





導入
AI 業界の最近の発展は、大規模なモデルの出現により、あらゆる分野の効率が大幅に向上したと見なされている人もいます。ボストン コンサルティング グループは、GPT によって米国の作業効率が向上したと考えています。約20%増加します。同時に、大規模モデルによってもたらされる一般化能力は、新しいソフトウェア設計パラダイムとして歓迎されてきました。これまで、ソフトウェア設計は正確なコードを対象としていましたが、現在では、ソフトウェア設計は、ソフトウェアに組み込まれたより一般化された大規模モデル フレームワークを対象としています。より広範囲のモーダル入力と出力をより適切に表現し、サポートできるようになります。ディープラーニング技術は確かにAI業界に第4次ブームをもたらし、この傾向は暗号通貨業界にも波及しています。
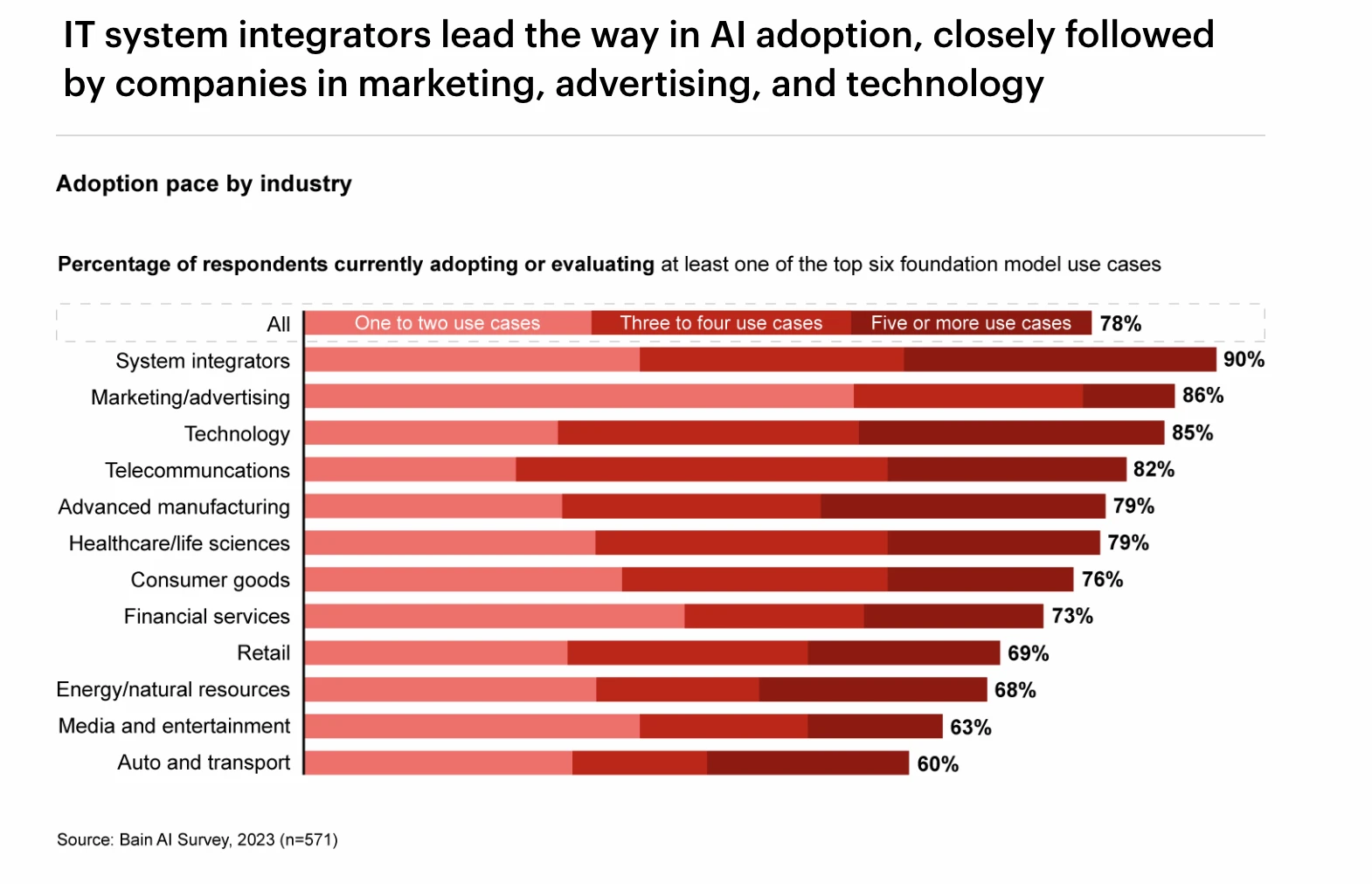
さまざまな業界における GPT 導入率のランキング、出典: Bain AI Survey
このレポートでは、AI業界の発展の歴史、テクノロジーの分類、ディープラーニングテクノロジーの発明が業界に与えた影響について詳しく調査します。次に、ディープラーニングにおける GPU、クラウド コンピューティング、データ ソース、エッジ デバイスなどの業界チェーンの上流と下流、およびその開発状況と傾向を深く分析します。その後、基本的に仮想通貨とAI産業の関係について詳細に議論し、仮想通貨関連のAI産業チェーンのパターンを整理しました。
AI産業の発展の歴史
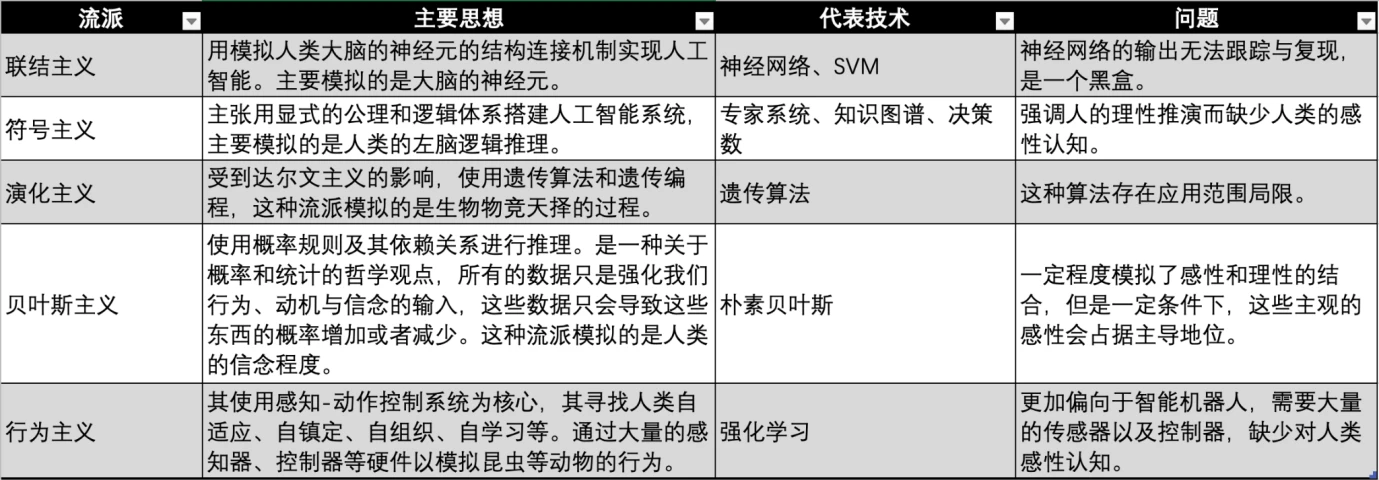
AI 産業は 1950 年代に始まり、人工知能のビジョンを実現するために、学界と産業界は、さまざまな時代や専門分野の背景で人工知能を実現するための多くの学派を開発してきました。
AI ジャンルの比較、出典: Gate Ventures
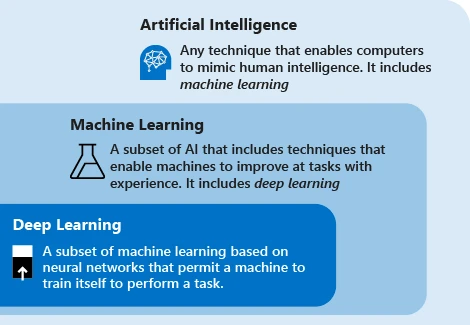
AI/ML/DL の関係、出典: Microsoft
最新の人工知能テクノロジーでは、主に「機械学習」という用語が使用されます。このテクノロジーの考え方は、機械がデータに依存してタスクを繰り返し実行し、システムのパフォーマンスを向上させることです。主な手順は、データをアルゴリズムにフィードし、このデータを使用してモデルをトレーニングし、モデルをテストおよびデプロイし、モデルを使用して自動予測タスクを完了することです。
現在、機械学習には、コネクショニズム、シンボリズム、行動主義という 3 つの主要な学派があり、それぞれ人間の神経系、思考、行動を模倣しています。
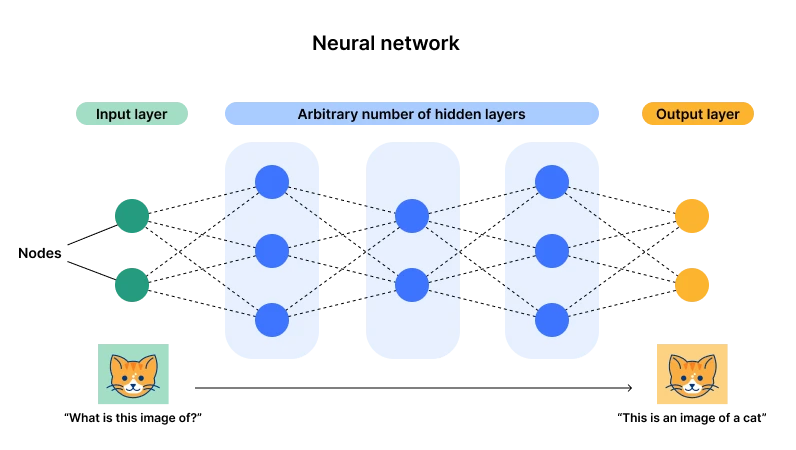
ニューラル ネットワーク アーキテクチャ図、出典: Cloudflare
現在のところ、ニューラル ネットワークに代表されるコネクショニズム (ディープ ラーニングとも呼ばれます) が優勢です。その主な理由は、このアーキテクチャには入力層と出力層がありますが、層とニューロンの数が複数あるためです。パラメータ) ) が十分に大きくなると、複雑な汎用タスクに適合する十分な機会が得られます。データ入力によりニューロンのパラメータを継続的に調整し、複数のデータを経験することでニューロンが最適な状態(パラメータ)に到達するのが、まさに「奇跡」の原点でもあります。 「深さ」という言葉 - 十分な層とニューロン。
たとえば、X=2、Y=5 を入力すると、この関数ですべての X を処理する必要があることがわかります。この関数とそのパラメータの次数は、たとえば、Y = 2 としてこの条件を満たす関数を構築できます。総当たりクラッキングに GPU を使用したデータ ポイントの関数は、Y = であることがわかりました。ここで、X 2 と X、X 0 はすべて異なるニューロンを表し、1、-3、5 はそれらのパラメーターです。
このとき、ニューラル ネットワークに大量のデータを入力すると、ニューロンを追加し、新しいデータに合わせてパラメーターを反復できます。これですべてのデータが適合します。
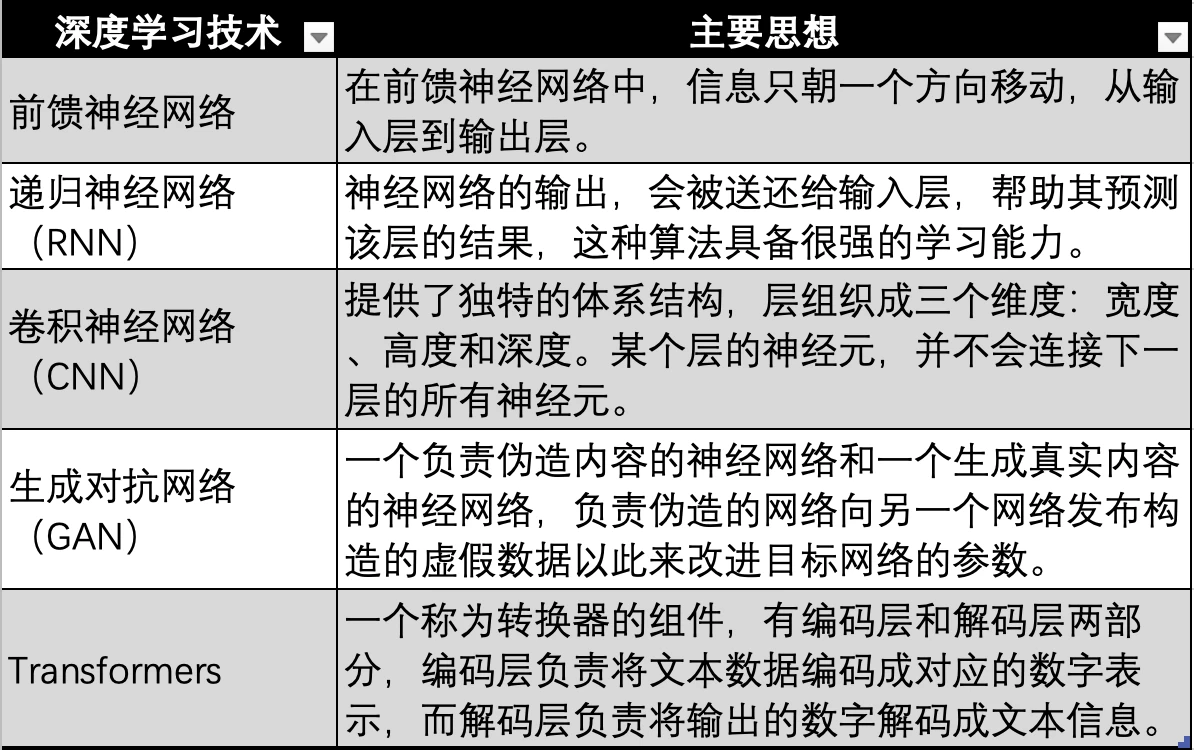
深層学習テクノロジーの進化、出典: Gate Ventures
ニューラル ネットワークに基づくディープ ラーニング テクノロジも、上の図にある最も初期のニューラル ネットワーク、フィードフォワード ニューラル ネットワーク、RNN、CNN、GAN など、技術的な反復と進化を繰り返し、最終的には、次のような最新の大規模モデルで使用される Transformer テクノロジに進化しました。 GPT 、Transformer テクノロジーは、ニューラル ネットワークの進化の方向にすぎず、あらゆるモダリティ (オーディオ、ビデオ、画像など) のデータを対応する数値にエンコードするために使用される追加のコンバーター (Transformer) を追加します。次に、それがニューラル ネットワークに入力されるため、ニューラル ネットワークはあらゆる種類のデータに適合できる、つまりマルチモダリティが実現されます。
AI の発展には 3 つの技術の波がありました。最初の波は、AI 技術が提案されてから 10 年後の 1960 年代に起こり、一般的な自然言語処理と人間機械の問題を解決しました。会話的な質問の処理。同時に、NASA の監督の下でスタンフォード大学によって完成されたエキスパート システムが誕生しました。このシステムは非常に強力な化学知識を持ち、化学の専門家と同じ答えを導き出します。このシステムは、化学知識ベースと推論システムの組み合わせとして見ることができます。
エキスパート システムの後、イスラエル系アメリカ人の科学者で哲学者のジューデア パールは 1990 年代にベイジアン ネットワークを提案しました。これは信念ネットワークとしても知られています。同時に、ブルックスは行動ベースのロボット工学を提案し、行動主義の誕生を告げました。
1997 年、IBM ディープ ブルー「ブルー」がチェスのチャンピオン、カスパロフ 3.5: 2.5 を破りました。この勝利は人工知能のマイルストーンとみなされ、AI テクノロジーは開発の第 2 の頂点を迎えました。
AI テクノロジーの第 3 の波は 2006 年に起こりました。ディープ ラーニングの 3 人の巨人、ヤン ルカン、ジェフリー ヒントン、ヨシュア ベンジオは、データの表現を学習するためのフレームワークとして人工ニューラル ネットワークを使用するアルゴリズムであるディープ ラーニングの概念を提案しました。その後、深層学習アルゴリズムは RNN と GAN から Transformer と Stable Diffusion へと徐々に進化し、これら 2 つのアルゴリズムが共同してこの第 3 のテクノロジーの波を形成しました。これはコネクショニズムの全盛期でもありました。
深層学習テクノロジーの探索と進化に伴い、次のような多くの画期的な出来事が徐々に出現してきました。
● 2011 年、IBM のワトソンがクイズ番組「ジェパディ」で人間を破って優勝しました。
● 2014 年、グッドフェローは、2 つのニューラル ネットワークを互いに競合させて学習し、本物のように見える写真を生成する GAN (敵対的生成ネットワーク) を提案しました。同時に、グッドフェローはフラワーブックと呼ばれる「ディープラーニング」という本も執筆しました。これはディープラーニングの分野における重要な入門書の 1 つです。
● 2015 年、Hinton らは Nature 誌で深層学習アルゴリズムを提案しました。この深層学習手法の提案はすぐに学会や産業界で大きな反響を呼びました。
● 2015年にOpenAIが設立され、マスク氏、YC社長のアルトマン氏、エンジェル投資家のピーター・ティール氏らは10億ドルの共同投資を発表した。
● 2016年、ディープラーニング技術に基づくAlphaGoは、囲碁の世界チャンピオンでプロ棋士のイ・セドル九段と囲碁の人間対機械戦で対戦し、合計スコア4対1で勝利した。
●2017年、中国・香港のハンソンロボティクス社が開発した人型ロボット「ソフィア」は、史上初の一級市民権を獲得したロボットと称され、豊かな表情と人間の言語理解能力を備えています。
● 2017年、人工知能の分野で豊富な人材と技術的余力を有するGoogleが「attention is all you need」という論文を発表し、Transformerアルゴリズムを提案し、大規模な言語モデルが登場し始めた。
● 2018 年、OpenAI は、当時最大の言語モデルの 1 つであった Transformer アルゴリズムに基づく GPT (Generative Pre-trained Transformer) をリリースしました。
● 2018 年、Google チーム Deepmind は、タンパク質の構造を予測できる深層学習に基づく AlphaGo をリリースし、人工知能の分野における大きな進歩の兆しとみなされています。
● 2019 年、OpenAI は 15 億のパラメータを持つモデル GPT-2 をリリースしました。
● 2020 年、OpenAI によって開発された GPT-3 は、前バージョン GPT-2 の 100 倍である 1,750 億個のパラメータを持ち、このモデルはトレーニングに 570 GB のテキストを使用し、複数の NLP (自然言語処理) で使用できます。最先端のパフォーマンスを達成するためのタスク (質問への回答、翻訳、記事の執筆)。
● 2021 年、OpenAI は GPT-4 をリリースしました。このモデルには GPT-3 の 10 倍である 1 兆 7,600 億個のパラメータがあります。
● GPT-4 モデルに基づく ChatGPT アプリケーションは 2023 年 1 月にリリースされました。3 月に ChatGPT はユーザー数 1 億人に達し、史上最速で 1 億ユーザーに達したアプリケーションとなりました。
● 2024 年、OpenAI は GPT-4 オムニを発売します。
ディープラーニング産業チェーン
現在、大規模なモデル言語では、ニューラル ネットワークに基づく深層学習手法が使用されています。 GPT が主導する大規模モデルは、人工知能の流行の波を引き起こし、多くのプレーヤーがこのトラックに流入していることもわかりました。したがって、レポートのこの部分では、私たちは主に、深層学習アルゴリズムが支配する AI 業界における学習アルゴリズムの産業チェーンの深さ、その上流と下流のコンポーネントがどのように構成されているか、現状、需要と供給の関係、将来の発展はどうなっているのかを調査します。上流と下流。

GPT トレーニング パイプライン 出典: WaytoAI
まず、Transformer テクノロジーに基づく GPT に基づいて LLM (大規模モデル) をトレーニングする場合、3 つのステップがあることを明確にする必要があります。
トレーニングの前に、コンバーターは Transformer に基づいているため、テキスト入力を数値に変換する必要があります。このプロセスは「トークン化」と呼ばれ、これらの数値はトークンと呼ばれます。一般的な経験則として、1 つの英語の単語または文字はおおよそ 1 つのトークンと見なすことができ、各漢字はおおよそ 2 つのトークンと見なすことができます。これは、GPT の価格設定に使用される基本単位でもあります。
最初のステップは事前トレーニングです。レポートの最初の部分の (X, Y) の例と同様に、入力層に十分なデータ ペアを与えることで、モデル内の各ニューロンの最適なパラメーターを見つけることができます。これには大量のデータとこのプロセスが必要です。これは、さまざまなパラメーターを試すためにニューロンを繰り返し実行する必要があるため、最も手間のかかるプロセスでもあります。データのバッチがトレーニングされた後、通常、パラメータを反復するための二次トレーニングに同じデータのバッチが使用されます。
2 番目のステップは微調整です。微調整とは、トレーニング用に非常に高品質なデータのより小さなバッチを提供することであり、事前トレーニングには大量のデータが必要ですが、大量のデータにはエラーが含まれる可能性があるため、このような変更によりモデルの出力が高品質になります。または低品質。微調整ステップにより、適切なデータを使用してモデルの品質を向上させることができます。
3番目のステップは学習を強化することです。まず、「報酬モデル」と呼ばれるまったく新しいモデルが構築されます。このモデルの目的は、出力結果を並べ替えることです。したがって、このモデルの実装は比較的簡単です。シナリオは比較的垂直です。このモデルは、大規模モデルの出力が高品質であるかどうかを判断するために使用され、報酬モデルを使用して大規模モデルのパラメーターを自動的に反復できるようになります。 (ただし、モデルの出力品質を判断するために人間の参加が必要になる場合もあります)
つまり、大規模モデルのトレーニング プロセスでは、事前トレーニングにはデータ量に関する要件が非常に高く、GPU コンピューティング パワーを最も消費しますが、微調整にはパラメーターを改善し、学習を強化するために高品質のデータが必要です。報酬モデルを通じて、より高品質の結果を出力します。
トレーニング プロセス中、パラメーターが多いほど、一般化能力の上限が高くなります。たとえば、関数 Y = aX + b の場合、実際には 2 つのニューロン X と X 0 が存在するため、パラメーターは次のようになります。どんなに変化しても本質は直線であるため、適合できるデータは非常に限られています。ニューロンの数が増えると、より多くのパラメーターを反復でき、より多くのデータを当てはめることができるため、大規模モデルが驚異的に機能します。これが、大規模モデルの本質である理由でもあります。そしてデータには膨大なコンピューティング能力が必要です。
したがって、大規模モデルのパフォーマンスは主に 3 つの側面によって決まります。パラメータの数、データの量と質、計算能力です。これら 3 つは共同して大規模モデルの結果の品質と汎化能力に影響します。パラメータの数を p、データ量を n (トークンの数に基づいて計算) と仮定すると、必要な計算量は一般的な経験則に基づいて計算でき、おおよその計算能力を見積もることができます。購入とトレーニング時間が必要です。
計算能力は通常、浮動小数点演算を表す基本単位としてフロップに基づきます。浮動小数点演算は、2.5+3.557 などの非整数値の加算、減算、乗算、除算の総称です。 FP 16 は小数点をサポートすることを意味し、FP 32 は一般的により一般的な精度です。実際の経験則によれば、大規模なモデルを 1 回 (通常は複数回) 事前トレーニングするには約 6 np フロップが必要で、6 は業界定数と呼ばれます。推論 (推論。データを入力して大きなモデルの出力を待つプロセス) は、n 個のトークンの入力と n 個のトークンの出力の 2 つの部分に分かれているため、合計で約 2 np フロップが必要です。
初期には、CPU チップはコンピューティング能力をサポートするトレーニングに使用されていましたが、後に Nvidia の A 100 チップや H 100 チップなどの GPU に置き換えられ始めました。 CPU は汎用コンピューティングとして存在しますが、GPU は専用コンピューティングとして使用できるため、エネルギー消費効率は CPU をはるかに上回ります。 GPU は主に Tensor Core と呼ばれるモジュールを通じて浮動小数点演算を実行します。したがって、一般的なチップには FP 16 / FP 32 精度の Flops データがあり、これはその主要な計算能力を表し、チップの主要な測定指標の 1 つでもあります。
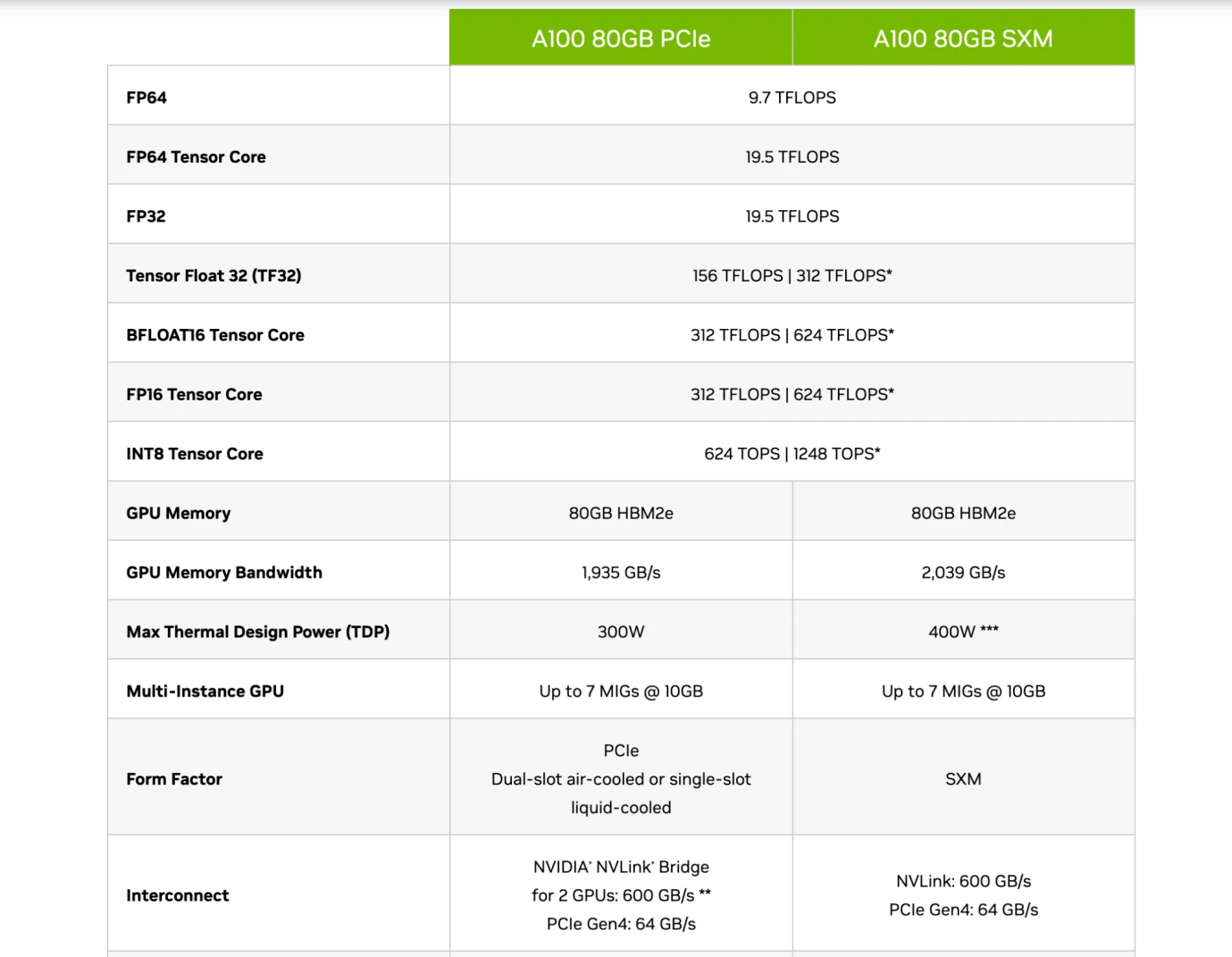
Nvidia A 100 チップの仕様、出典: Nvidia
したがって、読者はこれらの企業のチップの導入を理解できるはずです。上の図に示すように、Nvidia の A 100 80 GB PCIe モデルと SXM モデルを比較すると、PCIe と SXM が Tensor Core (a) の下にあることがわかります。 FP 16 精度では、それぞれ 312 TFLOPS と 624 TFLOPS (トリリオン フロップ) です。
大規模なモデル パラメーターが GPT 3 を例としており、パラメーターが 1,750 億個、データ量が 1,800 億トークン (約 570 GB) であると仮定すると、事前トレーニング中に 6 np フロップが必要となり、これは約 3.15 * 1022 になります。フロップスを TFLOPS (兆 FLOP) で測定すると、約 3.15* 1010 TFLOPS になります。これは、SXM モデル チップが GPT 3 を 1 回事前トレーニングするのに約 50480769 秒、841346 分、14022 時間、および 584 日かかることを意味します。
これは、事前トレーニングを実現するために複数の最先端チップを組み合わせて計算する必要があり、非常に膨大な量の計算であることがわかります。さらに、GPT 4 のパラメータ量は GPT 3 の 10 倍です。つまり、データの量が変わらない場合、チップの数は10倍以上購入する必要があり、GPT-4のトークン数は13兆で、GPT-3の10倍になります。最終的に、GPT-4 は 100 倍を超える計算能力を必要とする可能性があります。
大規模なモデルのトレーニングでは、GPT 3 トークン数などのデータが 1,800 億個あり、約 570 GB のストレージ スペースを占有し、1,750 億個のパラメータを持つ大規模なモデルのニューラル ネットワークが約 700 GB を占有するため、データ ストレージにも問題があります。収納スペース。 GPU のメモリ空間は一般に小さいため (上図に示すように、A100 は 80 GB)、メモリ空間がデータを収容できない場合は、チップの帯域幅、つまり転送速度を検討する必要があります。ハードディスクからメモリへのデータの速度。同時に、1 つのチップだけを使用するわけではないため、複数の GPU チップ上で大規模なモデルを共同でトレーニングする共同学習方法を使用する必要があります。これには、チップ間の GPU の伝送速度が関係します。したがって、多くの場合、最終的なモデル トレーニングの実践を制限する要因またはコストは、必ずしもチップの計算能力ではなく、チップの帯域幅であることがほとんどです。データ転送が遅いため、モデルの実行に時間がかかり、電力コストが増加します。

H 100 SXM チップ仕様、出典: Nvidia
現時点では、読者はチップの仕様をほぼ完全に理解できます。FP 16 は精度を表します。Tensor コア コンポーネントは主に AI LLM のトレーニングに使用されるため、このコンポーネントの計算能力だけを確認する必要があります。 FP 64 Tensor コアは、64 精度で 1 秒あたり 67 TFLOPS を処理できる H 100 SXM を表します。 GPU メモリとは、チップのメモリが 64 GB しかないことを意味し、大規模モデルのデータ ストレージ要件をまったく満たすことができません。したがって、GPU メモリ帯域幅は、H 100 SXM のデータ転送速度を意味します。
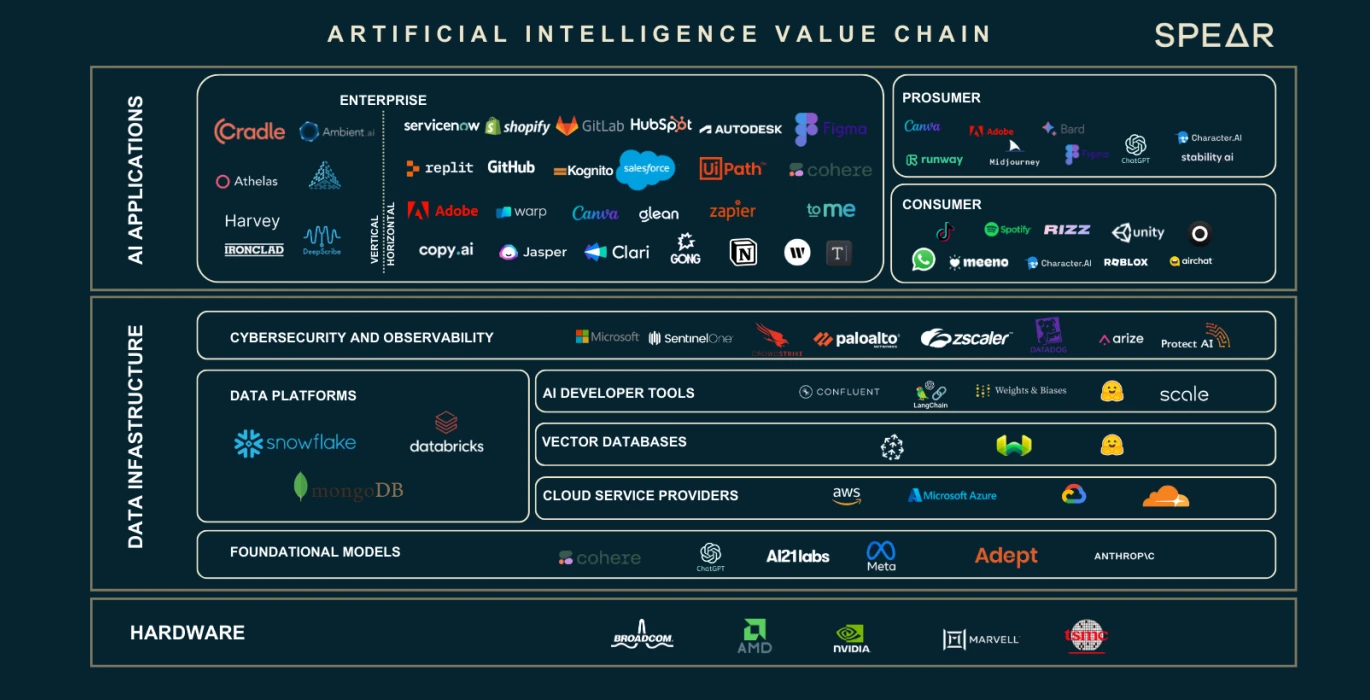
AI バリュー チェーン、出典: Nasdaq
データとニューロン パラメーターの数の拡大により、コンピューティング能力とストレージ要件に大きなギャップが生じていることがわかりました。これら 3 つの主要な要素が産業チェーン全体を育成してきました。上の図を使って、産業チェーンにおける各部分の役割と機能を紹介します。
ハードウェアGPUプロバイダー
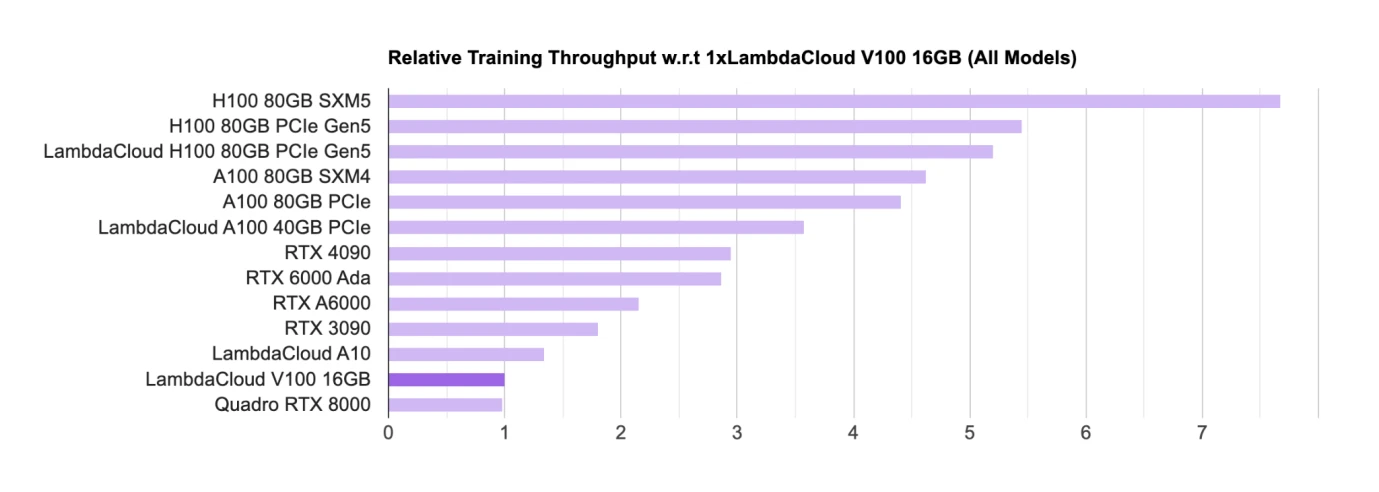
AI GPU チップ ランキング、出典: Lambda
GPU などのハードウェアは現在、トレーニングおよび推論用のメイン チップです。GPU チップの主要な設計者としては、現在、Nvidia が主にコンシューマー レベルの GPU (RTX、メイン) を使用しています。ゲーム用 GPU)、業界では主に大型モデルの商品化に H 100、A 100 などが使用されます。
リストでは、Nvidia のチップがリストをほぼ独占しており、すべてのチップが Nvidia 製です。 Google にも TPU と呼ばれる独自の AI チップがありますが、TPU は主に Google Cloud によって B サイド企業にコンピューティング能力のサポートを提供するために使用されており、一般的には依然として Nvidia GPU を購入する傾向があります。
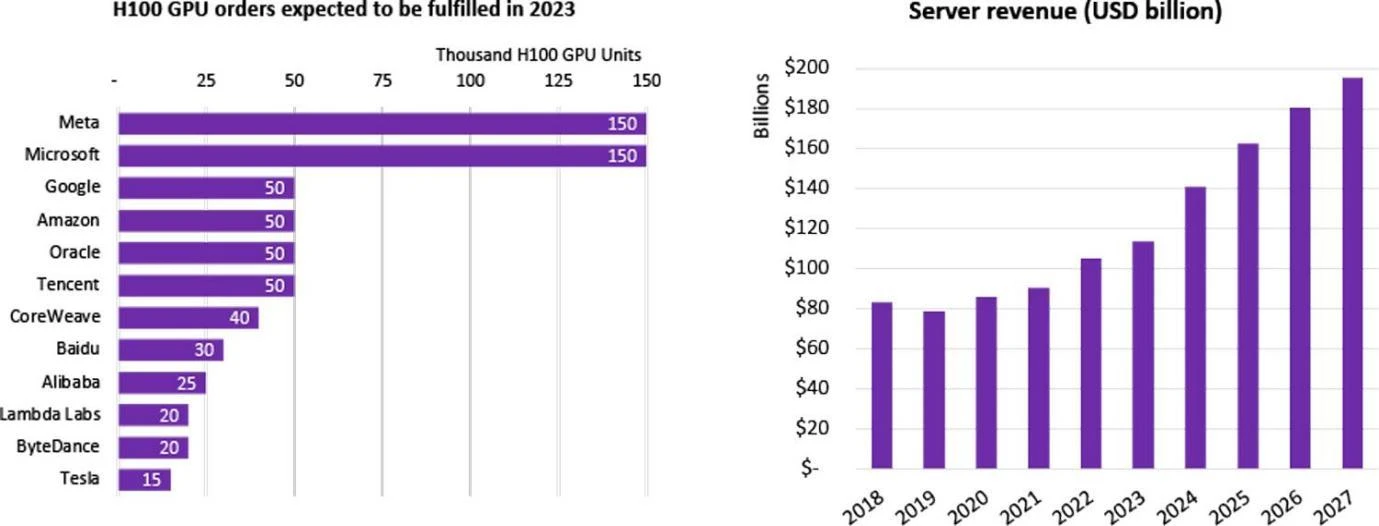
企業別の H 100 GPU 購入統計、出典: Omdia
中国では 100 を超える大規模なモデルを含む多くの企業が LLM の研究開発に着手しており、世界中で合計 200 を超える大規模な言語モデルが発行されており、多くのインターネット大手がこの AI ブームに参加しています。これらの企業は、大型モデルを自社で購入するか、クラウド会社を通じてレンタルします。 2023 年、Nvidia の最先端チップ H 100 は、発売されるとすぐに多くの企業に登録されました。 H 100 チップの世界的な需要は供給をはるかに上回っています。これは、現在 Nvidia のみが最高級チップを供給しており、その出荷サイクルが驚くべき 52 週間に達しているためです。
Nvidia の独占を考慮して、人工知能における絶対的なリーダーの 1 つである Google が主導権を握り、Intel、Qualcomm、Microsoft、Amazon は共同で CUDA Alliance を設立し、GPU に対する Nvidia の絶対的な影響力を排除することを望んでいます。ディープラーニング産業チェーン。
非常に大規模なテクノロジー企業/クラウド サービス プロバイダー/国立研究所の場合、HPC (ハイ パフォーマンス コンピューティング センター) を構築するために数千個または数万個の H 100 チップを購入することがよくあります。たとえば、Tesla の CoreWeave クラスターは 1 万個の H 100 80 GB を購入しました。平均購入価格は 44,000 米ドル (Nvidia のコストは約 10 分の 1)、総コストは 4 億 4,000 万米ドルで、Meta は 2023 年末までに 150,000 個を購入しました。 GPU の販売者である Nvidia は、500,000 個を超える H 100 チップを注文しました。
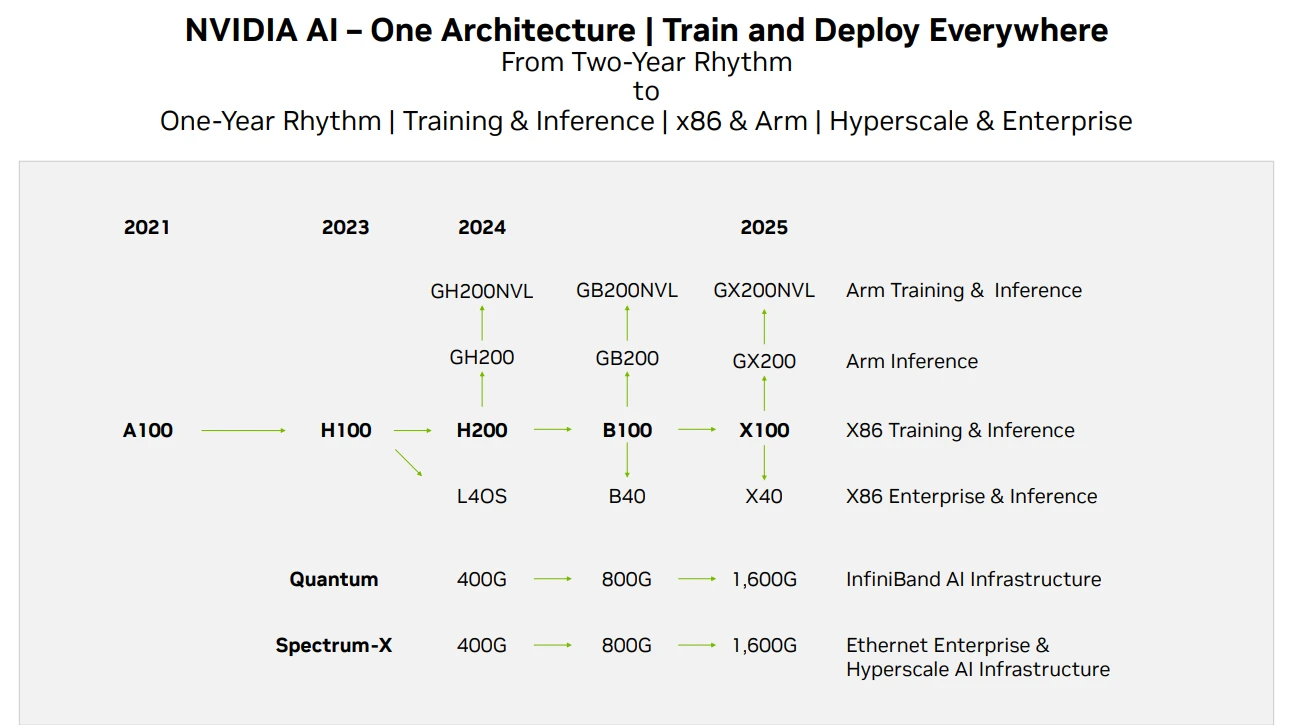
Nvidia GPU 製品ロードマップ、出典: Techwire
Nvidia のチップ供給に関して、上記は製品イテレーション ロードマップです。このレポートの時点で、H 200 のパフォーマンスは H 100 の 2 倍であると予想されています。 100 台は 2024 年末または 2025 年初頭にリリースされる予定です。ロールアウトします。現在の GPU の開発は依然としてムーアの法則を満たしており、性能は 2 年ごとに 2 倍になり、価格は半分に下がります。
クラウドサービスプロバイダー

GPU クラウドの種類、出典: Salesforce Ventures
クラウド サービス プロバイダーは、HPC をセットアップするのに十分な GPU を購入すると、資金が限られている人工知能企業に柔軟なコンピューティング パワーと管理されたトレーニング ソリューションを提供できます。上図に示すように、現在の市場は主に 3 つのタイプのクラウド コンピューティング パワー プロバイダーに分かれています。1 つ目は、従来のクラウド ベンダーに代表されるクラウド コンピューティング パワー プラットフォーム (AWS、Google、Azure) の超大規模な拡大です。 。 2 番目のカテゴリは垂直型クラウド コンピューティング プラットフォームで、主に AI またはハイ パフォーマンス コンピューティング向けに設計されており、より専門的なサービスを提供するため、この種の新興垂直型業界クラウド サービス企業との競争においては一定の市場スペースが存在します。 CoreWeave (シリーズ C 融資で 11 米ドルを受け取り、評価額 190 億米ドル)、Crusoe、Lambda (シリーズ C 融資で 2 億 6,000 万米ドルを受け取り、評価額 15 億米ドル以上) などが含まれます。 3 番目のタイプのクラウド サービス プロバイダーは、新しい市場プレーヤーであり、主にクラウド サービス プロバイダーから GPU をレンタルし、その上に構築します。微調整や推論では、この種の市場の代表的な企業には、Togetter.ai (最新評価額 12 億 5,000 万米ドル)、Fireworks.ai (ベンチマーク主導の投資、シリーズ A 資金調達 2,500 万米ドル) などが含まれます。
トレーニング データ ソースプロバイダー
第 2 部で前述したように、大規模モデルのトレーニングは主に、事前トレーニング、微調整、強化学習という 3 つのステップを経ます。事前トレーニングには大量のデータが必要であり、微調整には高品質のデータが必要となるため、大量のデータを保有する Google や高品質の回答データを保有する Reddit などのデータ企業が広く受け入れています。市場からの注目。
GPT などの汎用的な大規模モデルと競合しないように、細分化された分野での開発を選択する開発者もいます。そのため、データに対する要件は、金融、医療、化学、物理学などの業界固有のデータである必要があります。生物学など 画像認識などこれらは特定の分野のモデルであり、特定の分野のデータを必要とするため、これらの大規模なモデルのデータを提供する会社もあります。これは、データを収集した後にラベルを付けて、より良い品質を提供することを意味します。特定のデータ型。
モデルを開発する企業にとって、大量のデータ、高品質のデータ、特定のデータが 3 つの主要なデータ需要となります。
主要なデータラベル会社、出典: Venture Radar
Microsoft の調査によると、SLM (小規模言語モデル) の場合、データ品質が大規模言語モデルよりも大幅に優れている場合、そのパフォーマンスは必ずしも LLM よりも劣るとは限りません。そして実際、GPT には独創性とデータの点で明らかな利点はなく、主にこの方向に賭ける大胆さが成功に貢献しています。 Sequoia America はまた、GPT が将来的に必ずしも競争上の優位性を維持できるわけではないことを認めました。その理由は、現時点ではこの分野に深い堀がなく、主な制限はコンピューティング能力の獲得の限界にあるからです。
データ量に関しては、EpochAIの予測によると、現在のモデル規模の拡大に応じて、低品質データと高品質データは2030年までにすべて枯渇するとのことです。したがって、業界は現在、無制限のデータを生成できるように人工知能の合成データを探索していますが、ボトルネックとなるのはコンピューティング能力だけであり、この方向性はまだ探索段階にあり、開発者の注目に値します。
データベースプロバイダー
データはありますが、データの追加、削除、変更、検索を容易にするために、通常はデータベースにデータを保存する必要もあります。従来のインターネット ビジネスでは、MySQL について聞いたことがあるかもしれません。また、イーサリアム クライアントである Reth については、Redis について聞いたことがあるかもしれません。これらは、ビジネス データまたはブロックチェーン上のデータを保存するローカル データベースです。データの種類やビジネスごとにデータベースの適応方法が異なります。
AI データやディープラーニングのトレーニング推論タスクのために、現在業界で使用されているデータベースは「ベクター データベース」と呼ばれます。ベクトル データベースは、大量の高次元ベクトル データを効率的に保存、管理、インデックス付けできるように設計されています。私たちのデータは単なる数値やテキストではなく、画像や音声などの膨大な非構造化データであるため、ベクトルデータベースはこれらの非構造化データを「ベクトル」の形で保存することができ、ベクトルデータベースはこれらのベクトルの保存と処理に適しています。

ベクター データベースの分類、出典: Yingjun Wu
現在の主要プレーヤーには、Chroma (1,800 万ドルの資金調達を受けた)、Zilliz (最新の資金調達ラウンドは 6,000 万ドル)、Pinecone、Weaviate などが含まれます。データ量の需要の増加と、さまざまなニッチ分野での大規模なモデルやアプリケーションの急増により、Vector Database の需要が大幅に増加すると予想されます。そして、この分野には強い技術的障壁があるため、投資する際には成熟し顧客を抱える企業がさらに考慮されることになる。
エッジデバイス
GPU HPC (ハイパフォーマンス コンピューティング クラスター) を構築する場合、通常、大量のエネルギーが消費され、高温環境ではチップは温度を下げるために動作速度を制限します。これは一般に「周波数削減」と呼ばれるもので、HPC の継続的な動作を保証するためにいくつかの冷却エッジ デバイスが必要です。
したがって、ここでは産業チェーンの 2 つの方向、つまりエネルギー供給 (通常は電気エネルギーを使用) と冷却システムが関係します。
現在、エネルギー供給面では電力が主に使用されており、データセンターとサポートネットワークが世界の電力消費量の2%~3%を占めています。 BCG は、大規模な深層学習モデルのパラメーターが増加し、チップが反復されるため、大規模なモデルのトレーニングに必要な電力が 2030 年までに 3 倍になると予測しています。現在、国内外のテクノロジーメーカーがエネルギー企業に積極的に投資を行っており、主なエネルギー投資の方向性としては、地熱エネルギー、水素エネルギー、蓄電池、原子力などが挙げられます。
HPC クラスターの冷却に関しては、現在空冷が主流ですが、多くの VC は HPC のスムーズな動作を維持するために液体冷却システムに多額の投資を行っています。たとえば、Jetcool は、その液体冷却システムにより H 100 クラスターの総電力消費量を 15% 削減できると主張しています。現在、液体冷却は主にコールドフォーマット液体冷却、浸漬液体冷却、スプレー液体冷却の 3 つの探査方向に分かれています。この分野の企業には、Huawei、Green Revolution Cooling、SGI などが含まれます。
応用
現在の AI アプリケーションの開発は、革新的な産業としてのブロックチェーン産業の発展と似ています。Transformer は 2017 年に提案され、OpenAI は 2023 年に大規模モデルの有効性を確認したばかりです。そのため現在、多くの Fomo 企業が大規模モデルの研究開発トラックにひしめき合っています。つまり、インフラストラクチャは非常に混雑していますが、アプリケーションの開発が追いついていません。

月間アクティブ ユーザーのトップ 50、出典: A16Z
現在、最初の 10 か月間でアクティブな AI アプリケーションのほとんどは検索タイプのアプリケーションであり、実際に登場した AI アプリケーションはまだ非常に限られており、ソーシャル アプリケーションやその他のタイプのアプリケーションはありません。無事出現しました。
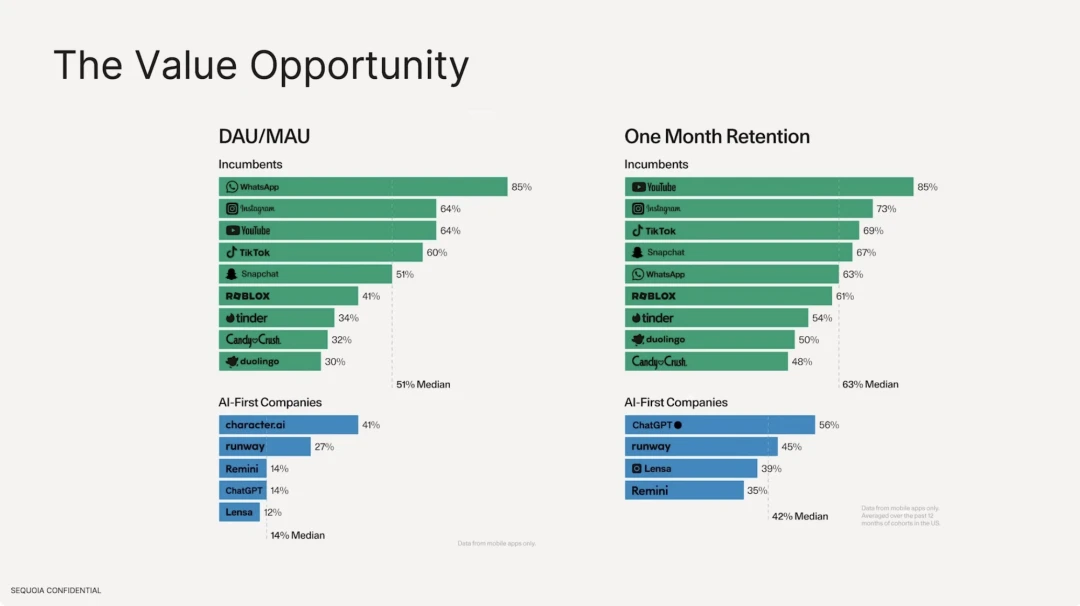
また、大規模なモデルに基づく AI アプリケーションの保持率は、既存の従来のインターネット アプリケーションの保持率よりもはるかに低いこともわかりました。アクティブ ユーザー数に関しては、従来のインターネット ソフトウェアの中央値は 51% で、最も高いのはユーザーの粘着力が強い Whatsapp です。しかし、AI アプリケーション側では、最も高い DAU/MAU はcharacter.ai であり、これはわずか 41% であり、DAU は総ユーザー数の中央値の 14% を占めています。ユーザー維持率に関して言えば、従来のインターネット ソフトウェアで最も優れているのは Youtube、Instagram、Tiktok であり、トップ 10 の維持率の中央値は 63% であるのに対し、ChatGPT の維持率はわずか 56% です。

AI アプリケーションの状況、出典: Sequoia
Sequoia America のレポートによると、アプリケーションを役割指向の観点から、専門消費者、企業、一般消費者の 3 つのカテゴリに分類しています。
1. 消費者指向: 一般的に、QA に GPT を使用するテキスト ワーカー、自動 3D レンダリング モデリング、ソフトウェア編集、自動エージェント、および音声会話、コンパニオンシップ、言語演習などのための音声タイプのアプリケーションなど、生産性を向上させるために使用されます。
2. 企業向け: 通常、マーケティング、法律、医療デザイン、その他の業界。
現在、インフラストラクチャはアプリケーションよりもはるかに優れていると多くの人が批判していますが、実際には、現代の世界は人工知能テクノロジーによって広く再形成されていると考えられていますが、人工知能テクノロジーでは、TikTok、Toutiao、ByteDance Music の Soda などのレコメンデーション システムが使用されています。小紅書やWeChatのビデオアカウント、広告レコメンデーションテクノロジーなどはすべて個人向けにカスタマイズされたレコメンデーションであり、これらはすべて機械学習アルゴリズムです。したがって、現在ブームとなっているディープラーニングはAI業界を完全に代表するものではありません。一般的な人工知能を実現する可能性のある多くの潜在的な技術が並行して開発されており、それらの技術のいくつかはさまざまな業界で広く使用されています。 。
では、仮想通貨とAIの間にはどのような関係が生まれるのでしょうか?仮想通貨業界のバリューチェーンにおいて、他に注目に値するプロジェクトは何ですか? 「Gate Ventures:初心者からマスターまでAI×暗号(後編)」で一つ一つ解説していきます。
免責事項:
上記の内容は参考用であり、アドバイスとして考慮されるべきではありません。投資する前に必ず専門家のアドバイスを求めてください。
ゲートベンチャーズについて
Gate Venturesは Gate.io のベンチャー キャピタル部門で、Web 3.0 時代に世界を再構築する分散型インフラストラクチャ、エコシステム、アプリケーションへの投資に重点を置いています。 Gate Ventures は世界的な業界リーダーと協力して、社会と金融の相互作用モデルを再定義する革新的な思考と能力をチームやスタートアップに与えます。
公式サイト: https://ventures.gate.io/
Twitter: https://x.com/gate_ventures





