




GPT の出現により、大規模言語モデルが世界的に注目を集め、各界がこの「ブラック テクノロジー」を利用して作業効率を向上させ、業界の発展を加速させようとしています。 Future 3 Campus は、Footprint Analytics と提携して、AI と Web3 の組み合わせの無限の可能性に関する詳細な調査を実施し、「Web3 と Web3 の統合の現状、競争環境、および将来の機会の分析」と題した調査レポートを共同で発表しました。 AIとWeb3データ産業。」調査レポートは 2 部に分かれており、この記事は最初の部分であり、Footprint Analytics の研究者である Lesley 氏と Shelly 氏が共同編集しています。次の記事は、Future 3 キャンパスの研究者である Sherry と Humphrey によって共同編集されています。
まとめ:
LLM テクノロジーの発展により、AI と Web3 の組み合わせに対する人々の注目が高まり、新しいアプリケーション パラダイムが徐々に展開されています。この記事では、AI を使用して Web3 データのエクスペリエンスと生産性を向上させる方法に焦点を当てます。
業界の初期段階とブロックチェーン技術の特性により、Web3 データ業界はデータ ソース、更新頻度、匿名性属性などを含む多くの課題に直面しており、これらの問題を解決するための AI の活用が新たな焦点となっています。
従来の人工知能と比較して、LLM のスケーラビリティ、適応性、効率向上、タスク分解、アクセシビリティ、使いやすさなどの利点により、ブロックチェーン データのエクスペリエンスと生産効率を向上させるための想像力の余地が提供されます。
LLM はトレーニングのために大量の高品質のデータを必要とし、ブロックチェーン分野には豊富な垂直知識とオープンデータがあり、LLM の学習材料を提供できます。
LLM は、データ クリーニング、アノテーション、構造化データの生成など、ブロックチェーン データの価値を生成および強化するのにも役立ちます。
LLM は万能薬ではないため、特定のビジネス ニーズに適用する必要があります。 LLM の高効率を活用すると同時に、結果の精度にも注意を払う必要があります。
1. AIとWeb3の開発と組み合わせ
1.1. AIの発展の歴史
人工知能 (AI) の歴史は 1950 年代にまで遡ります。 1956 年以来、人々は人工知能の分野に注目し始め、専門分野の問題解決に役立つ初期のエキスパート システムが徐々に開発されました。その後、機械学習の台頭によりAIの応用分野は拡大し、あらゆる分野でAIがより広く活用され始めています。これまで、ディープラーニングと生成型人工知能の爆発的な発展は、人々に無限の可能性をもたらし、そのあらゆる段階で、より高い知能レベルとより幅広い応用分野を追求する継続的な挑戦と革新に満ちています。
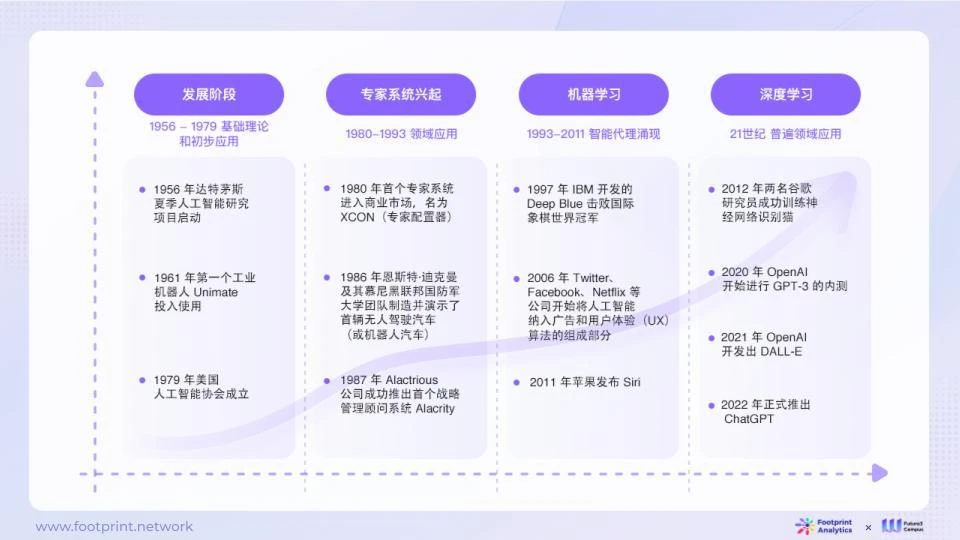
図1:AI開発の歴史
2022 年 11 月 30 日、ChatGPT が開始され、AI と人間の間の低しきい値で高効率なインタラクションの可能性が初めて実証されました。 ChatGPT は、人工知能に関する広範な議論を引き起こし、AI と対話する方法を再定義して AI をより効率的、直観的かつ人間味のあるものにし、また、より生成的な人工知能、Anthropic (Amazon)、DeepMind (Google)、Llama などへの人々の注目を促進しました。その後、他のモデルも人々の視野に入ってきました。同時に、さまざまな業界の実務家が、AIがどのように自分たちの分野の発展を促進するか、またはAI技術と組み合わせて業界での優位性を模索することを積極的に検討し始めており、さまざまな分野でAIの普及がさらに加速しています。
1.2. AIとWeb3の統合
Web3 のビジョンは金融システムの改革から始まり、より多くのユーザーパワーを実現することを目指しており、現代の経済と文化の変革をリードすることが期待されています。ブロックチェーン技術は、この目標を達成するための強固な技術基盤を提供し、価値の伝達とインセンティブのメカニズムを再設計するだけでなく、リソースの割り当てと権力の分散化のサポートも提供します。
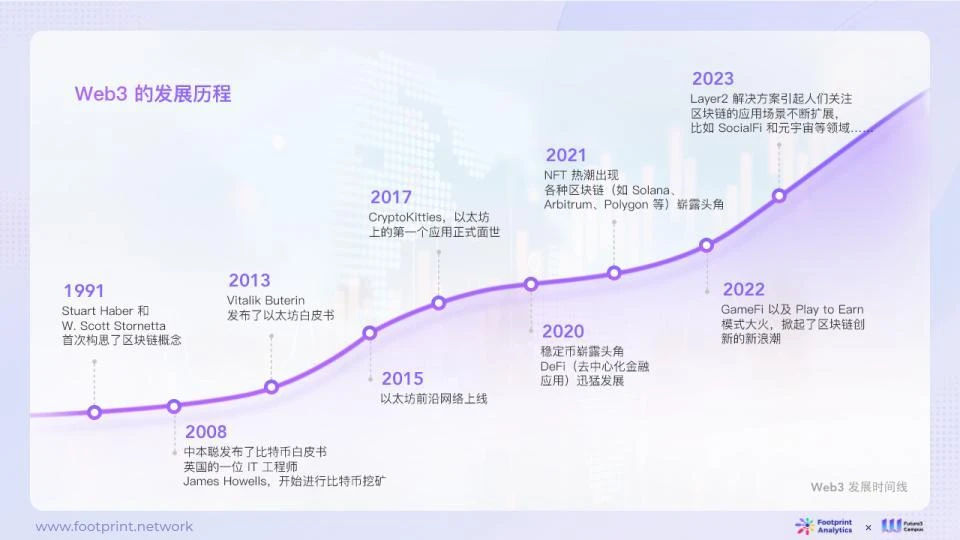
図 2: Web3 開発の歴史
早ければ2020年にもブロックチェーン分野の投資会社がFourth Revolution Capital(4 RC)ブロックチェーン技術とAIを組み合わせることで、金融、医療、電子商取引、エンターテインメントなどのグローバル産業の分散化を通じて既存産業を破壊する可能性が指摘されている。
現在、AI と Web3 の組み合わせは主に 2 つの大きな方向に焦点を当てています。
● AI を使用して生産性とユーザー エクスペリエンスを向上させます。
● ブロックチェーンの透明性、セキュリティ、分散ストレージ、トレーサビリティ、検証可能性の技術的特徴と、Web3 の分散生産関係を組み合わせることで、従来のテクノロジーでは解決できない問題点を解決したり、生産効率を向上させるためにコミュニティの参加を促進したりできます。
市場における AI と Web3 の組み合わせには、次のような探索方向があります。
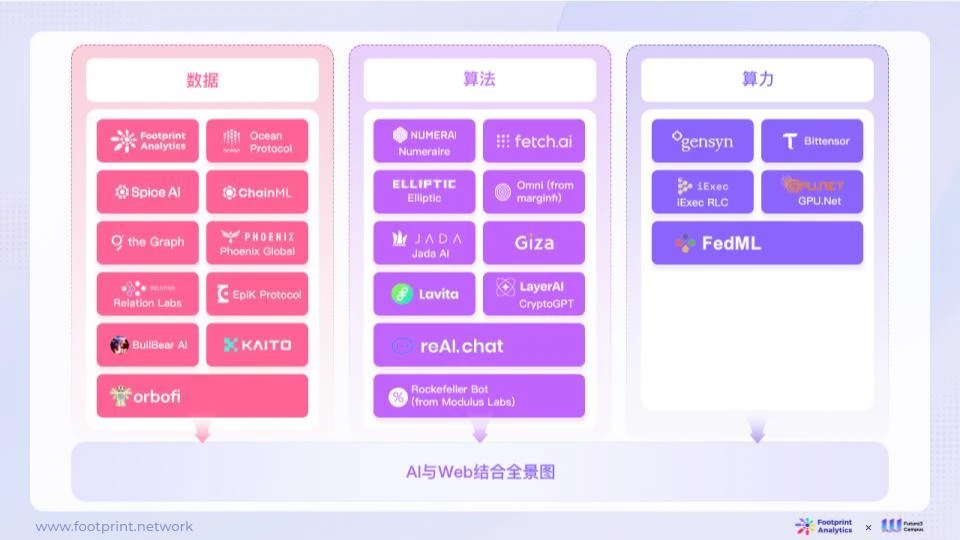
図 3: AI と Web3 の組み合わせのパノラマ
● データ: ブロックチェーン技術はモデル データ ストレージに適用でき、暗号化されたデータ セットの提供、データ プライバシーの保護、モデル データのソースと使用方法の記録、データの信頼性の検証を行うことができます。 AI は、ブロックチェーンに保存されているデータにアクセスして分析することで、貴重な情報を抽出し、モデルのトレーニングと最適化に使用できます。同時に、AIをデータ制作ツールとしても活用し、Web3データの制作効率を向上させることもできます。
● アルゴリズム: Web3 のアルゴリズムは、AI に対してより安全で信頼性が高く、自律的に制御されるコンピューティング環境を提供し、AI システムに暗号化保護を提供できます。セキュリティ フェンスは、システムの悪用や悪意のある攻撃を防ぐためにモデル パラメーターに埋め込まれています。操作された。 AI は、スマート コントラクトを使用してタスクを実行し、データを検証し、意思決定を実行するなど、Web3 のアルゴリズムと対話できます。同時に、AI アルゴリズムは、Web3 に対してよりインテリジェントで効率的な意思決定とサービスを提供することもできます。
● コンピューティング能力: Web3 の分散コンピューティング リソースは、AI に高性能コンピューティング機能を提供できます。 AI は、Web3 の分散コンピューティング リソースをモデルのトレーニング、データ分析、予測に使用できます。 AI は、コンピューティング タスクをネットワーク上の複数のノードに分散することで、計算を高速化し、より大量のデータを処理できます。
この記事では、AI テクノロジーを使用して Web3 データの生産性とユーザー エクスペリエンスを向上させる方法を検討することに焦点を当てます。
2. Web3データの現状
2.1. Web2 と Web3 データ業界の比較
Web3 は AI の中核コンポーネントである「データ」として、私たちが慣れ親しんでいる Web2 とは大きく異なります。違いは主に Web2 と Web3 のアプリケーション アーキテクチャにあり、その結果、データ特性が異なります。
2.1.1. Web2 と Web3 アプリケーションのアーキテクチャの比較
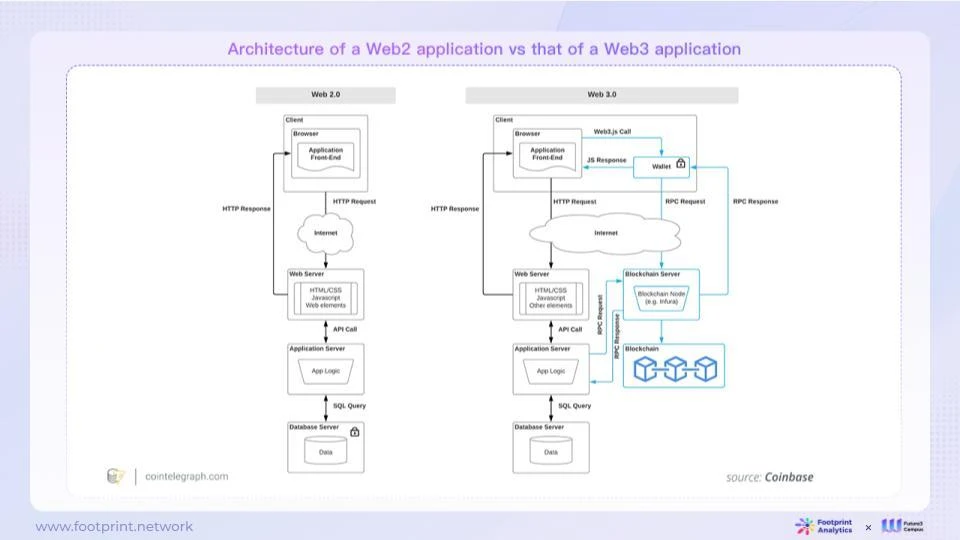
図 4: Web2 および Web3 アプリケーション アーキテクチャ
Web2 アーキテクチャでは、通常、単一のエンティティ (通常は会社) が Web ページまたは APP を制御します。会社は、構築するコンテンツを完全に制御します。サーバー上のコンテンツとロジックに誰がアクセスできるか、およびユーザーを決定できます。どのような権利を持っているかによって、コンテンツがオンラインに存在する期間も決まります。インターネット企業には、ユーザーが生み出した価値を維持できないまま、自社のプラットフォームのルールを変更したり、ユーザーへのサービスを停止したりする権利があることが、多くの事例で明らかになっている。
Web3 アーキテクチャは、ユニバーサル ステート レイヤーの概念に依存して、コンテンツとロジックの一部またはすべてをパブリック ブロックチェーン上に配置します。これらのコンテンツとロジックはブロックチェーン上に公的に記録され、誰もがアクセスでき、ユーザーはチェーン上のコンテンツとロジックを直接制御できます。 Web2 では、ユーザーがブロックチェーン上のコンテンツを操作するにはアカウントまたは API キーが必要です。ユーザーは、対応するオンチェーンのコンテンツとロジックを直接制御できます。 Web2 とは異なり、Web3 ユーザーはブロックチェーン上のコンテンツを操作するために承認されたアカウントや API キーを必要としません (特定の管理操作を除く)。
2.1.2. Web2 と Web3 のデータ特性の比較
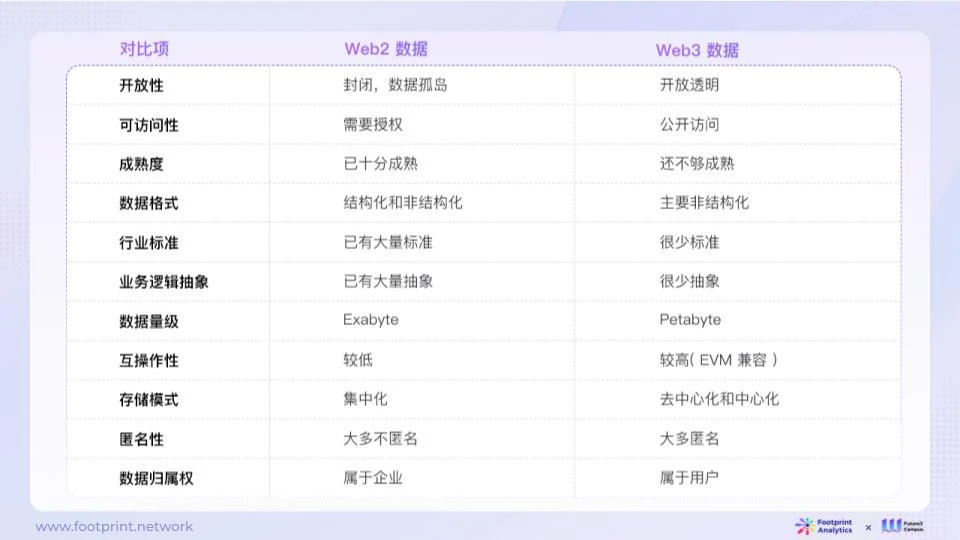
図 5: Web2 と Web3 のデータ特性の比較
Web2 データは通常、閉鎖的で高度に制限されており、複雑な権限制御、高い成熟度、複数のデータ形式、業界標準への厳密な準拠、および複雑なビジネス ロジックの抽象化を備えています。これらのデータは規模が大きいですが、相互運用性が比較的低く、通常は中央サーバーに保存され、プライバシー保護には注意が払われず、ほとんどが非匿名です。
対照的に、Web3 データはよりオープンであり、より広いアクセス権を持っていますが、成熟度は低く、非構造化データが多くを占め、標準化はまれで、ビジネス ロジックの抽象化は比較的単純です。 Web3 は Web2 に比べてデータ サイズが小さいですが、相互運用性 (EVM 互換性など) が高く、データを分散または集中的に保存でき、ユーザーのプライバシーも重視されており、ユーザーは通常匿名でチェーン上で対話します。
2.2. Web3 データ業界の現状と展望、直面する課題
Web2 時代では、データは石油の「埋蔵量」と同じくらい貴重であり、大規模なデータにアクセスして取得することは常に大きな課題でした。 Web3 では、データのオープン化と共有により、誰もが突然「石油はどこにでもある」と感じるようになり、AI モデルがより多くのトレーニング データを取得しやすくなりました。これは、モデルのパフォーマンスとインテリジェンスの向上に不可欠です。しかし、「新しい石油」である Web3 のデータ処理には、主に次のような解決すべき課題がまだ多くあります。
● データソース: チェーン上のデータ「標準」は複雑かつ分散しており、データ処理には多大な人件費がかかります。
オンチェーンデータを処理する場合、時間と労働集約的なインデックス作成プロセスを繰り返し実行する必要があるため、開発者やデータアナリストは、異なるチェーンや異なるプロジェクト間のデータの違いに適応するために多大な時間とリソースを費やす必要があります。オンチェーン データ業界には統一された生成および処理基準が欠如しており、イベント、ログ、トレースはブロックチェーン台帳に記録されるだけでなく、基本的にプロジェクト自体によって定義および生成 (または生成) されるため、非専門的なトレーダーが利用することになります。最も正確で信頼できるデータを識別して見つけるのは難しく、オンチェーン取引や投資の意思決定がさらに困難になります。例えば、分散型取引所のUniswapとPancakeswapでは、データ処理方法やデータ口径に違いがある可能性があり、その過程での検査や口径統一などの手順により、データ処理の複雑性はさらに高まります。
● データ更新: チェーン上のデータは大容量かつ頻繁に更新されるため、タイムリーに構造化データに処理することが困難です。
ブロックチェーンは常に変化しており、データの更新は数秒、場合によってはミリ秒単位で測定されます。データの生成と更新が頻繁に行われるため、高品質のデータ処理とタイムリーな更新を維持することが困難になります。したがって、自動化された処理プロセスは非常に重要ですが、これはデータ処理のコストと効率に対する大きな課題でもあります。 Web3 データ業界はまだ初期段階にあります。新しい契約の継続的な出現と反復的な更新に伴い、標準の欠如とデータ形式の多様化により、データ処理の複雑さがさらに増大しています。
● データ分析: チェーン上のデータの匿名属性により、データの身元を区別することが困難になります。
オンチェーンデータには、各アドレスを明確に識別するのに十分な情報が含まれていないことが多く、そのデータをオフチェーンの経済的、社会的、または法的発展と結び付けることが困難になります。ただし、チェーン上のデータの傾向は現実世界と密接に関連しているため、チェーン上のアクティビティと現実世界の特定の個人またはエンティティとの相関関係を理解することは、データ分析などの特定のシナリオでは非常に重要です。
LLM (Large Language Model) テクノロジーによる生産性の変化が議論される中、Web3 分野でも AI を活用してこれらの課題を解決できるかどうかが焦点の 1 つになっています。
3. AIとWeb3データの衝突が引き起こす化学反応
3.1. 従来のAIとLLMの特性の比較
モデルのトレーニングに関して、従来の AI モデルは通常、パラメータ数が数万から数百万に及ぶ小規模なモデルですが、出力結果の精度を確保するには、手動でラベル付けされた大量のデータが必要です。 。 LLM が非常に強力である理由の 1 つは、大規模なコーパスを使用して数百億、数千億のパラメーターを適合させるため、自然言語を理解する能力が大幅に向上することですが、それはまた、トレーニングを非常に困難にするためにより多くのデータが必要になることも意味します。高い。
機能範囲と操作方法の点で、従来の AI は特定分野のタスクにより適しており、比較的正確で専門的な回答を提供できます。対照的に、LLM は一般的なタスクにより適していますが、幻覚の問題が発生する傾向があります。つまり、場合によっては、LLM の答えが十分に正確でないか専門的ではない、あるいは完全に間違っている可能性さえあります。したがって、客観的で信頼できる追跡可能な結果が必要な場合は、複数のチェック、複数のトレーニング、または追加のエラー修正メカニズムやフレームワークの導入が必要になる場合があります。

図 6: 従来の AI とラージ モデル言語モデル (LLM) の機能の比較
3.1.1. Web3 データ分野における従来の AI の実践
従来の AI はブロックチェーン データ業界においてその重要性を示しており、この分野にさらなる革新と効率をもたらしています。たとえば、0x Scope チームは AI テクノロジーを使用して、グラフ コンピューティングに基づくクラスター分析アルゴリズムを構築しました。これは、さまざまなルールの重み付け分散を通じてユーザー間の関連するアドレスを正確に識別するのに役立ちます。この深層学習アルゴリズムの適用により、アドレス クラスタリングの精度が向上し、より正確なデータ分析ツールが提供されます。 Nansen は NFT 価格予測に AI を使用し、データ分析と自然言語処理テクノロジーを通じて NFT 市場動向に関する洞察を提供します。一方、Trusta Labs は、アセット グラフ マイニングとユーザー行動シーケンス分析に基づく機械学習手法を使用して、Sybil 検出ソリューションの信頼性と安定性を強化し、ブロックチェーン ネットワーク エコシステムのセキュリティの維持に貢献しています。一方、Trusta Labs は、グラフマイニングとユーザー行動分析手法を使用して、Sybil 検出ソリューションの信頼性と安定性を強化し、ブロックチェーン ネットワークのセキュリティの維持に貢献しています。 Goplus は、分散型アプリケーション (dApp) のセキュリティと効率を向上させるために、運用に従来の人工知能を活用しています。 dApps からセキュリティ情報を収集および分析し、迅速なリスク アラートを提供して、これらのプラットフォームでのリスク エクスポージャを軽減します。これには、オープンソースのステータスや潜在的な悪意のある動作などの要素を評価することで dApp マスター コントラクト内のリスクを検出することや、監査会社の資格情報、監査時間、監査レポートのリンクなどの詳細な監査情報を収集することが含まれます。 Footprint Analytics は AI を使用して、構造化データを生成し、NFT トランザクション、ウォッシュ取引トランザクション、ロボット アカウントのスクリーニングとトラブルシューティングを分析するコードを生成します。
ただし、従来の AI は情報が限られており、事前に設定されたタスクを実行するために事前に決定されたアルゴリズムとルールを使用することに重点を置いていますが、LLM は大規模な自然言語データから学習し、自然言語を理解して生成できるため、複雑で巨大なタスクの処理により適しています。テキストデータの量。
最近、LLM が大幅に進歩したため、AI と Web3 データの組み合わせについて新しい考えや探求も行われています。
3.1.2. LLM の利点
LLM には、従来の人工知能に比べて次の利点があります。
● スケーラビリティ: LLM は大規模なデータ処理をサポートします。
LLM はスケーラビリティに優れており、大量のデータやユーザー インタラクションを効率的に処理できます。そのため、テキスト分析や大規模なデータ クリーニングなど、大規模な情報処理が必要なタスクに最適です。その高度なデータ処理機能は、ブロックチェーン データ業界に強力な分析と応用の可能性をもたらします。
● 適応性: LLM は複数の分野のニーズに適応する方法を学習できます。
LLM は適応性が高く、特定のタスクに合わせて微調整したり、業界または民間のデータベースに埋め込んだりすることができるため、さまざまなドメインの微妙な違いをすばやく学習して適応することができます。この機能により、LLM はマルチドメインおよび多目的の問題を解決するための理想的な選択肢となり、多様なブロックチェーン アプリケーションに対する幅広いサポートを提供します。
● 効率の向上: LLM はタスクを自動化して効率を向上させます。
LLM の高い効率は、ブロックチェーン データ業界に大きな利便性をもたらします。自動化しないと大量の手動の時間とリソースが必要となるタスクを自動化することで、生産性を向上させ、コストを削減します。 LLM は、大量のテキストの生成、大規模なデータセットの分析、またはさまざまな反復タスクを数秒で実行できるため、待機時間と処理時間を短縮し、ブロックチェーンデータ処理をより効率的にすることができます。
● タスクの分解: 特定のタスクに対して特定の計画を生成し、大きなタスクを小さなステップに分割できます。
LLM エージェントには、特定のジョブに対して特定の計画を生成し、複雑なタスクを管理可能な小さなステップに分割する独自の機能があります。この機能は、大規模なブロックチェーン データを処理し、複雑なデータ分析タスクを実行する場合に非常に役立ちます。大規模なジョブを小さなタスクに分割することで、LLM はデータ処理プロセスをより適切に管理し、高品質の分析を出力できます。
この機能は、ロボットによる自動化、プロジェクト管理、自然言語の理解と生成などの複雑なタスクを実行する AI システムにとって極めて重要であり、これにより高レベルのミッション目標を詳細な行動ルートに変換し、タスク実行の効率と精度を向上させることができます。
● アクセシビリティと使いやすさ: LLM は、自然言語によるユーザーフレンドリーな対話を提供します。
LLM のアクセシビリティにより、より多くのユーザーがデータやシステムを簡単に操作できるようになり、これらの操作がさらにユーザーフレンドリーになります。 LLM は自然言語を通じて、ユーザーがデータの取得や分析のために複雑な技術用語や SQL、R、Python などの特定のコマンドを学習する必要なく、データとシステムへのアクセスと対話を容易にします。この機能により、ブロックチェーン アプリケーションの対象範囲が広がり、テクノロジーに精通しているかどうかに関係なく、より多くの人が Web3 アプリケーションやサービスにアクセスして使用できるようになり、それによってブロックチェーン データ業界の発展と普及が促進されます。
3.2. LLM と Web3 データの統合
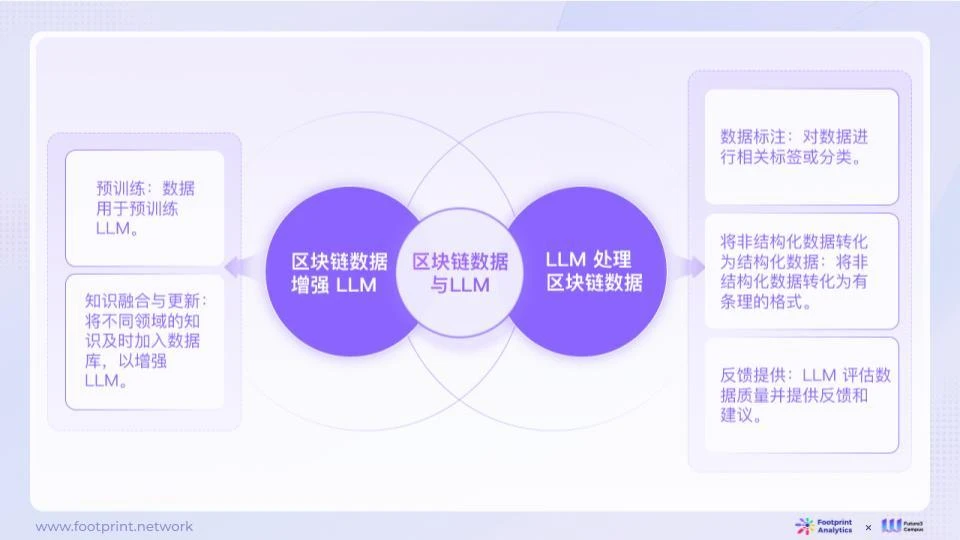
図 7: ブロックチェーン データと LLM の統合
大規模な言語モデルのトレーニングでは、大規模なデータに依存して、データ内のパターンを学習してモデルを構築する必要があります。ブロックチェーン データに含まれるインタラクションと行動パターンは、LLM 学習の燃料となります。データの量と質も、LLM モデルの学習効果に直接影響します。
LLM にとってデータは単なる消耗品ではなく、LLM はデータの生成にも役立ち、フィードバックを提供することもできます。たとえば、LLM は、データ アナリストがデータ クリーニングや注釈などのデータ前処理に貢献したり、データからノイズを除去して効果的な情報を強調するための構造化データを生成したりするのを支援できます。
3.3. LLM を強化するための共通の技術ソリューション
ChatGPT の出現は、複雑な問題を解決する LLM の一般的な能力を示すだけでなく、一般的な能力に外部の能力を重ね合わせるという世界的な探求のきっかけにもなります。これには、一般的な機能 (コンテキストの長さ、複雑な推論、数学、コード、マルチモダリティなど) の強化と、外部機能の拡張 (非構造化データの処理、より複雑なツールの使用、物理世界との対話など) が含まれます。 )。暗号分野における独自の知識と個人の個人データを大規模モデルの一般的な機能にどのように移植するかは、仮想通貨垂直分野における大規模モデルの商業化における中心的な技術的問題です。
現在、ほとんどのアプリケーションは、ヒント エンジニアリングや埋め込みテクノロジなどの検索拡張生成 (RAG) に焦点を当てており、既存のエージェント ツールのほとんどは、RAG 作業の効率と精度の向上に重点を置いています。市場にある LLM テクノロジーに基づくアプリケーション スタックの主なリファレンス アーキテクチャは次のとおりです。
● Prompt Engineering
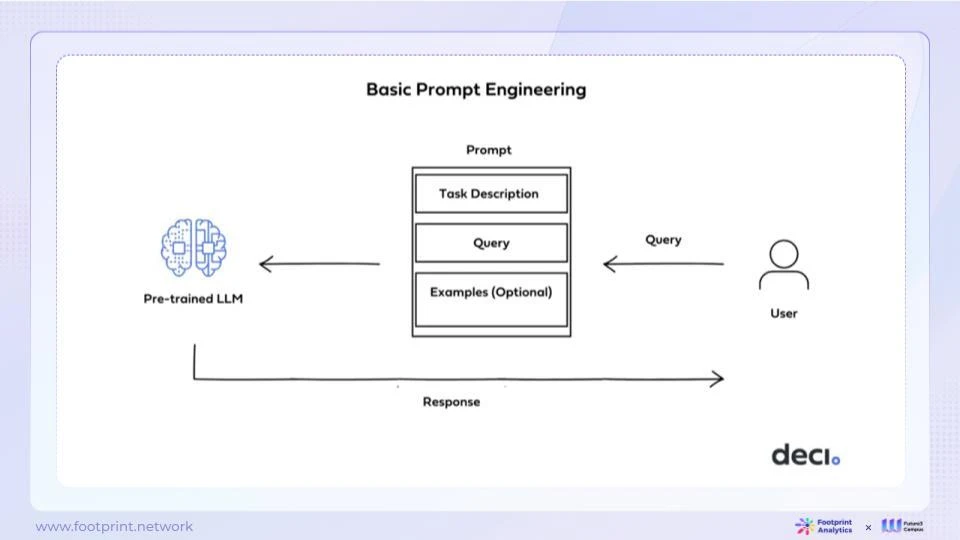
図 8: 迅速なエンジニアリング
現在、ほとんどの実務者は、アプリケーションを構築するときに基本的なソリューション、つまりプロンプト エンジニアリングを使用しています。この方法は、特定のアプリケーションのニーズを満たす特定のプロンプトを設計することにより、モデルの入力を変更する最も便利で迅速な方法です。ただし、基本的なプロンプト エンジニアリングには、タイミングの悪いデータベース更新、煩雑なコンテンツ、入力コンテキストの長さ (コンテキスト内長) のサポート、複数ラウンドの質問と回答の制限など、いくつかの制限があります。
したがって、業界では、埋め込みや微調整など、より高度な改善ソリューションも研究しています。
● 埋め込み
埋め込みは、人工知能の分野で広く使用されているデータ表現方法であり、オブジェクトの意味情報を効率的に取得できます。オブジェクトの属性をベクトル形式にマッピングすることにより、埋め込みテクノロジーはベクトル間の相関関係を分析することで、最も可能性の高い正解を迅速に見つけることができます。 LLM 上に埋め込みを構築して、モデルによって学習された豊富な言語知識を広範囲のコーパスで活用できます。特定のタスクやフィールドに関する情報は、埋め込みテクノロジーを通じて事前トレーニングされた大規模モデルに導入され、基本モデルの汎用性を維持しながら、モデルがより特化され、特定のタスクにさらに適応できるようになります。
平たく言えば、埋め込みとは、総合的な訓練を受けた大学生に参考書を渡し、特定のタスクに関連する知識が載っている参考書を使ってタスクを完了するように依頼するのと同じで、いつでもその参考書を参照して問題を解くことができます。特定の問題、問題。
● 微調整
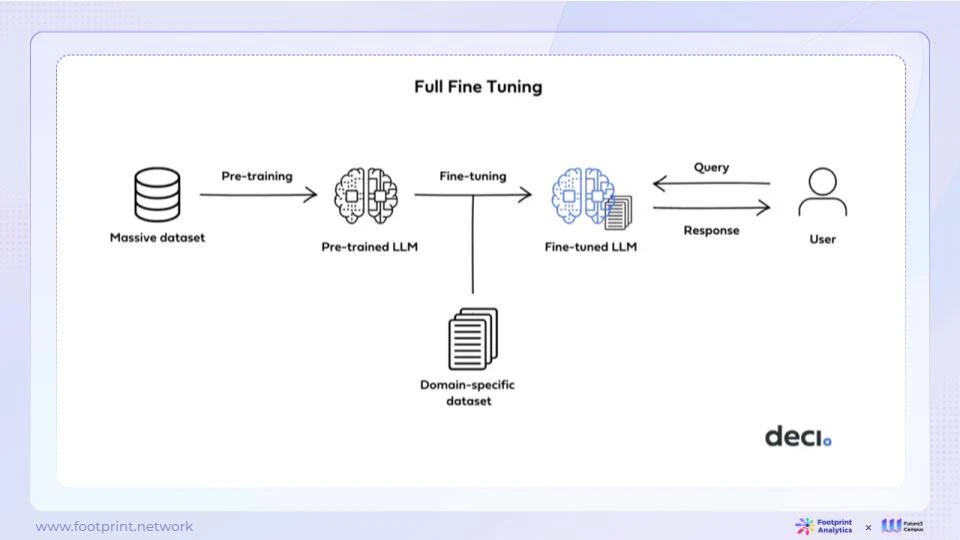
図 9: 微調整
微調整は、事前トレーニングされた言語モデルのパラメーターを更新して特定のタスクに適応させる埋め込みとは異なります。このアプローチにより、モデルは汎用性を保ちながら、特定のタスクでより優れたパフォーマンスを発揮できるようになります。微調整の中心的な考え方は、モデルのパラメーターを調整して、ターゲット タスクに関連する特定のパターンと関係をキャプチャすることです。ただし、モデルの一般的な微調整機能の上限は、依然としてベース モデル自体によって制限されています。
ファインチューニングとは、平たく言えば、総合的な研修を受けた大学生に専門知識の講座を与えることに似ており、総合的な能力に加えて専門講座の知識も習得し、専門分野の問題を自力で解決できるようになります。
● LLM を再トレーニングする
現在の LLM は強力ですが、すべてのニーズを満たしているわけではありません。 LLM の再トレーニングは、新しいデータセットを導入し、モデルの重みを調整して特定のタスク、ニーズ、またはドメインにより適したものにすることで、高度にカスタマイズされたソリューションです。ただし、この方法には多くのコンピューティング リソースとデータが必要であり、再学習されたモデルの管理と維持も課題の 1 つです。
● エージェントモデル
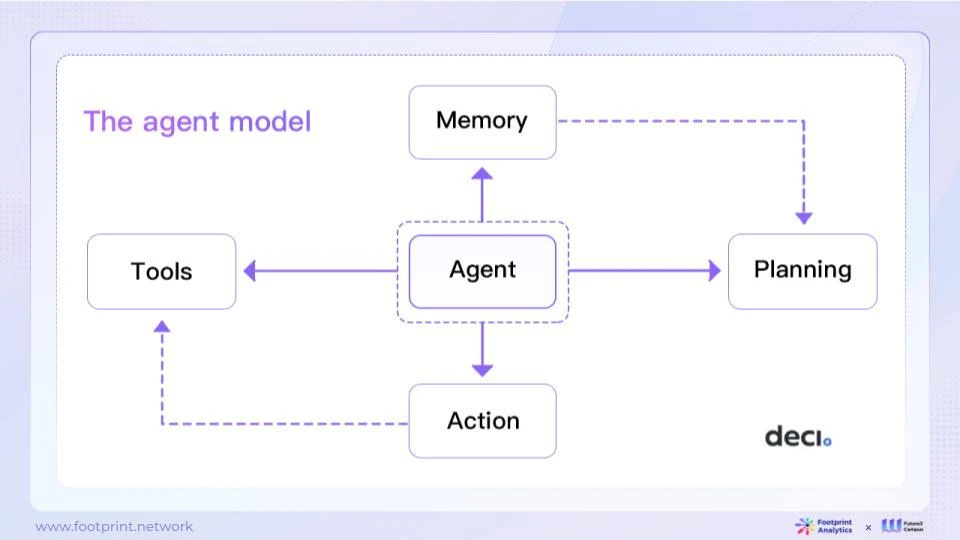
図 10: エージェント モデル
エージェント モデルは、LLM をコア コントローラーとして使用するインテリジェント エージェントを構築する方法です。このシステムには、より包括的なインテリジェンスを提供するためのいくつかの主要コンポーネントも含まれています。
● 計画: 大きなタスクを小さなタスクに分割して、完了しやすくします。
● 記憶、反省:過去の行動を振り返り、将来の計画を改善します。
● ツール、ツールの使用法: エージェントは、検索エンジンや計算機などの呼び出しなど、外部ツールを呼び出して詳細情報を取得できます。
人工知能エージェント モデルは、強力な言語理解と生成機能を備えており、一般的な問題を解決し、タスクの分解と内省を実行できます。これにより、さまざまな用途に幅広い可能性がもたらされます。ただし、エージェント モデルには、コンテキストの長さによって制限されること、長期計画やタスクの分割でエラーが発生しやすいこと、出力コンテンツの信頼性が不安定であることなど、いくつかの制限もあります。これらの制限により、さまざまな分野でエージェント モデルの適用をさらに拡大するには、長期にわたる継続的な研究と革新が必要です。
上記のさまざまな手法は相互に排他的ではなく、同じモデルのトレーニングと強化のプロセスで一緒に使用できます。開発者は、既存の大規模言語モデルの可能性を最大限に活用し、さまざまな方法を試して、ますます複雑になるアプリケーション要件を満たすことができます。この包括的な使用は、モデルのパフォーマンスを向上させるだけでなく、Web3 テクノロジーの急速な革新と進歩の促進にも役立ちます。
ただし、既存の LLM は Web3 の急速な発展において重要な役割を果たしてきましたが、これらの既存のモデル (OpenAI、Llama 2、その他のオープンソース LLM など) を完全に試す前に、浅いところから深いところまで始めることができると考えています。 , プロンプトエンジニアリングや埋め込みなどの RAG 戦略から始めて、基本モデルの微調整と再トレーニングを慎重に検討します。
3.4. LLM がブロックチェーンデータ生成のさまざまなプロセスをどのように加速するか
3.4.1. ブロックチェーンデータの一般的な処理の流れ
現在、ブロックチェーン分野の構築者は、データ製品の価値を徐々に認識しつつあります。この値は、製品運用監視、予測モデル、推奨システム、データ駆動型アプリケーションなどの複数の領域をカバーしています。この認識は徐々に高まっていますが、データ処理は、データ取得からデータ適用までの不可欠な重要なステップとして見落とされがちです。
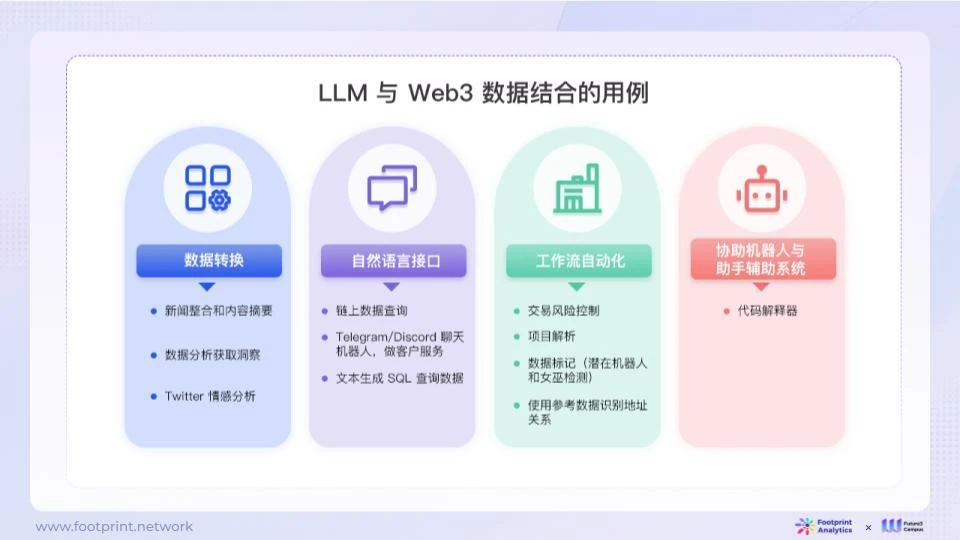
図 11: ブロックチェーン データ処理プロセス
● イベントやログなどのブロックチェーンの元の非構造化データを構造化データに変換します
ブロックチェーン上のすべてのトランザクションまたはイベントはイベントまたはログを生成しますが、これらのデータは通常、構造化されていません。このステップはデータを取得するための最初のエントリ ポイントですが、有用な情報を抽出して構造化された生データを取得するには、データをさらに処理する必要があります。これには、データの整理、例外の処理、共通形式への変換が含まれます。
● 構造化された生データをビジネス上の意味を持つ抽象テーブルに変換する
構造化された生データを取得した後、ビジネスをさらに抽象化し、そのデータをビジネス エンティティや指標 (トランザクション量、ユーザー量、その他のビジネス指標など) にマッピングして、生データをビジネスや意思決定にとって意味のあるデータに変換する必要があります。 。
● 抽象テーブルからビジネス指標を計算して抽出する
抽象的なビジネス データを取得した後、その抽象的なビジネス データに対してさらに計算を実行して、さまざまな重要な導出指標を取得できます。たとえば、総トランザクション量の月ごとの増加率やユーザー維持率などの主要な指標です。これらの指標は SQL や Python などのツールを使用して実装でき、ビジネスの健全性を監視し、ユーザーの行動と傾向を理解し、意思決定と戦略的計画をサポートするのに役立つ可能性が高くなります。
3.4.2. ブロックチェーンデータ生成プロセスにLLMを追加した後の最適化
LLM は、以下を含むがこれらに限定されない、ブロックチェーン データ処理における複数の問題を解決できます。
非構造化データを処理します。
● トランザクション ログとイベントから構造化情報を抽出: LLM は、ブロックチェーンのトランザクション ログとイベントを分析し、取引金額、取引当事者のアドレス、タイムスタンプなどの重要な情報を抽出し、非構造化データをビジネス上の意味を持つデータに変換できます。分析と理解が容易になります。
● データのクリーニングと異常なデータの特定: LLM は、一貫性のないデータや異常なデータを自動的に特定してクリーニングできるため、データの精度と一貫性が確保され、データ品質が向上します。
ビジネスの抽象化を実行します。
● 元のオンチェーン データをビジネス エンティティにマッピング: LLM は、ブロックチェーン アドレスを実際のユーザーや資産にマッピングするなど、元のブロックチェーン データをビジネス エンティティにマッピングできるため、ビジネス処理がより直観的かつ効率的になります。
● 非構造化オンチェーンコンテンツを処理してラベルを付ける:LLM は、Twitter センチメント分析結果などの非構造化データを分析し、ポジティブ、ネガティブ、またはニュートラルなセンチメントとしてマークすることができるため、ユーザーがソーシャル メディアの傾向に関するセンチメントをよりよく理解できるようになります。
データの自然言語解釈:
● コア指標の計算: ビジネスの抽象化に基づいて、LLM はユーザーの取引量、資産価値、市場シェアなどのコア ビジネス指標を計算し、ユーザーがビジネスの主要なパフォーマンスをよりよく理解できるようにします。
● クエリ データ: LLM はユーザーの意図を理解し、AIGC を通じて SQL クエリを生成できるため、ユーザーは複雑な SQL クエリ ステートメントを作成することなく、自然言語でクエリ リクエストを行うことができます。これにより、データベース クエリのアクセシビリティが向上します。
● インジケーターの選択、並べ替え、相関分析: LLM は、ユーザーがさまざまな複数のインジケーターを選択、並べ替え、分析して、それらの間の関係や相関関係をより深く理解できるように支援し、より深いデータ分析と意思決定をサポートします。
● ビジネス抽象化の自然言語説明の生成: LLM は、事実データに基づいて自然言語による概要や説明を生成し、ユーザーがビジネス抽象化とデータ指標をよりよく理解し、解釈可能性を高め、より合理的な意思決定を行えるようにします。
3.5. 現在の使用例
LLM 独自のテクノロジーと製品エクスペリエンスの利点によると、さまざまなオンチェーン データ シナリオに適用できます。技術的には、これらのシナリオは簡単なものから難しいものまで 4 つのカテゴリに分類できます。
● データ変換: テキストの要約、分類、情報抽出などのデータの強化や再構築などの操作を実行します。このタイプのアプリケーションは開発が速くなりますが、一般的なシナリオにより適しており、大量のデータの単純なバッチ処理には適していません。
● 自然言語インターフェイス: LLM をナレッジ ベースまたはツールに接続し、質疑応答や基本的なツールの使用を自動化します。これはプロフェッショナルなチャットボットの構築に使用できますが、その実際の価値は、接続されているナレッジ ベースの品質などの他の要因によって影響されます。
● ワークフローの自動化: LLM を使用してビジネス プロセスを標準化および自動化します。これは、スマートコントラクトの運用プロセスの分解やリスクの特定など、より複雑なブロックチェーンデータ処理プロセスに適用できます。
● 支援ロボットとアシスタント補助システム: 補助システムは、自然言語インターフェースに基づいてより多くのデータ ソースと機能を統合する拡張システムであり、ユーザーの作業効率を大幅に向上させます。
図 12: LLM アプリケーションのシナリオ
3.6. LLM の制限
3.6.1. 業界の現状: 成熟したアプリケーション、克服されつつある問題、未解決の課題
Web3 データの分野では、いくつかの重要な進歩が見られましたが、まだいくつかの課題があります。
比較的成熟したアプリケーション:
● 情報処理に LLM を使用する: LLM などの AI テクノロジーは、テキストの要約、概要、説明などを生成するためにうまく使用されており、ユーザーが長い記事や専門的なレポートから重要な情報を抽出するのに役立ち、データの読みやすさと理解しやすさを向上させます。
● AI を使用して開発上の問題を解決する: LLM は、StackOverflow や検索エンジンを置き換えて開発者に質問回答やプログラミング サポートを提供するなど、開発プロセスの問題を解決するために使用されてきました。
解決すべき問題と検討中の問題:
● LLM を使用してコードを生成する: 業界は、LLM テクノロジーを自然言語から SQL クエリ言語への変換に適用して、データベース クエリの自動化と理解しやすさを向上させることに熱心に取り組んでいます。ただし、そのプロセスには多くの困難が伴います。たとえば、場合によっては、生成されたコードに非常に高い精度が要求され、プログラムをバグなく実行して正しい結果を得るには、構文が 100% 正確である必要があります。困難には、質問への回答の成功率と正確性を確保すること、ビジネスを深く理解することも含まれます。
● データ注釈の問題: データ注釈は機械学習および深層学習モデルのトレーニングに不可欠ですが、Web3 データ分野では、特に匿名のブロックチェーン データを扱う場合、データの注釈付けは非常に複雑です。
● 精度と幻覚の問題: AI モデルにおける幻覚の発生は、偏ったまたは不十分なトレーニング データ、過剰適合、限られたコンテキスト理解、ドメイン知識の欠如、敵対的攻撃、モデル アーキテクチャなどの複数の要因によって影響を受ける可能性があります。研究者と開発者は、生成されるテキストの信頼性と精度を向上させるために、モデルのトレーニングとキャリブレーションの方法を継続的に改善する必要があります。
● ビジネス分析と記事出力へのデータ活用:ビジネス分析と記事作成へのデータ活用は依然として難しい課題です。問題の複雑さ、慎重に設計されたプロンプトの必要性、高品質のデータ、データ量、幻覚の問題を軽減する方法はすべて解決すべき問題です。
● データ抽象化のためにビジネス ドメインに基づいてスマート コントラクト データに自動的にインデックスを作成する: データ抽象化のために、さまざまなビジネス ドメインにわたってスマート コントラクト データに自動的にインデックスを作成することは、まだ未解決の問題です。そのためには、さまざまなビジネス分野の特性やデータの多様性と複雑さを総合的に考慮する必要があります。
● 時系列データ、表文書データ、その他のより複雑なモダリティの処理: DALL・E 2 などのマルチモーダル モデルは、テキストから画像や音声などの一般的なモダリティを生成するのに非常に優れています。ブロックチェーンや金融分野では時系列データによっては特殊な処理が必要となる場合があり、テキストのベクトル化だけでは解決できません。時系列データとテキストの組み合わせ、クロスモーダル共同トレーニングなどは、インテリジェントなデータ分析と応用を実現するための重要な研究方向です。
3.6.2. LLM だけではブロックチェーンデータ業界の問題を完全に解決できない理由
言語モデルとして、LLM はより高い流暢さを必要とするシナリオの処理に適していますが、正確さを追求するには、モデルへのさらなる調整が必要になる場合があります。 LLM をブロックチェーン データ業界に適用する場合、次のフレームワークが参考になります。
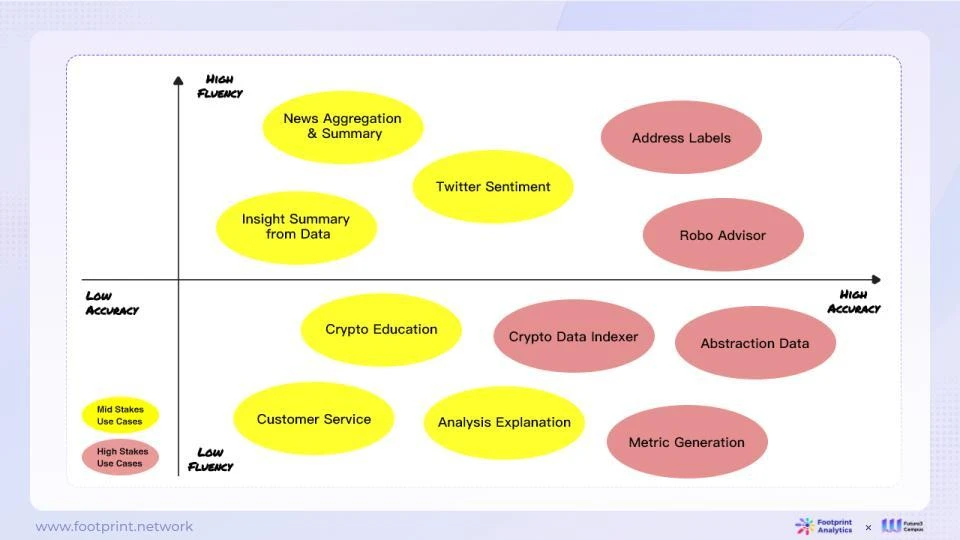
図 13: ブロックチェーン データ業界における LLM 出力の流暢性、正確性、およびユースケースのリスク
さまざまなアプリケーションにおける LLM の適合性を評価する場合、流暢さと正確さに焦点を当てることが重要です。流暢性はモデルの出力が自然で滑らかかどうかを指し、精度はモデルの答えが正確かどうかを示します。これら 2 つの次元には、さまざまなアプリケーション シナリオで異なる要件があります。
自然言語生成やクリエイティブライティングなど、高い流暢性が要求されるタスクには、自然言語処理における強力なパフォーマンスにより流暢なテキストを生成できる LLM が通常は適切です。
ブロックチェーンデータは、データ分析、データ処理、データ活用など多くの課題に直面しています。 LLM は優れた言語理解機能と推論機能を備えているため、ブロックチェーン データの操作、整理、要約に理想的なツールとなります。ただし、LLM はブロックチェーン データ フィールドのすべての問題を解決できるわけではありません。
データ処理の点では、LLM はオンチェーン データの迅速な反復および探索的処理により適しており、常に新しい処理方法を試しています。ただし、LLM には、運用環境での詳細な調整などのタスクに関しては、依然としていくつかの制限があります。典型的な問題は、トークンの長さが長いコンテキスト コンテンツを処理できるほど十分ではないことです。時間のかかるプロンプトは、不安定性がダウンストリーム タスクに影響を及ぼし、成功率が不安定になり、大量のタスクの実行効率が低下するという問題の解決策となります。
第二に、LLM によるコンテンツの処理では幻覚の問題が発生する可能性があります。 ChatGPT の幻覚確率は約 15% ~ 20% であると推定されており、その処理の不透明さにより、多くのエラーの検出が困難です。そのため、枠組みの構築と専門知識の導入が重要となります。さらに、LLM がオンチェーン データを結合する場合には、依然として多くの課題があります。
● チェーン上には多くの種類と膨大な量のデータ エンティティがあり、他の垂直産業と同様に、より多くの調査と調査が必要となる、どのような形式で LLM にフィードし、特定の商用シナリオで効果的に使用する必要があるか。
● オンチェーン データには構造化データと非構造化データが含まれており、業界の現在のデータ ソリューションのほとんどはビジネス データの理解に基づいています。オンチェーン データを解析するプロセスでは、ETL を使用してビジネス ロジックのフィルタリング、クリーンアップ、補足、復元が行われ、さらに非構造化データを構造化データに編成することで、将来のさまざまなビジネス シナリオに対してより効率的な分析が可能になります。たとえば、構造化された DEX 取引、NFT マーケットプレイス取引、ウォレット アドレス ポートフォリオなどは、前述の高品質、高価値、正確性、信頼性という特徴を備えており、一般的な LLM を効率的に補完することができます。
4. 誤解されている LLM
4.1. LLM は非構造化データを直接処理できるため、構造化データは不要になるのでしょうか?
LLM は通常、大量のテキスト データに基づいて事前トレーニングされており、あらゆる種類の非構造化テキスト データの処理に当然適しています。しかし、さまざまな業界はすでに大量の構造化データ、特に Web3 分野の解析データを保有しています。これらのデータを効果的に使用して LLM を強化する方法は、業界で注目の研究テーマです。
LLM にとって、構造化データには依然として次の利点があります。
● 大規模: 大量のデータ、特にプライベート データが、さまざまなアプリケーションの背後でデータベースやその他の標準形式に保存されます。どの企業や業界でも、事前トレーニング用の社内データのない大量の LLM が依然として存在します。
● 既存:このデータは作り直す必要がなく、投資コストが非常に低いので、問題は使い方だけです。
● 高品質かつ高価値: 現場で長年蓄積された専門知識は、通常、構造化データとして蓄積され、産学、研究で活用されます。データの完全性、一貫性、正確性、一意性、事実性など、構造化データの品質がデータの可用性の鍵となります。
● 高効率: 構造化データはテーブル、データベース、またはその他の標準化された形式に保存され、スキーマは事前定義されており、データ セット全体にわたって一貫しています。これは、データの形式、タイプ、関係が予測可能で制御可能であることを意味し、データ分析とクエリがより簡単かつ信頼性の高いものになります。さらに、業界にはすでに成熟した ETL と、より効率的で使いやすいさまざまなデータ処理および管理ツールが存在します。 LLM は API を通じてこのデータを使用できます。
● 正確性と事実性: LLM のテキスト データは、トークン確率に基づいており、現時点では正確な答えを安定して出力することができず、幻覚の問題は常に LLM が解決すべき中心的な基本問題でした。医療、金融など、多くの業界やシナリオで、セキュリティと信頼性の問題が発生します。構造化データは、LLM のこうした問題を支援し、修正できる方向性です。
● リレーショナル グラフと特定のビジネス ロジックを反映する: さまざまな種類の構造化データを特定の組織形態 (リレーショナル データベース、グラフ データベースなど) で LLM に入力して、さまざまな種類のドメインの問題を解決できます。構造化データは標準化されたクエリ言語 (SQL など) を使用するため、複雑なクエリとデータの分析がより効率的かつ正確になります。ナレッジ グラフはエンティティ間の関係をより適切に表現し、関連するクエリを容易にします。
● 低コスト: LLM は、ベース モデル全体を毎回最初から再トレーニングする必要がなく、エージェントや LLM API などのメソッドを有効にする LLM と組み合わせることで、より高速かつ低コストで LLM にアクセスできます。
市場には、LLM がテキスト情報や非構造化情報の処理能力に非常に優れていると信じている想像力豊かな意見がまだあり、非構造化データを含む生データを LLM にインポートするだけで実現できます。この考え方は、汎用 LLM に数学の問題を解くように依頼するのと似ています。特別に構築された数学能力のモデルがなければ、ほとんどの LLM は、小学校の簡単な足し算や引き算の問題を扱うときに間違いを犯す可能性があります。それどころか、数学的能力モデルや画像生成モデルと同様の Crypto LLM 垂直モデルを確立することは、暗号分野における LLM のより実用的なソリューションです。
4.2. LLM はニュースやツイートなどのテキスト情報からコンテンツを推測できます。結論を引き出すためにオンチェーン データ分析はもう必要ありません。
LLM はニュースやソーシャル メディアなどのテキストから情報を取得できますが、次の主な理由により、オンチェーン データから直接得られる洞察が依然として不可欠です。
● オンチェーンデータはオリジナルの一次情報ですが、ニュースやソーシャルメディアの情報は一方的または誤解を招く可能性があります。オンチェーンデータを直接分析することで、情報の偏りを軽減できます。テキスト分析に LLM を使用すると解釈バイアスのリスクが伴いますが、オンチェーンデータを直接分析することで誤解を減らすことができます。
● オンチェーンデータには包括的な過去のインタラクションとトランザクション記録が含まれており、分析により長期的な傾向とパターンを発見できます。チェーン上のデータは、資本の流れや関係者間の関係など、エコシステム全体の全体像を示すこともできます。これらの全体像を把握することで、状況をより深く理解できるようになります。一方、ニュースやソーシャルメディアの情報は、より断片的で短期的なものが多いです。
● チェーン上のデータはオープンです。誰でも分析結果を検証でき、情報の非対称性を回避できます。ニュースやソーシャルメディアが必ずしも真実を明らかにするとは限りません。テキスト情報とオンチェーンデータを相互検証することができます。両者を組み合わせることで、より立体的で正確な判断が可能となります。
オンチェーンデータ分析は依然として不可欠です。 LLM はテキストから情報を取得する補助的な役割を果たしますが、オンチェーン データの直接分析に代わることはできません。両方の利点を最大限に活用して、最良の結果を達成してください。
4.3. LangChain、LlamaIndex、またはその他の AI ツールを使用して、LLM に基づくブロックチェーン データ ソリューションを構築するのは簡単ですか?
LangChain や LlamaIndex などのツールは、カスタマイズされたシンプルな LLM アプリケーションを構築するのに便利で、迅速な構築を可能にします。ただし、これらのツールを実際の運用環境にうまく適用するには、さらに多くの課題が伴います。効率的に実行され、高品質を維持する LLM アプリケーションの構築は複雑なタスクであり、ブロックチェーン テクノロジーと AI ツールがどのように機能するかを深く理解し、それらを効果的に統合する必要があります。これは、ブロックチェーン データ業界にとって重要ではありますが、困難な課題です。
このプロセスでは、非常に高い精度と再現性のある検証が必要となるブロックチェーン データの特性を認識する必要があります。 LLM を通じてデータが処理および分析されると、ユーザーはその正確性と信頼性に対して高い期待を抱くようになります。これと LLM のファジー フォールト トレランスとの間には潜在的な矛盾があります。したがって、ブロックチェーン データ ソリューションを構築するときは、ユーザーの期待に応えるために、これら 2 つのニーズを慎重に比較検討する必要があります。
現在の市場にはすでにいくつかの基本的なツールがありますが、この分野は依然として急速に進化しており、継続的に反復されています。 Web2 の世界の開発プロセスに似ており、初期の PHP プログラミング言語から、Java、Ruby、Python、JavaScript、Node.js などのより成熟したスケーラブルなソリューション、Go や Rust などの新興テクノロジーに至るまで、継続的な開発と進化を経験しました。 AI ツールも常に変化しており、AutoGPT、Microsoft AutoGen などの新興 GPT フレームワークや、最近 OpenAI によって開始された ChatGPT 4.0 Turbo の GPT とエージェント自体は、将来の可能性の一部を示しているにすぎません。これは、ブロックチェーン データ産業と AI テクノロジーの両方にまだ開発の余地が多く、継続的な努力と革新が必要であることを示しています。
現在、LLM を適用する際に特別な注意が必要な落とし穴が 2 つあります。
● 期待が高すぎる: 多くの人は LLM ですべての問題を解決できると考えていますが、実際には LLM には明らかな限界があります。大量のコンピューティング リソースが必要で、トレーニングに費用がかかり、トレーニング プロセスが不安定になる可能性があります。 LLM の機能について現実的な期待を持ち、自然言語処理やテキスト生成などの一部のシナリオでは優れているものの、他の領域では能力が発揮できない可能性があることを理解してください。
● ビジネス ニーズの無視: もう 1 つの落とし穴は、ビジネス ニーズを十分に考慮せずに LLM テクノロジを強制的に適用することです。 LLM を適用する前に、特定のビジネス ニーズを特定することが重要です。 LLM が最適なテクノロジーの選択であるかどうかを評価し、リスクの評価と管理を行う必要があります。 LLM を効果的に適用するには、悪用を避けるために実際の状況に基づいて慎重に検討する必要があることが強調されます。
LLM は多くの分野で大きな可能性を秘めていますが、開発者や研究者は LLM を適用する際には注意し、より適切なアプリケーション シナリオを見つけてその利点を最大限に活用するために、オープンな探求の姿勢を採用する必要があります。
この記事は、Footprint Analytics、Future 3 Campus、HashKey Capital が共同で公開したものです。
私たちについて
Footprint Analyticsブロックチェーン データ ソリューション プロバイダーです。最先端の人工知能技術の助けを借りて、当社は暗号分野初のコード不要のデータ分析プラットフォームと統合データ API を提供し、ユーザーが 30 を超える公開データの NFT、GameFi、ウォレット アドレスの資金フロー追跡データを迅速に取得できるようにします。連鎖するエコシステム。
フットプリント公式サイト:https://www.footprint.network
Twitter:https://twitter.com/Footprint_Data
WeChat パブリック アカウント: フットプリント ブロックチェーン分析
コミュニティに参加: アシスタント WeChat グループを追加 footprint_analytics
Future 3 CampusWanxiang Blockchain LaboratoryとHashKey Capitalが共同で立ち上げたWeb3.0イノベーションインキュベーションプラットフォームで、上海、広東、香港、マカオ大湾区とのWeb3.0大規模導入、DePIN、AIの3大トラックに焦点を当てている。 、およびシンガポールを主要なインキュベーターとして拠点とし、グローバルな Web3.0 エコロジーを放射します。同時に、Future 3 Campus は、Web3.0 プロジェクトのインキュベーションのために 5,000 万米ドルの初期シードファンドを立ち上げ、Web3.0 分野におけるイノベーションと起業家精神に真の貢献をします。
HashKey Capitalブロックチェーン技術とデジタル資産への投資に重点を置いた資産管理機関であり、現在の資産管理規模は10億米ドルを超えています。アジア最大かつ最も影響力のあるブロックチェーン投資機関の 1 つであり、またイーサリアムへの最初の機関投資家でもある HashKey Capital は、Web2 と Web3 を結び付け、起業家、投資家、コミュニティ、規制当局とつながり、主導的なグース効果を発揮しています。持続可能なブロックチェーンエコシステムを構築します。同社は香港、シンガポール、日本、米国などに拠点を置き、レイヤー 1、プロトコル、暗号金融、Web3 インフラストラクチャ、アプリケーション、NFT、メタバース、および投資プロジェクトには、Cosmos、Coinlist、Aztec、Blockdaemon、dYdX、imToken、Animoca Brands、Falcon X、Space and time、Mask Network、Polkadot、Moonbeam、Galxe (旧 Project Galaxy) などが含まれます。





