
ZKML and Distributed Computing: Potential Governance Narratives of AI and Web3
AI & Web 3.0: The State of Affairs - Uncontrolled Swarms and Entropy Increase
In his book "Out of Control: The New Biology of Machines, Social Systems, and the Economic World," Kevin Kelly proposed a phenomenon: swarms of bees make decisions through distributed management and dance, and the entire swarm follows the largest group in the dance to determine the outcome of an event. This is what Maurice Maeterlinck referred to as the "soul of the hive" - each individual bee can make its own decision and guide other bees to confirm it, ultimately resulting in a collective choice.

The increase of entropy and disorder follows the laws of thermodynamics. In physics, this theory is concretized by placing a certain quantity of molecules in an empty box and calculating the final distribution. When applied to humans, algorithm-generated mobs, despite the differences in individual thinking, can exhibit collective patterns. However, they are often restricted to a confined space due to factors such as time and era, and eventually reach a consensus decision.
Of course, collective patterns are not necessarily correct, but they can represent consensus. The ability to influence consensus by oneself makes one a super-individual. However, in most cases, consensus does not require unconditional agreement from everyone; it only needs to be generally accepted by the group.
We are not discussing here whether AI will lead humanity astray. In fact, there have been many discussions on this topic, whether it is the generation of a large amount of garbage by AI applications, which has polluted the authenticity of network data, or the mistakes made by collective decision-making, which can lead to more dangerous situations.
AI is currently in a state of natural monopoly. For example, training and deploying large models require a large amount of computing resources and data, which only a small number of companies and organizations possess. These billions of data are regarded as treasures by each monopolist and are not even available for open sharing, let alone mutual access.
This leads to significant waste of data, as every large-scale AI project has to collect user data repeatedly, ultimately resulting in winners taking all - whether it is through mergers and acquisitions, selling out, growing individual giant projects, or the logic of traditional internet enclosure and race.
Many people say that AI and Web 3 are unrelated, but that's not entirely true. While they operate in different realms, the use of distributed technology can help break AI monopolies and promote the formation of decentralized consensus mechanisms, making it a natural fit.
Underlying Inference: Creating a Genuine Distributed Consensus Mechanism for AI
The essence of artificial intelligence lies in human beings themselves, with machines and models merely speculating and imitating human thinking. It's difficult to abstract a collective because what we encounter daily are real individuals. However, models learn and adjust using massive amounts of data, ultimately simulating collective forms. We won't evaluate the consequences of such models as there have been numerous instances of collective wrongdoing. Nevertheless, models accurately represent the formation of this consensus mechanism.
For example, when it comes to a specific DAO, if governance is mechanized, it's bound to impact efficiency. This is because the formation of collective consensus is already a complex matter, with the added tasks of voting, tallying, and other processes. If the governance of a DAO is embodied in the form of an AI model, with all data collection stemming from the speech data of all individuals within the DAO, the resulting decisions would be closer to collective consensus.
While training models for individual consensus can be done using the aforementioned approach, these individuals will still remain isolated. However, if a collective intelligent system forms a group AI, where each AI model collaborates with others to solve complex problems, it will significantly empower consensus dynamics.
For smaller collectives, they have the autonomy to build their own ecosystems or cooperate with other collectives, enabling efficient and cost-effective fulfillment of high-capacity computing or data transactions. But here lies a problem: the current state among various model databases is one of complete distrust, with everyone on guard against others. This is where the innate nature of blockchain comes into play: by achieving decentralization, true distributed interaction can be realized between AI machines with enhanced security and efficiency.
A global intelligent brain can enable independent and functionally singular AI algorithm models to collaborate and execute complex intelligent algorithm processes internally, forming a growing distributed consensus network. This is the greatest significance of AI's empowerment of Web 3.
Privacy and Data Monopoly? The Combination of ZK and Machine Learning
Whether it is for the purpose of AI evil or based on the protection of privacy and the fear of data monopoly, humans need to take targeted precautions. The core problem is that we do not know how the conclusions are drawn, and similarly, the operators of the model do not intend to clarify and answer this question. Solving this problem is even more necessary for the combination of the global intelligent brain mentioned above, otherwise no data provider is willing to share their core data with others.
ZKML (Zero Knowledge Machine Learning) is a technology that applies zero-knowledge proofs to machine learning. Zero-knowledge proofs (ZKPs) allow the verifier to believe in the truthfulness of the data without the prover revealing the specific data.
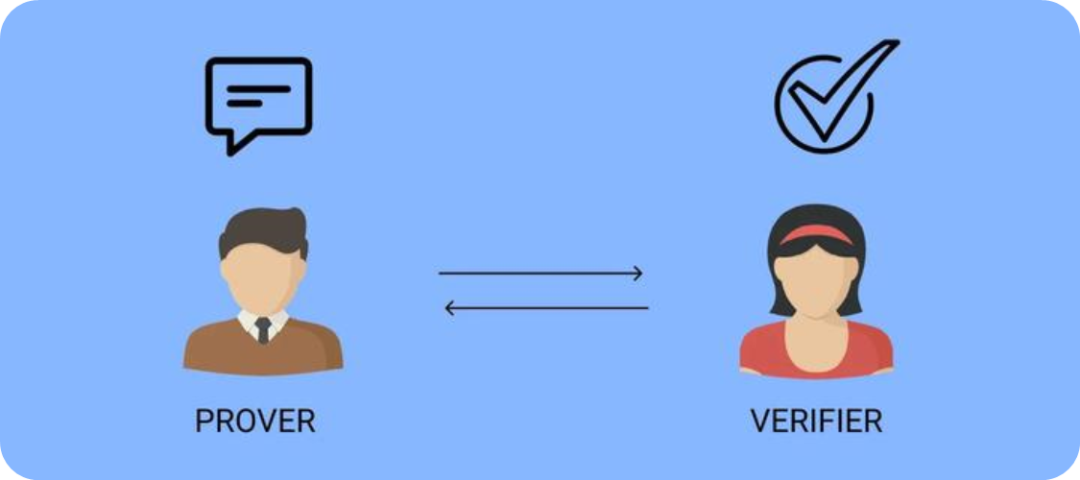
Using a theoretical case as an example, consider a standard 9x9 Sudoku puzzle. The condition for completion is to fill in the numbers 1 to 9 in each of the nine 3x3 grids, so that each number appears only once in each row, column, and grid. How can the person who creates this puzzle prove to the challenger that the Sudoku has a solution without revealing the solution?
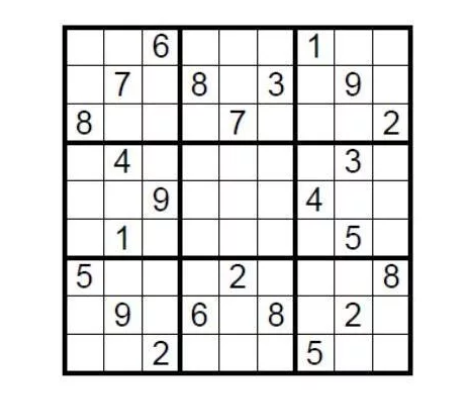
Simply cover the filled cells with the answers, then randomly ask the challenger to select a few rows or columns, shuffle the order of all the numbers, and verify if they are all from the number 1 to 9. This is a simple demonstration of zero-knowledge proofs.
Zero-knowledge proofs have three characteristics: completeness, correctness, and zero-knowledge. It proves the conclusion without revealing any details. The simplicity of this technology is reflected in the background of homomorphic encryption, where the difficulty of verification is much lower than the difficulty of generating the proof.
Machine Learning is the use of algorithms and models to allow computer systems to learn and improve from data. By learning from experience in an automated way, systems can automatically perform tasks such as prediction, classification, clustering, and optimization based on data and models.
The core of Machine Learning lies in building models that can learn from data and make predictions and decisions automatically. The construction of these models typically requires three key elements: dataset, algorithm, and model evaluation. The dataset is the foundation of Machine Learning and contains data samples used for training and testing Machine Learning models. The algorithm is the core of the Machine Learning model, defining how the model learns and predicts from data. Model evaluation is an important step in Machine Learning, used to assess the performance and accuracy of the model and determine whether optimization and improvement are needed.

In traditional Machine Learning, datasets usually need to be collected in a centralized location for training, which means that data owners must share their data with third parties, leading to the risk of data leakage or privacy breaches. With ZKML, data owners can share datasets with others without revealing the data. This is achieved through the use of zero-knowledge proofs.
The application of zero-knowledge proofs in Machine Learning is expected to solve the long-standing issues of privacy black boxes and data monopolies. Can project parties complete proofs and verification without revealing user data inputs or specific model details? Can every entity share their data or models without compromising privacy? Of course, the current technology is still in its early stages, and there will undoubtedly be many issues in practice. However, this does not prevent us from envisioning the possibilities, and many teams are already working on development.
Will this situation lead to small databases freeloading off large databases? When considering governance issues, we return to the thinking of Web 3. The essence of Crypto lies in governance. Whether through extensive use or sharing, appropriate incentives should be obtained. Whether it is through existing PoW, PoS mechanisms, or the latest PoR (Proof of Reputation) mechanisms, they all provide guarantees for incentive effects.
Distributed Computing: A Narrative of Interwoven Lies and Reality
The decentralized computing power network has always been a hot topic in the encryption circle. After all, AI models require astonishing computing power, and a centralized computing power network not only leads to resource waste but also forms substantial monopolies. It would be meaningless if the ultimate competition is just about the quantity of GPUs.
The essence of a decentralized computing power network is to integrate computing resources dispersed in different locations and on different devices. The main advantages commonly mentioned are: providing distributed computing capabilities, solving privacy issues, enhancing the credibility and reliability of artificial intelligence models, supporting quick deployment and operation in various application scenarios, and providing decentralized data storage and management solutions. Yes, with decentralized computing power, anyone can run AI models and test them on real-chain data sets from global users, thus enjoying more flexible, efficient, and cost-effective computing services.
At the same time, a decentralized computing power network can address privacy issues by creating a powerful framework that protects the security and privacy of user data. It also provides a transparent and verifiable computing process, enhancing the credibility and reliability of artificial intelligence models, and offering flexible and scalable computing resources for rapid deployment and operation in various application scenarios.
Looking at the model training process from a complete centralized computing power perspective, the steps typically include: data preparation, data segmentation, inter-device data transmission, parallel training, gradient aggregation, parameter updating, synchronization, and repeated training. In this process, even with centralized data centers using high-performance computing device clusters and sharing computing tasks through high-speed network connections, the high communication costs become one of the major limitations of a decentralized computing power network.
Therefore, despite the many advantages and potential of decentralized computing power networks, the development path still faces challenges considering the current communication costs and operational difficulties. In practice, realizing a decentralized computing power network requires overcoming many practical technical issues, whether it is ensuring the reliability and security of nodes, managing and scheduling dispersed computing resources effectively, or achieving efficient data transmission and communication. These are all significant problems to address.
Conclusion: Expectations for Idealists
Returning to the reality of business, the narrative of the deep integration of AI and Web 3 seems promising, but capital and users tell us through actual actions that this is bound to be an exceptionally challenging journey of innovation. Unless the project team can embrace a powerful patron like OpenAI while maintaining its own strength, the bottomless R&D costs and the unclear business model will crush us completely.
Whether it's AI or Web 3, they are currently in the very early stages of development, just like the dot-com bubble at the end of the last century, which didn't really enter its golden age until nearly a decade later. McCarthy once fantasized about designing artificial intelligence with human intelligence within a holiday, but it took nearly seventy years for us to take a crucial step in artificial intelligence.
Web 3+AI is the same, we have already determined the correctness of the direction, the rest is left to time.
As the tide of time gradually recedes, those who stand firm will be the cornerstone that leads us from science fiction to reality.


