




协处理器历史背景
在传统的计算机领域,协处理器是负责为 CPU 大脑处理其它繁杂的事情的处理单元。协处理在计算机领域非常常见,如苹果在 2013 年推出 M 7 运动协处理器,大幅度提升了智能设备的运动方面灵敏度。广为人知的 GPU 便是 Nvidia 在 2007 年提出的协处理器,其负责为 CPU 处理图形渲染等任务。GPU 通过卸载一些计算密集且耗时的代码部分来加速 CPU 上运行的应用程序,这种架构被称为“异构” / “混合”计算。
协处理器能够卸载一些复杂且单一性能要求或者性能要求极高的代码,让 CPU 去处理更加灵活多变的部分。
在以太坊链上,有两个严重阻碍应用发展的问题:
由于操作需要高昂的 Gas Fee,一笔普通的转账硬编码为 21000 Gas Limit,这个就展现以太坊网络的 Gas Fee 底线,其它操作包括存储就会花费更多的 Gas,进而就会限制链上应用的开发范围,大多数的合约代码仅仅是围绕资产操作而编写,一旦涉及到复杂的操作就会需要大量 Gas,这对于应用和用户的“Mass Adoption”是严重阻碍。
由于智能合约存在于虚拟机中,智能合约实际上只能访问近期的 256 个区块的数据,特别是在明年的 Pectra 升级,引入的 EIP-4444 提案,全节点将不会再存储过去的区块数据,那么数据的缺失,导致了基于数据的创新应用迟迟无法出现,毕竟类似于 Tiktok、Instagram、多数据的 Defi 应用、LLM 等都是基于数据来进行构建,这也是为什么 Lens 这种基于数据的社交协议要推出 Layer 3 Momoka 的原因,因为我们认为的区块链是数据流向非常顺畅的毕竟链上都是公开透明的,但是实际不然,仅仅是代币资产数据流通顺畅,但是数据资产由于底层设施的不完善仍然阻碍很大,这也会严重限制“Mass Adoption”产品的出现。
我们通过这一事实,发现其计算和数据都是限制新的计算范式“Mass Adoption”出现的原因。然而这个是以太坊区块链本身的弊病,并且其在设计时本就不是为了处理大量计算以及数据密集型任务而设计的。但是想要兼容这些计算与数据密集型的应用该如何实现?这里就需要引出协处理器,以太坊链本身作为 CPU,协处理器就类似于 GPU,链本身能处理一些非计算、数据密集型的资产数据和简单操作,而应用想要灵活使用数据或者计算资源可以使用协处理器。伴随着 ZK 技术的探索,为了保证协处理器在链下进行计算和数据使用的无需信任,因此自然而然,协处理器大多都在以 ZK 为底层进行研发。
对于 ZK Coporcessor,其应用边界之广,任何真实的 dapp 应用场景均能覆盖,如社交、游戏、Defi 积木、基于链上数据的风控系统、Oracle、数据存储、大模型语言训练推理等等,从理论上来说,任何Web2的应用能做到的事情,有了 ZK 协处理器就都能实现,并且还有以太坊来作为最终结算层保护应用安全性。
在传统的世界中,协处理器也没有一个明确的定义,只要能作为辅助协助完成任务的单独芯片都叫协处理器。当前业内对 ZK 协处理器的定义并不完全相同,如 ZK-Query、ZK-Oracle、ZKM 等都是协处理器,能够协助查询链上完整数据、链下的可信数据以及链下计算结果,从这个定义来看,实际上 layer 2 也算是以太坊的协处理器,我们也会在下文中对比 Layer 2 与通用 ZK 协处理器的异同。
协处理器项目一览
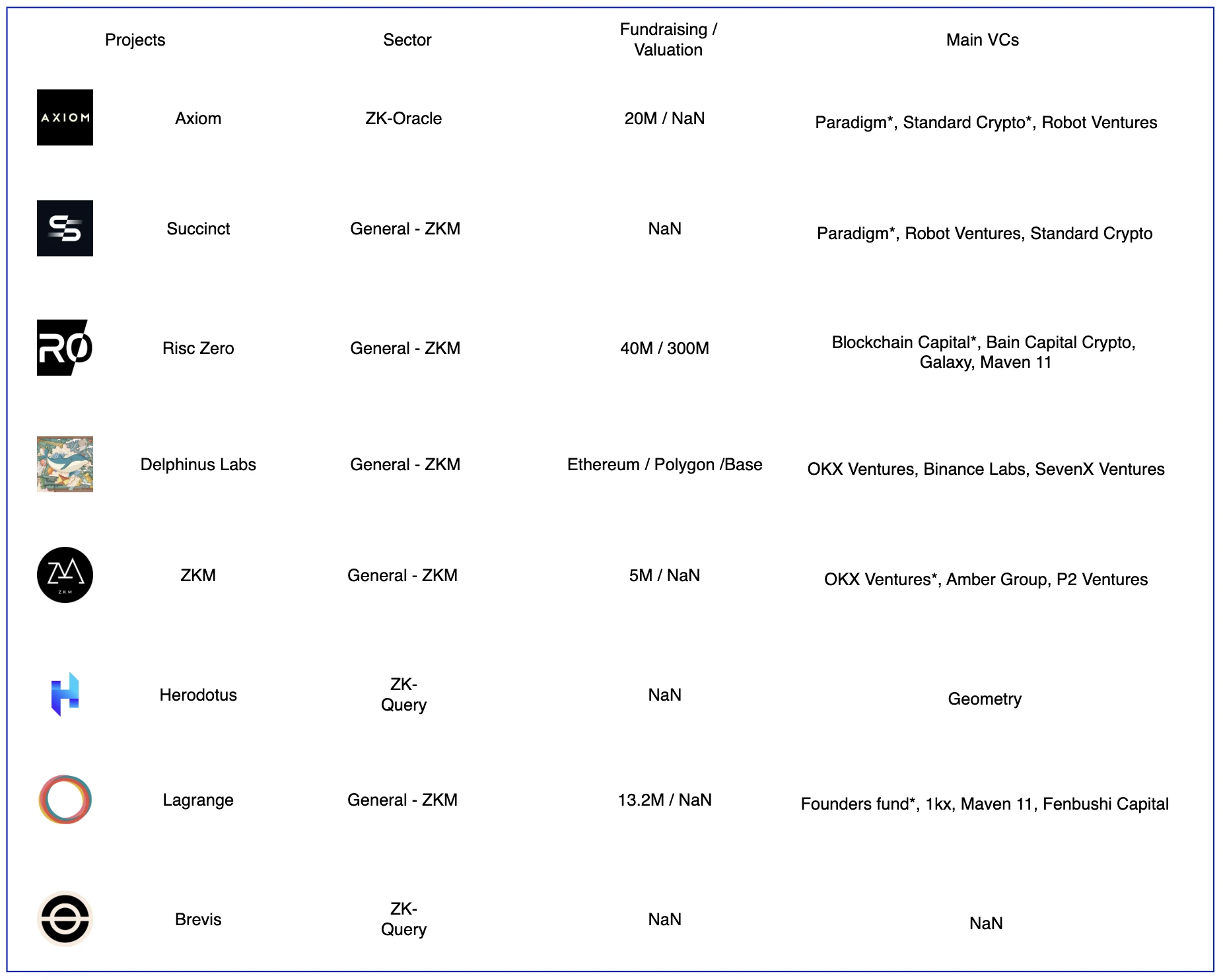
ZK 协处理器部分项目,图源:Gate Ventures
目前业内比较知名的协处理分成三大部分,分别是链上数据索引、预言机、ZKML 这三大应用场景,而三种场景都包含的项目为 General-ZKM,在链下运行的虚拟机又各有不同,如 Delphinus 专注于 zkWASM,而 Risc Zero 专注于 Risc-V 架构。
协处理器技术架构
我们以 General ZK 协处理器为例,进行其架构的分析,来让读者明白,该通用型的虚拟机在技术以及机制设计上的异同,来判断未来协处理器的发展趋势,其中主要围绕 Risc Zero、Lagrange、Succinct 三个项目进行分析。
Risc Zero
在 Risc Zero 中,其 ZK 协处理器名为 Bonsai。
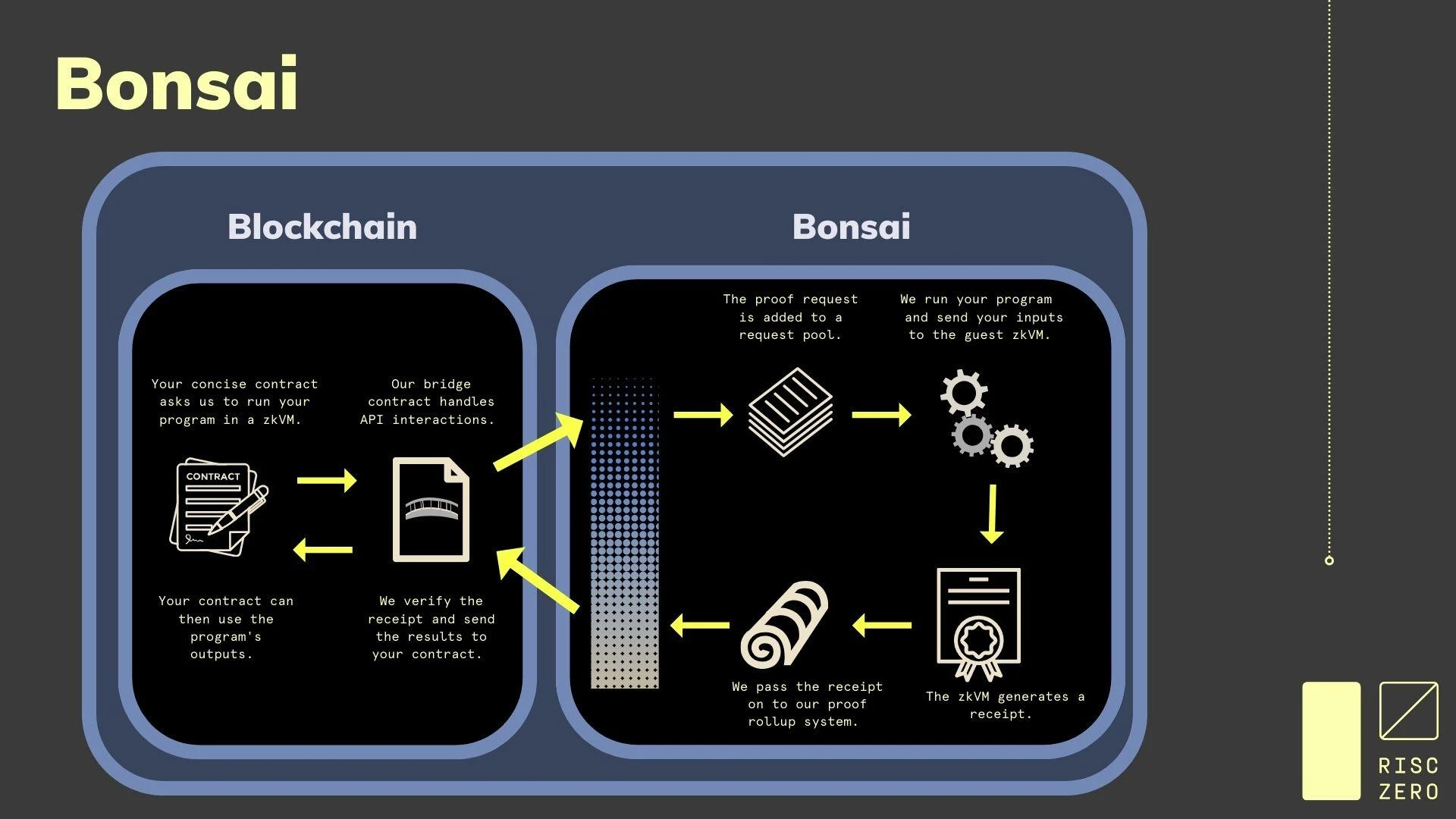
Bonsai 架构,图源:Risc Zero
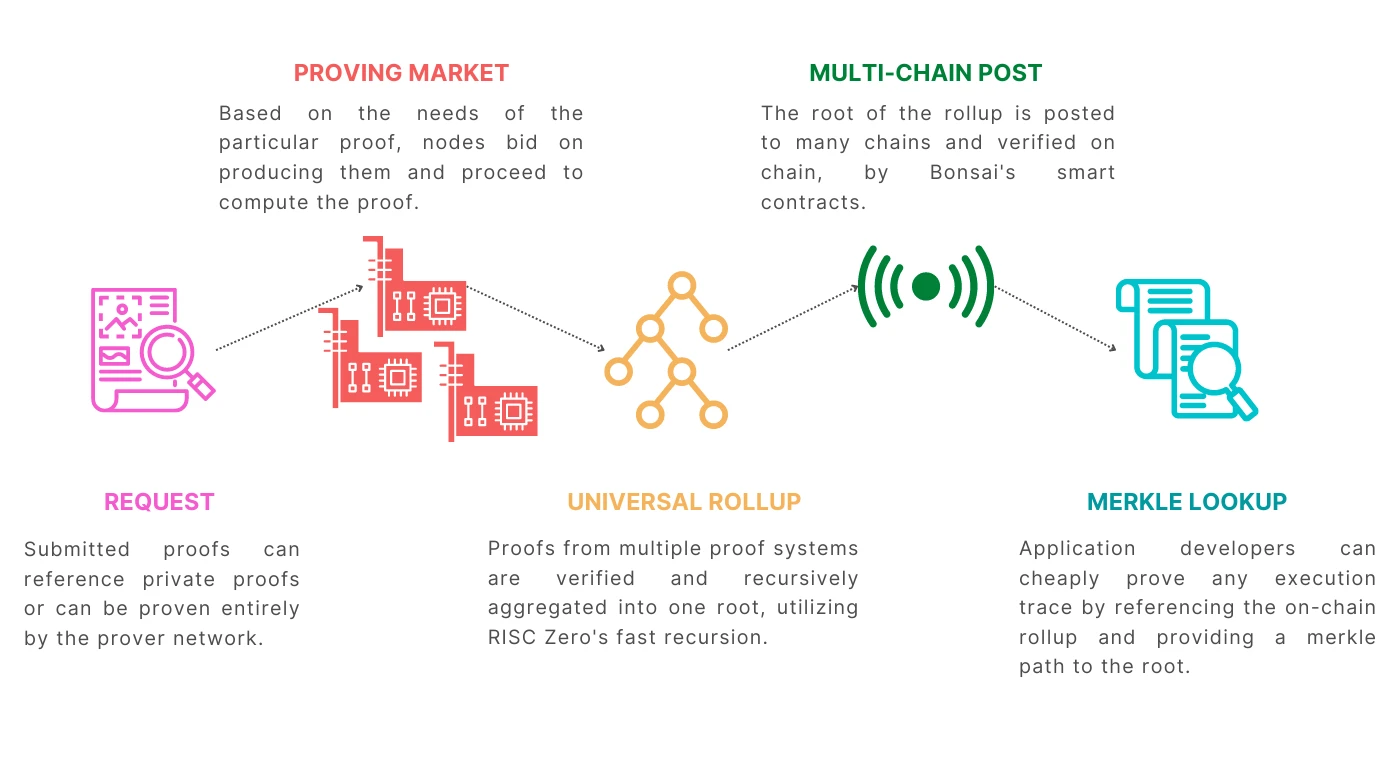
Bonsai 组件,图源:Risc Zero
在 Bonsai 中,构建了一整套的与链无关的零知识证明的组件,其目标是成为一个与链无关的协处理器,基于 Risc-V 指令集架构,具备极大的通用性,支持的语言包括 Rust、C++、Solidity、Go 等。其主要的功能包括:
通用 zkVM,能够在零知识/可验证环境中运行任何虚拟机。
可直接集成到任何智能合约或链中的 ZK 证明生成系统
一个通用的 rollup,将 Bonsai 上证明的任何计算分发到链上,让网络矿工进行证明生成。
其组件包括:
证明者网络:通过 Bonsai API,证明者在网络中接受到需要验证的 ZK 代码,然后运行证明算法,生成 ZK 证明,这个网络未来会开放给所有人。
Request Pool:这个池是存储用户发起的证明请求的(类似于以太坊的 mempool,用于暂存交易),然后这个 Request Pool 会经过 Sequencer 的排序,生成区块,其中的许多证明请求会被拆分以提高证明效率。
Rollup 引擎:这个引擎会收集证明者网络里收集到的证明结果,然后打包成 Root Proof,上传到以太坊主网,以让链上的验证者随时验证。
Image Hub:这个是一个可视化的开发者平台,在这个平台中可以存储函数以及完整的应用程序,因此开发者可以通过智能合约调用对应的 API,因此链上智能合约就具备了调用链下程序的能力。
State Store:Bonsai 还引入了链下的状态存储,在数据库中以键值对的形式存储,这样就能够减少链上的存储费用,并且与 ImageHub 平台配合,能减少智能合约的复杂性。
Proving Marketplace: ZK 证明产业链的中上游,算力市场用于匹配算力的供需双方。
Lagrange
Lagrange 的目标是构建一个协处理器和可验证的数据库,其中包括了区块链上的历史数据,可以顺畅的使用这些数据来进行无需信任的应用搭建。这就能满足计算和数据密集型应用的开发。
这涉及到两个功能:
可验证数据库:通过索引链上智能合约的 Storage,将智能合约产生链上状态放入数据库中。本质上就是重新构建区块链的存储、状态和区块,然后以一种更新的方式存储在便于检索的链下数据库中。
MapReduce 原则的计算:MapReduce 原则就是在大型数据库上,采用数据分离多实例并行计算,最后将结果整合在一起。而这种支持并行执行的架构被 Lagrange 称为 zkMR。
在数据库的设计中,其一共涉及到链上数据的三部分,分别为合约存储的数据、EOA 状态数据以及区块数据。
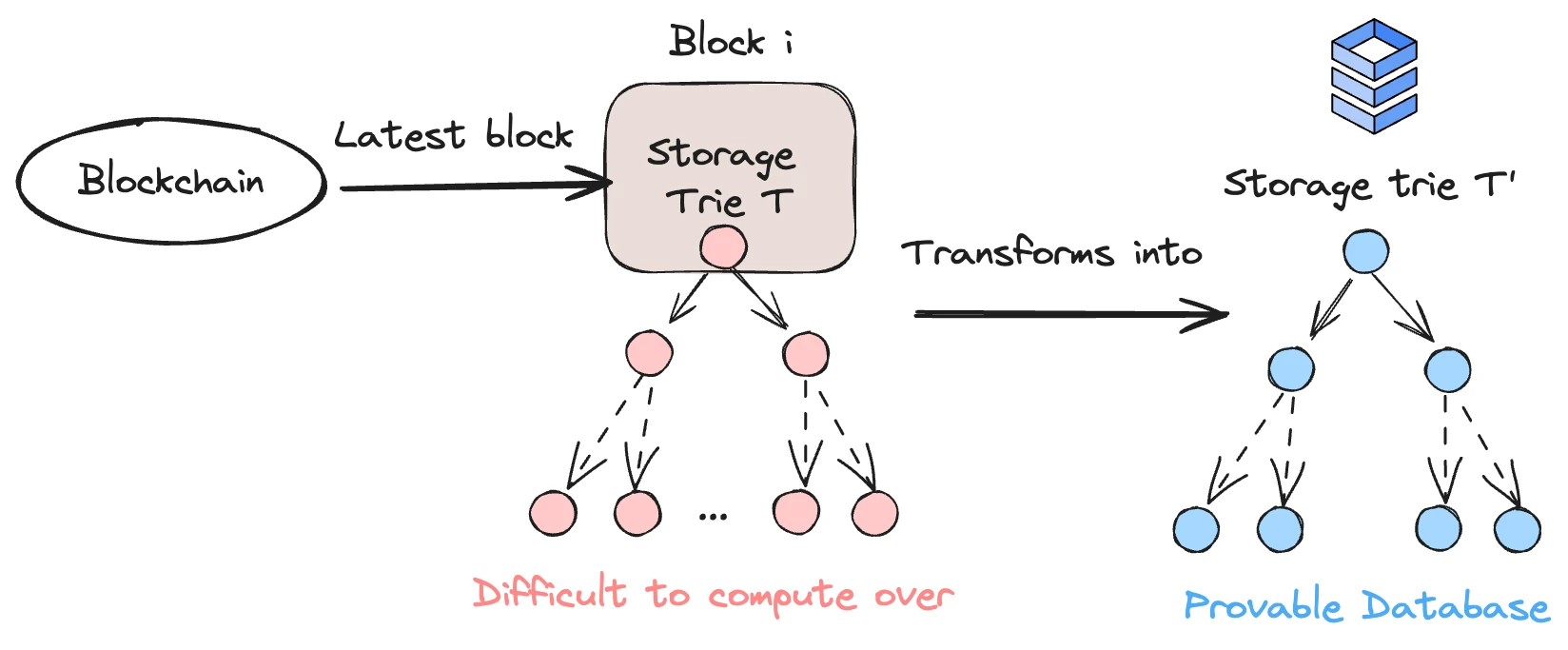
Lagrange 数据库结构,图源:Lagrange
以上是其合约存储的数据的映射结构,在这里存储了合约的状态变量,并且每个合约都有一个独立的 Storage Trie,这个 Trie 在以太坊内是以 MPT 树的形式存储。MPT 树虽然简单,但是其效率很低,这也是为什么以太坊核心开发者推动 Verkel 树开发的原因。在 Lagrange 内,每个节点都能使用 SNARK/STARK 进行“证明”,而父节点又包含了子节点的证明,这其中需要使用递归证明的技术。
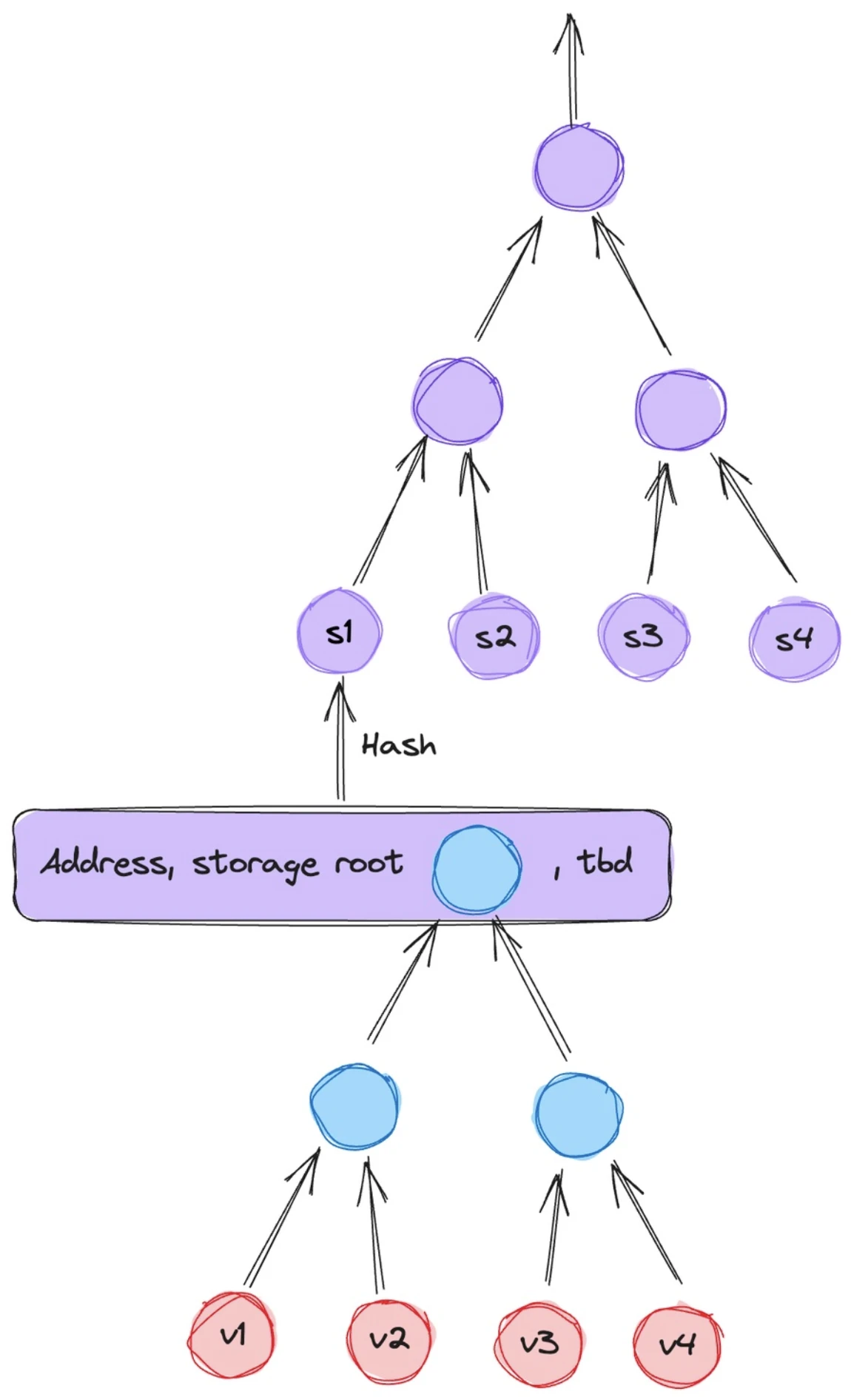
账户状态,图源:Lagrange
账户分别为 EOA 和合约账户,都可以以账户 / Storage Root(合约变量的存储空间)的形式存储来代表账户状态,但是似乎 Lagrange 并没有完全设计好这一部分,实际上还需要加上 State Trie(外部账户的状态存储空间)的根。
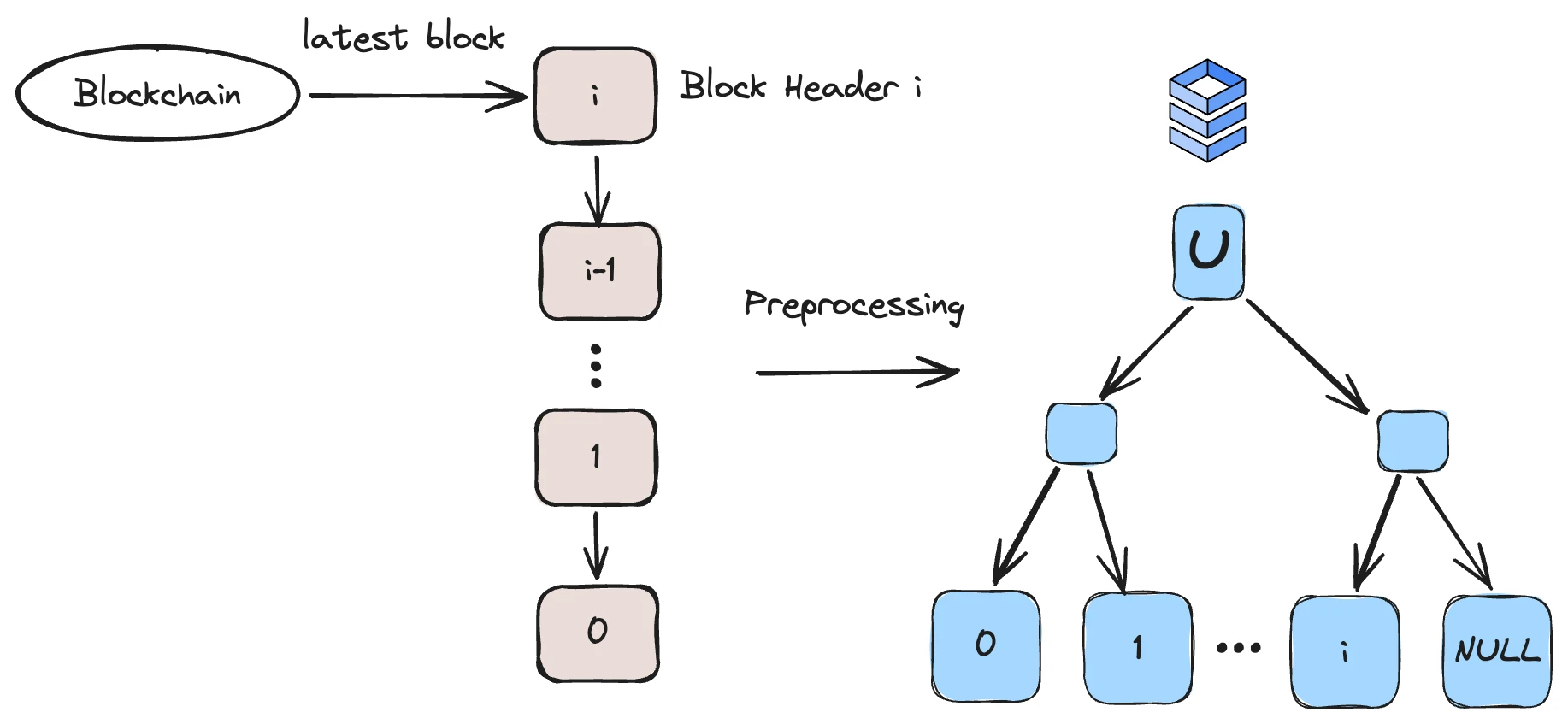
区块数据结构,图源:Lagrange
Lagrange 在新的数据结构中,创建了对于 SNARKs 证明友好的区块数据结构,这颗树的每个叶子都是一个区块头,这个数的大小是固定的,如果以太坊 12 秒出块一次,那么这个数据库大约可以使用 25 年。
在 Lagrange 的 ZKMR 虚拟机中,其计算有两个步骤:
Map:分布式的机器对一整个数据进行映射,生成键值对。
Reduce:分布式计算机分别计算证明,之后将证明全部合并。
简而言之,ZKMR 可以将较小计算的证明组合起来以创建整个计算的证明。这使得 ZKMR 能够有效地扩展,以在需要多个步骤或多层计算的大型数据集上进行复杂的计算证明。比如,如果 Uniswap 在 100 条链上部署,那么如果想要计算 100 条链上的某个代币的 TWAP 价格,就需要大量的计算以及整合,这个时候 ZKMR 就能够分别计算每条链,然后组合起来一个完整计算证明。
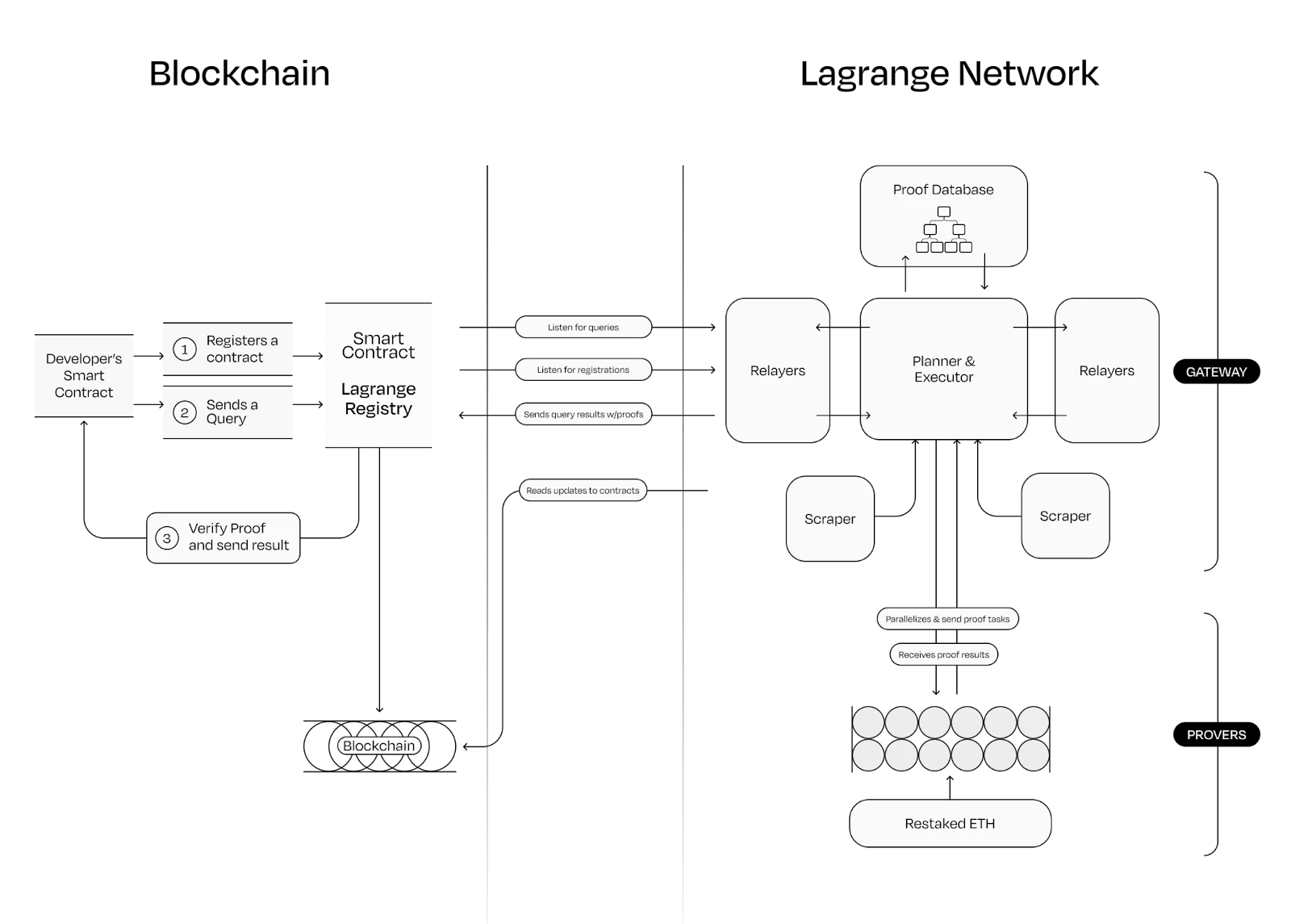
Lagrange 协处理器运行流程,图源:Lagrange
以上是其执行流程:
开发者的智能合约,首先在 Lagrange 上注册,然后向 Lagrange 的链上智能合约提交一个证明请求,这时,代理合约负责与开发者合约交互。
链下的 Lagrange 通过将请求分解为可并行的小任务并分发给不同的证明器来共同验证。
该证明器实际上也是一个网络,其网络的安全性由 EigenLayer 的 Restaking 技术保障。
Succinct
Succinct Network 的目标是将可编程事实集成到区块链开发 Stack 的每个部分(包括 L2、协处理器、跨链桥等)。
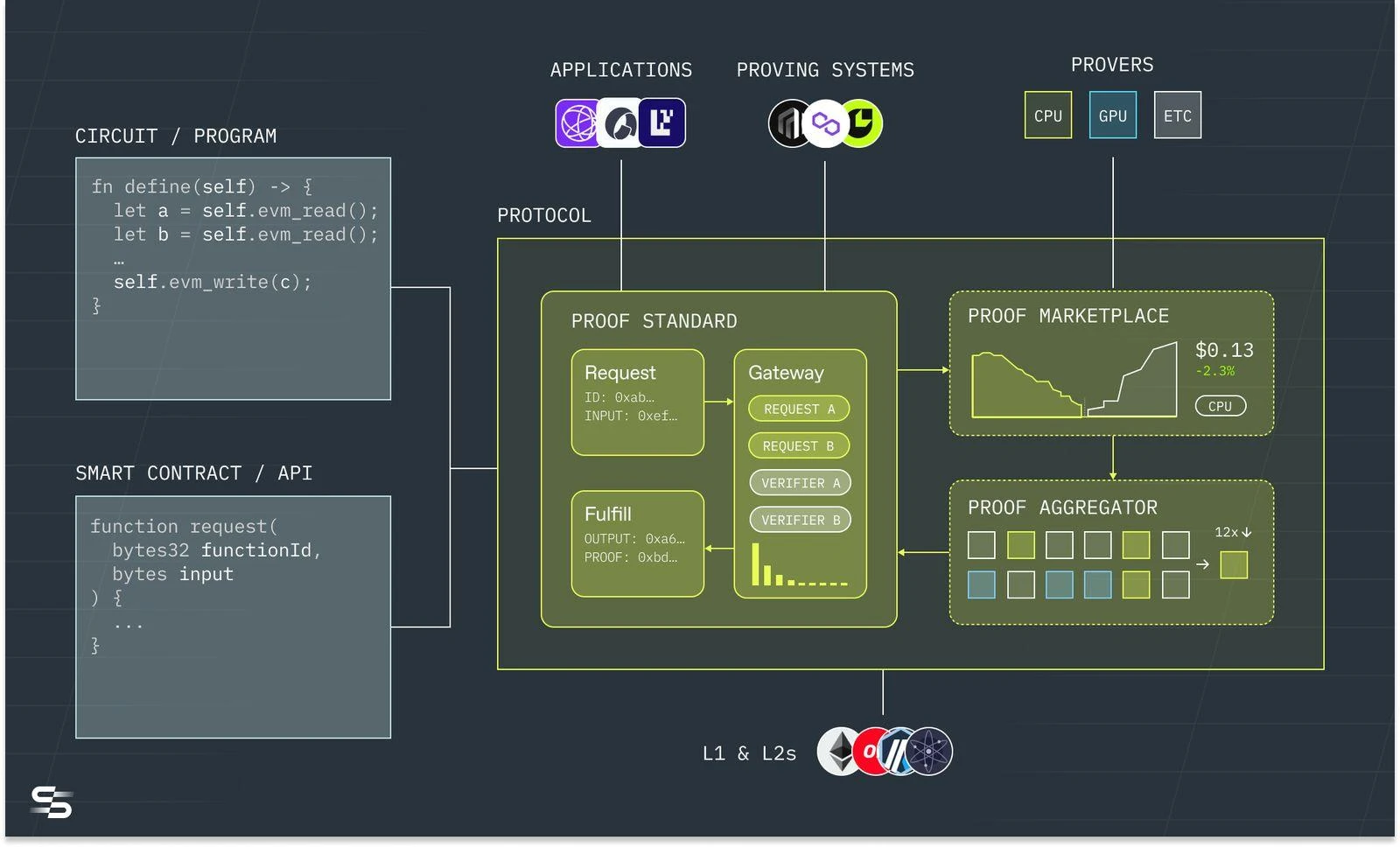
Succinct 运作流程,图源:Succinct
Succinct 可以接受包括 Solidity 和零知识领域的专门语言(DSL)等代码,传入到链下的 Succinct 协处理器,Succinct 完成目标链的数据索引,然后将证明申请发送给证明市场,能够支持 CPU、GPU 以及 ETC 等芯片的矿机在证明网络中提交证明。其特点在于证明市场对于各种证明系统都兼容,因为未来会有很长一段各种证明系统并存的时期。
Succinct 的链下 ZKVM 称为 SP(Succinct Processor),其能够支持 Rust 语言以及其它的 LLVM 语言,其核心特性包括:
递归+验证:基于 STARKs 技术的递归证明技术,能够指数级增强 ZK 压缩效率。
支持 SNARKs 到 STARKs 包装器:能够同时采纳 SNARKs 和 STARKs 优点,解决证明大小和验证时间的权衡问题。
预编译为中心的 zkVM 架构:对于一些常见的算法如 SHA 256、Keccak、ECDSA 等,能够提前编译以减少运行时的证明生成时间和验证时间。
比较
在进行通用 ZK 协处理器的比较时,我们主要以满足 Mass Adoption 第一性原理来进行比较,我们也会阐述为什么很重要:
数据索引/同步问题:只有完整的链上数据以及同步索引功能才能满足基于大数据的应用的要求,否则其应用范围较为单一。
基于技术:SNARKs 与 STARKs 技术有不同的抉择点,在中期内是以 SNARKs 技术为主,在长期以 STARKs 技术为主。
是否支持递归:只有支持递归才能更大程度的压缩数据以及实现计算的并行证明,因此实现完全的递归是项目的技术亮点。
证明系统:证明系统直接影响了证明生成的大小、时间,这个是 ZK 技术中成本最高的地方,目前都是以自建 ZK 云算力市场和证明网络为主。
生态合作:能够通过第三真实需求方来判断其技术方向是否被 B 端用户认可。
支持的 VC 以及融资情况:可能能够表示其后续的资源支持情况。
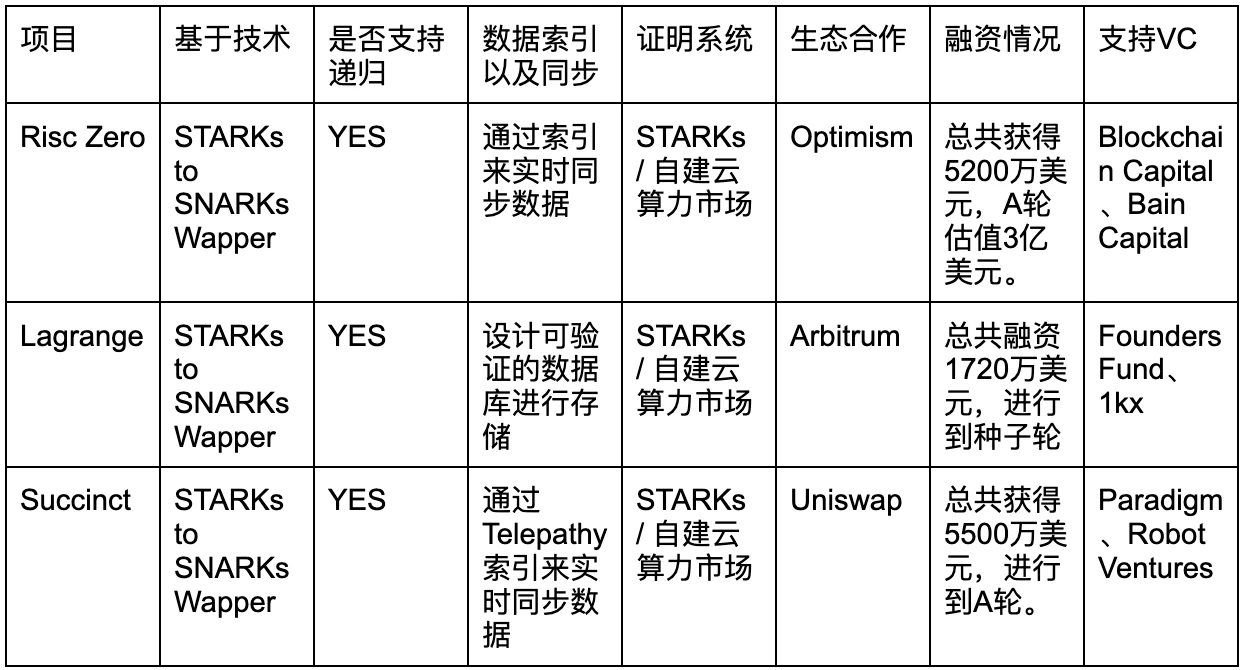
其实整体的技术路径已经很明晰,因此大多数的技术都趋同,比如都使用 STARKs 到 SNARKs 的包装器,能够同时使用 STARKs 和 SNARKs 的优点,降低证明生成时间和验证时间以及抗量子攻击。由于 ZK 算法的递归性能够很大程度影响 ZK 的性能,目前三个项目都有递归功能。ZK 算法的证明生成是成本和时间耗费最多的地方,因此三个项目的都依赖于本身对 ZK 算力的强需求构建了证明者网络和云算力市场。也鉴于此,目前技术路径非常相似的情况下,可能突围更需要团队以及背后的 VC 对于生态合作资源方面的协助以占据市场份额。
协处理器与 Layer 2 的异同
与 Layer 2 不同的是,协处理器是面向应用的,而 Layer 2 仍然是面向用户的。协处理器能作为一个加速组件或者模块化的组件,构成以下几种应用场景:
作为 ZK Layer 2 的链下虚拟机组件,这些 Layer 2 可以将自己的 VM 换成协处理器。
作为公链上应用卸载算力到链下的协处理器。
作为公链上应用获取其它链可验证数据的预言机。
作为两条链上的跨链桥进行消息的传递。
这些应用场景仅仅是罗列了一部分,对于协处理器,我们需要理解其带来了全链的实时同步数据与高性能低成本可信计算的潜力,能够通过协处理器安全地重构几乎区块链的所有中间件。包括 Chainlink、The Graph 目前也在开发其自己的 ZK 预言机和查询;而主流的跨链桥如 Wormhole、Layerzero 等也在研发基于 ZK 的跨链桥技术;链下的 LLMs(大模型预言)的训练以及可信推理、等等。
协处理器面临的问题
开发者进入有阻力,ZK 技术从理论上可行,但是目前技术难点仍然有很多,外部理解也晦涩难懂,因此当新的开发者进入到生态中时,由于需要掌握特定的语言与开发者工具,可能是一个较大的阻力。
赛道处于极早期,zkVM 性能非常复杂且涉及多个维度(包括硬件、单节点与多节点性能、内存使用、递归成本、哈希函数选择等因素),目前各个纬度都有在构建的项目,赛道处于非常早期,格局还不明朗。
硬件等先决条件仍然未落地,从硬件来看,目前主流的硬件是 ASIC 以及 FPGA 方式构建,厂商包括 Ingonyama、Cysic 等,也仍然处于实验室阶段,仍未商业化落地,我们认为硬件是 ZK 技术大规模落地前提。
技术路径相似,很难有技术上的隔代领先,目前主要比拼背后的 VC 资源以及团队 BD 能力,是否能拿下主流应用和公链的生态位。
总结与展望
ZK 技术具备极大通用性,也帮助以太坊生态从去中心化的价值取向走向了去信任化的价值观。“ Don’t Trust, Verify it“,这句话便是 ZK 技术的最佳实践。ZK 技术能够重构跨链桥、预言机、链上查询、链下计算、虚拟机等等一系列应用场景,而通用型的 ZK Coprocessor 就是实现 ZK 技术落地的工具之一。对于 ZK Coporcessor,其应用边界之广,任何真实的 dapp 应用场景均能覆盖,从理论上来说,任何Web2的应用能做到的事情,有了 ZK 协处理器就都能实现。
技术普及曲线,图源:Gartner
自古以来,技术的发展都落后于人类对美好生活的想象(比如嫦娥奔月到阿波罗踏上月球),如果一个东西确实有创新性和颠覆性以及必要性,那么技术一定会实现,只是时间问题。我们认为通用 ZK 协处理器遵循这一发展趋势。我们对于 ZK 协处理器“Mass Adoption”有两个指标:全链的实时可证明数据库以及低成本链下计算。如果数据量足够并且实时同步加上低成本的链下可验证计算,那么软件的开发范式便能够彻底改变,但是这一目标是缓慢迭代的,因此我们着重去寻找符合这两点趋势或者价值取向的项目,并且 ZK 算力芯片的落地是 ZK 协处理器大规模商业化应用的前提,本轮周期缺乏创新,是真正构建下一代“Mass Adoption”技术和应用的窗口期,我们预计在下一轮周期中,ZK 产业链能够商业化落地,因此现在正是将目光重新放在一些真正能让Web3承载 10 亿人链上交互的技术上面。
免责声明:
以上内容仅供参考,不应被视为任何建议。在进行投资前,请务必寻求专业建议。
关于 Gate Ventures
Gate Ventures 是 Gate.io 旗下的风险投资部门,专注于对去中心化基础设施、生态系统和应用程序的投资,这些技术将在 Web 3.0 时代重塑世界。Gate Ventures 与全球行业领袖合作,赋能那些拥有创新思维和能力的团队和初创公司,重新定义社会和金融的交互模式。
Twitter:https://x.com/gate_ventures





