
Avail Scalability: The Way Forward

Avail testnet is now live. As users begin to integrate Avail into their chain designs, a question that often arises is: How many transactions can Avail handle? This is the final article in a series on scalability and will discuss Avails current performance as well as its short-term and long-term scalability. You can read part one here and part two here .
The model below describes an architecture in which the actions of proposing and building blocks (deciding which transactions/data blocks are included in the block) are separated and performed by different actors.
By creating this new block builder entity, the computational work required to generate row commitments and generate cell proofs can be shared among different participants.
The core function of Avail is to receive data and output ordered data. Think of it like an API. Avail enables anyone to sample the availability of data.
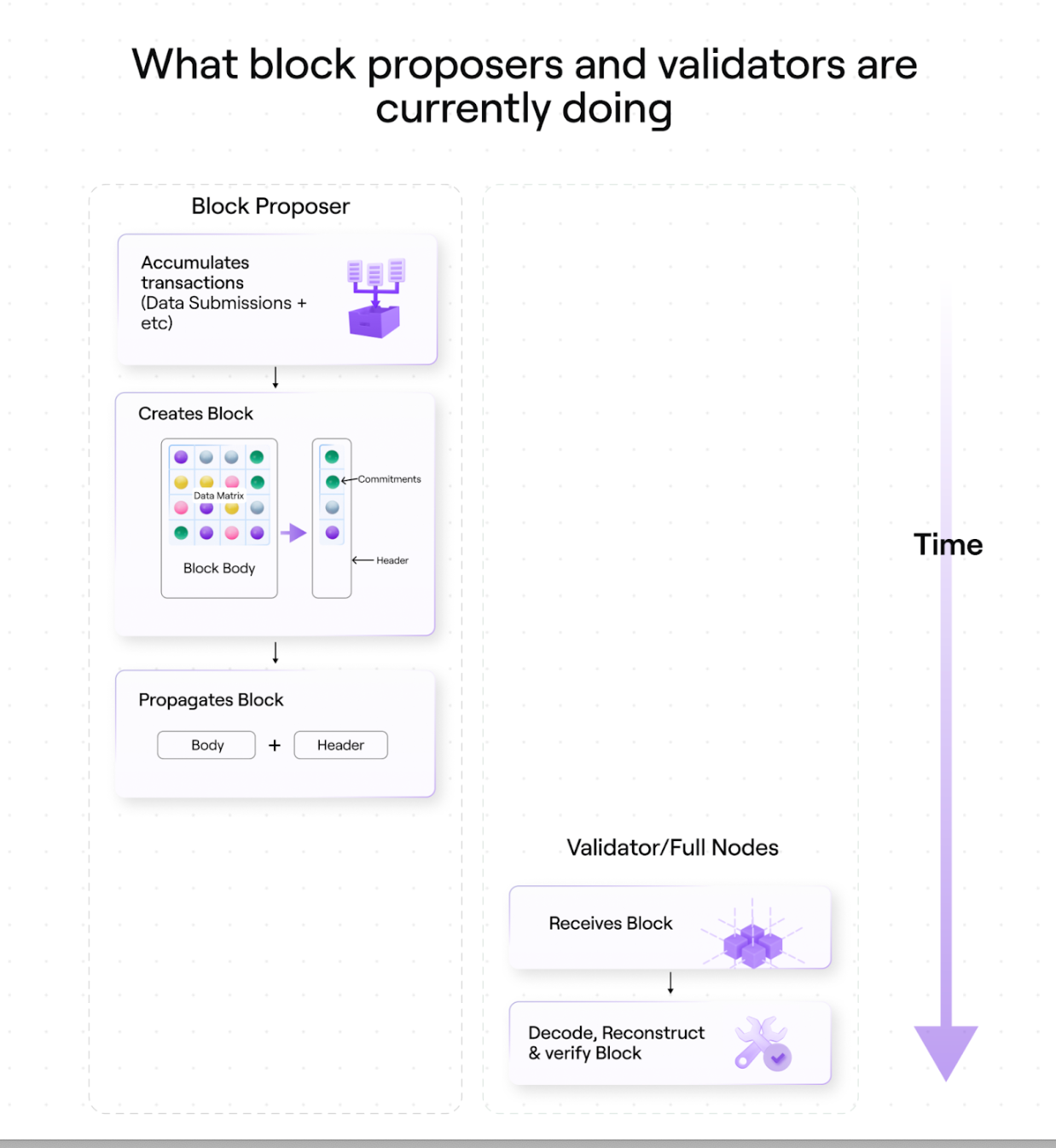
Before highlighting where we can improve, we first detail Avails requirements for block proposers and validators/full nodes in its current state.
1. The block producer creates the block body
Collect transactions (data submission)
Sort these transactions into the Avail data matrix, which becomes the block body
2. Block producer creates block header
Generate a promise for each row of the matrix
Extend these commitments using polynomial interpolation (generated and extended commitments become block headers)
3. The block producer propagates the block (body + header)
4. Validators and full nodes receive blocks
5. Validators and full nodes decode, reconstruct and verify blocks
Reconstruct data matrix
rebuilding commitments
extended commitment
Verify that all the data they receive matches the promise they generated
The fifth step, requiring the full node to regenerate the block header, is unnecessary in a system like Avail.
Full nodes currently do this because Avail inherits the architecture of traditional blockchains, which require validators to confirm that execution operations are completed correctly. Avail does not handle execution operations. Block proposers, validators, and light clients only care about data availability. This means that all participants in the Avail network can choose to use data availability sampling to trustlessly confirm the availability of data.
Since validators and full nodes can check the availability of data through sampling, they do not need to reconstruct entire blocks to ensure the security of the network.
The verifier doesnt need to redo everything the producer did to check if everything is true. Instead, they can be checked by sampling a small amount. Just like with light clients, when statistical guarantees of data availability are reached (after 8 - 30 samples), validators can add the block to the chain. Because Avail does not handle data execution, this operation can be performed safely.
Data sampling provides validators with a much faster alternative to the cumbersome 1:1 verification process. The magic of Avail is that by using only block headers, anyone (in this case the validators) can reach consensus that they are following the correct chain.
If we can do this, we can replace the entire block header reconstruction step with a few samples.
This article will explore the shift in our requirements for validators, as well as some other improvements. We will describe an improved system in which block proposers (still) create and propagate blocks, but all other network participants interact with the network through data availability sampling. We will then introduce a further system that separates block construction and block proposals, operated by two different network participants.
Its important to note that these changes are relatively advanced and are still under active research.
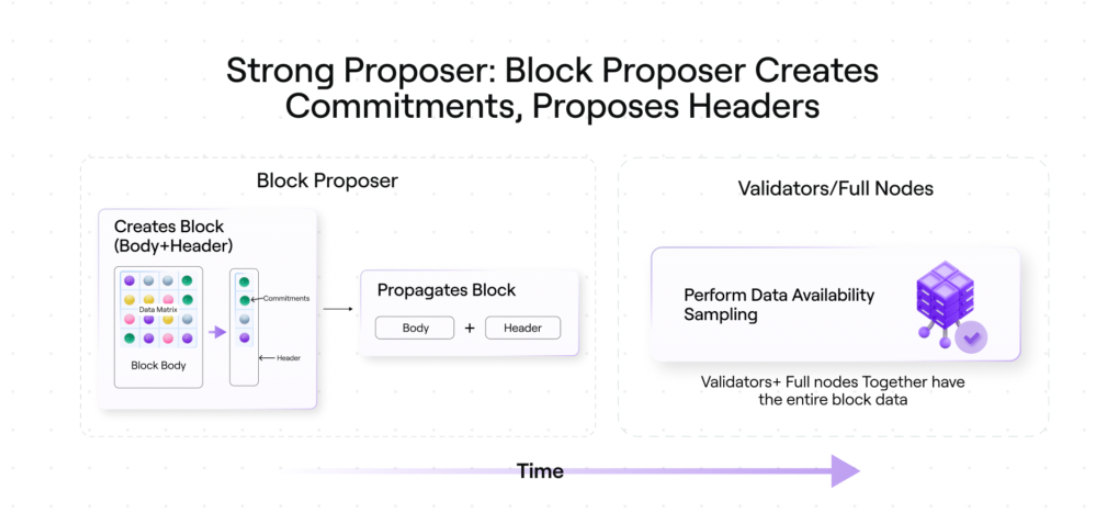
For Avail, a more efficient model is for a single node to build and propagate commitments to the network. All other participants will then generate and verify the proof.
This is the first time we enable not just light clients, but any part of a chain to do this. We allow validators to sample in the same way as light clients.
In this model, a single validator proposes a block, creates commitments for all rows of the data matrix, and then proposes only the block header.
Step 1: The proposer only propagates the block header information.
Step 2: Since the validators only receive the header information, they cannot decode or reconstruct the block. But since they can do data availability sampling, they dont need to.
In this case, other validators behave like light clients.
These other validators will use promises for data availability sampling and only accept blocks when the availability guarantee is met.
In this world, all nodes will run like light clients. Validators can avoid using the block body to regenerate commitments to ensure correct calculations by the block proposer.
Generating commitments for proof computations is unnecessary when the verifier can simply rely on proof verification.
Since we do not require full nodes to verify valid execution of blocks (Avail does not perform execution!), full nodes can be sure they are following the correct chain based on the header information alone. We just need proof of availability, and header information (combined with a small number of random samples) can provide this. This allows us to reduce the amount of computation required to become a validator.
This has the added benefit of potentially reducing communication times.
Complexity
We were hesitant to complete this model in the short term because it would require breaking away from the basic structure of Substrate. We need to remove the extrinsic root, which breaks all access to Substrate tools, although this is an improvement we are actively exploring.
Another model borrows from the sharded blob model in EIP-4844.https://eips.ethereum.org/EIPS/eip-4844?ref=blog.availproject.org
Imagine this system:
1. Each row of the block data matrix is built by a different builder and includes the associated polynomial commitment of the row.
Builders share their rows with the p2p network and pass promises to proposers.
2. Header Creation: A single block proposer collects these commitments.
Proposers sample from builders (and p2p networks) to confirm that a given commitment can generate valid open proofs before obliterating the encoded commitment. This combination of original promise + extended promise becomes the header.
3. The proposer shares this header with the validator.
4. Proposers and validators perform data availability sampling by sampling random units from the p2p network (or builders) and confirming that the data generates valid open proofs.
5. Once the validator reaches statistical guarantees of availability, the block header is added to the chain.
Block proposers dont need to do much work since commitments are generated by many participants.
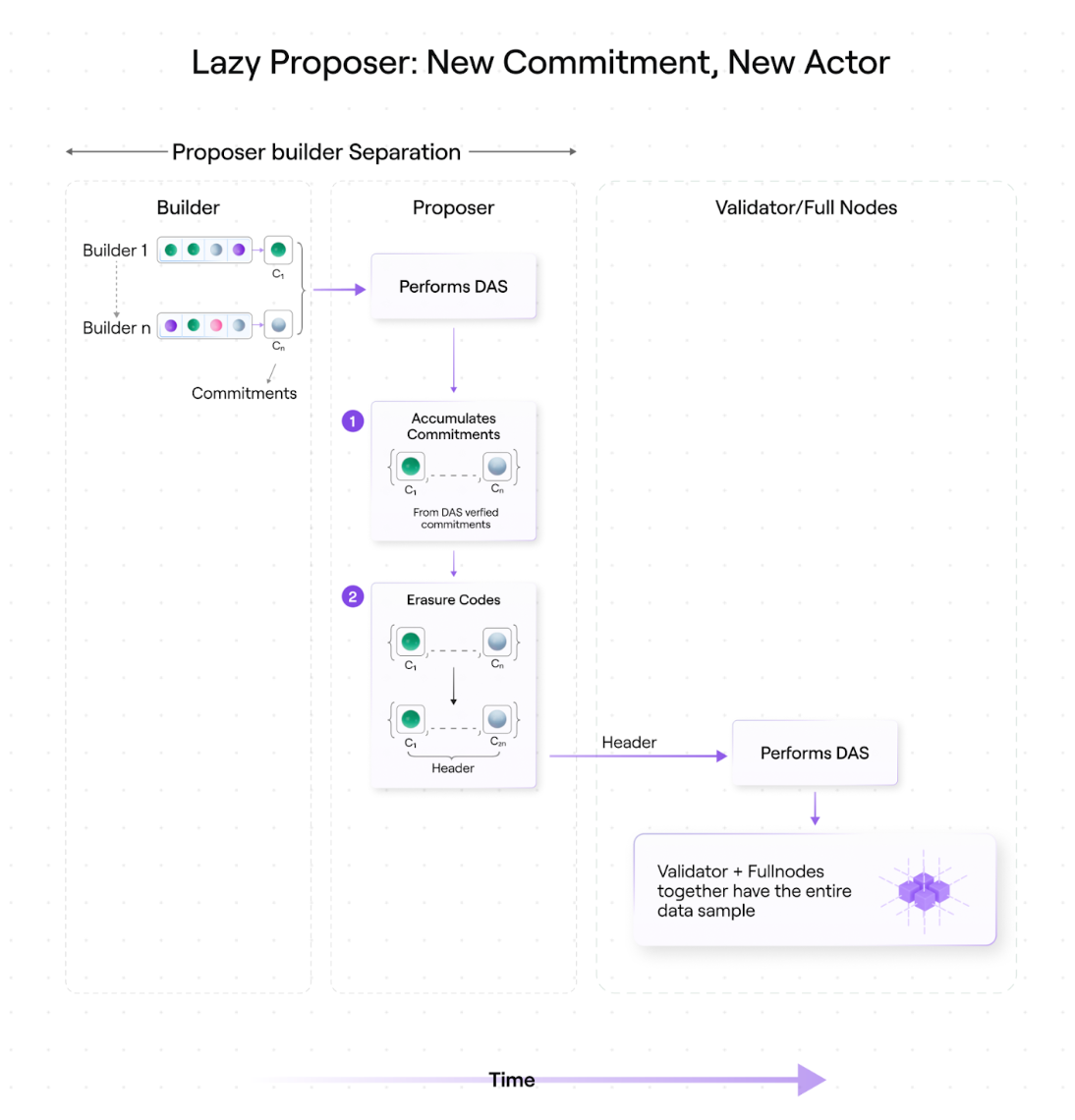
The lazy proposer model has a single proposer for a block. Participants can then be partitioned in the same manner as the proposer-builder separation described above.
There can be multiple builders creating small pieces of a block. They all send these blocks to an entity (the proposer), which randomly samples each part to build the header it proposes.
The block body is built using logical structures.
one example
What makes the lazy proposer model different is that block builders and block proposers are separate entities.
Suppose there are four block builders, each with a row of the data matrix. Each builder creates a promise using this line.
Each builder then sends their rows and built commitments to a designated proposer, who samples data from the block body to confirm the given commitment. The proposer then polynomially interpolates the commitments so that they not only have four of the original constructed commitments, but also eight. The data matrix has now been erasure-encoded and expanded.
These eight lines and eight promises are verified by the same proposer.
When looking at the entire matrix, we can see that half of the rows are constructed by proposers (encoded by erasure) and the other half are offered to them.
The producer then proposes a block header and everyone accepts it. This results in blocks that look identical to those currently being produced by the Avail testnet, although they are built more efficiently.
Avails lazy proposer model is more efficient, but also quite complex. While there are other, easier opportunities to optimize the entire system, the Avail team is excited to explore implementing this model.
Comparing traditional blockchain transactions with the lazy proposer model
The lazy proposer model is not that different from the way individual blockchain transactions are processed on non-Avail blockchains today.
Today, when anyone makes a transaction on almost any chain, they send notifications of this transaction to all nodes. Soon, each node will have this transaction in its mempool.
So what do block producers do?
Block producers pull transactions from their mempool, aggregate them together, and generate a block. This is the typical role of a block producer.
In Avail, data blocks and their commitments are treated similarly as individual transactions. These data block + commitment combinations are propagated on the system just like individual transactions are sent on a traditional chain.
Soon, everyone will have a commitment to these chunks of data. With these commitments in place, proposers can begin random sampling to ensure data availability. With enough sampling confidence, the node will extend these commitments, accept the data in the body, and build the block header - thus creating the next block.
Conclusion
These architectural proposals proposed for Avail are intended to demonstrate the importance of decoupling the data availability layer from other core functionality of the blockchain.
When data availability is handled separately, optimizations can be made to treat data availability as an independent layer, which can lead to greater improvements than when data availability is tied to other blockchain functions such as execution.
Whether they’re called layer 3 solutions, modular blockchains, or off-chain scaling solutions, we’re excited to see the novel ideas teams come up with leveraging this dedicated data availability layer. Teams can rest assured that Avail will be able to scale directly with any chain or application built on top of it. As we build a modular blockchain network with hundreds of validators, thousands of light clients, and many new chains to come, we don’t expect to have any issues meeting demand.


