
Gate Ventures Research Insights: 병렬 실행은 병목 현상, Ethereum EVM의 성능 문제 및 병렬 실행으로의 길을 돌파합니다.
Ethereum의 EVM은 단일 스레드 아키텍처로 인해 특히 높은 동시 트랜잭션을 처리할 때 심각한 성능 문제에 직면합니다. 이 직렬 실행 방법은 네트워크의 처리량을 제한하므로 처리 속도가 증가하는 사용자 요구를 충족시키지 못합니다. EVM 직렬 실행의 전체 프로세스를 단계별로 분석함으로써 우리는 이더리움의 병렬 실행을 달성하기 위한 두 가지 주요 소프트웨어 문제를 발견했습니다. 1. 상태 식별 2. 데이터 아키텍처 및 IPOS 소비 이 두 가지 문제를 해결하기 위해 각 회사는 각자의 방식을 가지고 있습니다. 자체 솔루션을 보유하고 EVM 호환 여부, 낙관적 병렬성 또는 비관적 병렬성을 사용할지 여부 식별, 데이터베이스의 데이터 아키텍처, 메모리 효율성이 더 높은 채널 또는 하드 디스크 동시성 채널을 사용할지 여부 등 다양한 절충점에 직면합니다. 개발자 개발 경험, 하드웨어 요구 사항, 모듈성 또는 모놀리식 체인 아키텍처 등은 모두 신중하게 평가할 가치가 있습니다.
우리는 또한 병렬 실행이 블록체인을 기하급수적으로 확장하는 것처럼 보이지만 여전히 병목 현상이 있음을 발견했습니다. 이러한 병목 현상은 P2P 네트워크 및 데이터베이스 자체의 처리량과 같은 문제를 포함하여 분산 시스템에 내재되어 있습니다. 블록체인 컴퓨팅이 기존 컴퓨터의 컴퓨팅 성능에 도달하려면 아직 갈 길이 멀습니다. 현재 병렬 실행 자체도 병렬 실행을 위해 점점 더 높아지는 하드웨어 요구 사항, 점점 더 전문화되는 노드로 인해 발생하는 중앙화 및 검열의 위험, 메모리, 중앙 클러스터 또는 노드에 의존하는 메커니즘 설계 등 몇 가지 문제에 직면해 있습니다. 다운타임의 위험을 가져오는 동시에 병렬 블록체인 간의 크로스체인 통신도 문제가 될 것입니다. 이는 여전히 더 많은 팀에서 살펴볼 가치가 있습니다.
각 회사의 아키텍처와 EVM 호환성에 대한 생각을 통해 우리는 파괴적인 혁신이 과거에 대한 타협하지 않는 데서 비롯된다는 것을 알고 있습니다. 블록체인 기술은 아직 초기 단계이며, 성능 개선이 최종 단계에 도달하기에는 아직 멀었습니다. 더 강력하고 흥미로운 제품을 만들기 위해 타협을 거부하고 어떠한 규칙도 따르지 않는 기업가들이 더 많아지기를 기대합니다.
이더리움의 단일 스레드 문제
Ethereum EVM은 주로 낙후된 아키텍처 설계로 인해 성능에 대해 항상 비판을 받아 왔으며, 그 중 병렬화를 지원하지 않는 문제가 가장 심각한 문제입니다. 트랜잭션 병렬화의 경우 도로를 여러 개의 활주로로 바꾸는 것과 같으며, 이는 도로에서 수용할 수 있는 교통량을 기하급수적으로 향상시킬 수 있습니다.
현재 실행 계층과 합의 계층이 분리되어 있는 배경에서 이더리움에 대해 더 깊이 들어가면 EVM의 모든 트랜잭션 처리가 직렬 실행이라는 것을 알 수 있습니다.
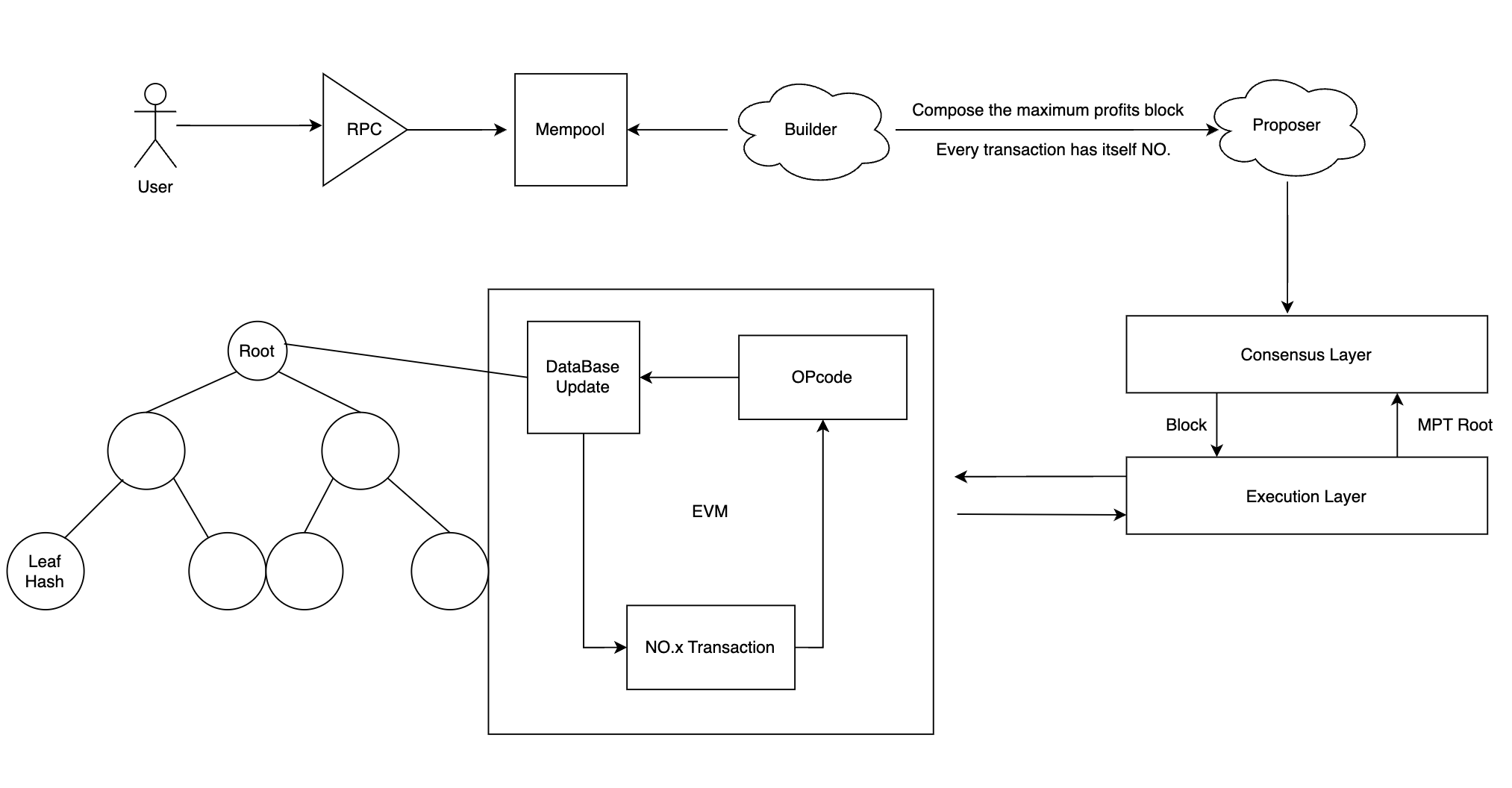
이더리움의 거래 실행 프로세스
이더리움 거래에서는 사용자가 먼저 RPC를 통해 Mempool에 거래를 보낸 후 Builder가 이익을 극대화하는 거래를 선택하고 정렬합니다. 이때 거래의 순서가 결정됩니다. 제안자는 트랜잭션을 합의 레이어에 브로드캐스팅하고, 합의 레이어는 유효한 발신자 등에서 블록의 유효성을 결정하며, 블록 내 트랜잭션은 실행 부하로 실행 레이어로 전송되고, 실행 레이어는 해당 트랜잭션을 실행합니다. 거래를 실행하는 간단한 과정은 다음과 같습니다. (예를 들어 Alice가 Bob에게 1 ETH를 보내는 경우)
1. 실행 노드의 EVM에서는 NO.0 트랜잭션 명령을 EVM이 인식할 수 있는 OPcode 코드로 변환합니다.
2. 그런 다음 OP코드 하드 코딩을 기반으로 이 거래에 필요한 가스를 결정합니다.
3. 트랜잭션 실행 중에 데이터베이스에 액세스하여 Alice와 Bob의 잔액 상태를 얻은 다음 트랜잭션 opcode를 실행하여 Alice의 잔액이 마이너스 1이고 Bob의 잔액이 플러스 1인지 확인하고 쓰기/업데이트해야 합니다. 이 잔액 상태를 데이터베이스에 전송합니다.
4. 블록에서 1번 트랜잭션을 꺼내어 해당 블록의 트랜잭션이 완료될 때까지 루프를 통해 순차적으로 계속 실행합니다.
5. 데이터베이스의 데이터는 주로 메르켈 번호 형태로 저장되며, 블록 내 모든 거래가 최종적으로 순차적으로 실행된 후 상태 루트(계정 상태 저장), 거래 루트(거래 순서 저장), 데이터베이스의 영수증 루트(성공 상태 및 가스 요금과 같은 거래에 대한 부수적 정보를 저장하는)가 합의 레이어에 제출됩니다.
6. 합의 계층은 상태 루트를 수신한 후 거래의 진위를 쉽게 증명할 수 있습니다. 실행 계층은 검증 데이터를 합의 계층으로 다시 전송하며 이제 블록은 검증된 것으로 간주됩니다.
7. 합의 계층은 자체 블록체인의 헤드에 블록을 추가하고 이를 증명하며, 그 증거를 네트워크를 통해 방송합니다.
이는 블록 내에서 트랜잭션의 순차적 실행을 포함하는 전체 프로세스입니다. 주된 이유는 각 트랜잭션에 고유한 NO가 있으며 각 트랜잭션은 데이터베이스에서 상태를 읽고 상태를 다시 작성해야 할 수 있기 때문입니다. 순차적으로 실행되지 않으면 일부 트랜잭션이 서로의 상태에 종속되어 있기 때문에 상태 충돌이 발생합니다. 이것이 바로 MEV가 직렬 실행을 선택하는 이유입니다.
MEV의 단순성은 직렬 실행이 극도로 낮은 성능을 가져온다는 것을 의미하며, 이는 이더리움이 두 자릿수 TPS만 갖는 주요 이유 중 하나입니다. 소비자 애플리케이션에 초점을 맞춘 현재 개발 맥락에서, 이전 버전의 설계 패러다임인 EVM은 시급히 개선이 필요한 성능 문제에 직면해 있습니다. 현재 EVM은 완전히 Layer 2 중심 로드맵으로 이동했지만, EVM 문제는 다음과 같습니다. MPT trie 구조, LevelDB 등 데이터베이스의 비효율성 문제를 시급히 해결해야 합니다.
이 문제가 발전함에 따라 많은 프로젝트에서 이더리움의 오래된 설계 패러다임을 해결하기 위해 병렬 고성능 EVM을 구축하기 시작했습니다. EVM 프로세스를 통해 고성능 EVM이 해결하는 두 가지 주요 문제가 있음을 알 수 있습니다.
1. 트랜잭션 상태의 분리: 상태의 상호 의존성으로 인해 트랜잭션은 순차적으로 실행되어야 하며, 독립적인 상태의 트랜잭션은 분리되어야 하고, 종속적인 트랜잭션은 순차적으로 실행되어야 합니다. 그런 다음 병렬 처리를 위해 여러 코어에 배포할 수 있습니다.
2. 데이터베이스 아키텍처 개선: Ethereum은 MPT 트리를 사용합니다. 트랜잭션에는 많은 수의 읽기 작업이 포함되므로 일반적으로 데이터베이스 읽기 및 쓰기 작업이 매우 높아집니다. 즉, IOPS(초당 IO) 요구 사항이 매우 높아집니다. 일반적인 소비자급 SSD는 이러한 수요를 충족할 수 없습니다.
일반적으로 현재 주류 블록체인 구축 솔루션에서 소프트웨어 최적화는 주로 병렬 트랜잭션을 구축하기 위한 트랜잭션 상태 분리와 동시 트랜잭션 상태 읽기를 지원하기 위한 데이터베이스 최적화에 관한 것입니다. 고성능에 대한 요구와 함께 대부분의 프로젝트의 하드웨어 요구 사항도 증가하고 있습니다. 이더리움은 레이어 1의 성능 확장에 대해 항상 매우 조심스러워왔습니다. 이는 중앙화와 불안정성을 의미하기 때문입니다. 그러나 현재의 고성능 EVM은 이러한 족쇄를 버리고 극단적인 소프트웨어 개선, P2P 네트워크 최적화, 데이터베이스 재구성 및 엔터프라이즈급 전문 하드웨어를 도입하는 경우가 많습니다.
파생된 데이터베이스 IOPS 문제
병렬 실행의 식별과 분리는 실제로 이해하기 어렵지 않습니다. 가장 큰 어려움과 덜 공개적인 논의는 데이터베이스의 IOPS 문제입니다. 이 기사에서는 독자들이 블록체인 데이터베이스가 직면한 복잡한 문제를 느낄 수 있도록 실제 사례도 사용할 것입니다.
Ethereum에서는 실제로 전체 노드가 가상 머신과 함께 설치되며 이는 일반 컴퓨터로 간주될 수 있습니다. 우리의 데이터는 전문 소프트웨어 데이터베이스에 저장됩니다. 이 소프트웨어를 사용하여 대용량 데이터를 관리하세요. 다양한 산업 데이터에는 데이터베이스 유형에 대한 요구 사항이 다릅니다. 예를 들어 벡터 데이터베이스는 다양한 데이터 유형이 있는 AI와 같은 분야에서 널리 사용됩니다. 블록체인 분야에서 이더리움은 비교적 간단한 키-값 쌍 데이터베이스를 사용합니다.
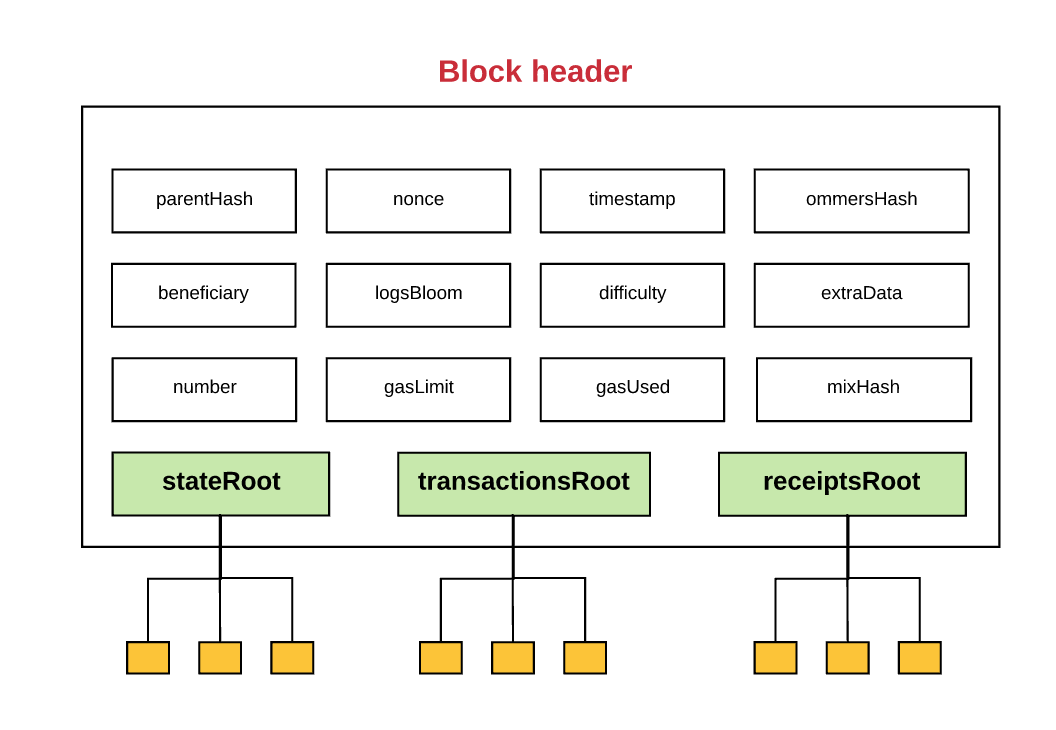
이더리움 데이터 조직의 개략도, 출처: Github
일반적으로 데이터베이스의 데이터는 추상적인 방식으로 함께 구성되며 이더리움은 MPT 트리 형태입니다. MPT 트리의 최종 데이터 상태는 루트 노드를 형성합니다. 데이터가 변경되면 루트 노드도 변경됩니다. 따라서 MPT를 사용하면 데이터 무결성을 쉽게 확인할 수 있습니다.
현재 데이터베이스의 리소스 소비를 느낄 수 있는 예를 들어보겠습니다.
n 리프 노드가 있는 k-포크 MPT(Merkle Patricia Tree)에서 단일 키-값 쌍을 업데이트하려면 O(klog kn) 읽기 작업과 O(log kn) 쓰기 작업이 필요합니다. 예를 들어, 160억 개의 키(즉, 1TB의 블록체인 상태)가 있는 바이너리 MPT의 경우 이는 약 68개의 읽기 작업과 34개의 쓰기 작업에 해당합니다. 우리의 블록체인이 초당 10,000개의 전송 트랜잭션을 처리하려고 하고 상태 트리에서 3개의 키 값을 총 10,000 x 3 x 68 = 2,040,000번 업데이트해야 한다고 가정합니다. 이는 2M IOPS(I/O Per)입니다. 둘째) 작업(실제로 압축 및 캐싱을 통해 약 200,000 IOPS까지 줄일 수 있으며 확장하지 않습니다). 현재 주요 소비자 SSD는 이를 지원할 수 없습니다(Intel Optane DC P 580 0X 800GB는 100,000 IOPS에 불과합니다).
MPT 트리는 현재 다음과 같은 여러 가지 문제에 직면해 있습니다.
● 성능 문제: 계층적 트리 구조로 인해 MPT는 데이터를 업데이트할 때 여러 노드를 통과해야 하는 경우가 많습니다. 각 상태 업데이트(예: 전송 또는 스마트 계약 실행)에는 많은 수의 해시 계산이 필요하며 많은 노드 계층에 액세스해야 하기 때문에 성능이 낮습니다.
● 상태 확장: 시간이 지남에 따라 블록체인의 스마트 계약 및 계정 잔액과 같은 상태 데이터가 계속 증가하여 MPT 트리의 크기가 계속 확장됩니다. 이로 인해 노드는 점점 더 많은 데이터를 저장해야 하게 되어 저장 공간 및 동기화 노드에 문제가 발생하게 됩니다.
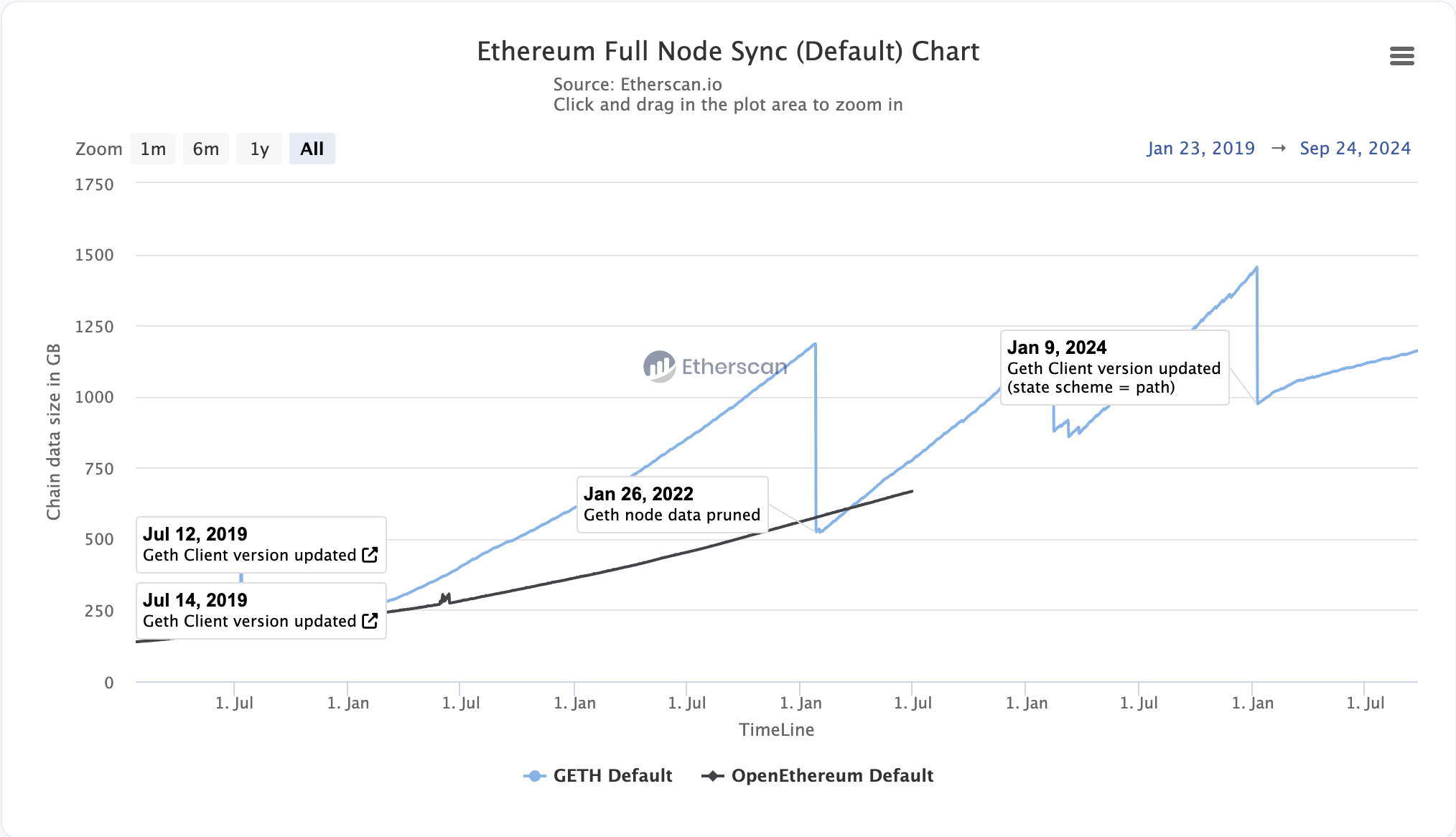
Ethereum 상태 확장(상태 정리 포함), 출처: Etherscan
● 부분 업데이트를 효율적으로 처리할 수 없음: 트리 구조의 리프 노드가 변경되면 전체 경로의 노드가 영향을 받습니다. 이더리움 MPT는 리프 노드에서 루트 노드까지 모든 해시 값을 다시 계산해야 하므로 로컬 상태 변경 사항도 많은 수의 노드에서 업데이트해야 하므로 성능에 영향을 미칩니다.
이더리움은 현재 MPT 하에서 다양한 문제에 직면해 있음을 알 수 있으며, 상태 확장을 위한 상태 가지치기, MPT 성능 문제에 대한 새로운 Verkel Tree 구축 등 다양한 솔루션도 제안했습니다. 새로운 Verkel Tree 구조 데이터베이스를 구축하여 부분 업데이트 중 데이터베이스 액세스 횟수를 줄이기 위해 트리 깊이를 줄이고, 벡터 커밋(주로 KZG 커밋)을 사용하여 증명 크기와 데이터베이스 액세스 양을 줄입니다.
즉, 과거 MPT 트리는 너무 오래되었고 많은 새로운 과제에 직면해 있으므로 Verkel 트리를 사용하는 등 데이터 저장 방식을 변경하는 것이 로드맵에 포함되었습니다. 그러나 이것은 매우 약한 수정일 뿐이며 여전히 병렬 실행과 높은 동시성에서 요구되는 높은 IOPS를 위한 솔루션을 포함하지 않습니다.
새로운 퍼블릭 체인은 병렬 실행을 표준으로 제공합니다.
이전 부분에서 말했듯이 병렬 실행은 단일 차선에서 다중 차선으로 변경하는 것을 의미합니다. 다중 차선 교차로에서는 각 차선이 원활하게 통과할 수 있도록 신호등 조정과 같은 미들웨어가 필요한 경우가 많습니다. 블록체인의 경우에도 마찬가지입니다. 병렬 실행을 위해 관련 없는 상태의 트랜잭션을 분리할 수 있도록 상태 식별 미들웨어를 통해 사용자 트랜잭션을 전달해야 합니다. 병렬 실행으로 인해 발생하는 높은 TPS는 대규모 IOPS 요구 사항을 의미합니다. 기본 데이터베이스의 경우. 거의 모든 새로운 레이어 1에는 표준 기능으로 병렬 실행이 있습니다.
병렬 실행 솔루션을 분류하는 방법에는 여러 가지가 있습니다. 기본 가상 머신에 따라 EVM(Sei, MegaETH, Monad)과 None-EVM(Solana, Aptos, Sui)으로 구분됩니다. 트랜잭션 상태 분리 방법에 따라 낙관적 실행(모든 트랜잭션이 수행되기를 원하지 않는다고 가정하고 상태가 충돌하면 트랜잭션의 이 부분이 롤백되어 다시 실행됨)과 조기 실행으로 나눌 수 있습니다. 선언(개발자는 프로그램에서 액세스된 상태 데이터를 선언해야 함) 이러한 분류는 또한 절충안을 의미합니다.
다음으로는 EVM 여부를 기준으로 나누지 않고 단순히 각 퍼블릭 체인의 상태 분리 및 데이터베이스 개선 사항을 비교해 보겠습니다.
메가ETH
MegaETH는 EigenDA를 합의 레이어와 DA 레이어로 사용하는 Ethereum의 보안에 의존하는 성능을 주요 목표로 하는 이종 블록체인입니다. 실행 계층으로서 하드웨어 성능을 극대화하고 TPS를 향상시킵니다.
트랜잭션 처리에는 세 가지 유형의 최적화 방법이 있습니다.
1. 상태 분리: 트랜잭션 우선순위를 이용한 스트리밍 블록 구성. 이 모델은 솔라나의 POS와 유사합니다. 사실 솔라나의 거래도 스트리밍 방식으로 구축되지만 솔라나는 우선순위가 없으며 모두 속도로 경쟁합니다. 그리고 MegaETH는 거래에 대한 일종의 우선순위 알고리즘을 구축할 수 있기를 원합니다.
2. 데이터베이스: MPT Trie의 문제를 해결하기 위해 더 높은 IOPS를 제공하는 새로운 데이터 구조를 구축했습니다. MegaETH의 코드베이스를 확인해 보니 Verkel Trie의 설계 방식도 참조하고 있는 것으로 나타났습니다.
3. 하드웨어 전문화: 분류기를 중앙 집중화하고 전문화함으로써 인메모리 컴퓨팅을 구현하여 IO 효율성을 크게 향상시킵니다.
실제로 MegaETH는 이더리움에 보안 및 검열 저항을 Layer 2로 맡겨서 노드를 최대한 최적화하고 POS의 경제적 보안을 통해 시퀀서가 악한 일을 하지 않도록 하고자 합니다. 여기에는 많은 이점이 있습니다. . 하지만 우리는 확장을 하지 않습니다. MegaETH는 병렬 실행을 위한 트랜잭션을 구축하고 있지만 실제로는 병렬 실행을 구현하지 않습니다. 단일 정렬 노드의 성능을 최대화하여 하드웨어로 성능을 최대한 확장한 다음 병렬 실행을 통해 성능을 확장하려고 합니다.
모나드
MegaETH와 달리 Monad는 병렬 실행, 병렬 실행의 상태 분리 및 데이터베이스 재구성을 위해 최적화해야 하는 두 가지 중요한 사항을 충족하는 별도의 체인입니다. Monad가 사용하는 구체적인 방법을 간략하게 설명합니다:
● 낙관적 병렬 실행: 트랜잭션 식별을 위해 모든 트랜잭션의 가장 고전적인 기본 상태는 상태 충돌이 발생하면 트랜잭션이 다시 실행됩니다. 이 방법은 현재 Aptos의 Block-STM 메커니즘에서 사용됩니다. . 잘 작동합니다.
● 데이터베이스 재구성: 데이터베이스의 IOPS를 향상시키기 위해 Monad는 EVM 호환 데이터 구조 MPT(Merkel Patricia Tree)를 재구성하고 Patricia Tree 호환 데이터 구조를 구현하며 최신 데이터베이스 비동기 I/O를 지원합니다. 데이터 쓰기가 완료될 때까지 기다리지 않고 특정 상태 읽기를 지원합니다.
● 비동기식 실행: Ethereum에서는 특정 합의 계층과 실행 계층을 엄격하게 식별하지만 합의 계층과 실행 계층(실행 계층인 Layer 2의 개념과 다름)이 있음을 발견했습니다. 여기서는 Ethereum이 여전히 필요하다는 것을 나타냅니다. 실행 노드(이더리움에서 트랜잭션을 실행하기 위한)는 여전히 서로 결합되어 있으며 실행 후 업데이트된 Merkel Root를 합의에 제공하므로 합의 레이어가 합의에 도달하기 위해 투표할 수 있습니다. 모나드는 정렬이 완료되는 순간 상태가 확정된 것으로 간주하므로 정렬된 트랜잭션에 대한 합의만 필요하며 이 결과를 밝히기 위한 실행은 필요하지 않습니다. 이 아이디어를 통해 Monad는 합의 레이어와 실행 레이어를 영리하게 분리하여 동시 합의 실행을 달성할 수 있습니다. 노드는 블록 N에 대한 합의 투표를 유지하면서 블록 N-1에서 트랜잭션을 실행할 수 있습니다.
물론 Monad에는 고성능 병렬 EVM 레이어 1을 함께 구축하는 새로운 합의 알고리즘 MonadBFT를 포함하여 다른 많은 기술도 있습니다.
앱토스
Aptos는 Facebook의 Diem 팀에서 분리되어 Move 듀오로 간주됩니다. 그러나 둘 사이의 기술 개념의 불일치로 인해 현재 둘의 Move 언어는 전반적으로 매우 달라졌습니다. Aptos It은 Diem의 원래 디자인에 더 가깝고 Sui는 디자인을 대폭 변경했습니다.
병렬 실행을 위해 해결해야 할 문제:
● 상태 식별: 낙관적 병렬 실행 Aptos는 기본적으로 트랜잭션을 낙관적으로 실행하는 Block-STM 병렬 실행 엔진을 개발했습니다. 현재 이 기술은 일반적으로 받아들여지고 있으며 Polygon, Monad, Sei, StarkNet은 모두 이 기술을 사용하고 있습니다.
● IO 개선: Block-STM은 다중 버전 데이터 구조를 사용하여 상태 충돌을 방지합니다. 예를 들어, 나머지 사람들이 데이터베이스를 작성하고 있다고 가정해 보겠습니다. 일반적으로 데이터 충돌을 피해야 하기 때문에 데이터베이스에 액세스할 수 없지만 다중 버전 데이터 구조를 사용하면 이전 버전에 액세스할 수 있습니다. 문제는 각 스레드에 대해 표시 가능한 버전을 생성해야 하기 때문에 이 솔루션은 막대한 리소스 소비를 발생시킨다는 것입니다.
● 비동기 실행: Monad와 유사하게 트랜잭션 전파, 트랜잭션 정렬, 트랜잭션 실행, 상태 저장 및 블록 검증이 모두 동시에 수행됩니다.
현재 Block-STM은 대부분의 퍼블릭 체인에서 받아들여지고 있으며, Monad는 이 기술의 출현 덕분에 개발자의 부담을 효과적으로 완화할 수 있다고 말했습니다. 그러나 앱토스가 직면한 문제는 Block-STM의 지능이 가지고 있다는 것입니다. 과도한 노드 요구 사항 문제는 이 문제를 해결하기 위해 전문적인 하드웨어와 중앙 집중화가 필요합니다.
수이
Sui는 Aptos와 마찬가지로 Diem 프로젝트에서 상속되었습니다. 이와 대조적으로 Sui는 비관적 병렬화를 사용하고 트랜잭션 간의 상태 종속성을 엄격하게 확인하며 잠금 메커니즘을 사용하여 실행 중 충돌을 방지합니다. 앱토스는 개발자들의 개발 부담을 덜어드리고자 합니다.
● 상태 식별: Aptosb와 달리 비관적 병렬화를 채택하므로 병렬 상태 식별을 시스템에 맡겨 처리하는 대신 개발자가 자신의 상태 액세스를 선언해야 합니다. 이는 개발자의 개발 부담을 증가시키고 시스템 설계의 복잡성을 줄입니다. 병렬화 능력이 향상됩니다.
● IO 개선: 현재 IO 개선은 주로 모델 개선에 관한 것입니다. Ethereum은 계정 기반 모델을 사용하며 각 계정은 데이터를 유지하지만 Sui는 계정 모델 대신 객체 구조를 사용합니다. 최대 성능으로 병렬 구현의 어려움에 영향을 미칩니다.
Sui는 EVM의 역사적 유산도 없고 호환성 문제도 없기 때문에 Move 시스템을 기반으로 과감한 변화를 주었습니다. 계정 모델의 경우에도 객체에 대한 혁신적인 아이디어를 제안했습니다. 그러나 객체 모델은 병렬 처리에 많은 이점을 제공합니다. 이론적으로 무한하게 확장할 수 있는 매우 독특한 네트워크 아키텍처를 구축하는 것도 객체 모델 때문입니다.
솔라나 - FireDancer
솔라나는 병렬 컴퓨팅의 선구자로 평가받고 있습니다. 솔라나의 철학은 항상 블록체인 시스템이 하드웨어의 발전과 함께 발전해야 한다는 것이었습니다. 현재 솔라나의 병렬 처리 방식은 다음과 같습니다.
● 상태 인식: SUI와 마찬가지로 Solana도 결정론적 병렬성을 사용합니다. 이는 모든 상태가 일반적으로 사전에 선언되는 임베디드 시스템을 다루는 Anatoly의 과거 경험에서 비롯됩니다. 이를 통해 CPU는 모든 종속성을 파악하여 필요한 메모리 부분을 미리 로드할 수 있습니다. 그 결과 시스템 실행이 최적화되지만 개발자는 사전에 추가 작업을 수행해야 합니다. 솔라나에서는 프로그램의 모든 메모리 종속성이 필요하며 구성된 트랜잭션(예: 액세스 목록)에 선언되어 런타임이 여러 트랜잭션을 병렬로 효율적으로 예약하고 실행할 수 있습니다.
● 데이터베이스: Solana는 Cloudbreak를 사용하여 계정을 모델로 사용하는 자체 사용자 정의 계정 데이터베이스를 구축했습니다. 계정 데이터는 라이브러리를 여러 레이어로 나누는 것과 유사하게 여러 "샤드"에 배포되며 이를 기반으로 할 수 있습니다. 로드 밸런싱을 위해 레이어 수를 늘리거나 줄입니다. SSD의 메모리에 매핑되므로 SSD는 파이프라인 설계를 통해 메모리를 통해 빠르게 작동할 수 있습니다. 또한 여러 데이터에 대한 병렬 액세스를 지원하고 동시에 32개의 IO 작업을 병렬로 처리할 수 있습니다.
솔라나는 개발자가 결정론적 병렬성을 통해 액세스해야 하는 상태를 선언하도록 요구합니다. 이는 실제로 프로그램 구성 측면에서 개발자가 직접 병렬 애플리케이션을 구축해야 하는 반면, 프로그램 스케줄링 및 런타임 파이프라인 비동기 병렬성이 필요한 것입니다. 프로젝트를 빌드해야 합니다. 데이터베이스 측면에서는 IPOS 개선을 위해 데이터 병렬화를 위한 자체 DataBase를 구축합니다.
동시에 후속 솔라나 반복의 클라이언트인 파이어댄서(Firedancer)는 매우 강력한 엔지니어링 역량을 갖춘 거대 양적 기업인 점프 트레이딩(Jump Trading)에 의해 주도 및 개발되었습니다. 하드웨어 제한. 개선 사항은 주로 P2P 전파, 하드웨어 SIMD 데이터 병렬 처리 등을 포함한 기본 하드웨어 개선을 목표로 합니다. 이는 MegaETH의 아이디어와 매우 유사합니다.
세이
현재 세이가 사용하고 있는
● 낙관적 병렬 실행: Aptos의 Block-STM 설계를 참조했습니다. Sei V1 버전은 Sui 및 Solana와 유사한 수동 병렬 처리 방식을 사용하므로 개발자가 사용하는 개체를 선언해야 합니다. 그러나 Sei V2 이후에는 Aptos의 낙관적 병렬 처리 방식으로 변경되었습니다. 이는 개발자가 부족한 Sei에 도움이 되며 EVM 생태계에서 계약을 보다 쉽게 마이그레이션할 수 있습니다.
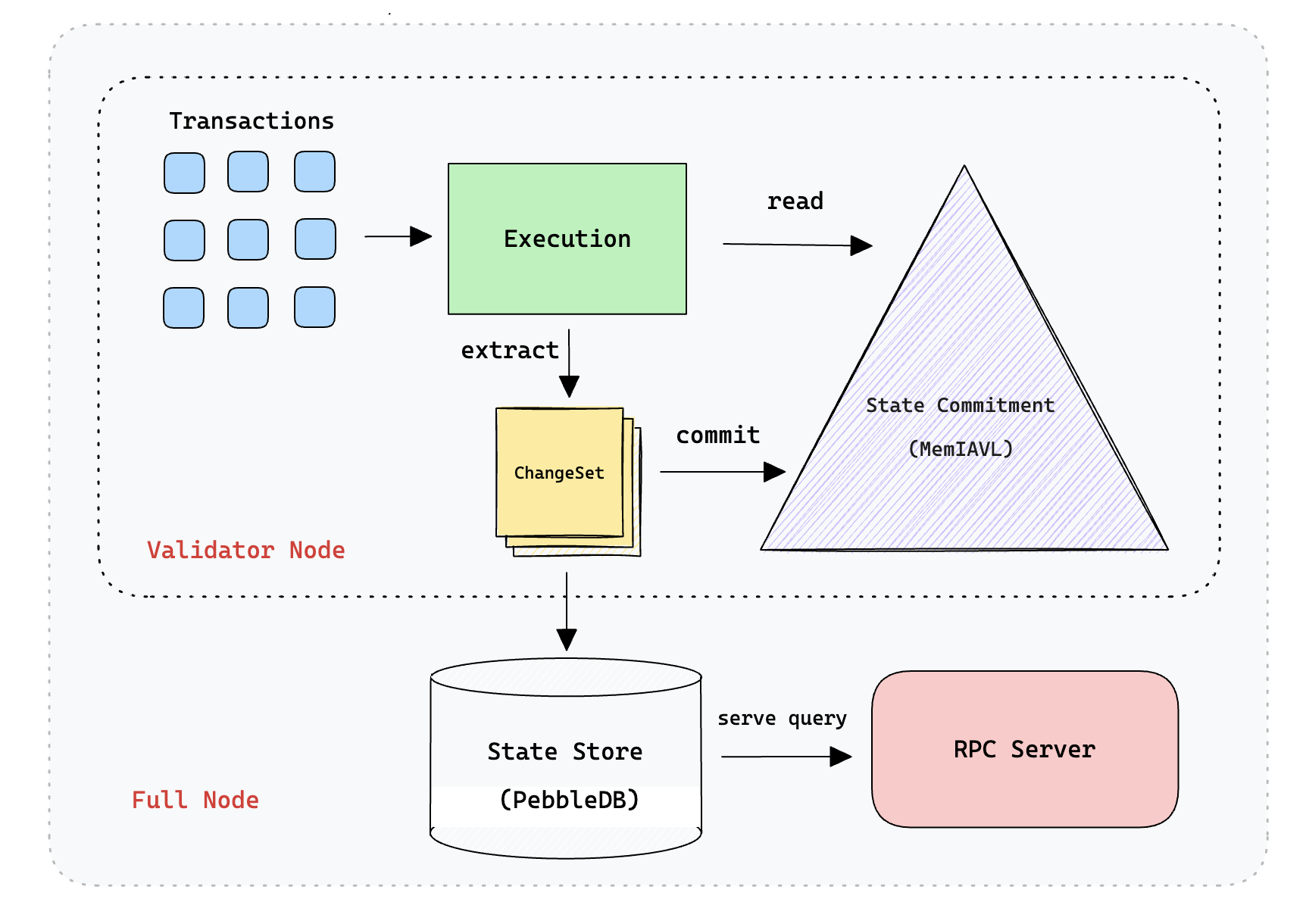
SeiDB 디자인, 출처: Sei
● SeiDB: 전체 데이터베이스 솔루션은 Cosmos의 ADR-065 제안을 기반으로 구축되었습니다. 해당 개체는 PebbleDB를 사용합니다. 데이터 구조는 데이터를 활성 데이터와 기록 데이터로 나누도록 설계되었습니다. SSD 하드 디스크의 데이터는 메모리에 매핑됩니다. 동시에 SSD 데이터는 MemIAVL 트리 구조를 사용하는 반면, 메모리 데이터는 합의 실행을 위한 상태 루트를 제공하는 상태 커밋을 위해 IAVL 트리(Cronos에서 개발)를 사용합니다. MemIAVL의 추상적 아이디어는 새 블록이 커밋될 때마다 해당 블록의 트랜잭션에서 모든 변경 사항 집합을 가져와 해당 변경 사항을 현재 메모리 내 IAVL 트리에 적용하여 새 버전의 트리를 생성한다는 것입니다. 최신 블록의 경우 블록 커밋의 Merkle 루트 해시를 얻을 수 있습니다. 따라서 핫 업데이트에 메모리를 사용하는 것과 동일하며 대부분의 상태 액세스를 SSD 대신 메모리에 위치시켜 IOPS를 향상시킬 수 있습니다.
SeiDB의 가장 큰 문제점은 최신 활성 데이터가 메모리에 저장되면 다운타임 동안 데이터가 손실된다는 점입니다. 따라서 MemIAVL은 WAL 파일과 트리 스냅샷을 도입합니다. 특정 기간 내에 메모리의 데이터를 스냅샷하여 로컬 하드 디스크에 저장해야 합니다. 특정 시간 스냅샷 간격을 제어하여 데이터 확장이 메모리에 미치는 OOM 영향을 적시에 제어합니다.
나란히 비교
전체 노드 요구 사항
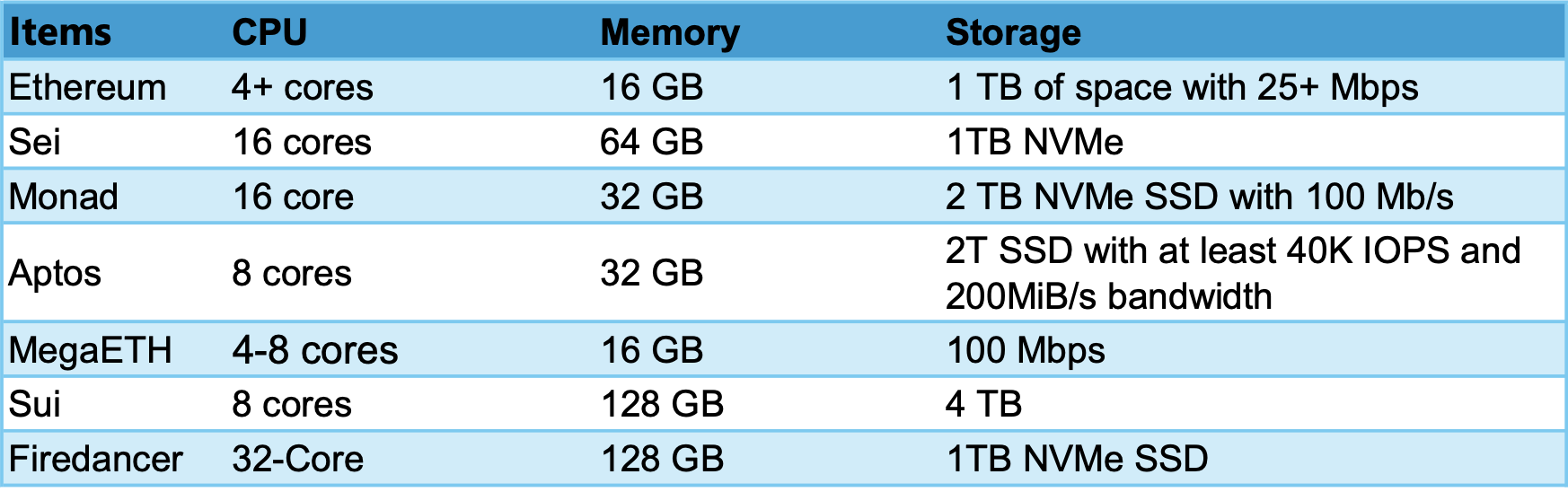
전체 노드 실행을 위한 요구 사항
FireDancer는 노드에 대한 작동 요구 사항이 가장 높으며 성능 괴물이라고 할 수 있습니다. MegaETH의 주요 성능 요구 사항은 100개 이상의 코어에 대한 시퀀서 요구 사항에 중점을 둡니다. 중앙 집중식 노드 시퀀서가 존재하기 때문에 다른 전체 노드에 대한 요구 사항은 높지 않습니다. 현재 SSD 가격은 상대적으로 저렴하기 때문에 일반적으로 CPU와 메모리의 성능 요구 사항만 살펴봅니다. 전체 노드 성능 요구 사항의 순위는 높은 것부터 낮은 것까지입니다: Firedancer > Sei > Monad > Sui > Aptos > MegaETH > Ethereum.
계획
현재 병렬 처리 솔루션의 경우 일반적으로 소프트웨어 수준의 최적화는 주로 1. 데이터베이스 IOPS 소비 문제, 2. 상태 식별 문제, 3. 파이프라인 비동기 문제에 중점을 둡니다. 이러한 세 가지 측면은 소프트웨어 수준을 최적화하는 데 사용됩니다. 상태 인정은 현재 낙관적 병렬 실행과 선언적 프로그래밍이라는 두 가지 진영으로 나뉩니다. 둘 다 장점과 단점이 있습니다. 그중 낙관적 병렬 실행은 주로 Aptos의 Block-STM 솔루션을 기반으로 하며, 주요 채택자에는 Monad 및 Sei V2가 포함되며 Sui, Solana 및 Sei V1은 모두 선언적 프로그래밍입니다. 기존의 동시 또는 비동기 프로그래밍 패러다임과 유사합니다. 데이터베이스의 IPOS 소비 문제와 관련하여 각 회사는 서로 다른 솔루션을 가지고 있습니다.
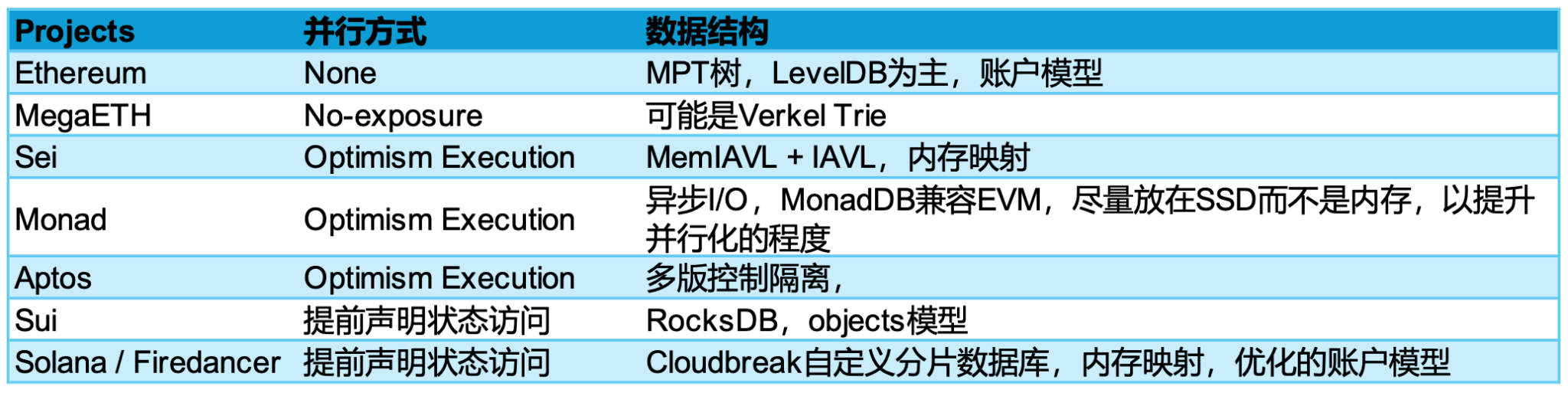
요금제 비교
데이터 구조를 보면 흥미로운 점이 있는데, Monad는 최대한 SSD에 배치하지만 하드디스크의 읽기 속도는 메모리에 비해 훨씬 느리지만 가격은 훨씬 저렴하다는 점이다. Monad는 가격, 하드웨어 임계값 및 병렬 처리 수준을 고려하여 SSD에 배치되었습니다. 이제 SSD는 더 많은 병렬 기능을 향상시키기 위해 32채널 I/O 작업을 지원할 수 있기 때문입니다. 대조적으로 Solana와 Sei는 메모리가 SSD보다 훨씬 빠르기 때문에 메모리 매핑을 선택합니다. 하나는 병렬 채널을 수평으로 확장하는 것이고, 다른 하나는 I/O 소비를 줄이기 위해 수직으로 확장하는 것입니다. 이것이 Monad의 노드 요구 사항이 32GB인 이유이지만 Sei와 Solana는 더 많은 메모리를 필요로 합니다.
또한 이더리움의 데이터 구조는 Patrci Tree에서 진화된 Merkel Patric Tree에서 파생되므로 EVM 호환 퍼블릭 체인은 Merkel Trie와 호환되어야 하므로 Aptos와 같은 자산을 생각하는 추상적인 방식을 구축할 수 없습니다. Sui, Solana 등 이더리움은 계정 모델을 기반으로 하지만 Sui는 객체 모델, Solana는 데이터와 코드를 분리하는 계정 모델이며 이더리움은 실제로 서로 결합되어 있습니다.
파괴적인 혁신은 과거에 대한 타협에서 비롯됩니다. 비즈니스 관점에서 볼 때 개발자 커뮤니티를 고려하는 것이 실제로 필요하며 과거 EVM 호환성에는 장단점이 있습니다.
시야
현재 병렬 실행의 주요 최적화 구성 요소는 상태를 식별하는 방법과 데이터 읽기 및 저장 속도를 향상시키는 방법에 중점을 두는 상대적으로 명확한 목표를 가지고 있습니다. 데이터 오버헤드 및 소비, 특히 Merkel trie는 루트 검증을 도입하지만 매우 높은 IO 오버헤드를 가져옵니다.
병렬 실행이 블록체인을 기하급수적으로 확장했지만 여전히 병목 현상이 발생합니다. 이러한 병목 현상은 P2P 네트워크, 데이터베이스 및 기타 문제를 포함한 분산 시스템에 내재되어 있습니다. 블록체인 컴퓨팅이 기존 컴퓨터의 컴퓨팅 성능에 도달하려면 아직 갈 길이 멀습니다. 현재 병렬 실행 자체도 병렬 실행을 위해 점점 더 높아지는 하드웨어 요구 사항, 점점 더 전문화되는 노드로 인해 발생하는 중앙화 및 검열의 위험, 메모리, 중앙 클러스터 또는 노드에 의존하는 메커니즘 설계 등 몇 가지 문제에 직면해 있습니다. 가동 중지 시간의 위험을 가져오는 동시에 병렬 블록체인 간의 크로스체인 통신도 문제가 될 것입니다.
병렬 실행에는 여전히 특정 문제가 있지만 각 회사는 MegaETH가 주도하는 모듈식 설계 아키텍처와 Monad가 주도하는 모놀리식 체인 설계 아키텍처를 포함하여 최고의 엔지니어링 사례를 모색하고 있습니다. 현재 병렬 실행 최적화 체계는 블록체인 기술이 지속적으로 전통적인 컴퓨터 최적화 체계에 더 가까워지고 있으며, 특히 데이터 저장, 하드웨어, 파이프라인 및 기타 기술의 세부 최적화가 점점 더 하위 수준에서 최적화되고 있음을 입증합니다. 그러나 이 문장에는 여전히 병목 현상과 문제가 남아 있으므로 기업가들에게는 아직 탐색할 수 있는 여지가 매우 광범위하게 남아 있습니다.
파괴적인 혁신은 과거를 타협하지 않는 것에서 비롯되며, 우리는 더 강력하고 흥미로운 제품을 만들기 위해 타협하지 않는 더 많은 기업가를 보고 싶습니다.
부인 성명:
위 내용은 참고용일 뿐이며 조언으로 간주되어서는 안 됩니다. 투자하기 전에 항상 전문가의 조언을 구하십시오.
게이트벤처스 소개
Gate Ventures 는 Gate.io의 벤처 캐피털 계열사로 웹 3.0 시대에 세상을 재편할 분산형 인프라, 생태계 및 애플리케이션에 대한 투자에 중점을 두고 있습니다. Gate Ventures는 글로벌 업계 리더들과 협력하여 혁신적인 사고와 역량을 갖춘 팀과 스타트업에 힘을 실어 사회와 금융의 상호 작용 모델을 재정의합니다.
공식 홈페이지: https://ventures.gate.io/ 트위터: https://x.com/gate_ventures 매체: https://medium.com/gate_ventures


