




原文:A Singular Trajectory
1999 年,Ray Kurzweil 曾做出以下预测:
2009 年,计算机将是平板电脑或更小尺寸的设备,高质量但传统显示屏;
2019 年,计算机将“基本上不可见”,大部分图像直接投射到视网膜中;
2029 年,计算机将通过直接神经通路进行通信。
在观察近 20 年人工智能、机器人技术和制造的发展,尤其是近期的 AIGC 的进展,有一些指标已表明,技术正在加速向奇点发展。
技术奇点
奇点(singularity)原意还有“奇异、突出、稀有”的意思,而这些意思逐渐被引申到自然科学中,先是应用于数学领域,后被引申至物理学界、天文学界等。不同版本的“技术奇点”预测便随之而来。

技术奇点“ 1.0 版”:
1958 年,“技术奇点”这个概念第一次被波兰数学家斯塔尼斯拉夫·乌拉姆(Stanisław Marcin Ulam)提出:“科技迭代的加速与人类生活方式的改变,似乎将把我们的历史进程带往一个重要的‘奇点’,在那之后,人类所熟知的事物将无法延续”,世界将会发生翻天覆地的变化。
技术奇点“ 2.0 版”:
1993 年,计算机科学家、科幻小说家文奇(Vernor Vinge)在《即将到来的技术奇点》(The Coming technology singularity)一文中写道,“技术奇点”这一时间点的到来将标志着人类时代的终结,而超级智能是“技术奇点”出现的前提,因为新的超级智能(super intelligence)将继续自我升级,并以不可思议的速度取得技术进步。
技术奇点“ 3.0 版”:
2005 年,奇点大学创始人兼校长、谷歌技术总监雷·库兹韦尔(Ray Kurzweil)在《奇点临近》(The Singularity Is Near)一书中将“技术奇点”的概念再一次调整,也更接近于我们所熟知的概念,并在当时预测技术奇点将会在 2045 年出现。他认为“技术奇点”是指技术变革迅速而深远的发展将对未来人类生活造成的不可逆转的变化,主要指代人工智能的快速发展。奇点将允许我们超越生物身体和大脑的限制,未来人类和机器之间将没有区别。
技术奇点“ 4.0 版”:
2013 年,牛津大学人类未来研究所高级研究员桑德伯格(Anders Sandberg)将“技术奇点”的影响范围扩大,他认为“超级智能”未必是必须的,任何新技术都有可能给人类社会带来的根本变化,而这样的技术发展和变化都可以称之为“技术奇点”。
GPT 用户,梦想有一个同伴吗?
2022 年 11 月 30 日,OpenAI 发布了 ChatGPT,一种会话界面和大型语言模型。对许多人来说,这是一个革命性的时刻。它的输出让人震惊,节省时间并且答案令人信服地真实(当 OpenAI 认为可以安全回答时)。

非常了不起的是,你今天在几秒钟内可以通过 LLM 得到一个不完美但有效的答案,而这个答案将花费领域专家几分钟的考虑和在线论坛几个小时的辩论。
聊天机器人一直是人们渴望的陪伴对象。图灵测试背后的动机可能是想要一个不会打破沉浸感的聊天机器人。
仍有待测试的是,作为社会动物的人类是否能通过数字大脑得到增强。我们一起打猎,一起耕种,现在社会可以被描述为工业规模机器的管理人员和操作员的巨大缓冲区,比以往任何时候都更加社会化。
人类会优化阻力最小的路径,选择复制或“谷歌”他们可能通过批判性思维和反复失败获得的不同知识。ChatGPT 的出现:学生可能会使用 LLM 为他们写论文,取得好成绩。Stack Overflow 可能会为了个人利益而受到女巫攻击,而观众(程序员)可能会以某种方式遵守 deepfakes 的交响曲。脚本小子可能会提示 ChatGPT 存在恶意软件。LLM 的主流使用是否会削弱我们的生产能力,尤其是在健全、有效和发散性思维方面?
奇点之前的最后傀儡师
人工智能可以产生的最深远的影响在于人力资本分配的文化。最近的一个观点很好地描述了人们对 ChatGPT 的反应:
最高兴的是那些发现机器显然可以胜任书面委托而目瞪口呆的人。
到目前为止,一切都在预料之中。如果回看历史会发现,人们通常高估了新的通信技术的短期影响,而严重低估了它们的长期影响。印刷、电影、广播、电视和互联网也是如此。
在试图理解 AI 的影响时,我们试图分离出短期的破坏,以猜测中期和长期的后果。
话虽如此,也许通过市场动态来描述这种反弹是一个好方法。AI 助手改变了内容创作的稀缺性,从而在某种程度上成为做市商。每当一个众所周知的“精灵”离开“瓶子”时,消费者通过重新定价市场和逐步淘汰次优供应商而获得不对称的利益。反过来,基于 AI 生产的供应商随着时间的推移,积累了更多的资本。
有人可能会争辩说,存在能够负担得起爬取整个互联网以生成训练数据集的公司的寡头垄断。可能只有有限数量的 SaaS 能够负担得起消耗此类资源来生成新颖的 ML 模型。如果基于 ML 的商业变得足够不稳定,那么能够实现和保持 PMF 的人可能会更少。在过去,我们被像 HAL 9000、Skynet 和 Butlerian Jihad 这样的心理战术哄骗。
许多公司和智能代理在 AI 经济中就稀缺性进行合作。我们现在的资本主义社会产生一个没有负面反馈的技术官僚的可能性有多大,它可以逐步淘汰社会经济阶层,基本原则,如人权/财产权,或加速某种形式的大规模毁灭的可能性?
这听起来可能很陈词滥调,但需要注意的即将到来的拐点将对社会运作方式产生根本性影响。一年后,有人可能会写下关于特定 AI 依赖产品的快速立法或郁金香狂热。在 5-10 年内,将实现对独资经济、现有政府形式和个人自主/消费的清算。“ Megacorp ”模式可能在整个颠覆过程中仍占主导地位,我们可能会发现自己处于“网络状态”,或者更像奥威尔式的状态。这一切都是因为计算机(通过任何方式获得)将编译我们对自然语言的集体使用,以包含当今社会的许多操作和经济功能。无论时间线是什么,这都将是远在“奇点”之前的一个明显拐点。
方法与技术
InstructGPT 的核心是一群人来策划最好的模仿(也称为通过人类反馈或 RLHF 进行强化学习)。但 InstructGPT 是一个 LLM,有点静态且易于重置。一个提示界面,幕后的模型经过反复训练,以猜测对提示的最简单的奖励反应。
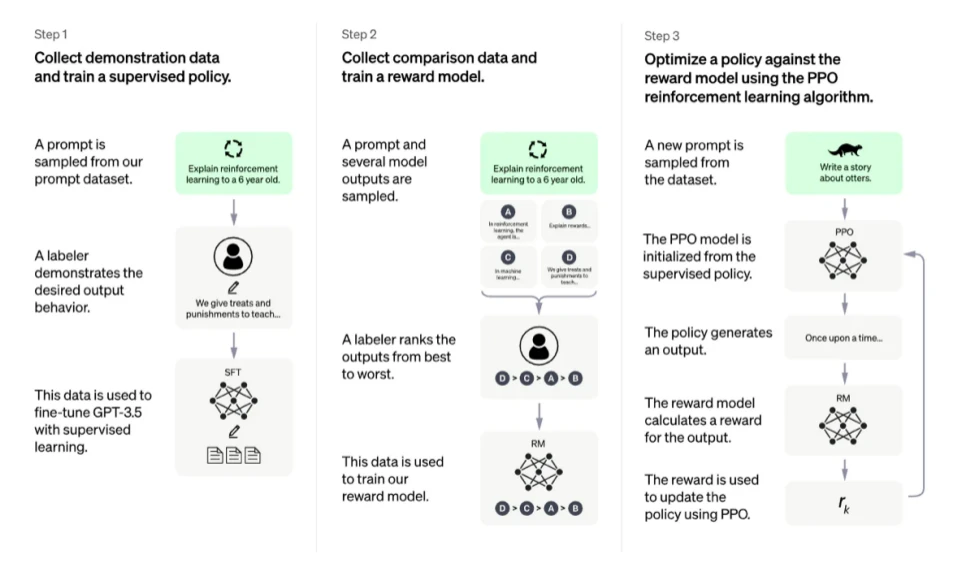
OpenAI 的 RLHF 图解
然而,要“完善” NLP 也存在挑战。
虽然这些技术极具前景和影响力,并引起了人工智能领域最大研究实验室的关注,但仍然存在明显的局限性。这些模型可以毫无不确定性地输出有害或实际上不准确的文本。这种不完美代表了 RLHF 的长期挑战和动力——在一个固有的人类问题领域中运行意味着永远不会有一条明确的终点线可以跨越,使模型被标记为完整。
在使用 RLHF 部署系统时,由于强制性和深思熟虑的人为因素,收集人类偏好数据非常昂贵。RLHF 性能仅与其人工注释的质量一样好,人工注释有两种:人工生成的文本,例如微调 InstructGPT 中的初始 LM,以及模型输出之间的人类偏好标签。
生成写得很好的人工文本来回答特定的提示是非常昂贵的,因为它通常需要雇用兼职人员(而不是能够依赖产品用户或众包)。值得庆幸的是,用于训练大多数 RLHF 应用的奖励模型的数据规模(~ 50 k 标记偏好样本)并不那么昂贵。然而,它仍然比学术实验室可能负担得起的成本更高。
目前,只有一个基于通用语言模型的 RLHF 大规模数据集(来自 Anthropic)和几个较小规模的任务特定数据集(例如来自 OpenAI 的摘要数据)。RLHF 数据挑战是标注者的偏见。几个人类标注者可能有不同意见,导致了训练数据存在一些潜在差异。
RLHF 可以应用于自然语言处理 (NLP) 之外的机器学习。例如,Deepmind 探索了将其用于多模态代理。同样的挑战适用于这种情况:
可扩展强化学习 (RL) 依赖于查询成本低廉的精确奖励函数。当 RL 可以应用时,它已经取得了巨大的成就,创造了可以匹配人类才能分布极值的 AI(Silver 等人, 2016 年;Vinyals 等人, 2019 年)。然而,对于人们经常参与的许多开放式行为,这种奖励功能并不为人所知。例如,考虑一种日常互动,要求某人“将杯子放在你附近”。对于能够充分评估这种交互的奖励模型,它需要对以自然语言提出请求的多种方式以及满足(或不满足)请求的多种方式具有鲁棒性,同时对不相关的变化因素(杯子的颜色)和语言固有的歧义(什么是“接近”?)不敏感。
因此,为了通过 RL 灌输更广泛的专家级能力,我们需要一种方法来生成精确的、可查询的奖励函数,以尊重人类行为的复杂性、可变性和模糊性。除了对奖励函数进行编程之外,一种选择是使用机器学习来构建它们。我们可以要求人类评估情况并提供监督信息以学习奖励函数,而不是尝试预测和正式定义奖励事件。对于人类可以自然、直观、快速地提供此类判断的情况,使用此类学习奖励模型的 RL 可以有效地改进智能体(Christiano 等人, 2017 年;Ibarz 等人, 2018 年;Stiennon 等人, 2020 年;)
导致奇点的许多因素有待进一步发展,我们可以比实施它们所花费的时间框架更有把握地确定它们是什么。Chris Lattner 从他的 POV 中提到了“稀疏门控的专家组合”:
简单地描述一下,也许有一个中介可以策划和组合许多“专家”的输入。
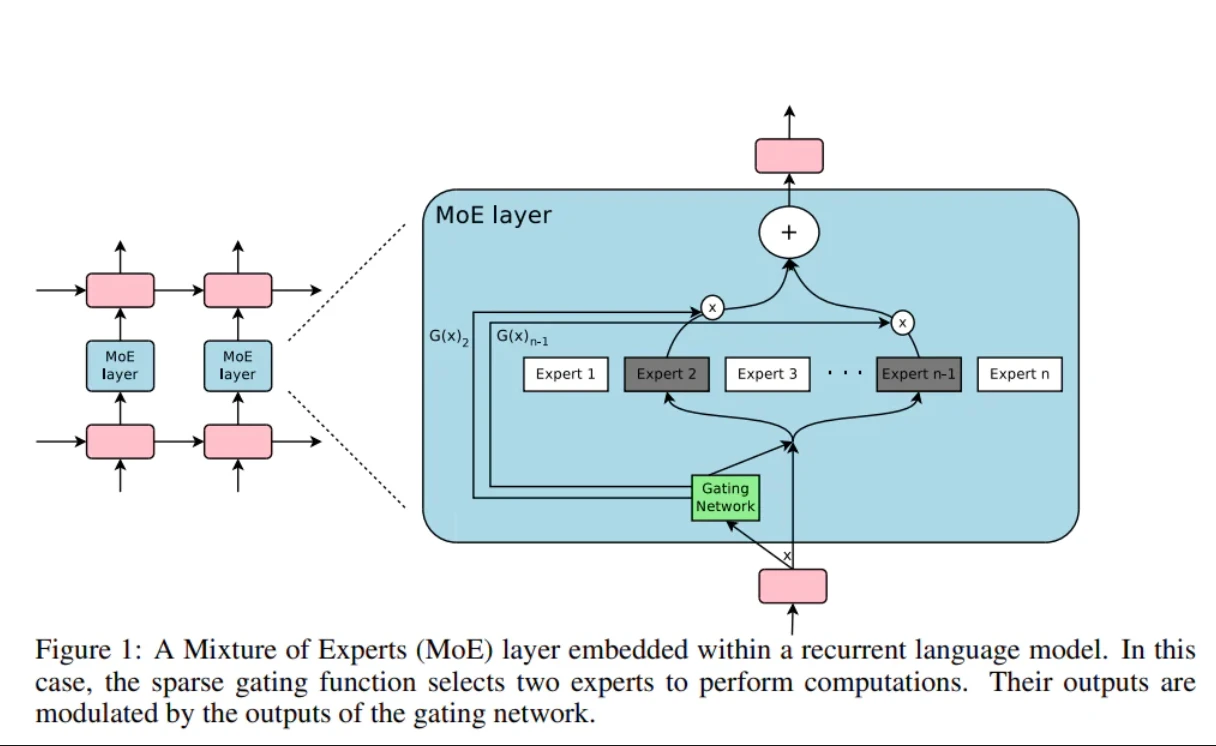
这为进一步研究提供了广阔的设计空间。也许中间层应该以不同的方式进行选择。
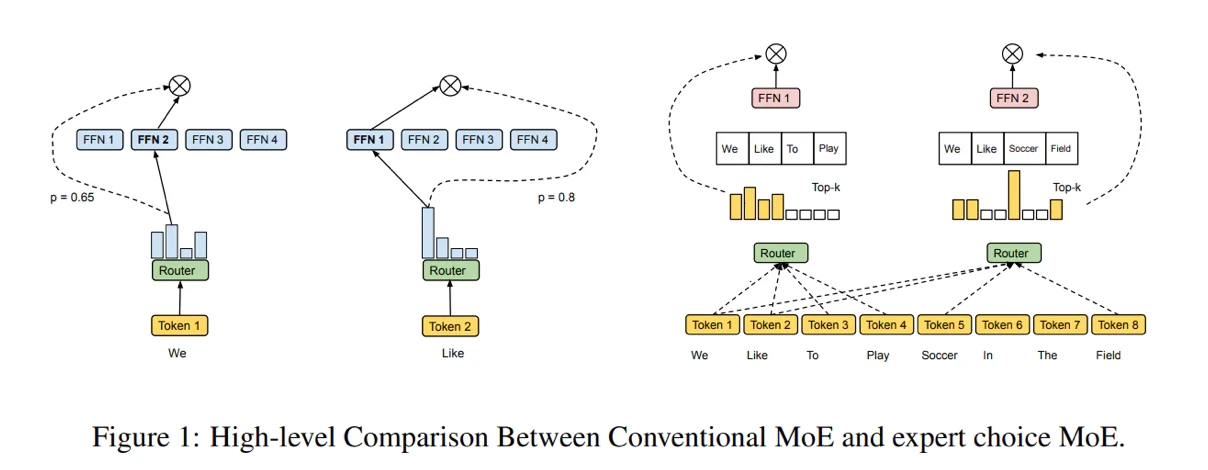
如,利用空间数据。
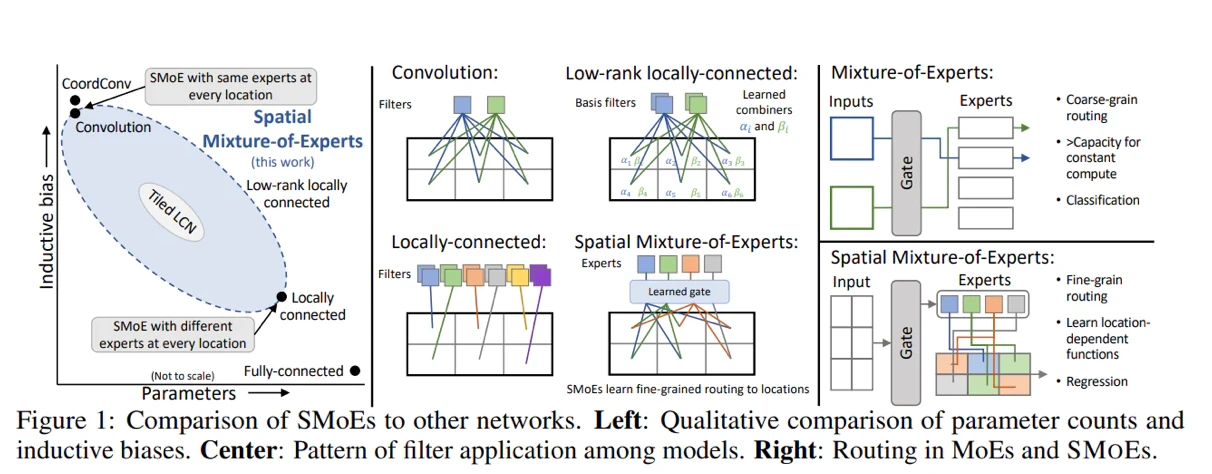
一项特别引人入胜的工作是 Nethack Learning Environment。就像 Twitch Plays Pokemon 是可行的,因为 JRPG 是回合制的,输入相对简单,NLE 也是回合制的,只需要键盘输入。此外,它在游戏的不同阶段的多个环境中具有程序生成,使其成为训练 AI 的极其有用的熔炉。根据我自己玩这个游戏的经验,你必须在回合制的基础上策划和组合许多策略。借助 polypiling 和 bones harvesting 等元博弈策略(作弊),AI 可以通过多种方式在逐场游戏的基础上进一步学习。
*拍击界面*“这个 Unicode 可以容纳这么多对象”
如 Tesla 和 Neuralink 最近开发的企业级机器学习。工业规模的生产需要工业规模的反馈增强强化学习。Optimus 可能是一个噱头,但它可能比 Atlas 在过去 9 年中对机器人的改进更多。Neuralink 植入物可能会杀死受试者,但它们会推动极其精确的手术机械和零件的发展。
制造业的反馈很好,但卫生部门的需求最大。现在,我们是零售生物传感器的早期采用者。随着时间的推移,同态密码学将使机器学习能够利用大量健康数据。数万年来,我们已经将药物消费众包,但我们如何与人工智能共存仍有待观察,人工智能可以在任意时间跨度内管理任意物质的剂量。与此同时,同态加密因效率问题仍然没有被使用。
Google Brain 刚刚发布了 Robotics Transformer-1 。在第一个版本中它可能只是一个执行简单任务的手臂,但显然有可能在常见的构建环境中使用更多的标记化操作进行迭代。由于全球经济以货运为中心,与目前全球约 6000 艘集装箱船相比,如果最终在这样的设施中建造 100 多艘“零排放”集装箱船,也属于正常。这也将是住房危机中一个巨大的潮流变化,分区条例允许它完全生效。
另外,不得不提阿尔伯塔计划, 12 个合理的 AGI 能力发展步骤。
“路线图”一词暗示绘制一条线性路径,即应按顺序采取和通过的一系列步骤。这并非完全错误,但它没有认识到研究的不确定性和机遇。我们在下面概述的步骤具有多重相互依赖性,而不是从头到尾的步骤。路线图建议一种自然的顺序,但在实践中通常会偏离这种顺序。可以通过进入或附加到任何步骤来进行有用的研究。举个例子,我们中的许多人最近在集成架构方面取得了有趣的进展,尽管这些进展只出现在排序的最后一步。
首先,让我们尝试全面了解路线图及其基本原理。共有十二个步骤,标题如下:
1. 表示 I:具有给定特征的持续监督学习。2. 表示 II:监督特征发现。3.预测一:连续广义价值函数(GVF)预测学习。4. 控制 I:持续的演员-评论家控制。5. 预测二:平均奖励 GVF 学习。6. 控制 II:持续控制问题。7. 计划 I:平均奖励的计划。8. 原型-AI I:具有连续函数逼近的基于模型的一步强化学习。9. 规划二:搜索控制与探索。10. 原型-AI II:STOMP 进程。11. 原型-AI III:Oak。12. 原型-IA:智能放大。
这些步骤从开发用于核心能力(用于表示、预测、规划和控制)的新型算法,发展到将这些算法组合起来,为持续的、基于模型的 AI 生成完整的原型系统。
简而言之,从 ANI 到 AGI 再到 ASI 的方法和技术的转折点将是不言自明的。

ChatGPT 的输出
“指数级进步”
上述阿尔伯塔计划是一种理想情况。人类已经很复杂,作为个体使用稀疏神经网络工具;作为团体,具有自组织的、社会学习和环境工程特性。在密码学和分布式(对抗性)计算的最新发展中,人类的自治程度仅可以维持图灵完备的全局状态(历史) 。还有一种被称为机械土耳其人的现象。关键是, AI 产品在任意时间跨度内的下降,都会有一个成熟的开发人员生态系统,可以通过协调执行超越现有的水平,并通过同期的 AI 工具和可验证的工作得到增强。
这促成了当前的思想实验:我们甚至需要在 The Singularity™ 之前实现每个预测的拐点吗?对于商业化模型训练中的每一项专有改进,都可能有一种可行的方法在公共领域实现。StableDiffusion 已经引发了围绕这一概念的对话。众包在过去十年中已经充分加速(正如 Twitch Plays Pokemon、社交网络和 DAO 所证明的那样),奇点已经是一个转移注意力的问题。正如以太坊扩展解决方案尝试使用像 zk-SNARKs 这样的密码学为了减少网络的基础设施需求,我们将尝试实施轻量级解决方案,以减少现有大型企业对 AI 进行暴力破解和货币化的需求。
事实上,反驳 OpenAI 模型最好方法之一是,金融市场和社交网络上类似的社会资本系统在某种程度上是可预测的行为。Twitter 汇总新闻是因为它的用户可以在全球范围内通过合法人物进行广播和放大。随着 COVID 封锁和央行货币政策等全球趋势,成长型股票可能会大幅上涨和下跌。不需要太多想象力就能在很短的时间内想象出一家初创公司,它可以将类似人工智能的 PMF 表现为一个自我调节、自我编排的社区。可能有数千亿美元的运营成本可以通过现有技术和进一步的业务发展在许多部门中释放出来。
在电视剧《西部世界》中,名为 Rehoboam 的人工智能系统通过分析大型数据集来操纵和预测未来,从而对人类事务施加秩序。自工业革命以来,颠覆性创新一再出现在官僚机构之外;今天,它们正在以越来越快的速度发生。近几十年来,公共领域的深度和范围不断扩大,许多技术无论其商业化程度如何都在被迫开源。





