
DA Scalability: Avail’s Current State

As users begin to integrate Avail into their chain designs, a question often arises: How many transactions can Avail handle? In this article, we will compare Ethereum and Avail based on the current architecture of the two chains. throughput.
This is the first in a series of articles on Avails scalability, discussing Avails current performance and its ability to scale in the near and long term.
Avail vs Ethereum
Ethereums blocks can hold up to 1.875 MB of data, and the block time is about 13 seconds. However, Ethereum blocks are usually not filled. Almost every block will not reach the upper limit of the data due to reaching the gas limit, because both execution and settlement consume gas. Therefore, the amount of data stored in each block is variable.
The need to combine execution, settlement and data availability in the same block is a core issue in a single blockchain architecture. L2 rollup started the movement towards modular blockchains, allowing execution operations to be handled on a separate chain with blocks of that chain dedicated to execution. Avail further adopts a modular design to decouple data availability, allowing blocks of a chain to be dedicated to data availability.

Currently, Avails block time is 20 seconds, and each block can hold approximately 2 MB of data. Assuming an average transaction size of 250 bytes, each Avail block today can accommodate approximately 8,400 transactions (420 transactions per second).
Whats more, Avail can always fill blocks up to the storage limit and increase the size as needed. We have a number of levers that can be adjusted quickly to increase the number of transactions per block to over 500,000 (25,000 transactions per second) if needed.
Can we increase throughput?
In order to increase throughput (especially transactions per second), the architects of the chain need to increase the block size or decrease the block time.
To be added to the chain, each block must generate commitments, construct proofs, propagate them, and have these proofs verified by all other nodes. These steps always take time, which puts a natural upper limit on block generation and confirmation time.
Therefore, we cannot simply reduce the block time to, say, one second. This simply does not allow enough time to generate commitments, generate proofs, and propagate these parts to all participants throughout the network. In a theoretical one-second block time, even if every network participant runs the most powerful machines capable of generating commitments and proofs instantaneously, the bottleneck is the propagation of data. Due to Internet speed limitations, the network cannot notify all full nodes of blocks fast enough. So we must ensure that the block time is high enough to allow data to be distributed to the network after consensus is reached.
Conversely, throughput can also be increased by increasing the block size, i.e. increasing the amount of data we can contain per block.
Current architecture: Adding a block to the chain
First, let’s look at the steps required to add a block to the chain. There are three main steps required to add each block to the chain. This includes the time it takes to generate a block, propagate the block, and validate the block.
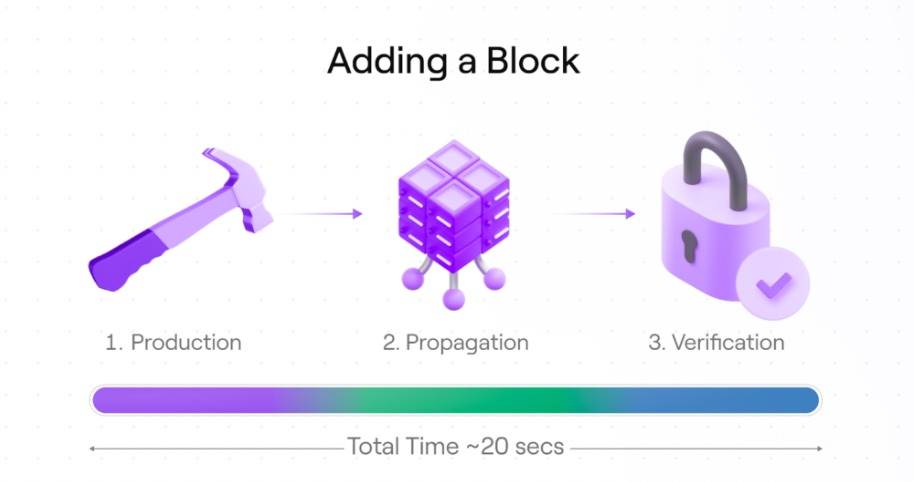
1. Block generation
This step includes the time required to collect and sort Avail transactions, build commitments, and expand (erasure code) the data matrix.
Block generation measures the time it takes to generate a block, as this always takes at least some time. Therefore, we have to consider not only the best-case times, but also the average-case and worst-case times on different machines.
The weakest machine that can participate in the generation of new blocks is the one that reaches its performance limit under average circumstances. All slower machines will eventually fall behind because they cannot catch up with the faster machines.
2. Propagation delay
Propagation latency is a measure of the time it takes to propagate blocks from producers to validators and the peer-to-peer network.
Currently, Avails block size is 2 MB. Within the current block time limit of 20 seconds, such a block size can be propagated. Larger block sizes make propagation trickier.
For example, if we increase Avail to support 128 MB blocks, the computation may scale (about 7 seconds). However, the bottleneck becomes the time required to send and download these blocks over the network.
Sending a 128 MB block around the world over a peer-to-peer network in 5 seconds is probably the limit of what is currently achievable.
The 128 MB limit has nothing to do with data availability or our commitment plan, but is a matter of communication bandwidth limitations.
This need to account for propagation delays provides us with Avails current theoretical block size limit.
3. Block verification
Once propagated, participating validators do not simply trust the block provided to them by the block proposer—they need to verify that the block produced actually contains the data claimed by the producer.
There is a certain tension between these three steps. We can have all validators being powerful machines and tightly connected by an excellent network in the same data center - this will reduce production and verification time, and let us spread large amounts of more data. However, since we also want to have a decentralized, diverse network with different types of participants, this is not an ideal approach.
Instead, throughput improvements will be achieved by understanding the steps required to add blocks to the Avail chain, and which steps can be optimized.
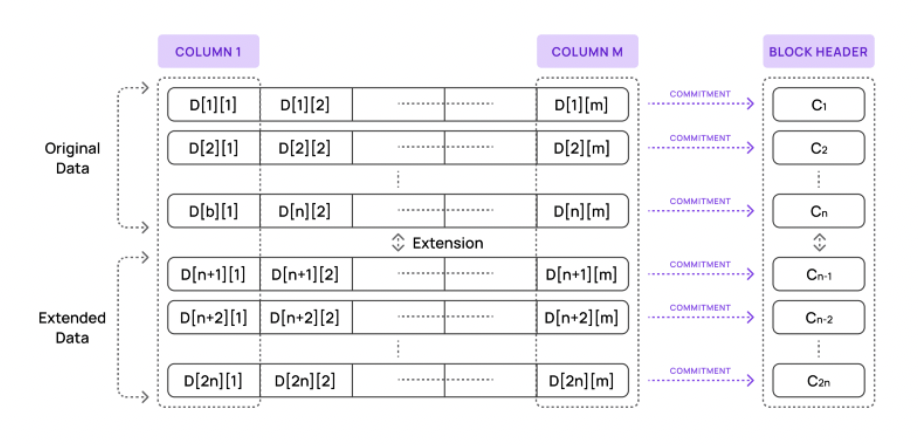
Currently, a validator using Avail takes the entire block and copies all commitments generated by the proposer to validate the block. This means that block producers and all validators need to perform each step in the diagram above.
In a single blockchain, it is the default practice for each validator to reconstruct the entire block. However, on a chain like Avail, where transactions are not executed, this reconstruction is not necessary. Therefore, one way we can optimize Avail is to allow validators to achieve their own guarantees on data availability through sampling, rather than by reconstructing blocks. This is less resource demanding on validators than requiring them to replicate all commitments. More related content will be introduced in subsequent articles.
How does Discovery Data Availability Sampling work?
In Avail, light clients use three core tools to confirm data availability: samples, commitments, and attestations.
Light clients currently perform sample operations, where they request the value of a specific cell and its associated validity certificate from the Avail network. The more samples they collect, the more confident they can be that all the data is available.
A commitment is generated by the block proposer and summarizes an entire row of data in the Avail block. (Tip: This is a step we will optimize later in this series.)
Every cell in the network generates a proof. Light clients use proofs and promises to verify that the value of the cell provided to them is correct.
Using these tools, the light client then performs three steps.
Decision: The required availability confidence determines the number of samples executed by the light client. They do not require many samples (8-30 samples) to achieve over 99.95% availability guarantees.
Download: The light client then requests these samples and their associated proofs and downloads them from the network (full node or other light client).
Verification: They look at the commitment in the block header (which is always accessible to light clients) and verify each cells proof against the commitment.
With this alone, light clients can confirm the availability of all data in a block without downloading the majority of the blocks contents. Additional steps performed by light clients also contribute to Avails security but are not listed here. For example, light clients are able to share their downloaded samples and proofs with other light clients in case they need them. But this is how the light client confirms data availability!
In the second part of this series, well look at ways to improve Avails throughput in the short term. Well explain why we believe Avail can meet the needs of any network over the next year, and how we can improve the network to meet the challenges of the coming years.


