




ผู้เขียนต้นฉบับ: เกรซ แอนด์ ฮิลล์
ขอขอบคุณ Brian Retford, SunYi, Jason Morton, Shumo, Feng Boyuan, Daniel, Aaron Greenblatt, Nick Matthew, Baz, Marcin และ Brent สำหรับข้อมูลเชิงลึก ข้อเสนอแนะ และบทวิจารณ์อันมีค่าของบทความนี้

สำหรับผู้ที่ชื่นชอบ crypto อย่างพวกเรา ปัญญาประดิษฐ์เป็นประเด็นที่ได้รับความนิยมมาระยะหนึ่งแล้ว ที่น่าสนใจคือไม่มีใครอยากเห็น AI วิ่งอาละวาด ความตั้งใจดั้งเดิมของการประดิษฐ์บล็อคเชนคือการป้องกันไม่ให้เงินดอลลาร์หลุดออกจากการควบคุม ดังนั้นเราอาจพยายามป้องกันไม่ให้ปัญญาประดิษฐ์หลุดออกจากการควบคุม นอกจากนี้ ขณะนี้เรามีเทคโนโลยีใหม่ที่เรียกว่าการพิสูจน์ความรู้เป็นศูนย์เพื่อให้แน่ใจว่าสิ่งต่างๆ จะไม่ผิดพลาด อย่างไรก็ตาม เพื่อควบคุมสัตว์ร้ายที่เป็น AI เราต้องเข้าใจว่ามันทำงานอย่างไร
ข้อมูลเบื้องต้นเกี่ยวกับการเรียนรู้ของเครื่อง
ปัญญาประดิษฐ์ได้ผ่านการเปลี่ยนชื่อหลายครั้ง ตั้งแต่ ระบบผู้เชี่ยวชาญ เป็น โครงข่ายประสาทเทียม จากนั้นเป็น แบบจำลองกราฟิก และสุดท้ายเป็น การเรียนรู้ของเครื่อง ทั้งหมดนี้เป็นส่วนย่อยของ “ปัญญาประดิษฐ์” ที่ได้รับการตั้งชื่อที่แตกต่างกัน และความเข้าใจของเราเกี่ยวกับ AI ยังคงเติบโตอย่างต่อเนื่อง มาเจาะลึกการเรียนรู้ของเครื่องและทำความเข้าใจให้ลึกซึ้งยิ่งขึ้น

หมายเหตุ: ปัจจุบัน โมเดลการเรียนรู้ของเครื่องส่วนใหญ่เป็นโครงข่ายประสาทเทียม เนื่องจากมีประสิทธิภาพที่เหนือกว่าในหลาย ๆ งาน เราเรียกการเรียนรู้ของเครื่องเป็นหลักว่าการเรียนรู้ของเครื่องเครือข่ายประสาทเทียม
แมชชีนเลิร์นนิงทำงานอย่างไร
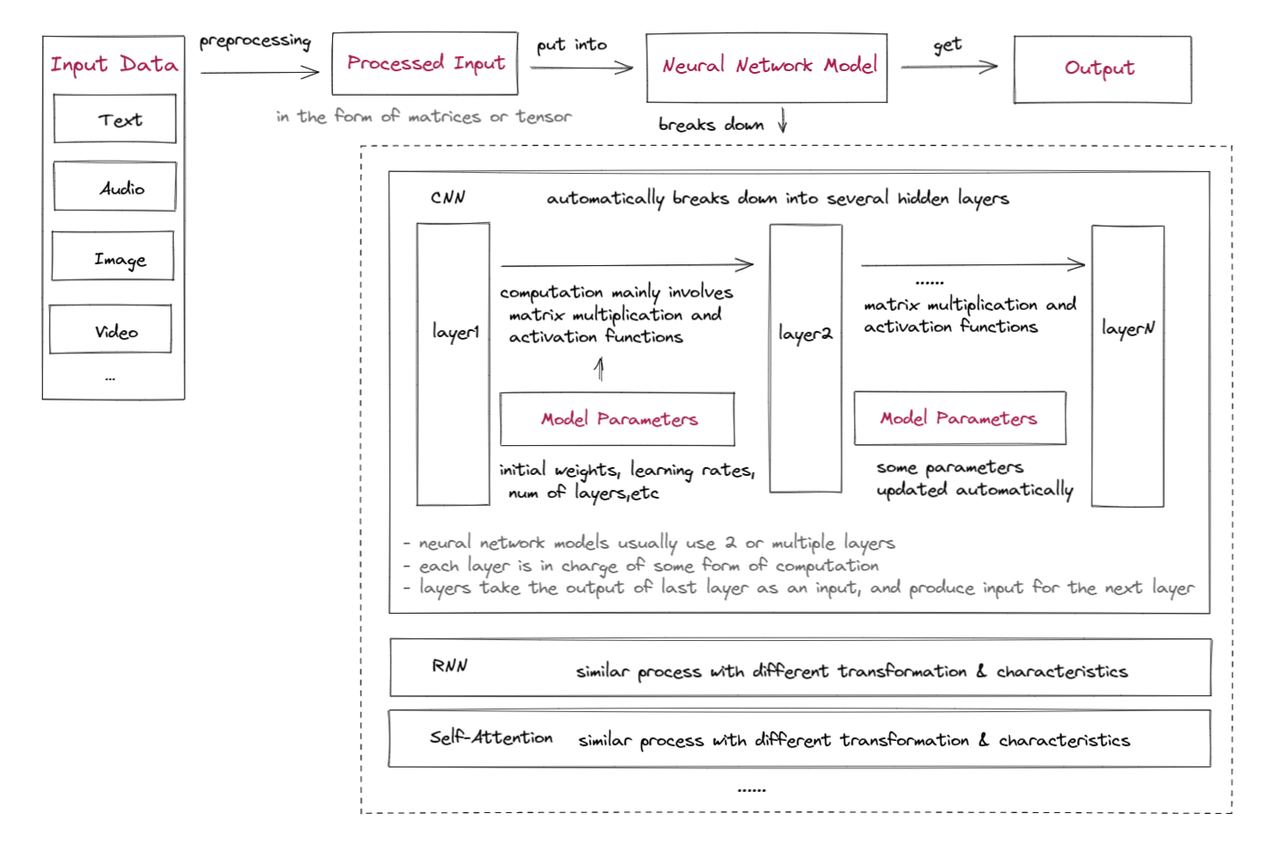 ก่อนอื่น มาดูการทำงานภายในของการเรียนรู้ของเครื่องกันก่อน:
ก่อนอื่น มาดูการทำงานภายในของการเรียนรู้ของเครื่องกันก่อน:
ป้อนข้อมูลการประมวลผลล่วงหน้า:
ข้อมูลอินพุตจะต้องได้รับการประมวลผลเป็นรูปแบบที่สามารถใช้เป็นอินพุตให้กับโมเดลได้ ซึ่งมักจะเกี่ยวข้องกับการประมวลผลล่วงหน้าและวิศวกรรมคุณลักษณะเพื่อดึงข้อมูลที่เป็นประโยชน์และแปลงข้อมูลให้อยู่ในรูปแบบที่เหมาะสม เช่น เมทริกซ์อินพุตหรือเทนเซอร์ (เมทริกซ์มิติสูง) นี่คือแนวทางของระบบผู้เชี่ยวชาญ ด้วยการมาถึงของการเรียนรู้เชิงลึก เลเยอร์การประมวลผลจะจัดการการประมวลผลล่วงหน้าโดยอัตโนมัติ
ตั้งค่าพารามิเตอร์โมเดลเริ่มต้น:
พารามิเตอร์โมเดลเริ่มต้นประกอบด้วยหลายเลเยอร์ ฟังก์ชันการเปิดใช้งาน น้ำหนักเริ่มต้น อคติ อัตราการเรียนรู้ ฯลฯ พารามิเตอร์บางตัวสามารถปรับได้ด้วยอัลกอริธึมการปรับให้เหมาะสมระหว่างการฝึกเพื่อปรับปรุงความแม่นยำของโมเดล
ข้อมูลการฝึกอบรม:
ข้อมูลอินพุตจะถูกป้อนเข้าสู่โครงข่ายประสาทเทียม โดยทั่วไปจะเริ่มต้นด้วยการแยกคุณลักษณะอย่างน้อยหนึ่งเลเยอร์และเลเยอร์การสร้างแบบจำลองความสัมพันธ์ เช่น เลเยอร์แบบหมุนวน (CNN) เลเยอร์ที่เกิดซ้ำ (RNN) หรือเลเยอร์การเอาใจใส่ตนเอง เลเยอร์เหล่านี้เรียนรู้ที่จะแยกคุณลักษณะที่เกี่ยวข้องออกจากข้อมูลอินพุตและสร้างแบบจำลองความสัมพันธ์ระหว่างคุณลักษณะเหล่านี้
ผลลัพธ์ของเลเยอร์เหล่านี้จะถูกส่งไปยังเลเยอร์เพิ่มเติมหนึ่งเลเยอร์ขึ้นไป ซึ่งทำการคำนวณและการแปลงข้อมูลอินพุตที่แตกต่างกัน เลเยอร์เหล่านี้มักเกี่ยวข้องกับการคูณเมทริกซ์ของเมทริกซ์น้ำหนักที่เรียนรู้ได้เป็นหลัก และการประยุกต์ใช้ฟังก์ชันการเปิดใช้งานแบบไม่เชิงเส้น แต่ยังอาจรวมถึงการดำเนินการอื่นๆ เช่น การบิดและการรวมกลุ่มในโครงข่ายประสาทเทียมแบบบิด หรือการวนซ้ำในโครงข่ายประสาทที่เกิดซ้ำ ผลลัพธ์ของเลเยอร์เหล่านี้ทำหน้าที่เป็นอินพุตไปยังเลเยอร์ถัดไปในโมเดล หรือเป็นเอาต์พุตที่คาดการณ์ขั้นสุดท้าย
รับผลลัพธ์ของโมเดล:
ผลลัพธ์ของการคำนวณโครงข่ายประสาทเทียมมักเป็นเวกเตอร์หรือเมทริกซ์ที่แสดงถึงความน่าจะเป็นของการจัดประเภทภาพ คะแนนการวิเคราะห์ความรู้สึก หรือผลลัพธ์อื่นๆ ขึ้นอยู่กับการใช้งานของเครือข่าย โดยปกติแล้วยังมีโมดูลการประเมินข้อผิดพลาดและการอัปเดตพารามิเตอร์ที่อัปเดตพารามิเตอร์โดยอัตโนมัติตามวัตถุประสงค์ของโมเดล
หากคำอธิบายข้างต้นดูคลุมเครือเกินไป คุณสามารถดูตัวอย่างการใช้โมเดล CNN เพื่อระบุรูปภาพ Apple ต่อไปนี้
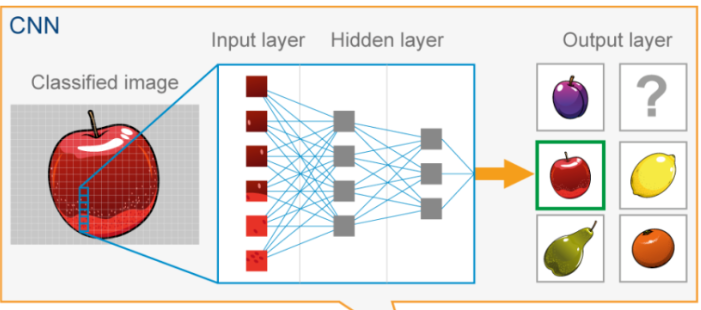
โหลดรูปภาพลงในโมเดลเป็นเมทริกซ์ของค่าพิกเซล เมทริกซ์นี้สามารถแสดงเป็นเทนเซอร์ 3 มิติที่มีขนาด (ความสูง ความกว้าง ช่อง)
ตั้งค่าพารามิเตอร์เริ่มต้นของโมเดล CNN
รูปภาพอินพุตจะถูกส่งผ่านเลเยอร์ที่ซ่อนอยู่หลายชั้นใน CNN โดยแต่ละเลเยอร์จะใช้ฟิลเตอร์แบบหมุนวนเพื่อแยกคุณสมบัติที่ซับซ้อนมากขึ้นจากรูปภาพ ผลลัพธ์ของแต่ละเลเยอร์จะถูกส่งผ่านฟังก์ชันการเปิดใช้งานแบบไม่เชิงเส้น จากนั้นจึงรวมกลุ่มเพื่อลดมิติของแผนผังคุณลักษณะ โดยปกติเลเยอร์สุดท้ายจะเป็นเลเยอร์ที่เชื่อมต่อกันอย่างสมบูรณ์ซึ่งสร้างการคาดการณ์เอาต์พุตตามคุณสมบัติที่แยกออกมา
ผลลัพธ์สุดท้ายของ CNN คือคลาสที่มีความน่าจะเป็นสูงสุด นี่คือป้ายกำกับที่คาดการณ์ของภาพที่ป้อน
กรอบงานความน่าเชื่อถือสำหรับการเรียนรู้ของเครื่อง
เราสามารถสรุปสิ่งที่กล่าวมาข้างต้นเป็นเฟรมเวิร์กความน่าเชื่อถือของ Machine Learning รวมถึง Machine Learning พื้นฐาน 4 ชั้น กระบวนการ Machine Learning ทั้งหมดต้องการให้เลเยอร์เหล่านี้เชื่อถือได้จึงจะเชื่อถือได้:
ข้อมูลเข้า: ข้อมูลดิบจำเป็นต้องได้รับการประมวลผลล่วงหน้าและบางครั้งก็ถูกเก็บเป็นความลับ
ความสมบูรณ์: ข้อมูลอินพุตไม่ได้ถูกแก้ไข ไม่มีการปนเปื้อนจากอินพุตที่เป็นอันตราย และได้รับการประมวลผลล่วงหน้าอย่างถูกต้อง
ความเป็นส่วนตัว: ข้อมูลที่ป้อนจะไม่ถูกเปิดเผยหากจำเป็น
ผลลัพธ์: จำเป็นต้องสร้างและส่งอย่างแม่นยำ
ความสมบูรณ์: ผลลัพธ์ถูกสร้างขึ้นอย่างถูกต้อง
ความเป็นส่วนตัว: เอาต์พุตจะไม่รั่วไหลหากจำเป็น
ประเภทโมเดล/อัลกอริทึม: ควรคำนวณโมเดลอย่างถูกต้อง
ความสมบูรณ์: โมเดลทำงานได้อย่างถูกต้อง
ความเป็นส่วนตัว: ตัวโมเดลหรือการคำนวณจะไม่รั่วไหลหากจำเป็น
โมเดลโครงข่ายประสาทเทียมที่ต่างกันมีอัลกอริธึมและเลเยอร์ที่แตกต่างกันซึ่งเหมาะสำหรับกรณีการใช้งานและอินพุตที่แตกต่างกัน
โครงข่ายประสาทเทียมแบบหมุนวน (CNN) มักใช้สำหรับงานที่เกี่ยวข้องกับข้อมูลคล้ายตาราง เช่น รูปภาพ ซึ่งสามารถบันทึกรูปแบบและคุณสมบัติเฉพาะที่ได้โดยการใช้การดำเนินการแบบหมุนวนกับขอบเขตอินพุตขนาดเล็ก
ในทางกลับกัน โครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN) เหมาะอย่างยิ่งสำหรับข้อมูลตามลำดับ เช่น อนุกรมเวลาหรือภาษาธรรมชาติ ซึ่งสถานะที่ซ่อนอยู่สามารถรวบรวมข้อมูลจากขั้นตอนเวลาก่อนหน้าและสร้างแบบจำลองการพึ่งพาชั่วคราวได้
เลเยอร์การเอาใจใส่ตนเองมีประโยชน์สำหรับการจับความสัมพันธ์ระหว่างองค์ประกอบในลำดับอินพุต ทำให้มีประสิทธิภาพสำหรับงานต่างๆ เช่น การแปลด้วยคอมพิวเตอร์ หรือการสรุป ซึ่งการพึ่งพาระยะยาวเป็นสิ่งสำคัญ
ยังมีแบบจำลองประเภทอื่นๆ อยู่ด้วย รวมถึง Multilayer Perceptrons (MLP) และอื่นๆ
พารามิเตอร์โมเดล: ในบางกรณี พารามิเตอร์ควรมีความโปร่งใสหรือสร้างขึ้นตามระบอบประชาธิปไตย แต่ในทุกกรณีจะต้องไม่เสี่ยงต่อการถูกปลอมแปลง
ความสมบูรณ์: พารามิเตอร์ถูกสร้างขึ้น ดูแลรักษา และจัดการด้วยวิธีที่ถูกต้อง
ความเป็นส่วนตัว: เจ้าของโมเดลมักจะเก็บพารามิเตอร์โมเดลการเรียนรู้ของเครื่องไว้เป็นความลับเพื่อปกป้องทรัพย์สินทางปัญญาและความได้เปรียบทางการแข่งขันขององค์กรที่พัฒนาโมเดล ปรากฏการณ์นี้เป็นเรื่องปกติจนกระทั่งโมเดลหม้อแปลงมีราคาแพงมากในการฝึกอบรม แต่ก็ยังเป็นปัญหาสำคัญสำหรับอุตสาหกรรม
ปัญหาความน่าเชื่อถือในการเรียนรู้ของเครื่อง
ด้วยการเติบโตอย่างรวดเร็วของแอปพลิเคชันแมชชีนเลิร์นนิง (ML) (CAGR มากกว่า 20%) และการบูรณาการที่เพิ่มมากขึ้นในชีวิตประจำวัน เช่น ความนิยมล่าสุดของ ChatGPT ปัญหาความไว้วางใจใน ML จึงมีความสำคัญมากขึ้นเรื่อยๆ ไม่สามารถเพิกเฉยได้ ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องระบุและแก้ไขปัญหาความน่าเชื่อถือเหล่านี้เพื่อให้แน่ใจว่ามีการใช้ AI อย่างมีความรับผิดชอบ และป้องกันการใช้งานในทางที่ผิดที่อาจเกิดขึ้น อย่างไรก็ตาม ปัญหาคืออะไร? มาดูกันดีกว่า

ความโปร่งใสหรือพิสูจน์ได้ไม่เพียงพอ
ปัญหาด้านความน่าเชื่อถือรบกวนการเรียนรู้ของเครื่องจักรมายาวนานด้วยเหตุผลหลักสองประการ:
ลักษณะความเป็นส่วนตัว: ตามที่กล่าวไว้ข้างต้น พารามิเตอร์โมเดลมักจะเป็นแบบส่วนตัว และในบางกรณี อินพุตโมเดลจำเป็นต้องถูกเก็บไว้เป็นส่วนตัวเช่นกัน ซึ่งจะสร้างปัญหาความเชื่อถือระหว่างเจ้าของโมเดลและผู้ใช้โมเดลโดยธรรมชาติ
กล่องดำอัลกอริธึม: โมเดลการเรียนรู้ของเครื่องบางครั้งเรียกว่า กล่องดำ เนื่องจากเกี่ยวข้องกับขั้นตอนอัตโนมัติหลายขั้นตอนในการคำนวณที่ยากต่อการเข้าใจหรืออธิบาย ขั้นตอนเหล่านี้เกี่ยวข้องกับอัลกอริธึมที่ซับซ้อนและข้อมูลจำนวนมาก ส่งผลให้เกิดผลลัพธ์ที่ไม่แน่นอนและบางครั้งก็สุ่ม ทำให้อัลกอริธึมเสี่ยงต่อการถูกกล่าวหาว่ามีอคติหรือแม้แต่การเลือกปฏิบัติ
ก่อนที่จะไปไกลกว่านี้ ข้อสันนิษฐานที่สำคัญประการหนึ่งของบทความนี้ก็คือโมเดลนั้น พร้อมใช้งาน ซึ่งหมายความว่าโมเดลนี้ได้รับการฝึกอบรมมาเป็นอย่างดีและเหมาะสมกับวัตถุประสงค์ โมเดลอาจไม่เหมาะกับทุกสถานการณ์ และโมเดลจะมีการปรับปรุงในอัตราที่น่าตกใจ อายุการใช้งานปกติของโมเดล Machine Learning อยู่ระหว่าง 2 ถึง 18 เดือน ขึ้นอยู่กับสถานการณ์การใช้งาน
แจกแจงรายละเอียดปัญหาความน่าเชื่อถือในการเรียนรู้ของเครื่อง
มีปัญหาด้านความน่าเชื่อถือบางประการในกระบวนการฝึกอบรมโมเดล และขณะนี้ Gensyn กำลังดำเนินการสร้างหลักฐานที่ถูกต้องเพื่ออำนวยความสะดวกในกระบวนการนี้ อย่างไรก็ตาม บทความนี้เน้นที่กระบวนการอนุมานแบบจำลองเป็นหลัก ตอนนี้เรามาใช้การเรียนรู้ของเครื่องสี่องค์ประกอบเพื่อค้นหาปัญหาความน่าเชื่อถือที่อาจเกิดขึ้น:
เข้า:
แหล่งข้อมูลมีการป้องกันการแทรกแซง
ข้อมูลอินพุตส่วนตัวจะไม่ถูกขโมยโดยผู้ดำเนินการโมเดล (ปัญหาความเป็นส่วนตัว)
แบบอย่าง:
ตัวแบบมีความแม่นยำตามที่โฆษณาไว้
กระบวนการคำนวณเสร็จสมบูรณ์อย่างถูกต้อง
พารามิเตอร์:
พารามิเตอร์โมเดลไม่มีการเปลี่ยนแปลงหรือเป็นไปตามที่โฆษณา
ในระหว่างกระบวนการ พารามิเตอร์โมเดลที่มีค่าต่อเจ้าของโมเดลจะไม่รั่วไหล (ปัญหาความเป็นส่วนตัว)
เอาท์พุท:
ผลลัพธ์นั้นถูกต้องอย่างพิสูจน์ได้ (อาจปรับปรุงได้เนื่องจากองค์ประกอบทั้งหมดข้างต้นได้รับการปรับปรุง)
จะนำ ZK ไปใช้กับเฟรมเวิร์กความน่าเชื่อถือของการเรียนรู้ของเครื่องได้อย่างไร
ปัญหาด้านความน่าเชื่อถือบางประการข้างต้นสามารถแก้ไขได้โดยดำเนินการแบบ on-chain การอัปโหลดอินพุตและพารามิเตอร์การเรียนรู้ของเครื่องจักรไปยังห่วงโซ่และการคำนวณแบบจำลองบนห่วงโซ่สามารถรับประกันความถูกต้องของอินพุต พารามิเตอร์ และการคำนวณแบบจำลองได้ แต่แนวทางนี้อาจเสียสละความสามารถในการขยายขนาดและความเป็นส่วนตัว Giza กำลังดำเนินการนี้บน Starknet แต่เนื่องจากปัญหาด้านต้นทุน จึงรองรับเฉพาะโมเดลการเรียนรู้ของเครื่องอย่างง่าย ๆ เช่น การถดถอย ไม่ใช่โครงข่ายประสาทเทียม เทคโนโลยี ZK สามารถแก้ปัญหาความน่าเชื่อถือข้างต้นได้อย่างมีประสิทธิภาพมากขึ้น ปัจจุบัน ZK ใน ZKML มักจะหมายถึง zkSNARK ก่อนอื่น เรามาทบทวนแนวคิดพื้นฐานของ zkSNARK กันก่อน:
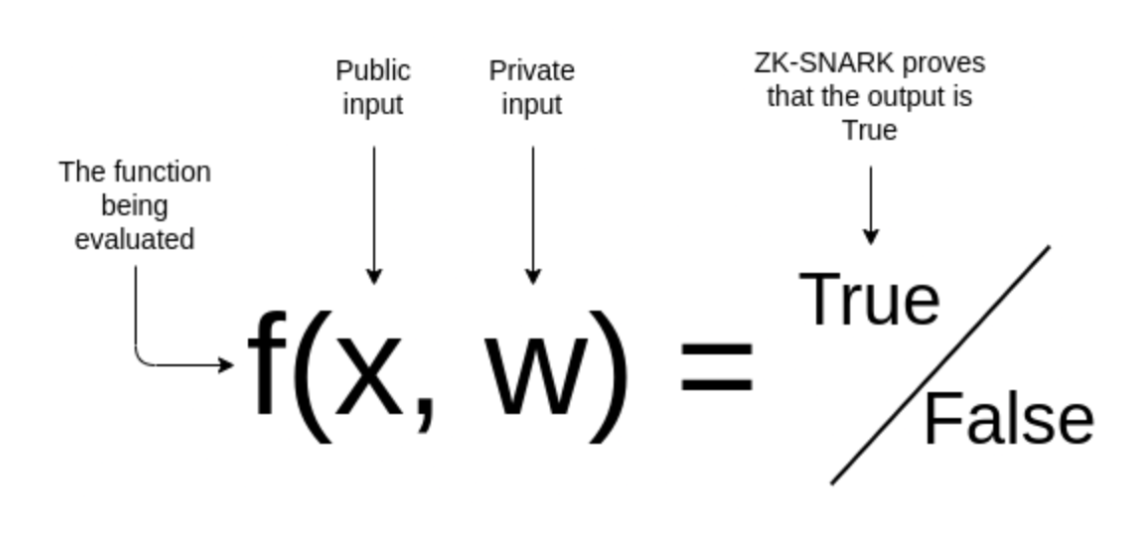
การพิสูจน์ zkSNARK เป็นการพิสูจน์ว่าฉันรู้ข้อมูลลับบางอย่าง w ซึ่งเป็นจริงที่ผลลัพธ์ของการคำนวณ f นี้เป็น OUT โดยไม่ได้บอกคุณว่า w คืออะไร กระบวนการสร้างหลักฐานสามารถสรุปได้เป็นขั้นตอนต่อไปนี้:
กำหนดข้อความที่ต้องการพิสูจน์: f(x, w)=true
ฉันจำแนกรูปภาพนี้อย่างถูกต้อง x โดยใช้โมเดลการเรียนรู้ของเครื่อง f พร้อมพารามิเตอร์ส่วนตัว w
แปลงคำสั่งให้เป็นวงจร (การคำนวณ): วิธีการสร้างวงจรแบบต่างๆ ได้แก่ R 1 CS, QAP, Plonkish เป็นต้น
เมื่อเปรียบเทียบกับกรณีการใช้งานอื่นๆ ZKML ต้องมีขั้นตอนเพิ่มเติมที่เรียกว่าการหาปริมาณ โดยทั่วไปการอนุมานโครงข่ายประสาทเทียมจะทำโดยใช้เลขทศนิยมซึ่งมีราคาสูงมากในการเลียนแบบในโดเมนหลักของวงจรเลขคณิต วิธีการหาปริมาณที่แตกต่างกันทำให้ความแม่นยำและข้อกำหนดของอุปกรณ์ลดลง
วิธีสร้างวงจรบางอย่าง เช่น R 1 CS ไม่ได้มีประสิทธิภาพสำหรับโครงข่ายประสาทเทียม ส่วนนี้สามารถปรับเปลี่ยนเพื่อปรับปรุงประสิทธิภาพได้
สร้างรหัสพิสูจน์และรหัสยืนยัน
สร้างพยาน: เมื่อ w=w*, f(x, w)=true
สร้างความมุ่งมั่นในแฮช: พยาน w* มุ่งมั่นที่จะสร้างค่าแฮชโดยใช้ฟังก์ชันแฮชที่เข้ารหัส แฮชนี้สามารถเปิดเผยต่อสาธารณะได้
ซึ่งช่วยให้แน่ใจว่าอินพุตส่วนตัวหรือพารามิเตอร์โมเดลจะไม่ถูกแก้ไขหรือแก้ไขระหว่างการคำนวณ ขั้นตอนนี้มีความสำคัญเนื่องจากแม้แต่การปรับเปลี่ยนเล็กน้อยก็อาจส่งผลกระทบอย่างมีนัยสำคัญต่อลักษณะการทำงานและผลลัพธ์ของแบบจำลอง
การสร้างหลักฐาน: ระบบพิสูจน์ที่แตกต่างกันใช้อัลกอริธึมการสร้างหลักฐานที่แตกต่างกัน
กฎความรู้แบบศูนย์พิเศษจำเป็นต้องได้รับการออกแบบสำหรับการดำเนินการเรียนรู้ของเครื่องจักร เช่น การคูณเมทริกซ์และเลเยอร์แบบบิดเบี้ยว เพื่อใช้โปรโตคอลที่ประหยัดเวลาแบบซับลิเนียร์สำหรับการคำนวณเหล่านี้
- ระบบ zkSNARK ทั่วไป เช่น Groth 16 อาจไม่สามารถรองรับโครงข่ายประสาทเทียมได้อย่างมีประสิทธิภาพเนื่องจากมีภาระในการคำนวณมากเกินไป
- ตั้งแต่ปี 2020 เป็นต้นมา ระบบพิสูจน์ ZK ใหม่จำนวนมากได้เกิดขึ้นเพื่อเพิ่มประสิทธิภาพการพิสูจน์ ZK สำหรับกระบวนการอนุมานแบบจำลอง รวมถึง vCNN, ZEN, ZKCNN และ pvCNN อย่างไรก็ตาม ส่วนใหญ่ได้รับการปรับให้เหมาะกับรุ่นของ CNN ใช้ได้กับชุดข้อมูลหลักบางชุดเท่านั้น เช่น MNIST หรือ CIFAR-10
- ในปี 2022 Daniel Kang Tatsunori Hashimoto, Ion Stoica และ Yi Sun (ผู้ก่อตั้ง Axiom) เสนอรูปแบบการพิสูจน์ใหม่โดยใช้ Halo 2 ซึ่งทำให้เกิดการสร้างการพิสูจน์ ZK สำหรับชุดข้อมูล ImageNet เป็นครั้งแรก การเพิ่มประสิทธิภาพมุ่งเน้นไปที่ส่วนเลขคณิต โดยมีพารามิเตอร์การค้นหาใหม่สำหรับความไม่เชิงเส้นและการนำวงจรย่อยกลับมาใช้ใหม่ข้ามเลเยอร์
- Modulus Labs กำลังเปรียบเทียบระบบการพิสูจน์ที่แตกต่างกันสำหรับการอนุมานแบบออนไลน์ และพบว่าในแง่ของเวลาในการพิสูจน์ ZKCNN และ plonky 2 ทำงานได้ดีที่สุด ในแง่ของการใช้หน่วยความจำของผู้พิสูจน์สูงสุด ZKCNN และ halo 2 ทำงานได้ดี ในขณะที่ plonky ทำงานได้ดี แต่มีค่าใช้จ่ายในการใช้หน่วยความจำและ ZKCNN เหมาะสำหรับรุ่น CNN เท่านั้น นอกจากนี้ยังกำลังพัฒนาระบบ zkSNARK ใหม่ที่ออกแบบมาเฉพาะสำหรับ ZKML รวมถึงเครื่องเสมือนใหม่
หลักฐานการตรวจสอบ: ผู้ตรวจสอบใช้กุญแจยืนยันในการตรวจสอบโดยที่พยานไม่รู้

ดังนั้นเราจึงสามารถแสดงให้เห็นว่าการใช้เทคนิคความรู้เป็นศูนย์กับโมเดลการเรียนรู้ของเครื่องสามารถแก้ปัญหาความน่าเชื่อถือได้มากมาย เทคนิคที่คล้ายกันโดยใช้การยืนยันแบบโต้ตอบสามารถให้ผลลัพธ์ที่คล้ายกัน แต่จะต้องใช้ทรัพยากรเพิ่มเติมในด้านผู้ตรวจสอบ และอาจประสบปัญหาความเป็นส่วนตัวมากขึ้น เป็นที่น่าสังเกตว่า การสร้างการพิสูจน์สำหรับสิ่งเหล่านี้อาจต้องใช้เวลาและทรัพยากร ทั้งนี้ขึ้นอยู่กับรุ่นเฉพาะ ดังนั้นในท้ายที่สุดแล้วจะเกิดข้อเสียเปรียบเมื่อนำเทคโนโลยีนี้ไปใช้กับกรณีการใช้งานจริงในท้ายที่สุด
สถานะปัจจุบันของโซลูชั่นปัจจุบัน
ต่อไป โซลูชั่นที่มีอยู่คืออะไร? โปรดทราบว่าผู้ให้บริการโมเดลอาจมีสาเหตุหลายประการที่ไม่ต้องการสร้างการพิสูจน์ ZKML สำหรับผู้ที่กล้าพอที่จะลองใช้ ZKML และโซลูชันก็สมเหตุสมผล พวกเขาสามารถเลือกจากโซลูชันที่แตกต่างกันสองสามรายการ ขึ้นอยู่กับรุ่นและตำแหน่งของอินพุต:
หากข้อมูลอินพุตเป็นแบบออนไลน์ ให้พิจารณาใช้ Axiom เป็นวิธีแก้ปัญหา:
Axiom กำลังสร้างตัวประมวลผลร่วมที่ไม่มีความรู้สำหรับ Ethereum เพื่อปรับปรุงการเข้าถึงข้อมูลบล็อกเชนของผู้ใช้ และมอบมุมมองดิจิทัลที่ซับซ้อนยิ่งขึ้นของข้อมูลบนเชน การคำนวณแมชชีนเลิร์นนิงที่เชื่อถือได้บนข้อมูลออนไลน์เป็นไปได้:
- ขั้นแรก Axiom นำเข้าข้อมูลออนไลน์โดยจัดเก็บราก Merkle ของแฮชบล็อก Ethereum ไว้ในสัญญาอัจฉริยะ AxiomV 0 ซึ่งได้รับการตรวจสอบอย่างน่าเชื่อถือผ่านกระบวนการตรวจสอบ ZK-SNARK จากนั้นสัญญา AxiomV 0 StoragePf จะอนุญาตให้มีการตรวจสอบแบทช์ของการพิสูจน์การจัดเก็บข้อมูล Ethereum ในอดีตโดยพลการ เทียบกับรากของความไว้วางใจที่ได้รับจากแฮชบล็อกแคชใน AxiomV 0
- จากนั้น ข้อมูลอินพุตของการเรียนรู้ของเครื่องสามารถดึงออกมาจากข้อมูลประวัติที่นำเข้าได้
- Axiom สามารถใช้การดำเนินการการเรียนรู้ของเครื่องที่ได้รับการพิสูจน์แล้วจากด้านบน โดยใช้ Halo 2 ที่ปรับให้เหมาะสมเป็นแบ็กเอนด์เพื่อตรวจสอบความถูกต้องของส่วนการคำนวณแต่ละส่วน
- ในที่สุด Axiom จะแนบหลักฐาน zk ของผลลัพธ์การสืบค้นแต่ละรายการ และสัญญาอัจฉริยะของ Axiom จะตรวจสอบหลักฐาน zk ผู้มีส่วนได้เสียที่ต้องการพิสูจน์สามารถเข้าถึงได้จากสัญญาอัจฉริยะ
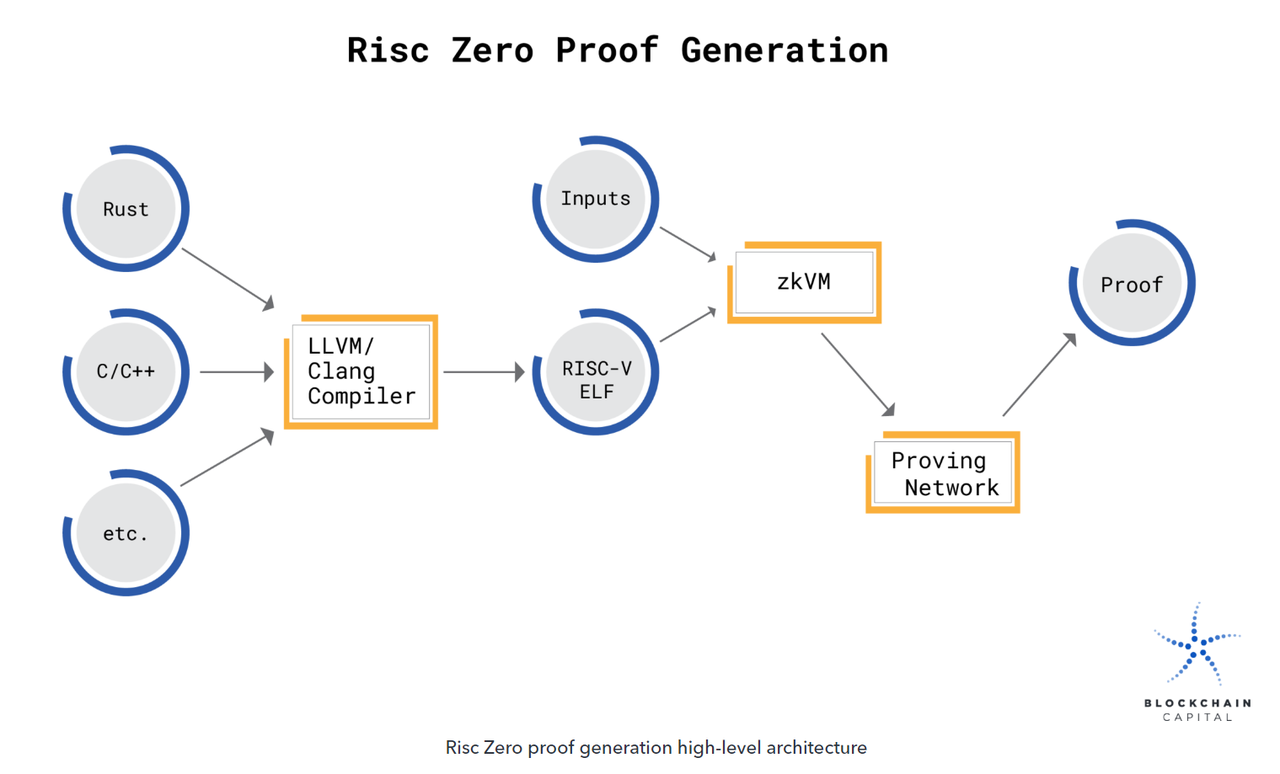
หากคุณวางโมเดลของคุณแบบออนไลน์ ให้พิจารณาใช้ RISCZero เป็นโซลูชัน:
ด้วยการรันโมเดลแมชชีนเลิร์นนิงใน ZKVM ของ RISC Zero คุณสามารถพิสูจน์ได้ว่าการคำนวณที่เกี่ยวข้องในโมเดลนั้นดำเนินการอย่างถูกต้อง กระบวนการคำนวณและการตรวจสอบสามารถทำได้แบบออฟไลน์ในสภาพแวดล้อมที่ผู้ใช้ต้องการ หรือใน Bonsai Network ซึ่งเป็นแบบรวมสากล
- ขั้นแรก จะต้องรวบรวมซอร์สโค้ดของโมเดลเป็นไบนารี RISC-V เมื่อดำเนินการไบนารีนี้ใน ZKVM เอาต์พุตจะถูกจับคู่กับใบเสร็จรับเงินที่คำนวณได้ซึ่งมีตราประทับการเข้ารหัส ตราประทับนี้ทำหน้าที่เป็นอาร์กิวเมนต์ที่ไม่มีความรู้เพื่อความสมบูรณ์ในการคำนวณ โดยเชื่อมโยง imageID ที่เข้ารหัส (ระบุไบนารี่ RISC-V ที่ดำเนินการ) กับเอาต์พุตโค้ดที่ประกาศเพื่อการตรวจสอบที่รวดเร็วโดยบุคคลที่สาม
- เมื่อดำเนินการโมเดลใน ZKVM การคำนวณเกี่ยวกับการเปลี่ยนแปลงสถานะจะทำภายใน VM ทั้งหมด ไม่มีข้อมูลใดๆ เกี่ยวกับสถานะภายในของโมเดลรั่วไหลสู่โลกภายนอก
- เมื่อดำเนินการแบบจำลองแล้ว ผลลัพธ์ที่ได้จะกลายเป็นหลักฐานพิสูจน์ความสมบูรณ์ของการคำนวณโดยปราศจากความรู้ RISC ZeroZKVM เป็นเครื่องเสมือน RISC-V ที่สามารถสร้างการพิสูจน์โค้ดที่รันโดยปราศจากความรู้ เมื่อใช้ ZKVM คุณสามารถสร้างใบเสร็จรับเงินที่เข้ารหัสซึ่งใครๆ ก็สามารถตรวจสอบได้ว่าสร้างโดยรหัสไคลเอ็นต์ ZKVM เมื่อมีการออกใบเสร็จรับเงิน จะไม่มีการเปิดเผยข้อมูลอื่น ๆ เกี่ยวกับการดำเนินการโค้ด (เช่น ข้อมูลป้อนเข้าที่ให้ไว้)
กระบวนการเฉพาะในการสร้างการพิสูจน์ ZK นั้นเกี่ยวข้องกับโปรโตคอลเชิงโต้ตอบที่มี oracle แบบสุ่มเป็นตัวตรวจสอบ ตราประทับบนใบเสร็จรับเงิน RISC Zero ถือเป็นบันทึกข้อตกลงปฏิสัมพันธ์นี้เป็นหลัก
หากคุณต้องการนำเข้าโมเดลโดยตรงจากซอฟต์แวร์แมชชีนเลิร์นนิงที่ใช้กันทั่วไป เช่น Tensorflow หรือ Pytorch ให้พิจารณาใช้ ezkl เป็นโซลูชัน:
Ezkl คือไลบรารีและเครื่องมือบรรทัดคำสั่งสำหรับการอนุมานโมเดลการเรียนรู้เชิงลึกและกราฟการคำนวณอื่นๆ ใน zkSNARK
- ขั้นแรก ส่งออกโมเดลสุดท้ายเป็นไฟล์ .onnx และอินพุตตัวอย่างบางส่วนเป็นไฟล์ .json
- จากนั้น ชี้ ezkl ไปที่ไฟล์ .onnx และ .json เพื่อสร้างวงจร ZK-SNARK ที่สามารถพิสูจน์คำสั่ง ZKML ได้
ดูเหมือนง่ายใช่มั้ย? เป้าหมายของ Ezkl คือการสร้างเลเยอร์นามธรรมที่ช่วยให้สามารถเรียกและจัดวางการดำเนินการระดับสูงในวงจร Halo 2 ได้ Ezkl ขจัดความซับซ้อนมากมายไปพร้อมๆ กับการคงความยืดหยุ่นอันเหลือเชื่อไว้ โมเดลเชิงปริมาณมีปัจจัยสเกลแบบเชิงปริมาณโดยอัตโนมัติ ซึ่งสนับสนุนความยืดหยุ่นในการเปลี่ยนไปใช้ระบบพิสูจน์อื่นๆ ที่เกี่ยวข้องกับโซลูชันใหม่ๆ นอกจากนี้ยังรองรับเครื่องเสมือนหลายประเภท รวมถึง EVM และ WASM
เกี่ยวกับระบบพิสูจน์ ezkl ปรับแต่งวงจร halo 2 โดยการรวมการพิสูจน์ (การแปลงการพิสูจน์ที่ยากต่อการตรวจสอบเป็นการพิสูจน์ที่ง่ายต่อการตรวจสอบผ่านตัวกลาง) และการเรียกซ้ำ (สามารถแก้ปัญหาหน่วยความจำได้ แต่ปรับให้เข้ากับ halo 2 ได้ยาก) Ezkl ยังปรับกระบวนการทั้งหมดให้เหมาะสมผ่านการหลอมรวมและนามธรรมซึ่งสามารถลดค่าใช้จ่ายผ่านการพิสูจน์ขั้นสูง
เป็นที่น่าสังเกตว่าเมื่อเทียบกับโครงการ zkml ทั่วไปอื่นๆ Accessor Labs มุ่งเน้นไปที่การจัดหาเครื่องมือ zkml ที่ออกแบบมาเป็นพิเศษสำหรับเกมออนไลน์เต็มรูปแบบ ซึ่งอาจเกี่ยวข้องกับ AI NPC การอัปเดตการเล่นเกมอัตโนมัติ อินเทอร์เฟซเกมที่เกี่ยวข้องกับภาษาธรรมชาติ ฯลฯ
กรณีการใช้งานอยู่ที่ไหน?
การแก้ปัญหาเรื่องความไว้วางใจด้วยแมชชีนเลิร์นนิงผ่านเทคโนโลยี ZK หมายความว่าตอนนี้สามารถนำไปใช้กับกรณีการใช้งานที่ มีความเสี่ยงสูง และ มีความมั่นใจสูง ได้มากกว่าแค่ติดตามการสนทนาของผู้คนหรือจับคู่ภาพแมวกับภาพสุนัขเพื่อสร้างความแตกต่าง Web3 กำลังสำรวจกรณีการใช้งานเหล่านี้จำนวนมากอยู่แล้ว นี่ไม่ใช่เรื่องบังเอิญ เนื่องจากแอปพลิเคชัน Web3 ส่วนใหญ่ทำงานหรือตั้งใจให้ทำงานบนบล็อกเชน เนื่องจากบล็อกเชนมีคุณสมบัติเฉพาะในการทำงานอย่างปลอดภัย ยากต่อการแก้ไข และมีการคำนวณที่กำหนดได้ AI ที่ประพฤติตัวดีและสามารถตรวจสอบได้ควรเป็น AI ที่สามารถทำงานในสภาพแวดล้อมที่ไม่น่าเชื่อถือและมีการกระจายอำนาจใช่ไหม?

กรณีการใช้งานที่สามารถใช้ ZK+ML ใน Web3
แอปพลิเคชัน Web3 จำนวนมากเสียสละประสบการณ์ผู้ใช้เพื่อความปลอดภัยและการกระจายอำนาจ เนื่องจากนั่นเป็นสิ่งสำคัญอันดับแรกอย่างชัดเจน และยังมีข้อจำกัดด้านโครงสร้างพื้นฐานอยู่ AI/ML มีศักยภาพในการเสริมสร้างประสบการณ์ผู้ใช้ ซึ่งไม่ต้องสงสัยเลยว่ามีประโยชน์ แต่ก่อนหน้านี้ดูเหมือนจะเป็นไปไม่ได้หากไม่มีการประนีประนอม ตอนนี้ ต้องขอบคุณ ZK ที่ทำให้เรามองเห็นการรวม AI/ML เข้ากับแอปพลิเคชัน Web3 ได้อย่างสะดวกสบาย โดยไม่ต้องเสียสละความปลอดภัยและการกระจายอำนาจมากเกินไป
โดยพื้นฐานแล้ว นี่จะเป็นแอปพลิเคชัน Web3 (ซึ่งอาจมีหรือไม่มีอยู่ในขณะที่เขียน) ที่ใช้ ML/AI ในลักษณะที่ไม่น่าเชื่อถือ ด้วยความไม่ไว้วางใจ เราหมายถึงว่ามันทำงานบนสภาพแวดล้อม/แพลตฟอร์มที่ไม่น่าเชื่อถือ หรือไม่หรือว่าการทำงานของมันสามารถพิสูจน์ได้ว่าสามารถตรวจสอบได้หรือไม่ โปรดทราบว่าไม่ใช่ทุกกรณีการใช้งาน ML/AI (แม้แต่ใน Web3) ที่ต้องการหรือต้องการทำงานในลักษณะที่ไม่น่าเชื่อถือ เราจะวิเคราะห์แต่ละส่วนของความสามารถ ML ที่ใช้ในโดเมน Web3 ต่างๆ จากนั้นเราจะระบุชิ้นส่วนที่ต้องใช้ ZKML ซึ่งโดยทั่วไปแล้วเป็นชิ้นส่วนที่มีมูลค่าสูงซึ่งผู้คนยินดีจ่ายเงินเพิ่มเพื่อพิสูจน์ กรณีการใช้งาน/แอปพลิเคชันส่วนใหญ่ที่กล่าวถึงด้านล่างยังอยู่ในขั้นตอนการวิจัยเชิงทดลอง ดังนั้นพวกเขาจึงยังห่างไกลจากการยอมรับในทางปฏิบัติ เราจะหารือว่าทำไมในภายหลัง
Defi
Defi เป็นหนึ่งในไม่กี่ข้อพิสูจน์ว่าตลาดผลิตภัณฑ์เหมาะสมกับโปรโตคอลบล็อกเชนและแอปพลิเคชัน Web3 ความสามารถในการสร้าง จัดเก็บ และจัดการความมั่งคั่งและทุนในลักษณะที่ไม่ได้รับอนุญาตนั้นไม่เคยมีมาก่อนในประวัติศาสตร์ของมนุษย์ เราได้ระบุกรณีการใช้งานจำนวนหนึ่งที่ต้องใช้โมเดล AI/ML เพื่อรันโดยไม่ได้รับอนุญาต เพื่อให้มั่นใจในความปลอดภัยและการกระจายอำนาจ
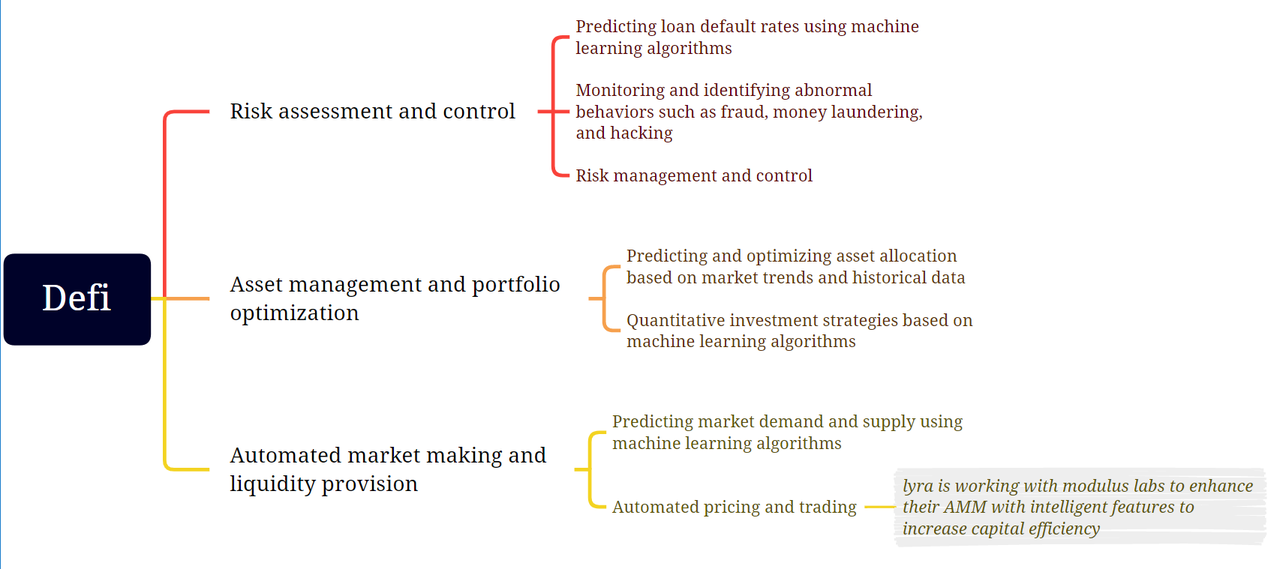
การประเมินความเสี่ยง: การเงินยุคใหม่ต้องใช้โมเดล AI/ML สำหรับการประเมินความเสี่ยงต่างๆ ตั้งแต่การป้องกันการฉ้อโกงและการฟอกเงินไปจนถึงการออกสินเชื่อที่ไม่มีหลักประกัน การตรวจสอบให้แน่ใจว่าโมเดล AI/ML ดังกล่าวทำงานในลักษณะที่ตรวจสอบได้ หมายความว่าเราสามารถป้องกันไม่ให้โมเดลเหล่านั้นถูกจัดการเพื่อให้สามารถเซ็นเซอร์ได้ ซึ่งจะเป็นอุปสรรคต่อการใช้ลักษณะที่ไม่ได้รับอนุญาตของผลิตภัณฑ์ Defi
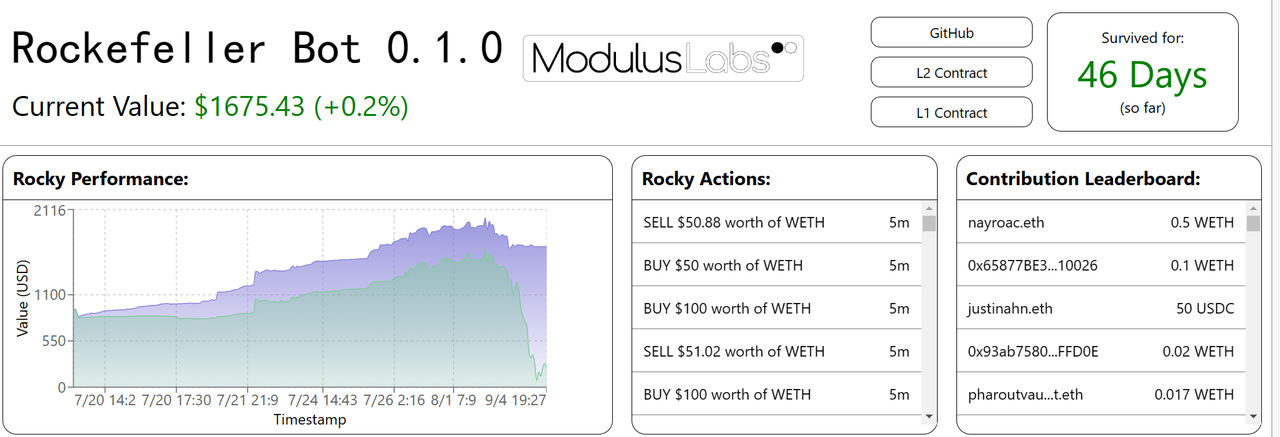
การจัดการสินทรัพย์: กลยุทธ์การซื้อขายอัตโนมัติไม่ใช่เรื่องใหม่สำหรับการเงินและ Defi แบบเดิม มีความพยายามที่จะใช้กลยุทธ์การซื้อขายที่สร้างโดย AI/ML แต่มีกลยุทธ์การกระจายอำนาจเพียงไม่กี่กลยุทธ์เท่านั้นที่ประสบความสำเร็จ การใช้งานทั่วไปในสาขา Defi ปัจจุบันรวมถึง Rocky Bot ที่ทดลองโดย Modulus Labs
- Rocky Bot: Modulus Labs ได้สร้างบอทการซื้อขายโดยใช้ AI เพื่อการตัดสินใจบน StarkNet
-- สัญญาที่ถือเงินบน L1 และแลกเปลี่ยน WEth/USDC บน Uniswap
สิ่งนี้ใช้กับส่วน เอาต์พุต ของกรอบงานความน่าเชื่อถือของ ML เอาต์พุตถูกสร้างขึ้นบน L2 ถ่ายโอนไปยัง L1 และใช้สำหรับการดำเนินการ ไม่สามารถแก้ไขได้ในระหว่างกระบวนการนี้
-- สัญญา L2 ที่ใช้โครงข่ายประสาทเทียมสามชั้นที่เรียบง่าย (แต่ยืดหยุ่น) เพื่อคาดการณ์ราคา WEth ในอนาคต สัญญาใช้ข้อมูลราคา WETH ในอดีตเป็นข้อมูลนำเข้า
สิ่งนี้ใช้ได้กับทั้งส่วน อินพุต และ โมเดล การป้อนข้อมูลราคาในอดีตมาจากบล็อกเชน การดำเนินการของโมเดลได้รับการคำนวณใน CairoVM (ประเภทหนึ่งของ ZKVM) และการติดตามการดำเนินการจะสร้างหลักฐาน ZK สำหรับการตรวจสอบ
-- ส่วนหน้าที่เรียบง่ายสำหรับการแสดงภาพและโค้ด PyTorch สำหรับการฝึก regressors และตัวแยกประเภท
ผู้ดูแลสภาพคล่องอัตโนมัติและการจัดหาสภาพคล่อง: โดยพื้นฐานแล้ว นี่คือการผสมผสานระหว่างความพยายามที่คล้ายกันที่เกิดขึ้นในการประเมินความเสี่ยงและการจัดการสินทรัพย์ ในรูปแบบที่แตกต่างกันในแง่ของปริมาณ ไทม์ไลน์ และประเภทสินทรัพย์ มีงานวิจัยมากมายเกี่ยวกับการใช้ ML เพื่อสร้างตลาดในตลาดหุ้น อาจเป็นเพียงเรื่องของเวลาก่อนที่ผลการวิจัยบางส่วนจะถูกนำมาใช้กับผลิตภัณฑ์ Defi
- ตัวอย่างเช่น LyraFinance กำลังทำงานร่วมกับ Modulus Labs เพื่อปรับปรุง AMM ด้วยฟีเจอร์อัจฉริยะ เพื่อทำให้การใช้เงินทุนมีประสิทธิภาพมากขึ้น
คำกล่าวอันทรงเกียรติ:
- ทีม Warp.cc ได้พัฒนาโปรเจ็กต์การสอนเกี่ยวกับวิธีการปรับใช้สัญญาอัจฉริยะที่รันโครงข่ายประสาทเทียมที่ได้รับการฝึกอบรมเพื่อทำนายราคา Bitcoin สิ่งนี้สอดคล้องกับส่วน อินพุต และ โมเดล ของเฟรมเวิร์กของเรา เนื่องจากอินพุตใช้ข้อมูลที่ได้รับจาก RedStoneOracles และโมเดลถูกดำเนินการบน Arweave เป็นสัญญาอัจฉริยะ Warp
- นี่เป็นการทำซ้ำครั้งแรกและเกี่ยวข้องกับ ZK ดังนั้นจึงเป็นหนึ่งในการกล่าวถึงอันทรงเกียรติของเรา แต่ในอนาคต ทีม Warp กำลังพิจารณาการนำชิ้นส่วน ZK ไปใช้
เกม
เกมและการเรียนรู้ของเครื่องมีหลายทางแยก:
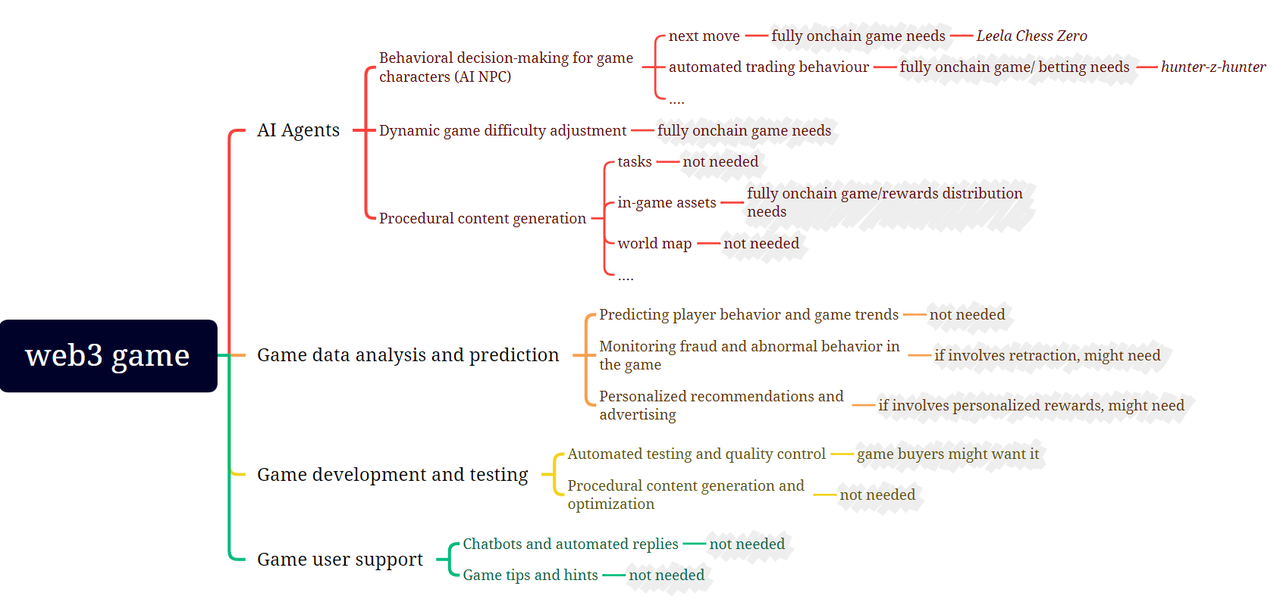
พื้นที่สีเทาในรูปแสดงถึงการประเมินเบื้องต้นของเราว่าความสามารถในการเรียนรู้ของเครื่องในส่วนของเกมจำเป็นต้องจับคู่กับการพิสูจน์ ZKML ที่เกี่ยวข้องหรือไม่ Leela Chess Zero เป็นตัวอย่างที่น่าสนใจมากในการใช้ ZKML กับเกม:
ตัวแทนเอไอ
- Leela Chess Zero (LC 0): ผู้เล่นหมากรุก AI แบบออนไลน์ทั้งหมดที่สร้างโดย Modulus Labs โดยเล่นกับกลุ่มผู้เล่นมนุษย์จากชุมชน
-- LC 0 และกลุ่มมนุษย์ผลัดกันเล่นเกม (ตามที่ควรจะเป็นในหมากรุก)
--การเคลื่อนที่ของ LC 0 คำนวณจากแบบจำลองวงจรพอดีอย่างง่ายของ LC 0
- การเคลื่อนไหวของ LC 0 มีการพิสูจน์ snark ของ Halo 2 เพื่อให้แน่ใจว่าไม่มีการรบกวนจากความไว้วางใจของสมองของมนุษย์ มีเพียงรุ่น LC 0 แบบเรียบง่ายเท่านั้นที่สามารถใช้เพื่อการตัดสินใจ
- ซึ่งสอดคล้องกับส่วน รุ่น การดำเนินการแบบจำลองมีหลักฐาน ZK เพื่อตรวจสอบว่าการคำนวณไม่ได้รับการแก้ไข
การวิเคราะห์และการทำนายข้อมูล: นี่เป็นการใช้งาน AI/ML ทั่วไปในโลกของเกม Web2 อย่างไรก็ตาม เราพบเหตุผลบางประการที่ต้องนำ ZK ไปใช้ในกระบวนการ ML นี้ อาจไม่คุ้มกับความพยายามที่จะไม่ให้คุณค่ามากเกินไปเข้าไปเกี่ยวข้องโดยตรงในกระบวนการนี้ อย่างไรก็ตาม หากใช้การวิเคราะห์และการคาดการณ์บางอย่างเพื่อกำหนดรางวัลสำหรับผู้ใช้ ZK ก็อาจถูกนำไปใช้เพื่อให้แน่ใจว่าผลลัพธ์นั้นถูกต้อง
คำกล่าวอันทรงเกียรติ:
- AI Arena เป็นเกมที่ใช้ Ethereum ซึ่งผู้เล่นจากทั่วโลกสามารถออกแบบ ฝึกฝน และต่อสู้กับตัวละคร NFT ที่ขับเคลื่อนโดยโครงข่ายประสาทเทียม นักวิจัยที่มีพรสวรรค์จากทั่วโลกแข่งขันกันเพื่อสร้างโมเดลการเรียนรู้ของเครื่อง (ML) ที่ดีที่สุดเพื่อมีส่วนร่วมในการต่อสู้ในเกม AI Arena มุ่งเน้นไปที่โครงข่ายประสาทเทียมแบบป้อนไปข้างหน้า โดยรวมแล้ว มีค่าใช้จ่ายในการคำนวณต่ำกว่าโครงข่ายประสาทเทียมแบบหมุนวน (CNN) หรือโครงข่ายประสาทที่เกิดซ้ำ (RNN) ถึงกระนั้น ในปัจจุบันโมเดลต่างๆ จะถูกอัปโหลดไปยังแพลตฟอร์มหลังจากการฝึกอบรมเสร็จสิ้นแล้วเท่านั้น ดังนั้นจึงคุ้มค่าที่จะกล่าวถึง
- GiroGiro.AI กำลังสร้างชุดเครื่องมือ AI ที่ช่วยให้คนจำนวนมากสามารถสร้างปัญญาประดิษฐ์สำหรับการใช้งานส่วนตัวหรือเชิงพาณิชย์ ผู้ใช้สามารถสร้างระบบ AI ประเภทต่างๆ โดยใช้แพลตฟอร์มเวิร์กโฟลว์ AI ที่ใช้งานง่ายและเป็นอัตโนมัติ ด้วยการป้อนข้อมูลเพียงเล็กน้อยและเลือกอัลกอริธึม (หรือโมเดลสำหรับการปรับปรุง) ผู้ใช้จึงสามารถสร้างและใช้โมเดล AI ที่ตนมีอยู่ในใจได้ แม้ว่าโปรเจ็กต์นี้จะยังอยู่ในช่วงเริ่มต้น แต่เรารู้สึกตื่นเต้นมากที่ได้เห็นสิ่งที่ GiroGiro สามารถนำมาสู่การเงินเกมและผลิตภัณฑ์ที่เน้น metaverse ได้ ดังนั้นเราจึงยกย่องให้เป็นรางวัลชมเชย
ทำและสังคม
ใน DID และพื้นที่โซเชียล จุดตัดของ Web3 และ ML ปัจจุบันส่วนใหญ่อยู่ในขอบเขตของการพิสูจน์โดยมนุษย์และการพิสูจน์รับรอง ส่วนอื่นๆ อาจพัฒนาขึ้น แต่จะใช้เวลานานกว่านี้
หลักฐานของมนุษย์
- Worldcoin ใช้อุปกรณ์ที่เรียกว่า Orb เพื่อตรวจสอบว่าบุคคลนั้นมีตัวตนจริงหรือไม่ แทนที่จะพยายามตรวจสอบโดยฉ้อโกง โดยการวิเคราะห์คุณสมบัติใบหน้าและม่านตาผ่านเซ็นเซอร์กล้องต่างๆ และโมเดลการเรียนรู้ของเครื่อง เมื่อตัดสินใจได้แล้ว Orb จะถ่ายภาพกลุ่มม่านตาของผู้คน และใช้โมเดลการเรียนรู้ของเครื่องหลายแบบและเทคนิคการมองเห็นด้วยคอมพิวเตอร์อื่นๆ เพื่อสร้างรหัสม่านตา ซึ่งเป็นการแสดงลักษณะดิจิทัลที่สำคัญที่สุดของรูปแบบม่านตาของแต่ละบุคคล ขั้นตอนการลงทะเบียนเฉพาะมีดังนี้:
-- ผู้ใช้สร้างคู่คีย์ Semaphore บนโทรศัพท์มือถือ และมอบคีย์สาธารณะที่แฮชให้กับ Orb ผ่านโค้ด QR
-- Orb สแกนม่านตาของผู้ใช้และคำนวณ IrisHash ของผู้ใช้ในเครื่อง จากนั้นจะส่งข้อความที่ลงนามซึ่งมีคีย์สาธารณะที่แฮชและ IrisHash ไปยังโหนดลำดับการลงทะเบียน
-- โหนดลำดับจะตรวจสอบลายเซ็นของ Orb จากนั้นตรวจสอบว่า IrisHash ตรงกับลายเซ็นในฐานข้อมูลหรือไม่ หากผ่านการตรวจสอบเอกลักษณ์ IrisHash และคีย์สาธารณะจะถูกบันทึก
- Worldcoin ใช้ระบบพิสูจน์ความรู้เป็นศูนย์ของ Semaphore แบบโอเพ่นซอร์สเพื่อแปลงเอกลักษณ์ของ IrisHash ให้กลายเป็นเอกลักษณ์ของบัญชีผู้ใช้โดยไม่ต้องเชื่อมโยง สิ่งนี้ทำให้มั่นใจได้ว่าผู้ใช้ที่ลงทะเบียนใหม่สามารถรับ WorldCoins ของตนได้สำเร็จ ดำเนินการดังต่อไปนี้:
-- แอปพลิเคชันของผู้ใช้สร้างที่อยู่กระเป๋าสตางค์ในเครื่อง
-- แอปพลิเคชันใช้เซมาฟอร์เพื่อพิสูจน์ว่ามีคีย์ส่วนตัวของคีย์สาธารณะที่ลงทะเบียนไว้ก่อนหน้านี้ เนื่องจากนี่เป็นข้อพิสูจน์ที่ไม่มีความรู้ จึงไม่ได้เปิดเผยว่าเป็นกุญแจสาธารณะใด
-- หลักฐานจะถูกส่งไปยังเครื่องจัดลำดับอีกครั้ง ซึ่งจะตรวจสอบหลักฐานและเริ่มกระบวนการฝากโทเค็นไปยังที่อยู่กระเป๋าเงินที่ให้ไว้ ส่วนที่เรียกว่าจะถูกส่งไปพร้อมกับหลักฐานเพื่อให้แน่ใจว่าผู้ใช้ไม่สามารถรับรางวัลได้สองครั้ง
- WorldCoin ใช้เทคโนโลยี ZK เพื่อให้แน่ใจว่าผลลัพธ์ของโมเดล ML จะไม่เปิดเผยข้อมูลส่วนบุคคลของผู้ใช้ เนื่องจากไม่มีความสัมพันธ์กันระหว่างข้อมูลเหล่านั้น ในกรณีนี้ จะอยู่ภายใต้ส่วน เอาต์พุต ของกรอบงานความน่าเชื่อถือของเรา เนื่องจากช่วยให้มั่นใจได้ว่าเอาต์พุตจะถูกส่งและใช้ในลักษณะที่ต้องการ ในกรณีนี้เป็นการส่วนตัว
พิสูจน์ได้จากการกระทำ
- Astraly เป็นแพลตฟอร์มการออกโทเค็นตามชื่อเสียงบน StarkNet ซึ่งใช้เพื่อค้นหาและสนับสนุนโครงการ StarkNet ล่าสุดและยิ่งใหญ่ที่สุด การวัดชื่อเสียงเป็นงานที่ท้าทายเนื่องจากเป็นแนวคิดที่เป็นนามธรรมซึ่งไม่สามารถวัดปริมาณได้ง่ายๆ ด้วยตัวชี้วัดง่ายๆ เมื่อต้องรับมือกับตัวบ่งชี้ที่ซับซ้อน ข้อมูลนำเข้าที่ครอบคลุมและหลากหลายมีแนวโน้มที่จะให้ผลลัพธ์ที่ดีกว่า นั่นเป็นเหตุผลที่ Astraly หันมาหา Modulus Labs เพื่อขอความช่วยเหลือในการใช้โมเดล ML เพื่อให้คะแนนชื่อเสียงที่แม่นยำยิ่งขึ้น
คำแนะนำส่วนบุคคลและการกรองเนื้อหา
- Twitter เพิ่งกลายเป็นโอเพ่นซอร์ส"สำหรับคุณ"(สำหรับคุณ) อัลกอริธึมของไทม์ไลน์ แต่ผู้ใช้ไม่สามารถตรวจสอบได้ว่าอัลกอริธึมทำงานอย่างถูกต้องหรือไม่ เนื่องจากน้ำหนักของโมเดล ML ที่ใช้ในการจัดอันดับทวีตจะถูกเก็บเป็นความลับ สิ่งนี้ทำให้เกิดความกังวลเกี่ยวกับอคติและการเซ็นเซอร์
- อย่างไรก็ตาม Daniel Kang, Edward Gan, Ion Stoica และ Yi Sun ใช้ ezkl เพื่อมอบโซลูชันที่ช่วยสร้างสมดุลระหว่างความเป็นส่วนตัวและความโปร่งใส โดยการพิสูจน์การทำงานที่แท้จริงของอัลกอริทึม Twitter โดยไม่เปิดเผยน้ำหนักของโมเดล ด้วยการใช้กรอบงาน ZKML Twitter สามารถยอมรับเวอร์ชันเฉพาะของโมเดลการจัดอันดับและเผยแพร่หลักฐานว่ามันสร้างการจัดอันดับผลลัพธ์สุดท้ายที่เฉพาะเจาะจงสำหรับผู้ใช้และทวีตที่กำหนด โซลูชันนี้ช่วยให้ผู้ใช้สามารถตรวจสอบได้ว่าการคำนวณนั้นถูกต้องโดยไม่ต้องเชื่อถือระบบ แม้ว่ายังมีงานอีกมากที่ต้องทำเพื่อให้ ZKML ใช้งานได้มากขึ้น แต่นี่เป็นก้าวเชิงบวกสู่ความโปร่งใสที่มากขึ้นในโซเชียลมีเดีย ดังนั้นสิ่งนี้จึงอยู่ภายใต้กรอบการทำงานที่เชื่อถือได้ของ ML ของเรา"แบบอย่าง"ส่วนหนึ่ง.
ทบทวนกรอบงานความน่าเชื่อถือของ ML จากมุมมองของกรณีการใช้งาน
จะเห็นได้ว่ากรณีการใช้งานที่เป็นไปได้ของ ZKML ใน Web3 ยังอยู่ในช่วงเริ่มต้น แต่ก็ไม่สามารถละเลยได้ ในอนาคต เนื่องจากการใช้ ZKML ยังคงขยายตัวต่อไป อาจมีความจำเป็นสำหรับผู้ให้บริการ ZKML โดยสร้างรูปแบบปิด วนซ้ำตามรูปด้านล่าง:
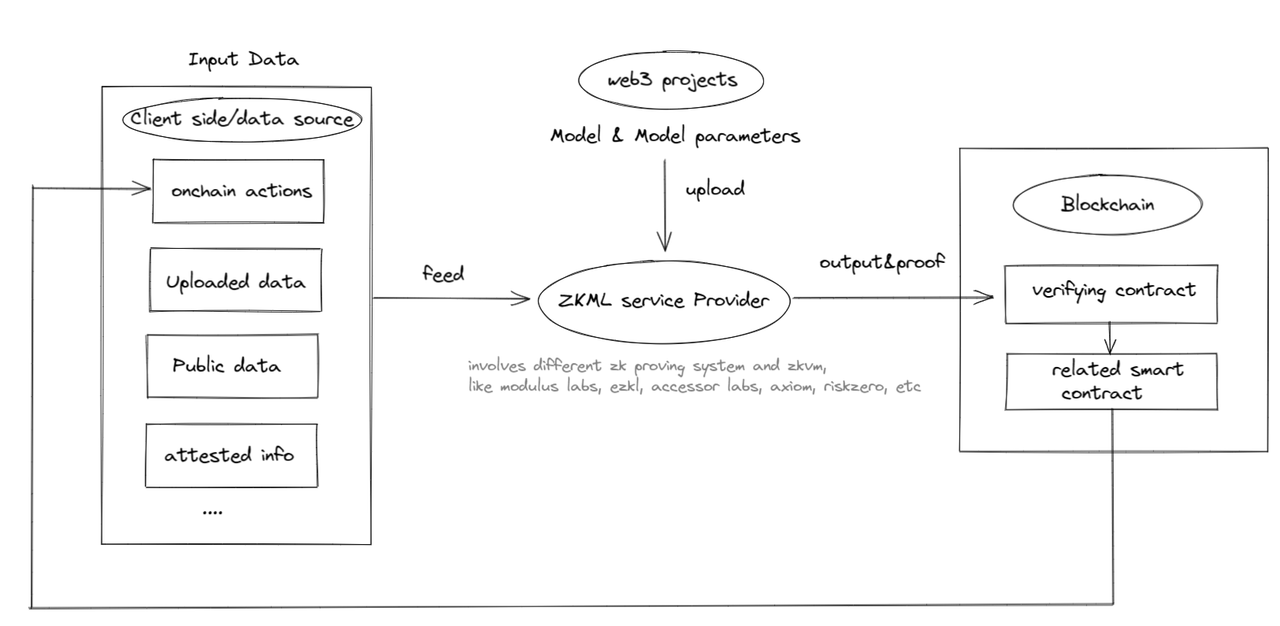
ผู้ให้บริการ ZKML มุ่งเน้นไปที่ส่วน โมเดล และ พารามิเตอร์ ของกรอบงานความน่าเชื่อถือของ ML เป็นหลัก แม้ว่าสิ่งที่เราเห็นตอนนี้ส่วนใหญ่เกี่ยวข้องกับ พารามิเตอร์ จะเกี่ยวข้องกับ โมเดล มากกว่า สิ่งสำคัญคือต้องทราบว่าส่วน อินพุต และ เอาต์พุต ได้รับการแก้ไขมากขึ้นโดยโซลูชันที่ใช้บล็อกเชน ไม่ว่าจะเป็นแหล่งข้อมูลหรือปลายทางข้อมูล ZK หรือบล็อกเชนเพียงอย่างเดียวอาจไม่บรรลุความน่าเชื่อถืออย่างสมบูรณ์ แต่เมื่อรวมกันแล้วอาจทำได้
ห่างไกลจากแอพพลิเคชั่นขนาดใหญ่แค่ไหน?
สุดท้ายนี้ เราสามารถมุ่งเน้นไปที่สถานะความเป็นไปได้ในปัจจุบันของ ZKML และว่าเราอยู่ห่างจากการใช้งาน ZKML ในวงกว้างเพียงใด
เอกสารของ Modulus Labs ให้ข้อมูลและข้อมูลเชิงลึกเกี่ยวกับความเป็นไปได้ของแอปพลิเคชัน ZKML โดยการทดสอบ Worldcoin (ด้วยข้อกำหนดด้านความแม่นยำและหน่วยความจำที่เข้มงวด) และ AI Arena (ด้วยข้อกำหนดด้านความคุ้มทุนและเวลา):
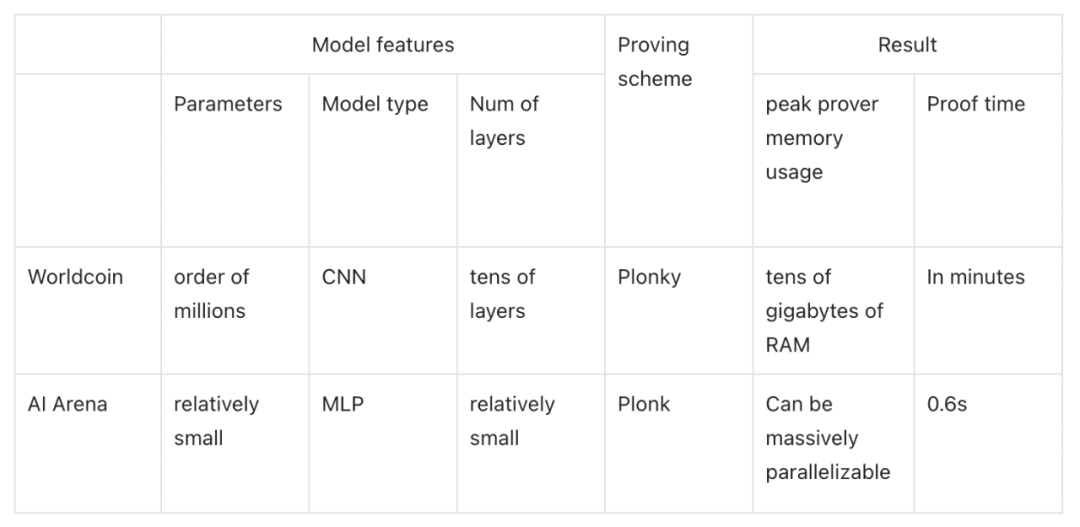
หาก Worldcon ใช้ ZKML การใช้หน่วยความจำของตัวพิสูจน์จะเกินความสามารถของฮาร์ดแวร์มือถือเชิงพาณิชย์ใดๆ หากการแข่งขัน AI Arena ใช้ ZKML การใช้ ZKCNN จะเพิ่มเวลาและค่าใช้จ่าย 100 เท่า (0.6 วินาที เทียบกับเดิม 0.008 วินาที) น่าเสียดายที่ไม่เหมาะสำหรับการใช้เทคนิค ZKML โดยตรงเพื่อพิสูจน์เวลาและการใช้หน่วยความจำของตัวพิสูจน์
แล้วขนาดหลักฐานและเวลาในการตรวจสอบล่ะ? เราสามารถอ้างถึงเอกสารของ Daniel Kang, Tatsunori Hashimoto, Ion Stoica และ Yi Sun ดังที่แสดงด้านล่าง โซลูชันการอนุมาน DNN สามารถบรรลุความแม่นยำ 79% บน ImageNet (ประเภทรุ่น: DCNN, 16 เลเยอร์, 3.4 ล้านพารามิเตอร์) ในขณะที่เวลาในการตรวจสอบใช้เวลาเพียง 10 วินาทีและขนาดการพิสูจน์คือ 5952 ไบต์ นอกจากนี้ zkSNARK ยังสามารถลดความแม่นยำลงได้ถึง 59% ด้วยเวลาการตรวจสอบเพียง 0.7 วินาที ผลลัพธ์เหล่านี้แสดงให้เห็นว่าการใช้ zkSNARK บนโมเดลมาตราส่วน ImageNet สามารถทำได้ในแง่ของขนาดการพิสูจน์และเวลาในการตรวจสอบ
ปัญหาคอขวดทางเทคนิคหลักในปัจจุบันคือเวลาพิสูจน์และการใช้หน่วยความจำ ยังเป็นไปไม่ได้ทางเทคนิคที่จะใช้ ZKML ในกรณี web3 ZKML มีศักยภาพที่จะตามทันการพัฒนา AI หรือไม่? เราสามารถเปรียบเทียบข้อมูลเชิงประจักษ์ได้หลายอย่าง:
ความเร็วในการพัฒนาโมเดลการเรียนรู้ของเครื่อง: รุ่น GPT-1 ที่เปิดตัวในปี 2562 มีพารามิเตอร์ 150 ล้านพารามิเตอร์ ในขณะที่รุ่น GPT-3 ล่าสุดที่เปิดตัวในปี 2563 มีพารามิเตอร์ 175 พันล้านพารามิเตอร์ ซึ่งเพิ่มขึ้น 1,166 เท่าของจำนวนพารามิเตอร์ในเวลาเพียง 2 เท่า ปี .
ความเร็วในการเพิ่มประสิทธิภาพของระบบความรู้เป็นศูนย์: การเติบโตของประสิทธิภาพของระบบความรู้เป็นศูนย์นั้นเป็นไปตามก้าว กฎของมัวร์ ระบบความรู้แบบศูนย์ใหม่เกิดขึ้นเกือบทุกปี และเราคาดหวังว่าประสิทธิภาพการพิสูจน์จะเติบโตอย่างรวดเร็วจะดำเนินต่อไประยะหนึ่ง
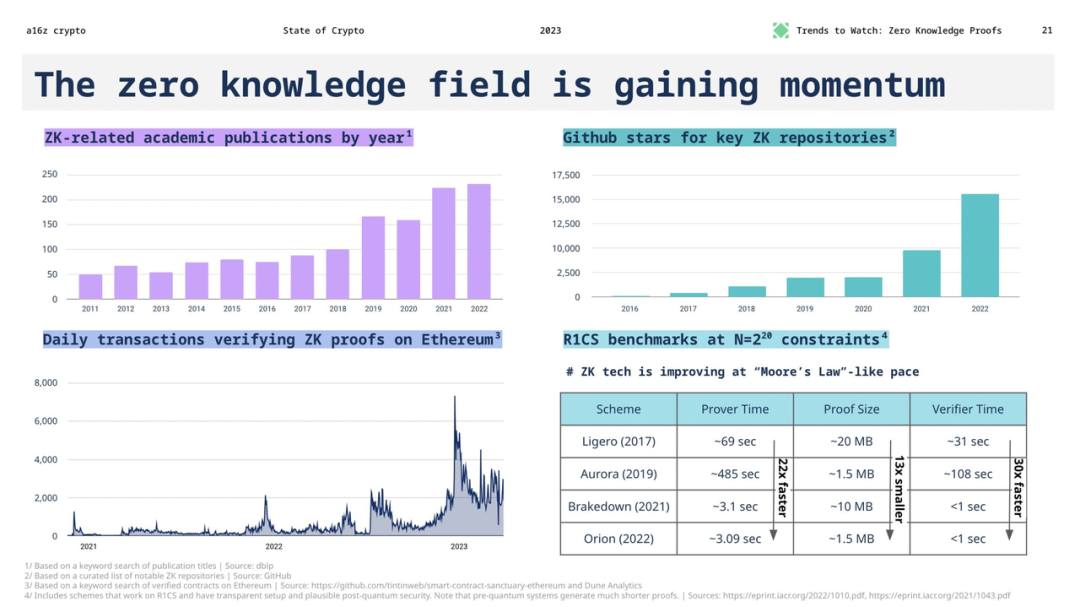
เมื่อพิจารณาจากข้อมูลนี้ แม้ว่าโมเดลการเรียนรู้ของเครื่องจะพัฒนาอย่างรวดเร็ว แต่ความเร็วในการเพิ่มประสิทธิภาพของระบบพิสูจน์ความรู้เป็นศูนย์ก็เพิ่มขึ้นอย่างต่อเนื่องเช่นกัน ในอนาคต ZKML อาจยังมีโอกาสที่จะค่อยๆ ตามการพัฒนาของ AI ได้ แต่จำเป็นต้องมีนวัตกรรมทางเทคโนโลยีอย่างต่อเนื่องและการเพิ่มประสิทธิภาพเพื่อลดช่องว่าง ซึ่งหมายความว่าแม้ว่าปัจจุบัน ZKML จะมีปัญหาคอขวดทางเทคนิคในแอปพลิเคชัน web3 ด้วยการพัฒนาอย่างต่อเนื่องของเทคโนโลยีที่ไม่มีความรู้ เรายังคงมีเหตุผลที่คาดหวังได้ว่า ZKML จะมีบทบาทมากขึ้นในสถานการณ์ web3 ในอนาคต เมื่อเปรียบเทียบอัตราการปรับปรุงของ ML และ ZK ที่ล้ำสมัย กลุ่มเป้าหมายไม่ได้มองในแง่ดีมากนัก อย่างไรก็ตาม ด้วยการปรับปรุงประสิทธิภาพการ Convolution อย่างต่อเนื่อง ฮาร์ดแวร์ ZK และระบบพิสูจน์ ZK ที่ปรับแต่งตามการดำเนินงานโครงข่ายประสาทเทียมที่มีโครงสร้างสูง หวังว่าการพัฒนา ZKML จะสามารถตอบสนองความต้องการของ web3 ได้ โดยเริ่มจากการจัดหาเครื่องจักรที่ล้าสมัย ฟังก์ชั่นการเรียนรู้เริ่มต้นขึ้น
แม้ว่าเราอาจใช้บล็อกเชน + ZK เพื่อตรวจสอบว่าข้อมูลที่ ChatGPT ฟีดกลับมาให้ฉันนั้นเชื่อถือได้อาจเป็นเรื่องยากสำหรับเรา แต่เราอาจนำโมเดล ML ที่เล็กกว่าและเก่ากว่าบางรุ่นไปใส่ในวงจร ZK ได้
สรุปแล้ว
"อำนาจมีแนวโน้มที่จะทุจริต และอำนาจเบ็ดเสร็จย่อมทุจริตอย่างแน่นอน". ด้วยพลังอันน่าทึ่งของ AI และ ML ทำให้ในปัจจุบันไม่มีวิธีที่เข้าใจผิดได้ในการนำสิ่งนี้ไปอยู่ภายใต้การกำกับดูแล ข้อเท็จจริงได้รับการพิสูจน์ครั้งแล้วครั้งเล่าว่ารัฐบาลต่างๆ เข้ามาแทรกแซงผลที่ตามมาล่าช้า หรือสั่งห้ามทันที Blockchain+ZK นำเสนอหนึ่งในโซลูชั่นไม่กี่อย่างที่สามารถทำให้สัตว์ร้ายเชื่องด้วยวิธีที่พิสูจน์ได้และตรวจสอบได้
เราหวังว่าจะได้เห็นนวัตกรรมผลิตภัณฑ์เพิ่มเติมในด้าน ZKML ZK และบล็อกเชนมอบสภาพแวดล้อมที่ปลอดภัยและเชื่อถือได้สำหรับการทำงานของ AI/ML นอกจากนี้เรายังคาดหวังว่านวัตกรรมผลิตภัณฑ์เหล่านี้จะสร้างโมเดลธุรกิจใหม่ทั้งหมด เนื่องจากในโลกของสกุลเงินดิจิทัลที่ไม่ได้รับอนุญาต เราไม่ได้ถูกจำกัดด้วยรูปแบบการค้า de-SaaS ที่นี่ เราหวังว่าจะสนับสนุนผู้สร้างเพิ่มเติมในเรื่องนี้"อนาธิปไตยตะวันตก"และ"ไอวอรี่ทาวเวอร์อีลิท"ของการทับซ้อนอันน่าทึ่งเพื่อต่อยอดจากแนวคิดที่น่าตื่นเต้น เรายังอยู่ในช่วงเริ่มต้น แต่เราอาจอยู่ในเส้นทางกอบกู้โลกแล้ว
บทความนี้เขียนโดยทีมวิจัยของ SevenX และมีวัตถุประสงค์เพื่อการสื่อสารและการเรียนรู้เท่านั้น และไม่ถือเป็นการอ้างอิงการลงทุนใดๆ หากต้องการอ้างอิงกรุณาระบุแหล่งที่มา





