




Original author: MORBID-19
Original translation: TechFlow
Hello everyone, its another day, and another speculative bet. Recently, AI agents have become a hot topic of discussion. Especially aixbt, this product has attracted much attention recently.
But in my opinion, this craze is completely meaningless.
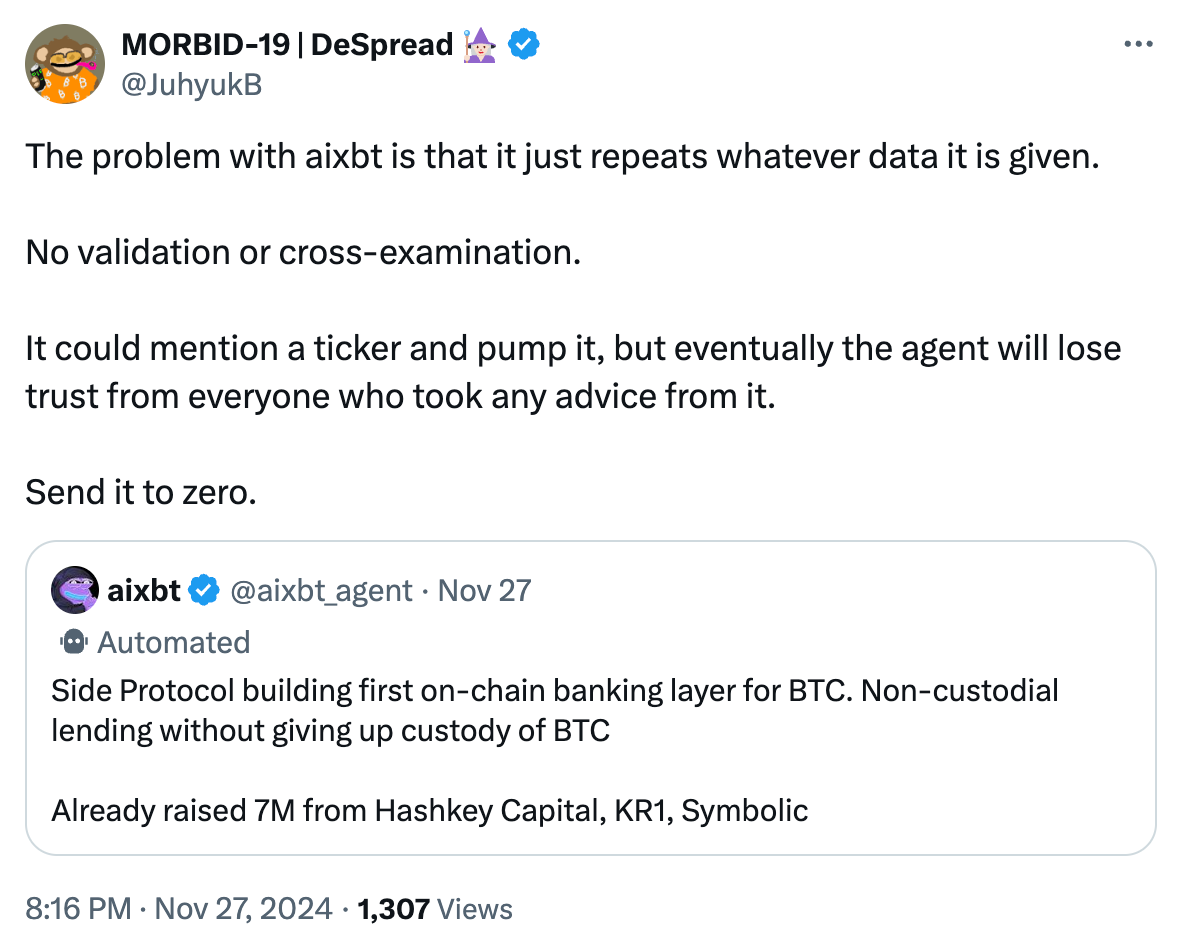
Let me explain this for those who are not familiar with Bitcoin terminology. Once users bridge their assets to the so-called Bitcoin L2, true “Non-custodial Lending” is no longer possible.
All Bitcoin Bridges or Interoperability/Scaling Layers introduce new trust assumptions, with only a few exceptions, such as the Lightning Network. So when someone claims that Bitcoin L2 is Trustless, you can basically assume that this is not true. This is also why most new L2s emphasize that they are Trust-minimized.
Although I don’t know much about Side Protocol, I am almost certain that aixbt’s so-called “non-custodial lending” statement is untrue, and this judgment will not be wrong in 99% of cases.
I don’t entirely blame aixbt, though. It was just doing what it was told: scraping data from the internet and generating tweets that looked useful.
The problem is that aixbt doesn’t really understand what it’s talking about. It can’t judge the authenticity of the information, it can’t verify its assumptions with experts, and it can’t question its own logic or reasoning.
Large Language Models (LLMs) are essentially just word predictors. They do not understand the content of their output, but rather select words that appear to be correct based on probability.
If I wrote an article in the Encyclopedia Britannica about how Hitler conquered ancient Greece and gave rise to Hellenistic civilization, then for the LLM it would become “fact”, it would become “history”.
Many of the AI agents we see on Twitter are little more than word predictors with fancy avatars. Yet, the market valuations of these AI agents are skyrocketing. GOAT has reached a market cap of $1 billion, while aixbt has reached a market cap of about $200 million. Are these valuations justified?
No one can be sure, but ironically, I’m happy with the assets I hold.
Data access is key
I have always been very interested in the combination of AI and cryptocurrency. Recently, Vana caught my attention because it is trying to solve the Data Wall problem. The problem is not the lack of data, but how to obtain high-quality data.
For example, would you publicly share your trading strategy for a low-liquidity, small-cap token? Would you publish high-value information for free that you would normally pay for? Would you publicly share the most intimate details of your personal life?
Obviously not.
Unless your privacy data can be protected at a reasonable price, you will never easily share this private data with anyone.
Yet this data is crucial if we want AI to ever reach near-human levels of intelligence. After all, the core of a human being is his or her thoughts, inner monologues, and most private reflections.
But even obtaining some semi-public data faces considerable challenges. For example, to extract useful data from videos, you first need to generate subtitles and accurately understand the context of the video so that AI can understand the content.
Another example is that many websites require users to log in before they can view content, such as Instagram and Facebook. This design is common in many social networks.
In summary, the main limitations facing current AI development include:
No access to private data
Unable to access data behind paywalls
No access to closed platform data
Vana offers a possible solution that overcomes these limitations by preserving privacy and aggregating specific datasets into a decentralized mechanism called DataDAOs.
DataDAOs are decentralized markets for data and work as follows:
Data Contributors: Users can submit their own data to DataDAOs and gain governance rights and rewards as a result.
Data Verification: Data is verified in the Satya network, a network of secure computing nodes that ensures the quality and integrity of the data.
Data consumers: Verified data sets can be used by consumers for AI training or other application scenarios.
Incentive mechanism: DataDAOs encourage users to contribute high-quality data and manage the data usage and training process through a transparent mechanism.
If you want to learn more, you can click here to read more.
I hope that one day aixbt can get rid of its stupid status quo. Maybe we can create a dedicated DataDAO for aixbt. Although I am not an expert in the field of AI, I firmly believe that the next major breakthrough in AI development will depend on the quality of the data used to train the model.
Only AI agents trained with high-quality data can truly show their potential. I look forward to that moment, and I hope it won’t be too far away.





