




Ethereums EVM faces serious performance issues due to its single-threaded architecture, especially when processing high-concurrency transactions. This serial execution method limits the throughput of the network, resulting in a processing speed that is far from meeting the growing user needs. By analyzing the entire process of EVM serial execution step by step, we found two major software problems that Ethereum wants to achieve parallel execution: 1. State recognition 2. Data architecture and IPOS consumption. For these two problems, each company has its own solution, facing multiple trade-offs including EVM compatibility, optimistic or pessimistic parallel recognition, database data architecture, more efficient use of memory or high-concurrency channels on hard disks, developer development experience, hardware requirements, modular or monolithic chain architecture, all of which are worth careful consideration.
We also noticed that although parallel execution seems to have expanded the blockchain exponentially, it still has bottlenecks. This bottleneck is inherent in distributed systems, including P2P networks, database throughput, and other issues. Blockchain computing still has a long way to go to reach the computing power of traditional computers. At present, parallel execution itself also faces some problems, including the increasingly high hardware requirements for parallel execution, the centralization and censorship risks brought about by the increasing specialization of nodes, and the reliance on memory, central clusters or nodes in mechanism design will also bring downtime risks. At the same time, cross-chain communication between parallel blockchains will also be a problem. This is still worth exploring by more teams.
From the architectures of various companies and their thoughts on EVM compatibility, we know that disruptive innovation comes from not compromising with the past. Blockchain technology is still in its early stages, and performance improvements are far from being finalized. We can’t wait to see more entrepreneurs who are unwilling to compromise and do not follow the rules build more powerful and interesting products.
Ethereum’s single-threaded problem
Ethereum EVM has always been criticized for its performance, mainly due to its backward architectural design, among which the most serious problem is the lack of support for parallelization. For transaction parallelization, it is equivalent to turning a road into multiple runways, which can bring an exponential increase in the amount of traffic that can be accommodated on the road.
Going deeper into Ethereum, in the context of the current separation of the execution layer and the consensus layer, we will find that all EVM transaction processing is executed serially.
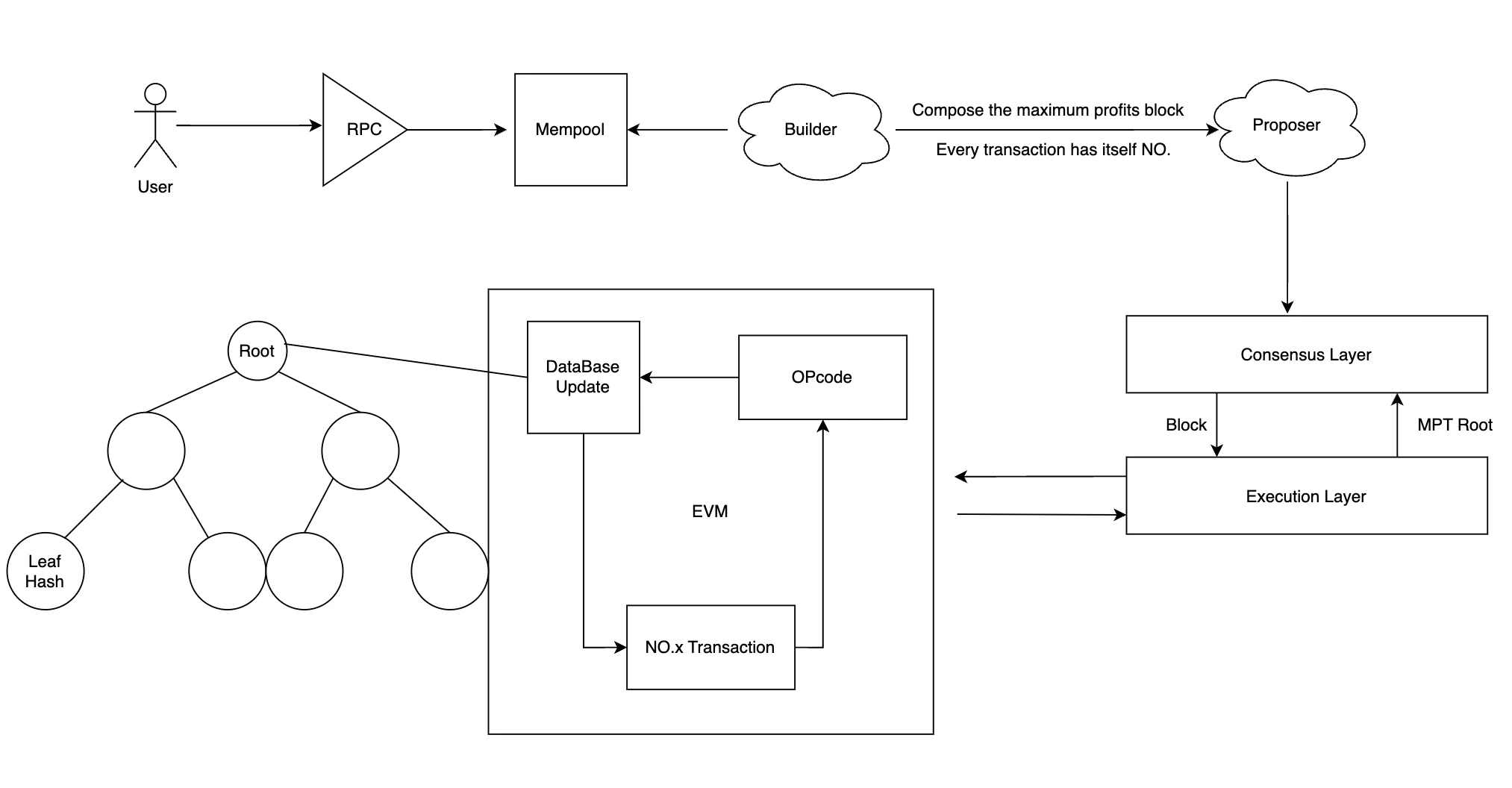
Ethereum transaction execution process
In Ethereum transactions, users first send transactions to Mempool via RPC, and then Builder selects transactions with the highest profit and sorts them. At this point, the order of transactions has been determined. Proposer broadcasts transactions to the consensus layer, and the consensus layer determines the validity of the block, such as whether it is from a valid sender. Transactions in the block are sent as execution loads to the execution layer, which executes the transactions. The brief process of executing transactions is as follows: (Take Alice sending 1 ETH to Bob as an example)
1. In the EVM of the execution node, it will convert the transaction instruction of NO.0 into an OPcode code that the EVM can recognize.
2. Then determine the Gas required for this transaction based on the OPcode hard code.
3. During the transaction, it is necessary to access the database to obtain the status of Alice and Bobs balances, and then execute the transaction opcode to know that Alices balance is reduced by one and Bobs balance is increased by one, and write/update the balance status to the database.
4. Take out the transaction No. 1 from the block and continue to execute it in a sequential loop until all the transactions in the block are executed.
5. The data in the database is mainly stored in the form of Merkel numbers. After all the transactions of the block are executed in sequence, the state root (storing account status), transaction root (storing the order of transactions), and receipt root (storing the accompanying information of the transaction, such as success status and Gas Fees) in the database will be submitted to the consensus layer.
6. The consensus layer receives the state root and can easily prove the authenticity of the transaction. The execution layer passes the verification data back to the consensus layer, and the block is now considered verified.
7. The consensus layer adds the block to the head of its own blockchain and attests to it, broadcasting the attestation across the network.
This is the entire process, which involves the sequential execution of transactions within the block. Each transaction has its own NO, and each transaction may need to read the status in the database and rewrite the status. If it is not executed sequentially, it will cause state conflicts because some transactions are interdependent. Therefore, this is why MEV chooses serial execution.
The simplicity of MEV also means that serial execution brings extremely low performance, which is one of the main reasons why Ethereum has only double-digit TPS. In the current development context of focusing on consumer applications, EVM, as a backward design paradigm, faces performance issues that need to be improved. Although the current EVM has moved towards a roadmap that is completely centered on Layer 2, its EVM problems, such as the MPT trie structure and the inefficiency of databases such as LevelDB, are all in urgent need of resolution.
As this problem evolves, many projects have begun to build parallel high-performance EVMs to solve Ethereums old design paradigm. Through the EVM process, we can see that there are two main problems that high-performance EVM solves:
1. Transaction state separation: Since transactions are interdependent in state, they need to be run serially. Transactions with independent states need to be separated, and dependent transactions still need to be executed sequentially. Then they can be distributed to multiple cores for parallel processing.
2. Improvement of database architecture: Ethereum uses MPT tree. Since a transaction involves a large number of read operations, this usually leads to extremely high database read and write operations, that is, the IOPS (IO Per Second) requirements are extremely high. Ordinary consumer-grade SSDs cannot meet this requirement.
In general, in the current mainstream blockchain construction solutions, the software optimization is often mainly the separation of transaction status to build parallel transactions and the optimization of the database to support high-concurrency transaction status reading. With the demand for high performance, the demand for hardware in most projects is also increasing. Ethereum has always been very cautious about the performance expansion of Layer 1, because it means centralization and instability. However, the current high-performance EVM often abandons these self-imposed shackles and introduces extreme software improvements, P2P network optimization, database reconstruction, and enterprise-level professional hardware.
The resulting database IOPS problem
The identification and separation of parallel execution is not difficult to understand. The main difficulty and less discussed by the public is the IOPS problem of the database. In this article, we will also use actual examples to let readers feel the complex problems faced by blockchain databases.
In Ethereum, the full node actually installs a virtual machine, which can be considered as our ordinary computer. Our data is stored in professional software - database. This software is used to manage huge data. Different industries have different requirements for different types of databases. For example, in AI, a field with a large number of data types, vector databases are popular. In the blockchain field, such as Ethereum, a relatively simple Key-Value Pair database is used.
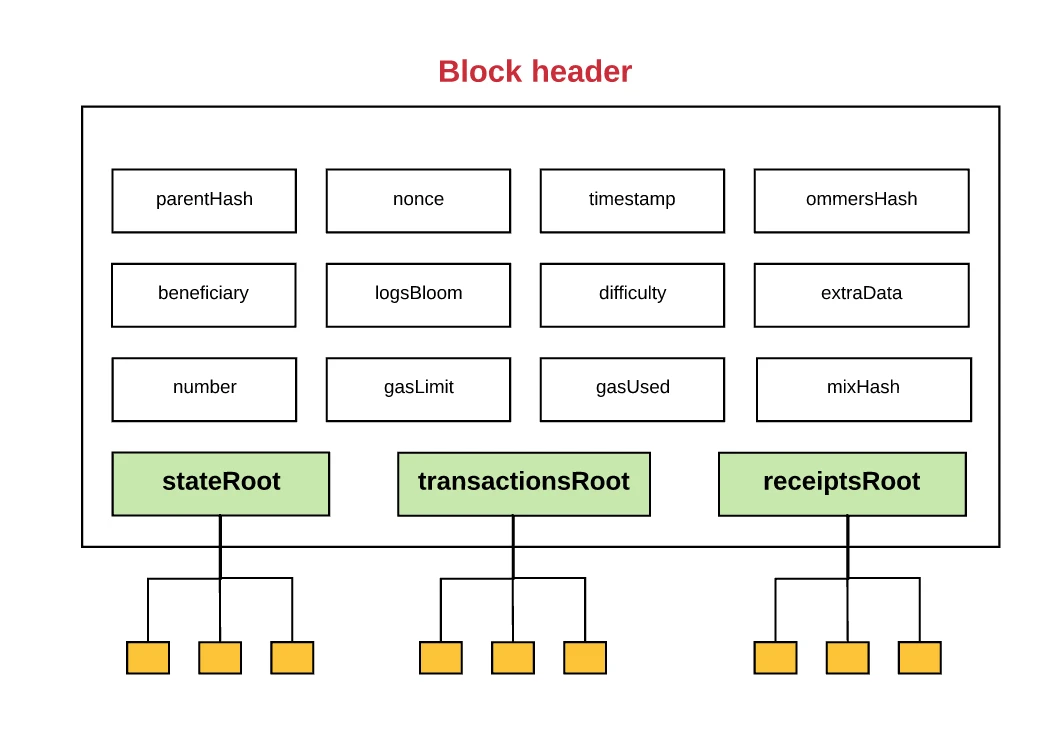
Schematic diagram of Ethereum data organization, source: Github
Usually the data in the database is organized in an abstract way, and Ethereum is organized in the MPT tree way. The final data state of the MPT tree will form a root node. If any data is changed, the root node will change, so using MPT can easily verify data integrity.
Lets take an example to feel the current database resource consumption:
In a k-fork Merkle Patricia Tree (MPT) with n leaf nodes, updating a single key-value pair requires O( klog kn ) read operations and O( log kn ) write operations. For example, for a binary MPT with 16 billion keys (i.e. 1 TB of blockchain state), this is equivalent to about 68 read operations and 34 write operations. Assuming that our blockchain wants to process 10,000 transfer transactions per second, it needs to update three key-values in the state tree, which requires a total of 10,000 x 3 x 68 = 2,040,000 times, or 2M IOPS (I/O Per Second) operations (in practice, this can be reduced by an order of magnitude through compression and caching, to about 200,000 IOPS, which we will not expand on). Currently major consumer-grade SSDs are completely unable to support this operation (Intel Optane DC P 580 0X 800 GB is only 100,000 IOPS).
MPT trees currently face many problems, including:
● Performance issues: Due to its hierarchical tree structure, MPT often needs to traverse multiple nodes when updating data. Each state update (such as transfer or smart contract execution) requires a large amount of hash calculations, and because it needs to access many layers of nodes, the performance is low.
● State expansion: As time goes by, the state data such as smart contracts and account balances on the blockchain will continue to increase, causing the size of the MPT tree to continue to expand. This will cause nodes to need to store more and more data, bringing challenges to storage space and synchronization nodes.
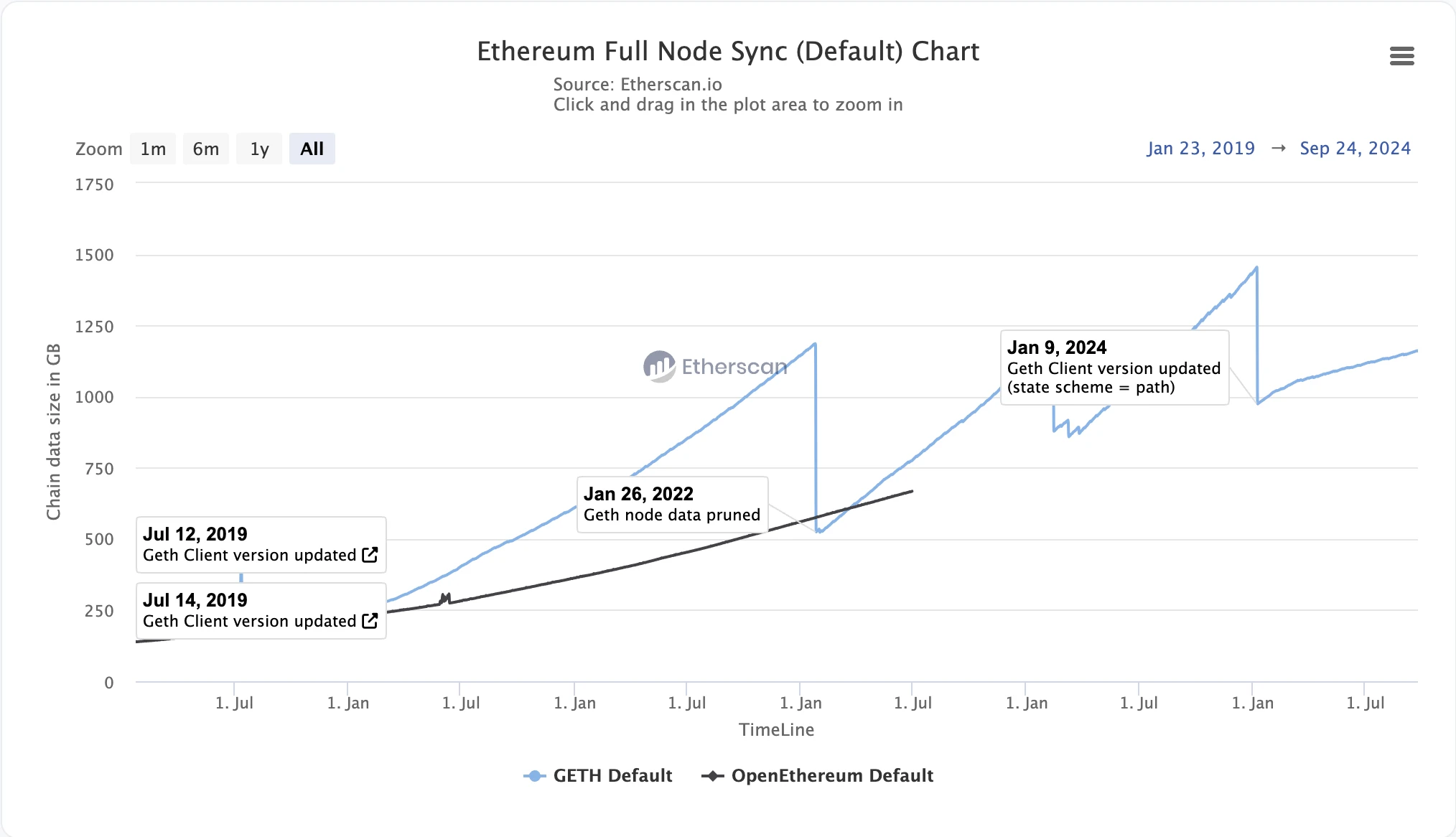
Ethereum state expansion (involving state pruning), source: Etherscan
● Inability to efficiently handle partial updates: When a leaf node in the tree structure changes, the nodes on the entire path will be affected. Ethereum MPT needs to recalculate all hash values from leaf nodes to the root node, which means that even local state changes require updating a large number of nodes, affecting performance.
We can see that Ethereum currently faces many problems under MPT, and it has also proposed many solutions, such as state pruning for state expansion and building a new Verkel Tree for MPT performance issues. By building a database with a new Verkel Tree structure, the number of database accesses during partial updates is reduced by reducing the depth of the tree, and vector commitments (mainly KZG commitments) are used to reduce the size of the proof and the number of database accesses.
In short, the past MPT tree is too old and faces many new challenges, so changing the way data is stored, such as using Verkel tree, has been included in its roadmap. However, this is only a very slight modification and still does not involve parallel execution and high IOPS solutions required under high concurrency.
New public chain comes standard with parallel execution
As we said in the previous section, parallel execution means changing from a single lane to multiple lanes. At a multi-lane intersection, a middleware such as a traffic light is often needed to coordinate and send information so that each lane can pass smoothly. The same is true for blockchain. In parallel transactions, we need to pass the users transactions through a state-recognizing middleware so that transactions with unrelated states can be separated to achieve parallel execution. The high TPS brought by parallel execution also means a large number of IOPS requirements for the underlying database. Almost all new Layer 1s have parallel execution as a standard feature.
There are many ways to classify the implementation of parallel execution. According to the underlying virtual machine, it can be divided into EVM (Sei, MegaETH, Monad) and None-EVM (Solana, Aptos, Sui). According to the separation of transaction status, it can be divided into optimistic execution (assuming that all transactions are not wanted, if the status conflicts, these transactions are rolled back and re-executed) and advance declaration (developers need to declare the state data to be accessed in the program). These classifications also mean trade-offs.
Next, we will not use EVM as the basis for classification, but will simply compare the improvements in state separation and database of each public chain.
MegaETH
Strictly speaking, MegaETH is a heterogeneous blockchain with performance as its main goal. It relies on the security of Ethereum and uses EigenDA as the consensus layer and DA layer. As the execution layer, it will maximize the release of hardware performance and improve TPS.
There are three types of optimization methods for transaction processing:
1. State separation: Streaming block construction using transaction priority. This model is similar to Solanas POS. In fact, Solanas transactions are also stream-constructed, but Solana has no priority and all competition depends on speed. MegaETH hopes to build some kind of priority algorithm for transactions.
2. Database: In response to the problems of MPT Trie, a new data structure was built to provide higher IOPS. When we checked the code base of MegaETH, we found that it also referred to the design of Verkel Trie.
3. Hardware specialization: By centralizing and specializing the sorter, in-memory computing is achieved, significantly improving IO efficiency.
In fact, MegaETH hopes to delegate security and anti-censorship to Ethereum as Layer 2, so that it can optimize nodes to the maximum extent and ensure that the sorter does not do evil through the economic security of POS. There are many points worth chanllenge here, but we will not expand them. Although MegaETH is building parallel execution transactions, in fact, it has not yet achieved parallel execution. It hopes to maximize the performance of a single sorter node to maximize the performance of hardware, and then expand the performance through parallel execution.
Monad
Unlike MegaETH, Monad is a separate chain, which meets the two important points that need to be optimized for parallel execution we introduced, state separation of parallel execution and database reconstruction. Lets briefly describe the specific methods used by Monad:
● Optimistic parallel execution: For transaction identification, the most classic default is adopted, which is that the status of all transactions is not closed. When a status conflict occurs, the transaction is re-run. This method currently works well on Aptos Block-STM mechanism.
● Database reconstruction: In order to improve the IOPS of the database, Monad reconstructed the EVM-compatible data structure MPT (Merkel Patricia Tree). Monad implemented a data structure compatible with Patricia Tree and supports the latest database asynchronous I/O. It can support reading a certain state without waiting for the completion of writing the data.
● Asynchronous execution: On Ethereum, although we strictly identify the specific consensus layer and execution layer, we find that the consensus layer and the execution layer (which is different from the concept of Layer 2 as the execution layer, here it means that Ethereum still needs execution nodes to execute transactions on Ethereum) are still coupled together. The execution gives the updated Merkel Root after execution to the consensus, so that the consensus layer can vote to reach a consensus. Monad believes that the state has been determined at the moment the sorting is completed, so it is only necessary to reach a consensus on the sorted transactions, and even execution is not needed to reveal this result. This idea allows Monad to cleverly separate the consensus layer from the execution layer to achieve simultaneous consensus execution. Nodes can execute transactions in N-1 blocks while maintaining consensus votes on N blocks.
Of course, Monad has many other technologies including the new consensus algorithm MonadBFT, which together build a high-performance parallel EVM Layer 1.
Aptos
Aptos was spun off from Facebooks Diem team, and it and Sui are considered the two leaders of Move. However, due to inconsistencies in technical concepts, the two companies current Move languages are very different. Overall, Aptos follows the original Diem design more, while Sui has made drastic changes to the design.
Problems that need to be solved for parallel execution:
● State recognition: Optimistic parallel execution. Aptos has developed the Block-STM parallel execution engine, which optimistically executes transactions by default. If a state conflict occurs, it will be re-executed. This technology has been widely accepted, such as Polygon, Monad, Sei, and StarkNet.
● IO improvement: Block-STM uses a multi-version data structure to avoid state conflicts. For example, if the rest of us are writing to a database, then normally we cannot access it because we need to avoid data conflicts, but the multi-version data structure allows us to access past versions. The problem is that this solution will cause huge resource consumption because you need to generate a visible version for each thread.
● Asynchronous execution: Similar to Monad, transaction propagation, transaction ordering, transaction execution, state storage, and block verification are all performed simultaneously.
Currently, Block-STM has been accepted by most public chains, and Monad said that thanks to the emergence of this technology, it can effectively reduce the pressure on developers. However, the problem faced by Aptos is that the intelligence of Block-STM brings about the problem of overly high requirements for nodes. This problem requires specialized hardware and centralization to solve.
Sui
Sui, like Aptos, is inherited from the Diem project. In contrast, Sui uses pessimistic parallelization, strictly verifies the state dependencies between transactions, and adopts a locking mechanism to prevent conflicts during execution. Aptos hopes to reduce the development burden on developers.
● State identification: Unlike Aptosb, it adopts pessimistic parallelization, so developers need to declare their own state access instead of leaving parallel state identification to the system. This increases the development burden of developers, reduces the design complexity of the system, and also increases the parallelization capability.
● IO improvement: IO improvement currently mainly focuses on improving the model. Ethereum uses an account-based model, and each account maintains its data. However, Sui uses the Objects structure instead of the account model. The improvement of this architecture will significantly affect the difficulty of implementing parallelism and peak performance.
Sui has made drastic changes based on the Move system because there are no historical issues with EVM and no compatibility issues. For the account model, it also proposed the innovative idea of Objects. This innovation at the abstract level is actually more difficult. However, its Objects model brings many benefits to parallel processing. It is also because of the Objects model that it has built a very different network architecture, which can be infinitely expanded in theory.
Solana - FireDancer
Solana is considered a pioneer in parallel computing. Solana’s philosophy has always been that blockchain systems should progress with the advancement of hardware. Here is how Solana currently does parallel processing:
● State Awareness: Like SUI, Solana uses a deterministic parallel approach, which comes from Anatoly’s past experience working with embedded systems, where all state is typically declared up front. This enables the CPU to know all dependencies, allowing it to pre-load the necessary parts of memory. The result is optimized system execution, but once again, it requires developers to do extra work up front. On Solana, all memory dependencies of a program are required and declared in constructed transactions (i.e. access lists), allowing the runtime to efficiently schedule and execute multiple transactions in parallel.
● Database: Solana built its own custom account database using Cloudbreak, which uses an account model, with account data distributed across multiple “shards”, similar to dividing a library into several layers, and it can increase or decrease the number of layers as needed to balance the load. It is mapped to memory on the SSD, so the pipeline design allows for fast memory operations on the SSD, while supporting parallel access to multiple data, and can handle 32 IO operations in parallel at the same time.
Solana requires developers to declare the states they need to access through deterministic parallelism, which is indeed similar to the traditional programming situation. In terms of program construction, developers need to build parallel applications themselves, while program scheduling and runtime pipeline asynchronous parallelism are what the project needs to build. In terms of databases, it builds its own DataBase for data parallelism to improve IPOS.
Meanwhile, the subsequent Solana iteration client, Firedancer, was developed by Jump Trading, a quantitative giant with very strong engineering capabilities. It has the same vision as Solana, aiming to eliminate software inefficiencies and push performance to the limits of hardware. Its improvements are mainly aimed at hardware bottom-level improvements, including P2P propagation, hardware SIMD data parallel processing, etc., which is very similar to the idea of MegaETH.
Sei
Sei currently uses
● Optimistic parallel execution: Based on the Block-STM design of Aptos. The Sei V1 version uses a negative parallel solution similar to Sui and Solana, which requires developers to declare the objects to be used themselves, but after Sei V2, it was changed to Aptos optimistic parallel solution. This will be helpful for Sei, which may lack developers, and can more conveniently migrate contracts from the EVM ecosystem.
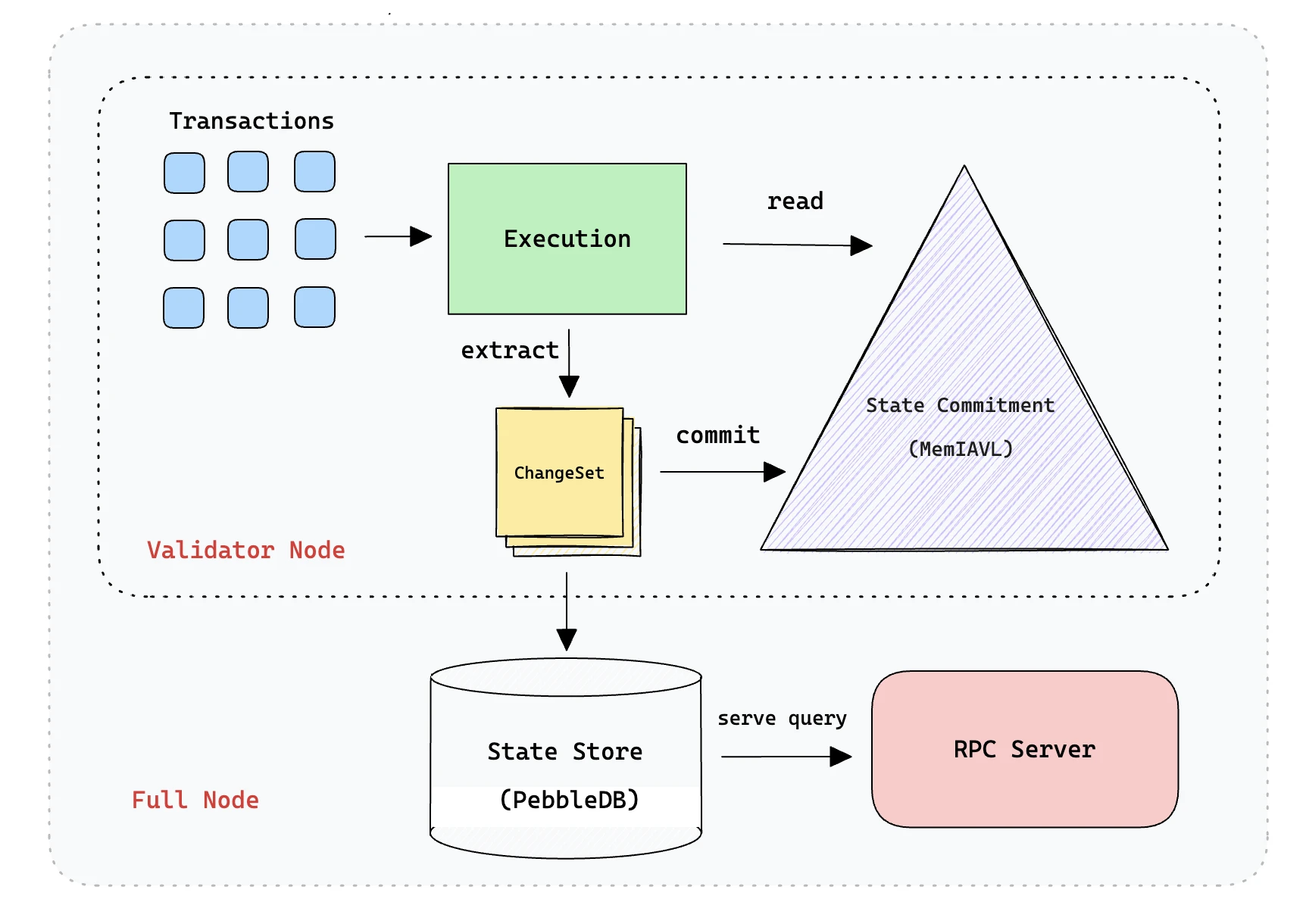
SeiDB design, source: Sei
● SeiDB: The entire database solution is built on the basis of Cosmos ADR-065 proposal. Its entity uses PebbleDB. The data structure is designed to divide the data into active data and historical data. The data in the SSD hard disk is mapped to the data in the memory. At the same time, the SSD data uses the MemIAVL tree structure, and the memory data uses the IAVL tree (invented by Cronos) for state commitment, which is the state root for running consensus. The abstract idea of MemIAVL is that every time a new block is submitted, we will extract all the change sets from the transactions of that block, and then apply these changes to the IAVL tree currently in memory, thereby generating a new version of the tree for the latest block, so that we can obtain the Merkle root hash of the block submission. Therefore, it is equivalent to using memory for hot updates, which can allow most of the state access to be located in memory instead of SSD, thereby improving IOPS.
The main problem with SeiDB is that if the latest active data is stored in memory, data loss may occur during downtime, so MemIAVL introduces WAL files and tree snapshots. Within a certain period of time, the data in memory needs to be snapshotted and stored on the local hard disk, and the snapshot interval is controlled to control the OOM impact of data expansion on memory in a timely manner.
Side-by-side comparison
Full-node Requirement
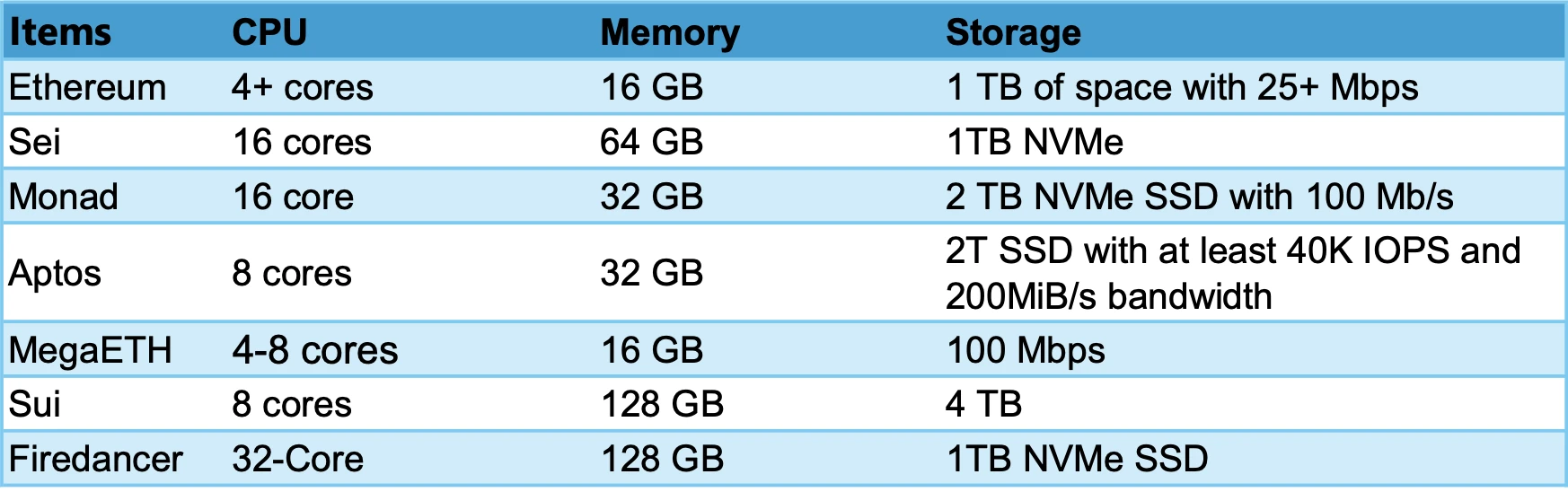
Requirements for running a full node
FireDancer has the highest requirements for node operation and can be called a performance monster. MegaETHs main performance requirements are concentrated on the Sequencer, which requires 100+ cores. Due to the existence of a centralized node sequencer, the requirements for other full nodes are not high. Currently, SSD prices are relatively low, so generally we only need to look at the performance requirements of CPU and Memory. We rank the Full Node performance requirements from high to low: Firedancer > Sei > Monad > Sui > Aptos > MegaETH > Ethereum.
plan
For the current parallel processing solutions, generally speaking, our optimization at the software level is mainly 1. Database IOPS consumption problem 2. State recognition problem 3. Pipeline asynchronous problem. We optimize these three aspects at the software level. State recognition is currently divided into two camps, optimistic parallel execution and declarative programming. Both have advantages and disadvantages. Among them, optimistic parallel execution is mainly based on Aptos Block-STM solution. Its main adopters include Monad and Sei V2, while Sui, Solana, and Sei V1 are all declarative programming, which is more similar to the traditional concurrent or asynchronous programming paradigm. For the problem of database IPOS consumption, the solutions of each company are quite different:
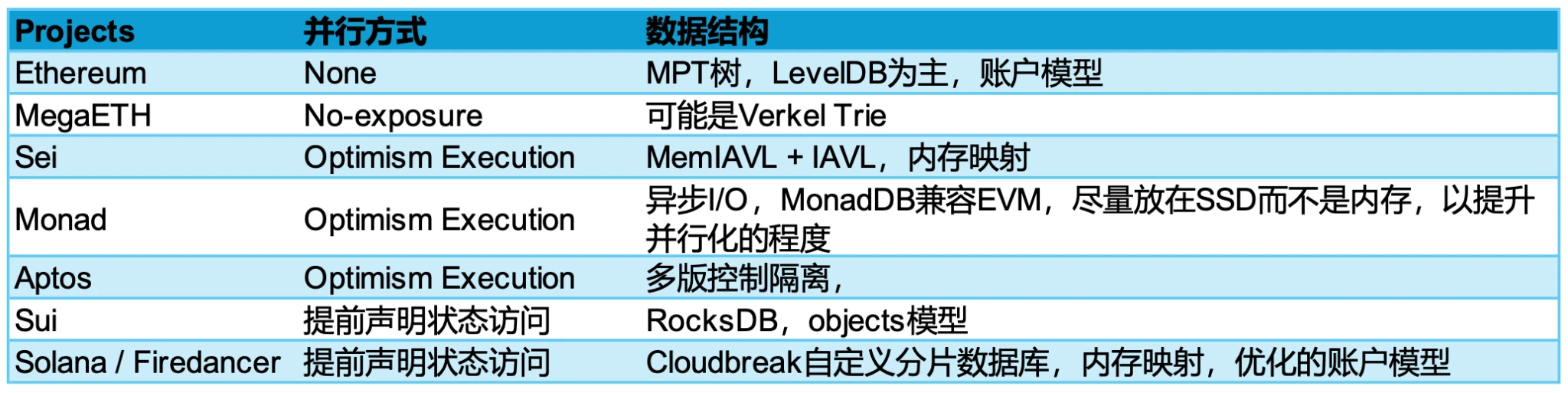
Solution comparison
Regarding the data structure, we see an interesting point. Monad is placed on SSD as much as possible, but the reading speed of the hard disk is much lower than that of the memory, but the price is much cheaper. Monad is placed on SSD considering price, hardware threshold and degree of parallelism, because SSD can now support 32-channel I/O operations, thereby improving more parallel capabilities. On the contrary, Solana and Sei choose memory mapping because the speed of memory is much higher than SSD. One is to expand parallel channels horizontally, and the other is to expand vertically to reduce I/O consumption. This is also the reason why the node requirement of Monad is 32 GB, but Sei and Solana need more memory.
In addition, Ethereums data structure is derived from the Merkel Patric Tree evolved from the Patrci Tree, so an EVM-compatible public chain needs to be compatible with the Merkel Trie. Therefore, it is impossible to build an abstract way to think about assets like Aptos, Sui, Solana, etc. Ethereum is based on an account model, but Sui is an Objects model, Solana is an account model that separates data and code, and Ethereum is indeed coupled together.
Disruptive innovation comes from not compromising with the past. From a business perspective, we do need to consider the developer community and past compatibility. Compatibility with EVM has its pros and cons.
Outlook
The main optimization components of parallel execution currently have relatively clear goals, focusing on how to identify states and how to increase the speed of reading and storing data, because the storage method of these data will cause additional overhead and consumption to read or store a piece of data, especially the Merkel trie introduces the advantage of root verification, but it brings super high IO overhead.
Although parallel execution seems to have expanded the blockchain exponentially, it still has bottlenecks. This bottleneck is inherent in distributed systems, including P2P networks, databases, and other issues. Blockchain computing still has a long way to go to achieve the computing power of traditional computers. At present, parallel execution itself also faces some problems, including the increasingly high hardware requirements for parallel execution, the centralization and censorship risks brought about by the increasing specialization of nodes, and the reliance on memory, central clusters or nodes in mechanism design will also bring downtime risks. At the same time, cross-chain communication between parallel blockchains will also be a problem.
Although there are still some problems with parallel execution, various companies are exploring the best engineering practices, including modular design architectures led by MegaETH and monolithic chain design architectures led by Monad. The current parallel execution optimization schemes have indeed proved that blockchain technology is constantly moving closer to traditional computer optimization schemes, and is being optimized more and more at the bottom level, especially in terms of data storage, hardware, pipelines and other technical aspects. However, there are still bottlenecks and problems in this sentence, so there is still a very broad space for exploration for entrepreneurs.
Disruptive innovation comes from not compromising with the past, and we can’t wait to see more entrepreneurs who are unwilling to compromise build more powerful and interesting products.
Disclaimer:
The above content is for reference only and should not be regarded as any advice. Please always seek professional advice before making any investment.
About Gate Ventures
Gate Ventures is the venture capital arm of Gate.io, focusing on investments in decentralized infrastructure, ecosystems, and applications that will reshape the world in the Web 3.0 era. Gate Ventures works with global industry leaders to empower teams and startups with innovative thinking and capabilities to redefine social and financial interaction models.
Official website: https://ventures.gate.io/ Twitter: https://x.com/gate_ventures Medium: https://medium.com/gate_ventures





