





giới thiệu
Sự phát triển gần đây của ngành AI được một số người coi là cuộc cách mạng công nghiệp lần thứ tư. Sự xuất hiện của các mô hình lớn đã cải thiện đáng kể hiệu quả của mọi tầng lớp trong xã hội. Boston Consulting Group tin rằng GPT đã cải thiện hiệu quả công việc ở Hoa Kỳ. khoảng 20%. Đồng thời, khả năng khái quát hóa do các mô hình lớn mang lại đã được ca ngợi là một mô hình thiết kế phần mềm mới. Trước đây, thiết kế phần mềm thiên về các mã chính xác, nhưng giờ đây thiết kế phần mềm thiên về các khung mô hình lớn tổng quát hơn được nhúng trong phần mềm. có thể đại diện tốt hơn và hỗ trợ nhiều loại đầu vào và đầu ra phương thức hơn. Công nghệ deep learning quả thực đã mang lại sự bùng nổ lần thứ tư cho ngành AI và xu hướng này cũng đã lan rộng sang ngành Crypto.
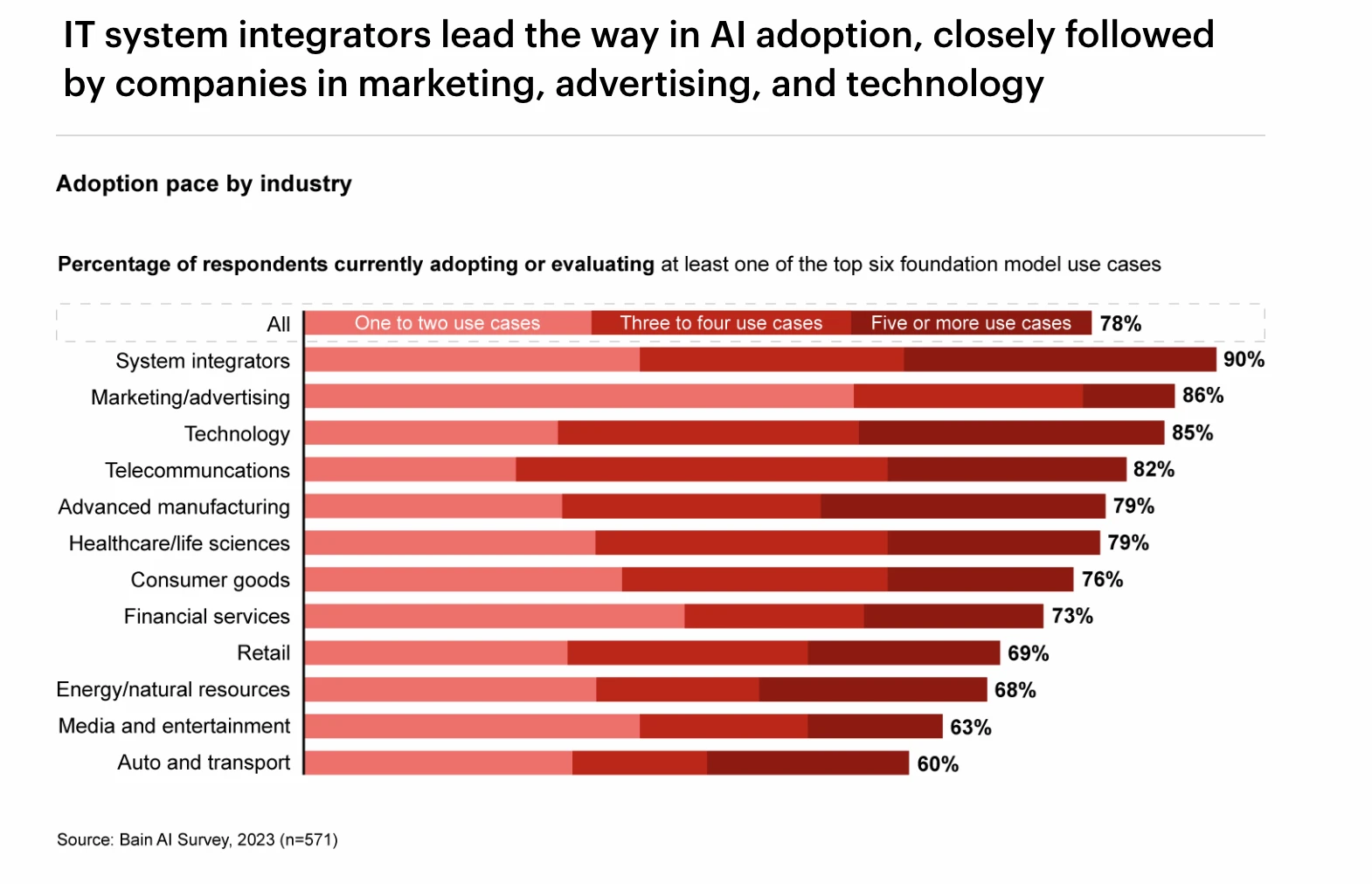
Xếp hạng tỷ lệ áp dụng GPT trong các ngành khác nhau, Nguồn: Khảo sát AI của Bain
Trong báo cáo này, chúng ta sẽ tìm hiểu chi tiết về lịch sử phát triển của ngành AI, phân loại công nghệ và tác động của việc phát minh ra công nghệ deep learning đối với ngành. Sau đó, chúng tôi phân tích sâu về thượng nguồn và hạ nguồn của chuỗi ngành như GPU, điện toán đám mây, nguồn dữ liệu và thiết bị biên trong học sâu, cũng như trạng thái và xu hướng phát triển của chúng. Sau đó, về cơ bản, chúng tôi đã thảo luận chi tiết về mối quan hệ giữa Tiền điện tử và ngành AI và sắp xếp mô hình của chuỗi ngành AI liên quan đến Tiền điện tử.
Lịch sử phát triển của ngành AI
Ngành công nghiệp AI bắt đầu từ những năm 1950. Để hiện thực hóa tầm nhìn về trí tuệ nhân tạo, giới học thuật và ngành công nghiệp đã phát triển nhiều trường phái tư tưởng nhằm hiện thực hóa trí tuệ nhân tạo ở các thời đại khác nhau và với các nền tảng kỷ luật khác nhau.
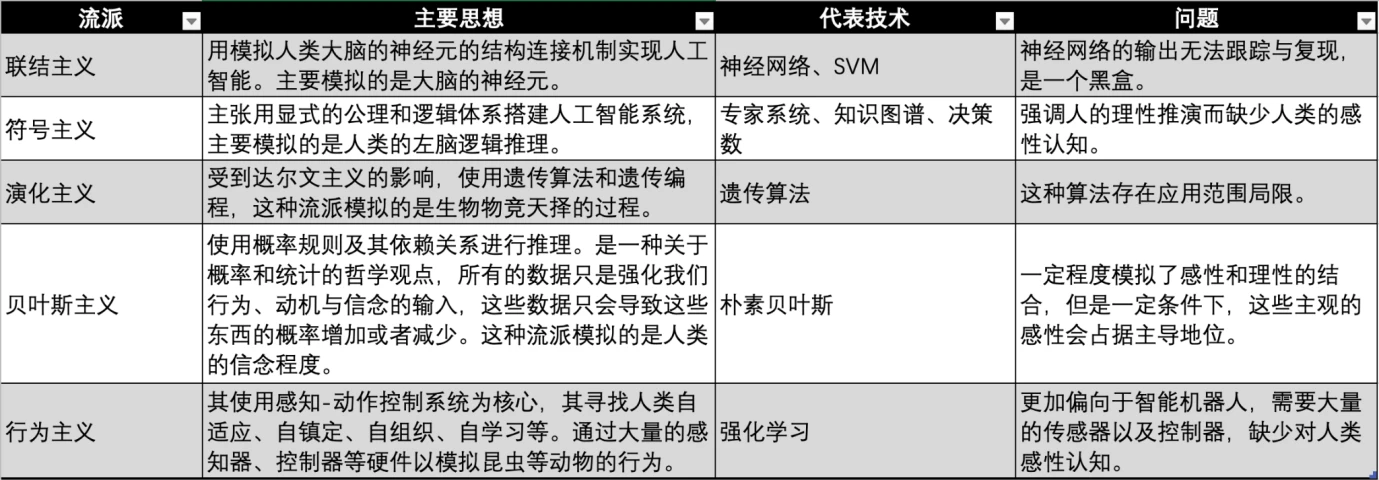
So sánh các thể loại AI, nguồn: Gate Ventures
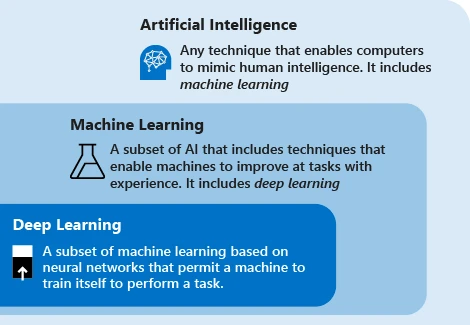
Mối quan hệ AI/ML/DL, nguồn: Microsoft
Công nghệ trí tuệ nhân tạo hiện đại chủ yếu sử dụng thuật ngữ máy học. Ý tưởng của công nghệ này là để máy dựa vào dữ liệu để lặp qua các tác vụ nhằm cải thiện hiệu suất của hệ thống. Các bước chính là cung cấp dữ liệu cho thuật toán, sử dụng dữ liệu này để huấn luyện mô hình, kiểm tra và triển khai mô hình cũng như sử dụng mô hình để hoàn thành các nhiệm vụ dự đoán tự động.
Hiện tại, có ba trường phái học máy chính là chủ nghĩa kết nối, chủ nghĩa biểu tượng và chủ nghĩa hành vi, lần lượt bắt chước hệ thống thần kinh, suy nghĩ và hành vi của con người.
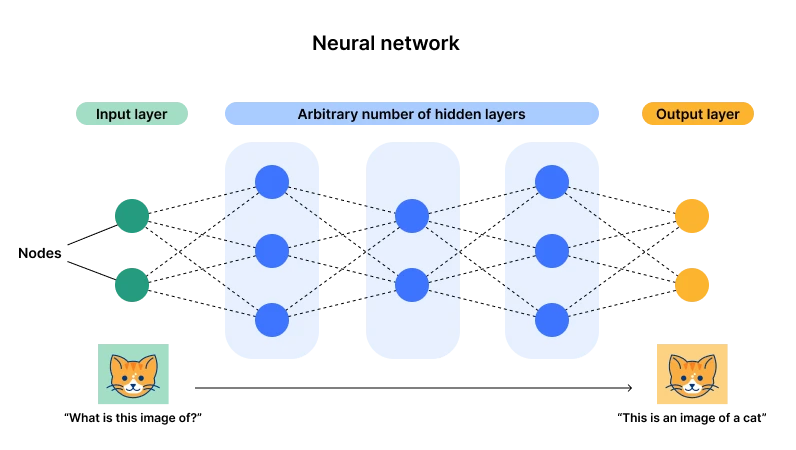
Sơ đồ kiến trúc mạng nơ-ron, nguồn: Cloudflare
Hiện tại, chủ nghĩa kết nối được biểu thị bằng mạng nơ-ron đang chiếm ưu thế (còn được gọi là học sâu). Lý do chính là kiến trúc này có một lớp đầu vào và một lớp đầu ra, nhưng lại có nhiều lớp ẩn và số lượng nơ-ron (. tham số) ) trở nên đủ lớn thì sẽ có đủ cơ hội để đáp ứng các nhiệm vụ có mục đích chung phức tạp. Thông qua dữ liệu đầu vào, các tham số của nơ-ron có thể được điều chỉnh liên tục. Sau đó, sau khi trải nghiệm nhiều dữ liệu, nơ-ron sẽ đạt đến trạng thái tối ưu (các tham số). từ độ sâu - đủ lớp và tế bào thần kinh.
Ví dụ, có thể hiểu đơn giản là một hàm được xây dựng. Khi ta nhập X= 2, Y= 3; khi X= 3, Y= 5. Nếu muốn hàm này xử lý tất cả X thì bạn cần tiếp tục cộng. Mức độ của hàm này và các tham số của nó. Ví dụ: tôi có thể xây dựng một hàm thỏa mãn điều kiện này là Y = 2 Một hàm của các điểm dữ liệu, sử dụng GPU để bẻ khóa vũ phu, nhận thấy rằng Y = Ở đây X 2 và X, X 0 đều đại diện cho các nơ-ron khác nhau và 1, -3, 5 là tham số của chúng.
Lúc này, nếu nhập một lượng lớn dữ liệu vào mạng nơ-ron, chúng ta có thể thêm nơ-ron và lặp lại các tham số để phù hợp với dữ liệu mới. Điều này sẽ phù hợp với tất cả các dữ liệu.
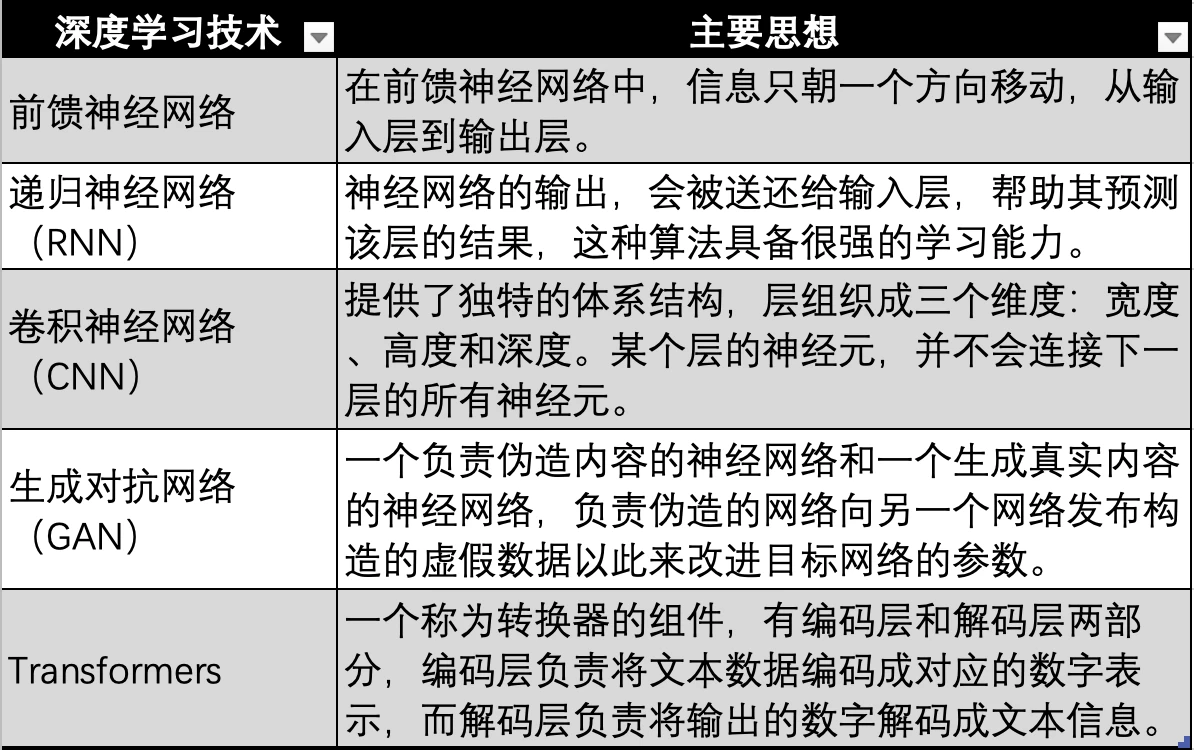
Sự phát triển của công nghệ deep learning, nguồn: Gate Ventures
Công nghệ học sâu dựa trên mạng nơ-ron cũng có nhiều lần lặp lại và phát triển kỹ thuật, chẳng hạn như mạng nơ-ron sớm nhất trong hình trên, mạng nơ-ron chuyển tiếp, RNN, CNN, GAN và cuối cùng là phát triển thành công nghệ Transformer được sử dụng bởi các mô hình lớn hiện đại như GPT., Công nghệ Transformer chỉ là một hướng phát triển của mạng nơ-ron. Nó bổ sung thêm một bộ chuyển đổi (Transformer), được sử dụng để mã hóa dữ liệu ở tất cả các phương thức (như âm thanh, video, hình ảnh, v.v.) thành các giá trị số tương ứng. Sau đó, nó được đưa vào mạng nơ-ron để mạng nơ-ron có thể phù hợp với bất kỳ loại dữ liệu nào, nghĩa là đạt được đa phương thức.
Sự phát triển của AI đã trải qua ba làn sóng công nghệ. Làn sóng đầu tiên là vào những năm 1960, mười năm sau khi công nghệ AI được đề xuất. Làn sóng này được gây ra bởi sự phát triển của công nghệ biểu tượng, giải quyết được vấn đề xử lý ngôn ngữ tự nhiên nói chung và con người-máy móc. xử lý các câu hỏi đàm thoại. Đồng thời, hệ thống chuyên gia ra đời. Đây là hệ thống chuyên gia DENRAL được hoàn thiện bởi Đại học Stanford dưới sự giám sát của NASA. Hệ thống này có kiến thức hóa học rất vững chắc và đưa ra các câu hỏi để đưa ra câu trả lời giống như các chuyên gia hóa học này. Hệ thống này có thể được xem như là sự kết hợp giữa cơ sở kiến thức hóa học và hệ thống suy luận.
Sau hệ thống chuyên gia, nhà khoa học và triết gia người Mỹ gốc Israel Judea Pearl đã đề xuất mạng lưới Bayesian vào những năm 1990, còn được gọi là mạng lưới niềm tin. Đồng thời, Brooks đề xuất robot dựa trên hành vi, đánh dấu sự ra đời của chủ nghĩa hành vi.
Năm 1997, IBM Deep Blue Blue đã đánh bại nhà vô địch cờ vua Kasparov với tỷ số 3,5: 2,5. Chiến thắng này được coi là một cột mốc quan trọng của trí tuệ nhân tạo và công nghệ AI đã mở ra đỉnh cao phát triển thứ hai.
Làn sóng công nghệ AI thứ ba xảy ra vào năm 2006. Ba gã khổng lồ của lĩnh vực học sâu, Yann LeCun, Geoffrey Hinton và Yoshua Bengio, đã đề xuất khái niệm học sâu, một thuật toán sử dụng mạng lưới thần kinh nhân tạo làm khuôn khổ để tìm hiểu cách biểu diễn dữ liệu. Sau đó, các thuật toán deep learning dần dần phát triển, từ RNN và GAN đến Transformer và Stable Diffusion. Hai thuật toán này đã cùng nhau định hình nên làn sóng công nghệ thứ ba này và đây cũng là thời kỳ hoàng kim của chủ nghĩa kết nối.
Nhiều sự kiện mang tính bước ngoặt đã dần xuất hiện cùng với sự khám phá và phát triển của công nghệ deep learning, bao gồm:
● Năm 2011, Watson của IBM đã đánh bại con người và giành chức vô địch trong chương trình đố vui Jeopardy.
● Vào năm 2014, Goodfellow đã đề xuất GAN (Mạng đối thủ sáng tạo), học bằng cách cho phép hai mạng thần kinh cạnh tranh với nhau để tạo ra những bức ảnh trông như thật. Đồng thời, Goodfellow cũng viết cuốn sách “Deep Learning” có tên là Flower Book, là một trong những cuốn sách nhập môn quan trọng trong lĩnh vực deep learning.
● Vào năm 2015, Hinton và cộng sự đã đề xuất một thuật toán deep learning trên tạp chí Nature. Đề xuất về phương pháp deep learning này ngay lập tức gây ra phản ứng rất lớn trong giới học thuật và ngành công nghiệp.
● Vào năm 2015, OpenAI được thành lập và Musk, Chủ tịch YC Altman, nhà đầu tư thiên thần Peter Thiel và những người khác đã công bố khoản đầu tư chung trị giá 1 tỷ USD.
● Năm 2016, AlphaGo dựa trên công nghệ deep learning đã thi đấu với nhà vô địch thế giới cờ vây và kỳ thủ cờ vây 9 đẳng chuyên nghiệp Lee Sedol trong trận đấu cờ vây giữa người và máy và giành chiến thắng với tổng số điểm là 4:1.
● Năm 2017, Sophia, một robot hình người được phát triển bởi Hanson Robotics ở Hồng Kông, Trung Quốc, được mệnh danh là robot đầu tiên trong lịch sử có được quyền công dân hạng nhất. Nó có nét mặt phong phú và khả năng hiểu ngôn ngữ con người.
● Năm 2017, Google, nơi có nguồn nhân lực dồi dào và dự trữ kỹ thuật trong lĩnh vực trí tuệ nhân tạo, đã xuất bản bài báo “Sự chú ý là tất cả những gì bạn cần” và đề xuất thuật toán Transformer, và các mô hình ngôn ngữ quy mô lớn bắt đầu xuất hiện.
● Năm 2018, OpenAI đã phát hành GPT (Generative Pre-training Transformer) dựa trên thuật toán Transformer, một trong những mô hình ngôn ngữ lớn nhất vào thời điểm đó.
● Năm 2018, nhóm Google Deepmind đã phát hành AlphaGo dựa trên deep learning, có thể dự đoán cấu trúc của protein và được coi là dấu hiệu của sự tiến bộ vượt bậc trong lĩnh vực trí tuệ nhân tạo.
● Năm 2019, OpenAI đã phát hành GPT-2, một model có 1,5 tỷ thông số.
● Năm 2020, GPT-3 do OpenAI phát triển có 175 tỷ tham số, cao gấp 100 lần so với phiên bản GPT-2 trước đó. Mô hình sử dụng 570 GB văn bản để huấn luyện và có thể sử dụng trong nhiều NLP (xử lý ngôn ngữ tự nhiên) nhiệm vụ (trả lời câu hỏi, dịch thuật, viết bài) để đạt được hiệu suất cao nhất.
● Năm 2021, OpenAI phát hành GPT-4 Mô hình này có 1,76 nghìn tỷ thông số, gấp 10 lần so với GPT-3.
● Ứng dụng ChatGPT dựa trên mẫu GPT-4 được ra mắt vào tháng 1 năm 2023. Vào tháng 3, ChatGPT đạt 100 triệu người dùng, trở thành ứng dụng đạt 100 triệu người dùng nhanh nhất trong lịch sử.
● Vào năm 2024, OpenAI ra mắt GPT-4 omni.
Chuỗi ngành công nghiệp học tập sâu
Hiện nay, các ngôn ngữ mô hình lớn sử dụng phương pháp học sâu dựa trên mạng lưới thần kinh. Các mô hình lớn do GPT đứng đầu đã tạo ra một làn sóng sốt trí tuệ nhân tạo. Một số lượng lớn người chơi đã đổ vào đường đua này. Chúng tôi cũng nhận thấy rằng nhu cầu thị trường về dữ liệu và sức mạnh tính toán đã bùng nổ. chúng tôi chủ yếu khám phá chiều sâu của chuỗi thuật toán học tập công nghiệp, trong ngành AI bị chi phối bởi các thuật toán học sâu, các thành phần thượng nguồn và hạ nguồn của nó được cấu thành như thế nào cũng như tình trạng hiện tại, mối quan hệ cung cầu và sự phát triển trong tương lai của nó. thượng nguồn và hạ lưu.

Quy trình đào tạo GPT Nguồn: WaytoAI
Trước hết, chúng ta cần làm rõ rằng khi đào tạo LLM (mô hình lớn) dựa trên GPT dựa trên công nghệ Transformer, có ba bước.
Trước khi đào tạo, vì dựa trên Transformer nên trình chuyển đổi cần chuyển đổi dữ liệu nhập văn bản thành các giá trị số. Quá trình này được gọi là Mã thông báo, và sau đó các giá trị số này được gọi là Mã thông báo. Theo nguyên tắc chung, một từ hoặc ký tự tiếng Anh có thể được coi đại khái là một Mã thông báo, trong khi mỗi ký tự tiếng Trung có thể được coi đại khái là hai Mã thông báo. Đây cũng là đơn vị cơ bản được sử dụng để định giá GPT.
Bước đầu tiên là đào tạo trước. Bằng cách cung cấp cho lớp đầu vào đủ các cặp dữ liệu, tương tự như các ví dụ (X, Y) trong phần đầu tiên của báo cáo, chúng ta có thể tìm ra các tham số tối ưu của từng nơ-ron theo mô hình. Điều này đòi hỏi một lượng lớn dữ liệu và quá trình này. cũng tốn nhiều công sức nhất. Đây là một quá trình tính toán chuyên sâu vì cần phải lặp đi lặp lại các nơ-ron để thử các tham số khác nhau. Sau khi huấn luyện một loạt dữ liệu, cùng một loạt dữ liệu đó thường được sử dụng cho huấn luyện thứ cấp để lặp lại các tham số.
Bước thứ hai là tinh chỉnh. Tinh chỉnh là đưa ra một lô dữ liệu nhỏ hơn với chất lượng rất cao cho việc huấn luyện. Những thay đổi như vậy sẽ làm cho đầu ra của mô hình có chất lượng cao hơn, vì việc huấn luyện trước yêu cầu một lượng lớn dữ liệu nhưng nhiều dữ liệu có thể chứa lỗi. hoặc chất lượng thấp. Bước tinh chỉnh có thể nâng cao chất lượng của mô hình với dữ liệu tốt.
Bước thứ ba là tăng cường học tập. Đầu tiên, một mô hình hoàn toàn mới sẽ được xây dựng, mà chúng tôi gọi là mô hình khen thưởng. Mục đích của mô hình này rất đơn giản là sắp xếp kết quả đầu ra nên việc triển khai mô hình này sẽ tương đối đơn giản vì doanh nghiệp sẽ tương đối đơn giản. kịch bản tương đối thẳng đứng. Sau đó, mô hình này được sử dụng để xác định xem đầu ra của mô hình lớn của chúng tôi có chất lượng cao hay không, để có thể sử dụng mô hình phần thưởng để tự động lặp lại các tham số của mô hình lớn. (Nhưng đôi khi cũng cần có sự tham gia của con người để đánh giá chất lượng đầu ra của mô hình)
Tóm lại, trong quá trình đào tạo các mô hình lớn, việc đào tạo trước có yêu cầu rất cao về lượng dữ liệu và tiêu tốn nhiều sức mạnh tính toán GPU nhất, trong khi việc tinh chỉnh yêu cầu dữ liệu chất lượng cao hơn để cải thiện các thông số và tăng cường việc học tập. thông qua mô hình khen thưởng để tạo ra kết quả chất lượng cao hơn.
Trong quá trình huấn luyện, càng có nhiều tham số thì khả năng tổng quát hóa của nó càng cao. Ví dụ, trong ví dụ của chúng ta về hàm Y = aX + b, khi đó thực tế có hai nơ-ron X và X 0, do đó các tham số. Dù có thay đổi thế nào thì dữ liệu mà nó có thể phù hợp là vô cùng hạn chế, vì bản chất của nó vẫn là một đường thẳng. Nếu có nhiều nơ-ron hơn thì có thể lặp lại nhiều tham số hơn và có thể trang bị nhiều dữ liệu hơn. Đây là lý do tại sao các mô hình lớn hoạt động kỳ diệu, và đây cũng là lý do tại sao cái tên phổ biến là các mô hình lớn. Bản chất là Một lượng lớn các nơ-ron, các tham số. và dữ liệu đòi hỏi một lượng lớn sức mạnh tính toán.
Do đó, hiệu suất của các mô hình lớn chủ yếu được xác định bởi ba khía cạnh: số lượng tham số, số lượng và chất lượng dữ liệu và khả năng tính toán. Ba yếu tố này cùng ảnh hưởng đến chất lượng kết quả và khả năng khái quát hóa của các mô hình lớn. Chúng tôi giả sử rằng số lượng tham số là p và lượng dữ liệu là n (được tính dựa trên số lượng Token), sau đó chúng tôi có thể tính toán lượng tính toán cần thiết thông qua các quy tắc chung để có thể ước tính sức mạnh tính toán gần đúng chúng ta cần mua và thời gian đào tạo.
Sức mạnh tính toán thường dựa trên Flops là đơn vị cơ bản, đại diện cho phép toán dấu phẩy động. Phép toán dấu phẩy động là thuật ngữ chung để cộng, trừ, nhân và chia các giá trị không nguyên, chẳng hạn như 2,5+ 3,557 có nghĩa là dấu phẩy động. rằng nó có thể có dấu thập phân và FP 16 có nghĩa là nó hỗ trợ số thập phân. Nói chung, FP 32 là độ chính xác phổ biến hơn. Theo quy tắc ngón tay cái trong thực tế, việc đào tạo trước một mô hình lớn (thường là nhiều lần) cần khoảng 6 np Flops và 6 được gọi là hằng số ngành. Suy luận (Suy luận, là quá trình chúng ta nhập dữ liệu và chờ đầu ra của mô hình lớn) được chia thành hai phần, nhập n mã thông báo và xuất ra n mã thông báo, do đó cần có tổng cộng khoảng 2 np Flops.
Trong những ngày đầu, chip CPU được sử dụng để đào tạo nhằm hỗ trợ sức mạnh tính toán, nhưng sau này chúng bắt đầu dần được thay thế bằng GPU, chẳng hạn như chip A 100 và H 100 của Nvidia. Bởi vì CPU tồn tại như một máy tính đa năng, nhưng GPU có thể được sử dụng như một máy tính chuyên dụng, vượt xa CPU về hiệu quả tiêu thụ năng lượng. GPU chạy các phép tính dấu phẩy động chủ yếu thông qua một mô-đun có tên Tensor Core. Vì vậy, các chip thông thường có dữ liệu Flops ở độ chính xác FP 16/FP 32, thể hiện sức mạnh tính toán chính của nó và cũng là một trong những chỉ số đo lường chính của chip.
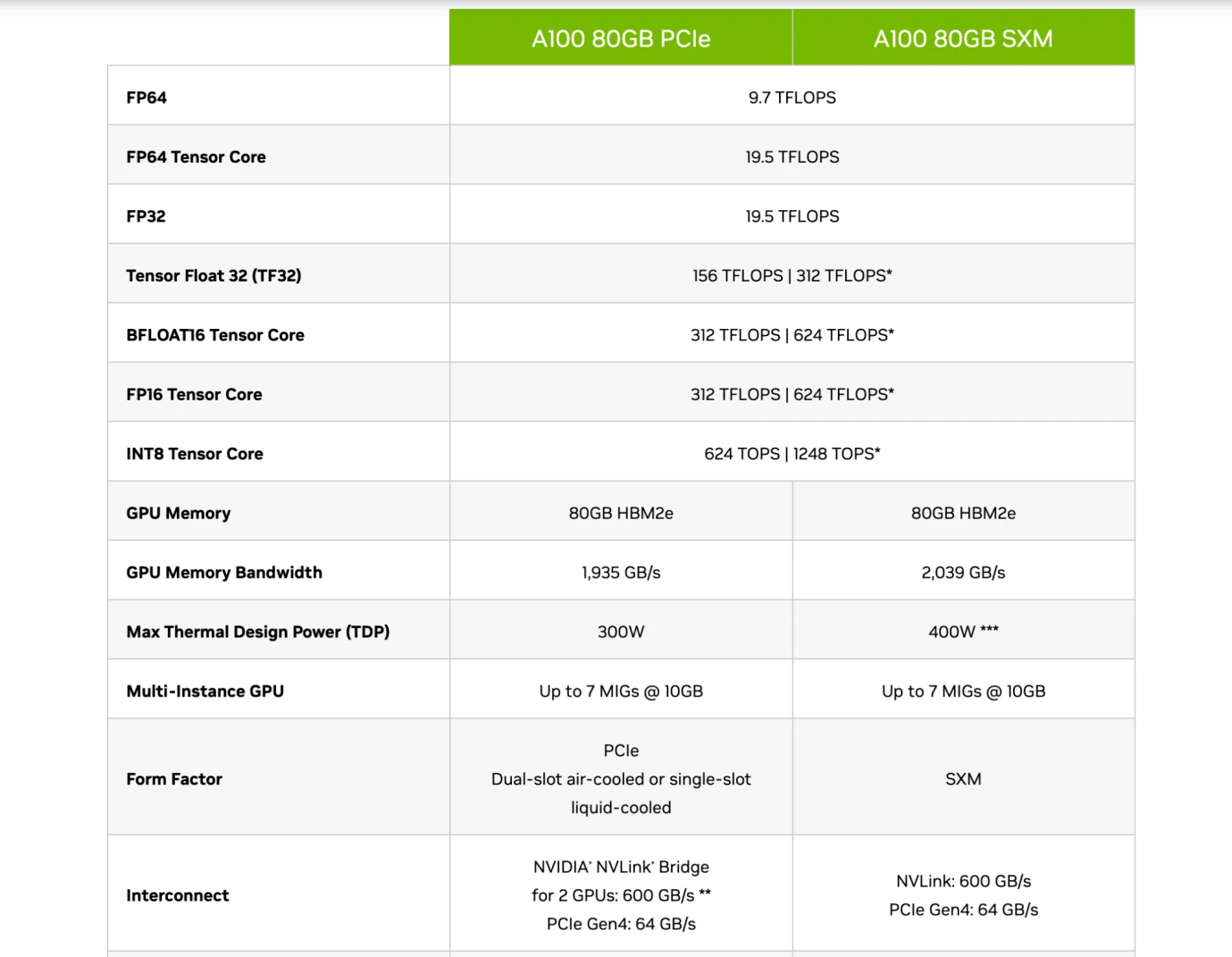
Thông số kỹ thuật của chip Nvidia A 100, Nguồn: Nvidia
Do đó, bạn đọc có thể hiểu phần giới thiệu chip của các hãng này, như hình trên, khi so sánh các mẫu A 100 80 GB PCIe và SXM của Nvidia, có thể thấy PCIe và SXM đều thuộc Tensor Core (a). mô-đun dành riêng cho tính toán AI). Với độ chính xác FP 16, chúng lần lượt là 312 TFLOPS và 624 TFLOPS (Trillion Flops).
Giả sử rằng các tham số mô hình lớn của chúng tôi lấy GPT 3 làm ví dụ, với 175 tỷ tham số và khối lượng dữ liệu là 180 tỷ Token (khoảng 570 GB), thì trong quá trình đào tạo trước, cần có 6 np Flops, tức là khoảng 3,15 * 1022 Số lần thất bại, nếu được đo bằng TFLOPS (Nghìn tỷ FLOP), thì nó xấp xỉ 3,15* 1010 TFLOPS, nghĩa là phải mất khoảng 50480769 giây, 841346 phút, 14022 giờ và 584 ngày để một chip mẫu SXM đào tạo trước GPT 3 một lần.
Chúng ta có thể thấy rằng đây là một khối lượng tính toán cực kỳ lớn. Nó đòi hỏi nhiều chip hiện đại để thực hiện đào tạo trước. Hơn nữa, lượng tham số của GPT 4 gấp 10 lần so với GPT 3 (1,76 nghìn tỷ). điều đó có nghĩa là ngay cả khi dữ liệu Nếu số lượng không thay đổi thì số lượng chip phải được mua nhiều hơn gấp 10 lần và số lượng Token của GPT-4 là 13 nghìn tỷ, gấp 10 lần so với GPT-3. , GPT-4 có thể yêu cầu số lượng chip gấp hơn 100 lần.
Trong đào tạo mô hình lớn, chúng tôi cũng gặp vấn đề với việc lưu trữ dữ liệu, vì dữ liệu của chúng tôi như số GPT 3 Token là 180 tỷ, chiếm khoảng 570 GB dung lượng lưu trữ và mạng thần kinh mô hình lớn với 175 tỷ tham số chiếm khoảng 700 GB. không gian lưu trữ. Dung lượng bộ nhớ của GPU nhìn chung nhỏ (như trong hình trên, A 100 là 80 GB), do đó khi không gian bộ nhớ không chứa được dữ liệu thì cần phải kiểm tra băng thông của chip, tức là đường truyền tốc độ truyền dữ liệu từ ổ cứng vào bộ nhớ. Đồng thời, vì chúng ta sẽ không chỉ sử dụng một chip nên chúng ta cần sử dụng phương pháp học chung để cùng đào tạo một mô hình lớn trên nhiều chip GPU, liên quan đến tốc độ truyền của GPU giữa các chip. Do đó, trong nhiều trường hợp, yếu tố hoặc chi phí hạn chế việc thực hành huấn luyện mô hình cuối cùng không nhất thiết là khả năng tính toán của chip mà thường là băng thông của chip. Do tốc độ truyền dữ liệu chậm nên thời gian chạy mô hình sẽ lâu hơn và tăng chi phí điện năng.

Thông số kỹ thuật chip H 100 SXM, Nguồn: Nvidia
Đến đây, bạn đọc có thể hiểu đại khái về Thông số kỹ thuật của chip, trong đó FP 16 thể hiện độ chính xác. Vì thành phần Tensor Core chủ yếu được sử dụng để huấn luyện AI LLM nên bạn chỉ cần nhìn vào khả năng tính toán của thành phần này. Lõi Tensor FP 64 đại diện cho H 100 SXM có khả năng xử lý 67 TFLOPS mỗi giây với độ chính xác 64. Bộ nhớ GPU đồng nghĩa với bộ nhớ của chip chỉ có 64 GB, hoàn toàn không thể đáp ứng yêu cầu lưu trữ dữ liệu của các dòng máy lớn. Do đó, băng thông bộ nhớ GPU đồng nghĩa với tốc độ truyền dữ liệu là 3,35 TB/s.
Chuỗi giá trị AI, Nguồn: Nasdaq
Chúng ta đã thấy rằng việc mở rộng số lượng dữ liệu và tham số nơ-ron đã tạo ra một khoảng cách lớn về sức mạnh tính toán và yêu cầu lưu trữ. Ba yếu tố chính này đã ươm mầm cả một chuỗi công nghiệp. Chúng ta sẽ sử dụng hình trên để giới thiệu về vai trò, chức năng của từng bộ phận trong chuỗi ngành.
Nhà cung cấp GPU phần cứng
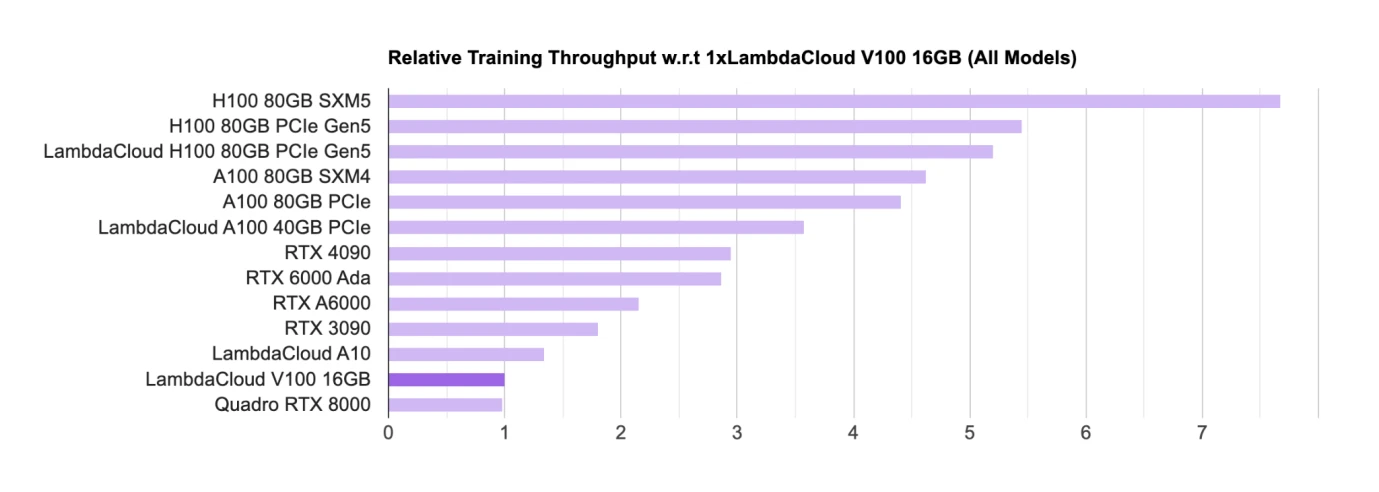
Xếp hạng chip GPU AI, Nguồn: Lambda
Phần cứng như GPU hiện là chip chính để đào tạo và suy luận. Về phía nhà thiết kế chính chip GPU, Nvidia hiện đang ở vị trí dẫn đầu tuyệt đối trong giới học thuật (chủ yếu là các trường đại học và viện nghiên cứu) chủ yếu sử dụng GPU cấp độ người tiêu dùng (RTX, Main). GPU chơi game); ngành công nghiệp chủ yếu sử dụng H 100, A 100, v.v. để thương mại hóa các mẫu lớn.
Trong danh sách, chip của Nvidia gần như chiếm ưu thế trong danh sách, và tất cả chip đều đến từ Nvidia. Google cũng có chip AI riêng tên là TPU, nhưng TPU chủ yếu được Google Cloud sử dụng để cung cấp hỗ trợ sức mạnh tính toán cho các công ty tự mua thường vẫn có xu hướng mua GPU Nvidia.
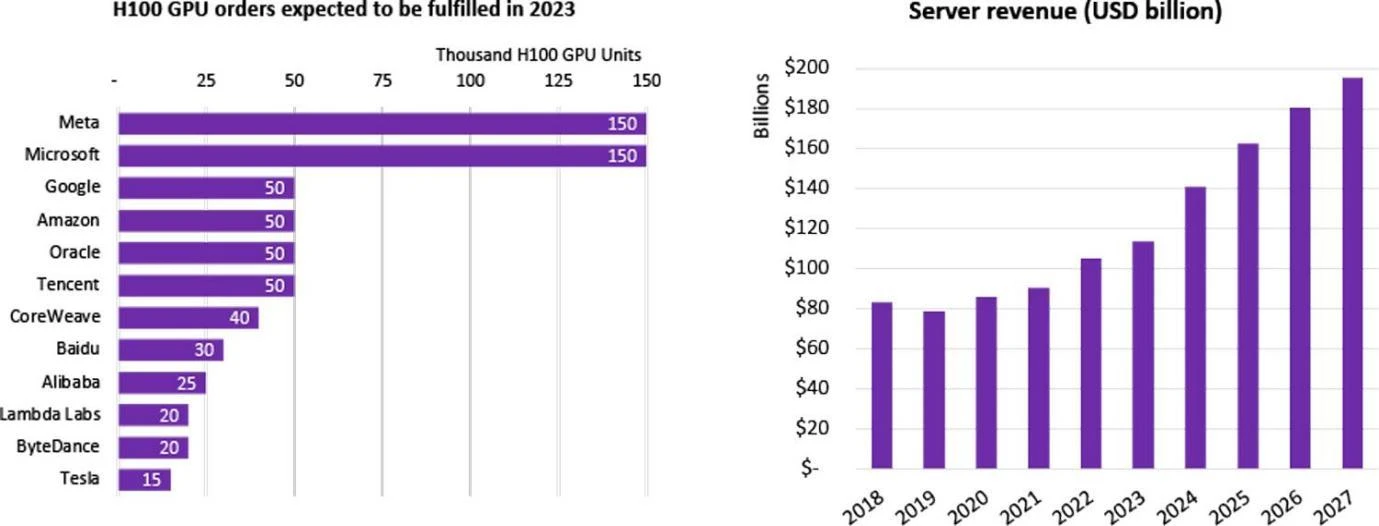
Thống kê mua GPU H 100 theo công ty, Nguồn: Omdia
Một số lượng lớn các công ty đã bắt tay vào nghiên cứu và phát triển LLM, bao gồm hơn 100 mô hình lớn ở Trung Quốc và tổng cộng hơn 200 mô hình ngôn ngữ lớn đã được phát hành trên toàn cầu. Nhiều gã khổng lồ Internet đang tham gia vào sự bùng nổ AI này. Các công ty này tự mua các mô hình lớn hoặc thuê chúng thông qua các công ty đám mây. Vào năm 2023, chip H 100 cao cấp nhất của Nvidia đã được nhiều hãng đăng ký ngay khi vừa ra mắt. Nhu cầu toàn cầu về chip H 100 vượt xa nguồn cung, bởi vì hiện tại chỉ có Nvidia đang cung cấp chip cao cấp nhất và chu kỳ vận chuyển của hãng đã lên tới con số đáng kinh ngạc là 52 tuần.
Trước sự độc quyền của Nvidia, Google, với tư cách là một trong những công ty dẫn đầu tuyệt đối về trí tuệ nhân tạo, đã dẫn đầu Intel, Qualcomm, Microsoft và Amazon đã cùng nhau thành lập Liên minh CUDA với hy vọng cùng nhau phát triển GPU để thoát khỏi ảnh hưởng tuyệt đối của Nvidia đối với thế giới. chuỗi công nghiệp học tập sâu.
Đối với các công ty công nghệ/nhà cung cấp dịch vụ đám mây/phòng thí nghiệm quốc gia rất lớn, họ thường mua hàng nghìn hoặc hàng chục nghìn chip H 100 để xây dựng HPC (trung tâm điện toán hiệu năng cao). Ví dụ: cụm CoreWeave của Tesla đã mua 10 nghìn chiếc H 100 80 GB. , giá mua trung bình là 44.000 USD (giá Nvidia khoảng 1/10) và tổng chi phí là 440 triệu USD; Tencent đã mua 50.000 chiếc; Meta đã mua 150.000 chiếc và đến cuối năm 2023, Là công ty có hiệu suất cao duy nhất Người bán GPU, Nvidia đã đặt hàng hơn 500.000 chip H 100.
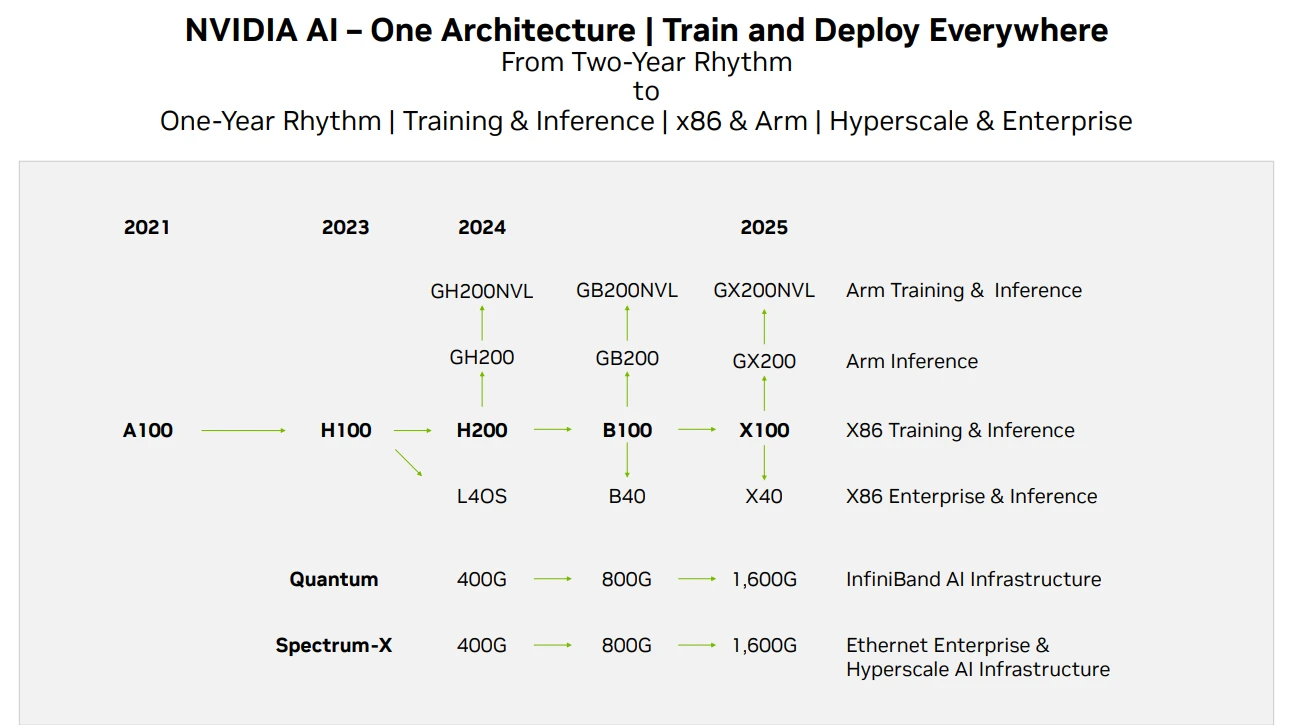
Lộ trình sản phẩm GPU Nvidia, Nguồn: Techwire
Về nguồn cung cấp chip của Nvidia, trên đây là lộ trình lặp lại sản phẩm của hãng. Theo báo cáo này, tin tức về H 200 đã được công bố. Người ta kỳ vọng rằng hiệu suất của H 200 sẽ gấp đôi so với H 100, trong khi B. 100 sẽ được phát hành vào cuối năm 2024 hoặc đầu năm 2025. Triển khai. Sự phát triển của GPU hiện nay vẫn đáp ứng Định luật Moore, với hiệu suất tăng gấp đôi sau mỗi 2 năm và giá thành giảm một nửa.
nhà cung cấp dịch vụ đám mây

Các loại đám mây GPU, Nguồn: Salesforce Ventures
Sau khi các nhà cung cấp dịch vụ đám mây mua đủ GPU để thiết lập HPC, họ có thể cung cấp sức mạnh tính toán linh hoạt và các giải pháp đào tạo được quản lý cho các công ty trí tuệ nhân tạo có nguồn vốn hạn chế. Như thể hiện trong hình trên, thị trường hiện tại chủ yếu được chia thành ba loại nhà cung cấp năng lượng điện toán đám mây. Loại thứ nhất là sự mở rộng quy mô cực lớn của các nền tảng sức mạnh điện toán đám mây (AWS, Google, Azure) được đại diện bởi các nhà cung cấp đám mây truyền thống. . Loại thứ hai là các nền tảng điện toán đám mây dọc, chủ yếu được thiết kế cho AI hoặc điện toán hiệu năng cao. Chúng cung cấp các dịch vụ chuyên nghiệp hơn, do đó vẫn còn một khoảng thị trường nhất định trong cuộc cạnh tranh với những gã khổng lồ thuộc loại hình dịch vụ đám mây ngành dọc mới nổi này. bao gồm CoreWeave (đã nhận được 11 USD trong vòng tài trợ Series C, trị giá 19 tỷ USD), Crusoe, Lambda (đã nhận được 260 triệu USD trong vòng tài trợ Series C, trị giá hơn 1,5 tỷ USD), v.v. Loại nhà cung cấp dịch vụ đám mây thứ ba là những người chơi trên thị trường mới, chủ yếu là nhà cung cấp dịch vụ suy luận. Các nhà cung cấp dịch vụ này thuê GPU từ các nhà cung cấp dịch vụ đám mây này chủ yếu triển khai các mô hình được đào tạo trước cho khách hàng và xây dựng dựa trên chúng. tinh chỉnh hoặc lý luận, các công ty đại diện trong loại thị trường này bao gồm Together.ai (định giá mới nhất là 1,25 tỷ USD), Fireworks.ai (Đầu tư dẫn đầu theo tiêu chuẩn, tài trợ Series A là 25 triệu USD), v.v.
Nhà cung cấp nguồn dữ liệu đào tạo
Như đã đề cập trước đó trong Phần 2, đào tạo mô hình lớn chủ yếu trải qua ba bước, đó là đào tạo trước, tinh chỉnh và học tăng cường. Đào tạo trước yêu cầu một lượng lớn dữ liệu và việc tinh chỉnh yêu cầu dữ liệu chất lượng cao. Do đó, các công ty dữ liệu như Google (có lượng dữ liệu lớn) và Reddit (có dữ liệu câu trả lời chất lượng cao) đã được đón nhận rộng rãi. sự chú ý từ thị trường.
Để không cạnh tranh với các mô hình lớn có mục đích chung như GPT, một số nhà phát triển chọn phát triển trong các lĩnh vực được chia nhỏ. Do đó, yêu cầu đối với dữ liệu là dữ liệu phải dành riêng cho ngành, chẳng hạn như tài chính, y tế, hóa học, vật lý,. sinh học, v.v. Nhận dạng hình ảnh, v.v. Đây là những mô hình dành cho các trường cụ thể và yêu cầu dữ liệu trong các trường cụ thể nên có những công ty cung cấp dữ liệu cho những mô hình lớn này. Chúng ta cũng có thể gọi đó là các công ty ghi nhãn dữ liệu, nghĩa là dán nhãn dữ liệu sau khi thu thập và cung cấp chất lượng tốt hơn và cụ thể hơn. kiểu dữ liệu.
Đối với các công ty đang phát triển mô hình, lượng dữ liệu lớn, dữ liệu chất lượng cao và dữ liệu cụ thể là ba nhu cầu dữ liệu chính.
Các công ty ghi nhãn dữ liệu lớn, Nguồn: Venture Radar
Một nghiên cứu của Microsoft tin rằng đối với SLM (mô hình ngôn ngữ nhỏ), nếu chất lượng dữ liệu của chúng tốt hơn đáng kể so với các mô hình ngôn ngữ lớn thì hiệu suất của chúng không nhất thiết kém hơn LLM. Và trên thực tế, GPT không có lợi thế rõ ràng về tính độc đáo và dữ liệu. Chính sự táo bạo khi đặt cược theo hướng này đã góp phần vào thành công của nó. Sequoia America cũng thừa nhận rằng GPT có thể không nhất thiết phải duy trì lợi thế cạnh tranh trong tương lai vì hiện tại không có hào sâu trong lĩnh vực này và hạn chế chính đến từ hạn chế trong việc mua lại sức mạnh tính toán.
Về lượng dữ liệu, theo dự đoán của EpochAI, theo sự tăng trưởng quy mô mô hình như hiện nay, tất cả dữ liệu chất lượng thấp và chất lượng cao sẽ cạn kiệt vào năm 2030. Do đó, ngành hiện đang khám phá dữ liệu tổng hợp trí tuệ nhân tạo để có thể tạo ra dữ liệu không giới hạn, nút thắt chỉ là sức mạnh tính toán. Hướng đi này vẫn đang trong giai đoạn thăm dò và đáng được các nhà phát triển quan tâm.
Nhà cung cấp cơ sở dữ liệu
Chúng ta có dữ liệu, nhưng dữ liệu cũng cần được lưu trữ, thường là trong cơ sở dữ liệu, để tạo điều kiện thuận lợi cho việc thêm, xóa, sửa đổi và truy xuất dữ liệu. Trong kinh doanh Internet truyền thống, chúng ta có thể đã nghe nói về MySQL và trong ứng dụng khách Ethereum Reth, chúng ta đã nghe nói về Redis. Đây là các cơ sở dữ liệu cục bộ nơi chúng tôi lưu trữ dữ liệu kinh doanh hoặc dữ liệu trên blockchain. Có các cách điều chỉnh cơ sở dữ liệu khác nhau cho các loại dữ liệu hoặc doanh nghiệp khác nhau.
Đối với dữ liệu AI và các tác vụ suy luận đào tạo deep learning, cơ sở dữ liệu hiện đang được sử dụng trong ngành được gọi là cơ sở dữ liệu vectơ. Cơ sở dữ liệu vectơ được thiết kế để lưu trữ, quản lý và lập chỉ mục một lượng lớn dữ liệu vectơ chiều cao một cách hiệu quả. Bởi vì dữ liệu của chúng ta không chỉ là các giá trị số hoặc văn bản mà còn là dữ liệu phi cấu trúc khổng lồ như hình ảnh và âm thanh, nên cơ sở dữ liệu vectơ có thể lưu trữ những dữ liệu phi cấu trúc này dưới dạng vectơ và cơ sở dữ liệu vectơ phù hợp để lưu trữ và xử lý các Vector này.

Phân loại cơ sở dữ liệu vectơ, Nguồn: Yingjun Wu
Những công ty lớn hiện tại bao gồm Chroma (đã nhận được 18 triệu USD tài trợ), Zilliz (vòng tài trợ mới nhất là 60 triệu USD), Pinecone, Weaviate, v.v. Chúng tôi hy vọng rằng với sự gia tăng nhu cầu về khối lượng dữ liệu và sự bùng nổ của các mô hình và ứng dụng lớn trong các lĩnh vực thích hợp khác nhau, nhu cầu về Cơ sở dữ liệu Vector sẽ tăng đáng kể. Và do có những rào cản kỹ thuật mạnh mẽ trong lĩnh vực này nên các công ty đã trưởng thành và có khách hàng khi đầu tư sẽ được cân nhắc nhiều hơn.
thiết bị cạnh
Khi xây dựng GPU HPC (cụm tính toán hiệu năng cao) thường tiêu thụ một lượng lớn năng lượng, tạo ra một lượng nhiệt năng lớn. Trong môi trường nhiệt độ cao, chip sẽ hạn chế tốc độ hoạt động để giảm nhiệt độ. Đây là cái mà chúng tôi thường gọi là giảm tần số, yêu cầu một số thiết bị làm mát cạnh để đảm bảo HPC hoạt động liên tục.
Do đó, ở đây có hai hướng của chuỗi công nghiệp tham gia, đó là cung cấp năng lượng (thường sử dụng năng lượng điện) và hệ thống làm mát.
Hiện tại, về mặt cung cấp năng lượng, điện được sử dụng chủ yếu, các trung tâm dữ liệu và mạng lưới hỗ trợ hiện chiếm 2% -3% lượng điện tiêu thụ toàn cầu. BCG dự đoán rằng khi các tham số của các mô hình học sâu lớn tăng lên và các con chip được lặp đi lặp lại, công suất cần thiết để đào tạo các mô hình lớn sẽ tăng gấp ba lần vào năm 2030. Hiện nay, các nhà sản xuất công nghệ trong và ngoài nước đang tích cực đầu tư vào các công ty năng lượng. Các hướng đầu tư năng lượng chính bao gồm năng lượng địa nhiệt, năng lượng hydro, pin lưu trữ và năng lượng hạt nhân.
Về mặt làm mát cụm HPC, làm mát bằng không khí hiện là phương pháp chính, nhưng nhiều VC đang đầu tư mạnh vào hệ thống làm mát bằng chất lỏng để duy trì hoạt động trơn tru của HPC. Ví dụ, Jetcool tuyên bố rằng hệ thống làm mát bằng chất lỏng của họ có thể giảm tổng mức tiêu thụ điện năng của cụm H 100 xuống 15%. Hiện nay, làm mát bằng chất lỏng chủ yếu được chia thành ba hướng thăm dò: làm mát bằng chất lỏng dạng lạnh, làm mát bằng chất lỏng ngâm và làm mát bằng chất lỏng phun. Các công ty trong lĩnh vực này bao gồm: Huawei, Green Revolution Cooling, SGI, v.v.
ứng dụng
Sự phát triển hiện tại của các ứng dụng AI cũng tương tự như sự phát triển của ngành công nghiệp blockchain. Là một ngành công nghiệp đổi mới, Transformer đã được đề xuất vào năm 2017 và OpenAI chỉ xác nhận tính hiệu quả của mô hình lớn vào năm 2023. Vì vậy hiện nay nhiều công ty Fomo đang chen chân vào con đường RD các mô hình lớn, tức là cơ sở hạ tầng rất đông đúc nhưng việc phát triển ứng dụng lại không theo kịp.

Top 50 người dùng hoạt động hàng tháng, Nguồn: A16Z
Hiện tại, hầu hết các ứng dụng AI đang hoạt động trong mười tháng đầu tiên là các ứng dụng loại tìm kiếm. Các ứng dụng AI thực tế đã xuất hiện vẫn còn rất hạn chế. Các loại ứng dụng tương đối đơn lẻ và không có loại ứng dụng xã hội và các loại ứng dụng khác. đã xuất hiện thành công.
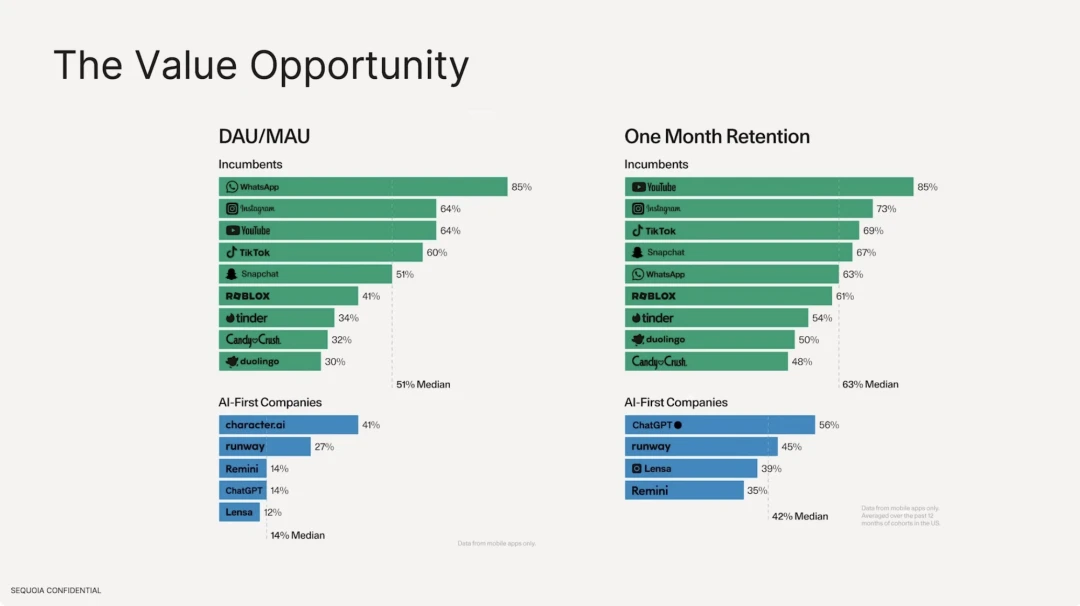
Chúng tôi cũng nhận thấy tỷ lệ duy trì của các ứng dụng AI dựa trên mô hình lớn thấp hơn nhiều so với các ứng dụng Internet truyền thống hiện có. Xét về số lượng người dùng hoạt động, tỷ lệ trung bình của phần mềm Internet truyền thống là 51%, trong đó cao nhất là Whatsapp, có mức độ gắn bó với người dùng cao. Nhưng về mặt ứng dụng AI, DAU/MAU cao nhất là character.ai, chỉ chiếm 41% và DAU chiếm trung bình 14% trong tổng số người dùng. Về tỷ lệ giữ chân người dùng, phần mềm Internet truyền thống tốt nhất là Youtube, Instagram và Tiktok. Tỷ lệ giữ chân trung bình của top 10 là 63%, so với tỷ lệ giữ chân của ChatGPT chỉ là 56%.

Bối cảnh ứng dụng AI, Nguồn: Sequoia
Theo báo cáo của Sequoia America, nó chia ứng dụng thành ba loại theo quan điểm định hướng vai trò, cụ thể là dành cho người tiêu dùng chuyên nghiệp, doanh nghiệp và người tiêu dùng thông thường.
1. Hướng đến người tiêu dùng: thường được sử dụng để cải thiện năng suất, chẳng hạn như nhân viên văn bản sử dụng GPT cho Hỏi Đáp, mô hình kết xuất 3D tự động, chỉnh sửa phần mềm, tác nhân tự động và ứng dụng Loại giọng nói cho cuộc trò chuyện bằng giọng nói, đồng hành, bài tập ngôn ngữ, v.v.
2. Đối với doanh nghiệp: thường là tiếp thị, pháp lý, thiết kế y tế và các ngành khác.
Mặc dù hiện nay nhiều người chỉ trích rằng cơ sở hạ tầng lớn hơn nhiều so với các ứng dụng, nhưng chúng tôi thực sự tin rằng thế giới hiện đại đã được định hình lại rộng rãi nhờ công nghệ trí tuệ nhân tạo, nhưng nó sử dụng các hệ thống đề xuất, bao gồm TikTok, Toutiao và Soda của ByteDance, v.v. cũng như tài khoản video Xiaohongshu và WeChat, công nghệ đề xuất quảng cáo, v.v. đều là những đề xuất tùy chỉnh cho các cá nhân và đây đều là các thuật toán học máy. Do đó, deep learning đang bùng nổ hiện nay không hoàn toàn đại diện cho ngành công nghiệp AI. Có rất nhiều công nghệ tiềm năng có cơ hội hiện thực hóa trí tuệ nhân tạo nói chung và cũng đang phát triển song song, và một số công nghệ này đã được sử dụng rộng rãi trong các ngành công nghiệp khác nhau. .
Vậy mối quan hệ nào phát triển giữa Crypto x AI? Những dự án nào khác đáng được chú ý trong Chuỗi giá trị của ngành công nghiệp tiền điện tử? Chúng tôi sẽ giải thích từng điều một trong Gate Ventures: AI x Crypto from Beginner to Master (Phần 2).
Tuyên bố từ chối trách nhiệm:
Nội dung trên chỉ mang tính tham khảo và không nên coi là bất kỳ lời khuyên nào. Luôn tìm kiếm lời khuyên chuyên nghiệp trước khi đầu tư.
Giới thiệu về Gate Ventures
Gate Ventures là nhánh đầu tư mạo hiểm của Gate.io, tập trung đầu tư vào cơ sở hạ tầng phi tập trung, hệ sinh thái và ứng dụng sẽ định hình lại thế giới trong kỷ nguyên Web 3.0. Gate Ventures làm việc với các nhà lãnh đạo ngành toàn cầu để trao quyền cho các nhóm và công ty khởi nghiệp có tư duy và năng lực đổi mới nhằm xác định lại mô hình tương tác của xã hội và tài chính.
Trang web chính thức: https://ventures.gate.io/
Twitter: https://x.com/gate_ventures
Trung bình: https://medium.com/gate_ventures





