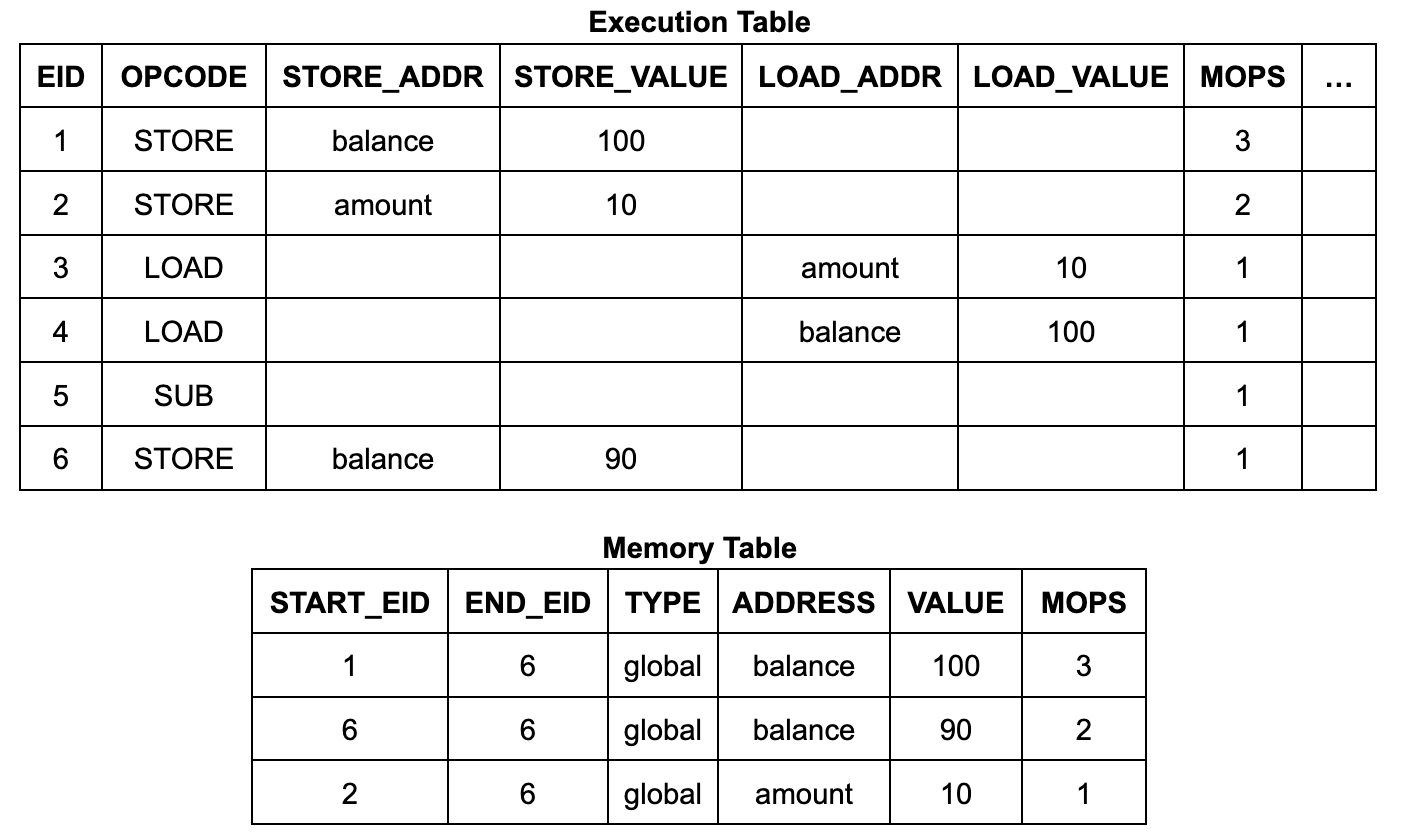
The logical statement above is a bit vague, and in the process of mechanical proof, we need to make it more precise. First, we need to correct the statement of the memory write lemma mentioned above. We define a function `mops_at eid type` that counts the number of memory table entries with a given `eid` and `type` (most instructions will create 0 or 1 entries at an eid). The full statement of the theorem has an additional precondition stating that there are no spurious memory table entries:
If the following constraints hold
(memory_table_lookup_write_cell eid type offset value)
And the following new constraints hold
(mops_at eid type) = 1
but
(memory_at(eid+ 1) type) = set (memory_at eid type) offset value
This requires our verification to be more precise than in the previous case. It is not enough to simply conclude from the equality constraint that the total number of memory table entries is equal to the total number of memory writes in the execution. In order to prove the correctness of the instructions, we need to know that each instruction corresponds to the correct number of memory table entries. For example, we need to rule out the possibility that an attacker could omit the memory table entry for an instruction in the execution sequence and create a malicious new memory table entry for another unrelated instruction.
To prove this, we take a top-down approach to constraining the number of memtable entries for a given instruction, which consists of three steps. First, we estimate the number of entries that should be created for the instructions in the execution sequence, based on the instruction type. We call the expected number of writes from the ith step to the end of execution `instructions_mops i`, and the corresponding number of memtable entries from the ith instruction to the end of execution `cum_mops (eid i)`. By analyzing the lookup constraints for each instruction, we can prove that it creates no fewer entries than expected, and thus that each segment [i... numRows] that is tracked creates no fewer entries than expected:
Lemma cum_mops_bound: forall ni,
0 ≤ i ->
i + Z.of_nat n = etable_numRow ->
MTable.cum_mops (etable_values eid_cell i) (max_eid+ 1) ≥ instructions_mops i n.
Second, if one can show that the table has no more entries than expected, then it has exactly the right number of entries, and this is obvious.
Lemma cum_mops_equal : forall ni,
0 ≤ i ->
i + Z.of_nat n = etable_numRow ->
MTable.cum_mops (etable_values eid_cell i) (max_eid+ 1) ≤ instructions_mops in ->
MTable.cum_mops (etable_values eid_cell i) (max_eid+ 1) = instructions_mops i n.
Now for step 3. Our correctness theorem states that for any n, cum_mops and instructions_mops always agree on the part of the table from row n to the end:
Lemma cum_mops_equal : forall n,
0 <= Z.of_nat n < etable_numRow ->
MTable.cum_mops (etable_values eid_cell (Z.of_nat n)) (max_eid+ 1) = instructions_mops (Z.of_nat n)
Verification is done by induction on n. The first row in the table is the equality constraint for zkWasm, which states that the total number of entries in the memory table is correct, i.e., cum_mops 0 = instructions_mops 0. For the following rows, the induction hypothesis tells us:
cum_mops n = instructions_mops n
And we hope to prove
cum_mops (n+ 1) = instructions_mops (n+ 1)
Note here
cum_mops n = mop_at n + cum_mops (n+ 1)
and
instructions_mops n = instruction_mops n + instructions_mops (n+ 1)
Therefore, we can get
mops_at n + cum_mops (n+ 1) = instruction_mops n + instructions_mops (n+ 1)
Earlier, we have shown that each instruction will create no less than the expected number of entries, e.g.
mops_at n ≥ instruction_mops n.
So it can be concluded
cum_mops (n+ 1) ≤ instructions_mops (n+ 1)
Here we need to apply the second lemma mentioned above.
(A similar lemma can be applied to jump tables to prove that every call instruction generates exactly one jump table entry, making the proof technique generally applicable. However, further work is needed to prove the correctness of return instructions. The return eid is different from the eid of the call instruction that created the call frame, so we need an additional invariant that states that the eid value is unidirectionally increasing in the execution sequence.)
Such detailed description of the proof is typical of formal verification and is the reason why verifying a particular piece of code often takes longer than writing it. But is it worth it? In this case, it is, because during the proof we did discover a critical bug in the jump table counting mechanism. This bug has been described in detail in a previous post - in summary, the old version of the code counted both call and return instructions, and an attacker could make room for a fake jump table entry by adding an extra return instruction to the execution sequence. Although the incorrect counting mechanism satisfies the intuition of counting every call and return instruction, problems become apparent when we try to refine this intuition into a more precise theorem statement.
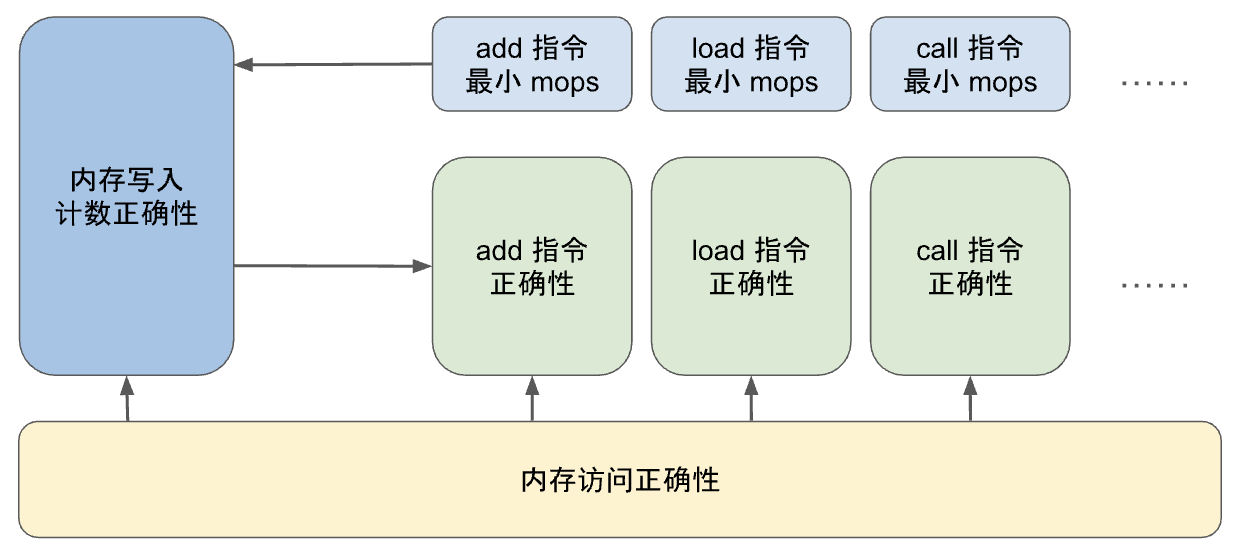
Modularize the proof process
From the above discussion, we can see that there is a circular dependency between the proof about each instruction circuit and the proof about the count column of the execution table. To prove the correctness of the instruction circuit, we need to reason about the memory writes in it; that is, we need to know the number of memory table entries at a specific EID, and we need to prove that the memory write operation count in the execution table is correct; which in turn requires proving that each instruction performs at least the minimum number of memory write operations.
In addition, there is another factor to consider. The zkWasm project is quite large, so the verification work needs to be modularized so that multiple verification engineers can divide the work. Therefore, when deconstructing the proof of the counting mechanism, special attention needs to be paid to its complexity. For example, for the LocalGet instruction, there are two theorems as follows:
Theorem opcode_mops_correct_local_get : forall i,
0 <= i ->
etable_values eid_cell i > 0 ->
opcode_mops_correct LocalGet i.
Theorem LocalGetOp_correct : forall i st y xs,
0 <= i ->
etable_values enabled_cell i = 1 ->
mops_at_correct i ->
etable_values (ops_cell LocalGet) i = 1 ->
state_rel i st ->
wasm_stack st = xs ->
(etable_values offset_cell i) > 1 ->
nth_error xs (Z.to_nat (etable_values offset_cell i - 1)) = Some y ->
state_rel (i+ 1) (update_stack (incr_iid st) (y::xs)).
First theorem statement
opcode_mops_correct LocalGet i
After the definition is expanded, it means that the instruction creates at least one memtable entry at line i (the number 1 is specified in the LocalGet opcode specification of zkWasm).
The second theorem is the complete correctness theorem for this instruction, which cites
mops_at_correct i
As a hypothesis, this means that the instruction creates exactly one memory table entry.
Verification engineers can prove these two theorems independently and then combine them with the proof about the execution table to prove the correctness of the entire system. It is worth noting that all proofs for individual instructions can be done at the level of read/write constraints without knowing the specific implementation of the memory table. Therefore, the project is divided into three parts that can be processed independently.
Summarize
Verifying zkVM circuits line by line is not fundamentally different from verifying other ZK applications, as they all require similar reasoning about arithmetic constraints. At a high level, verification of zkVM requires many of the same techniques used in formal verification of programming language interpreters and compilers. The main difference here is the dynamically sized virtual machine state. However, the impact of these differences can be minimized by carefully building the verification structure to match the abstraction level used in the implementation, so that each instruction can be independently verified modularly based on a get-set interface, just like for a regular interpreter.





