





การแนะนำ
การพัฒนาอุตสาหกรรม AI เมื่อเร็ว ๆ นี้ถือเป็นการปฏิวัติอุตสาหกรรมครั้งที่สี่ การเกิดขึ้นของโมเดลขนาดใหญ่ได้ปรับปรุงประสิทธิภาพของทุกสาขาอาชีพอย่างมีนัยสำคัญ ประมาณ 20% ในเวลาเดียวกัน ความสามารถในการวางนัยทั่วไปจากโมเดลขนาดใหญ่ได้รับการยกย่องว่าเป็นกระบวนทัศน์การออกแบบซอฟต์แวร์ใหม่ ในอดีต การออกแบบซอฟต์แวร์เป็นเรื่องเกี่ยวกับโค้ดที่แม่นยำ แต่ตอนนี้การออกแบบซอฟต์แวร์เป็นเรื่องเกี่ยวกับเฟรมเวิร์กโมเดลขนาดใหญ่ทั่วไปที่ฝังอยู่ในซอฟต์แวร์เหล่านี้ สามารถนำเสนอและสนับสนุนอินพุตและเอาท์พุตโมดอลได้หลากหลายยิ่งขึ้น เทคโนโลยีการเรียนรู้เชิงลึกได้นำความเจริญครั้งที่สี่มาสู่อุตสาหกรรม AI และแนวโน้มนี้ได้แพร่กระจายไปยังอุตสาหกรรม Crypto ด้วย
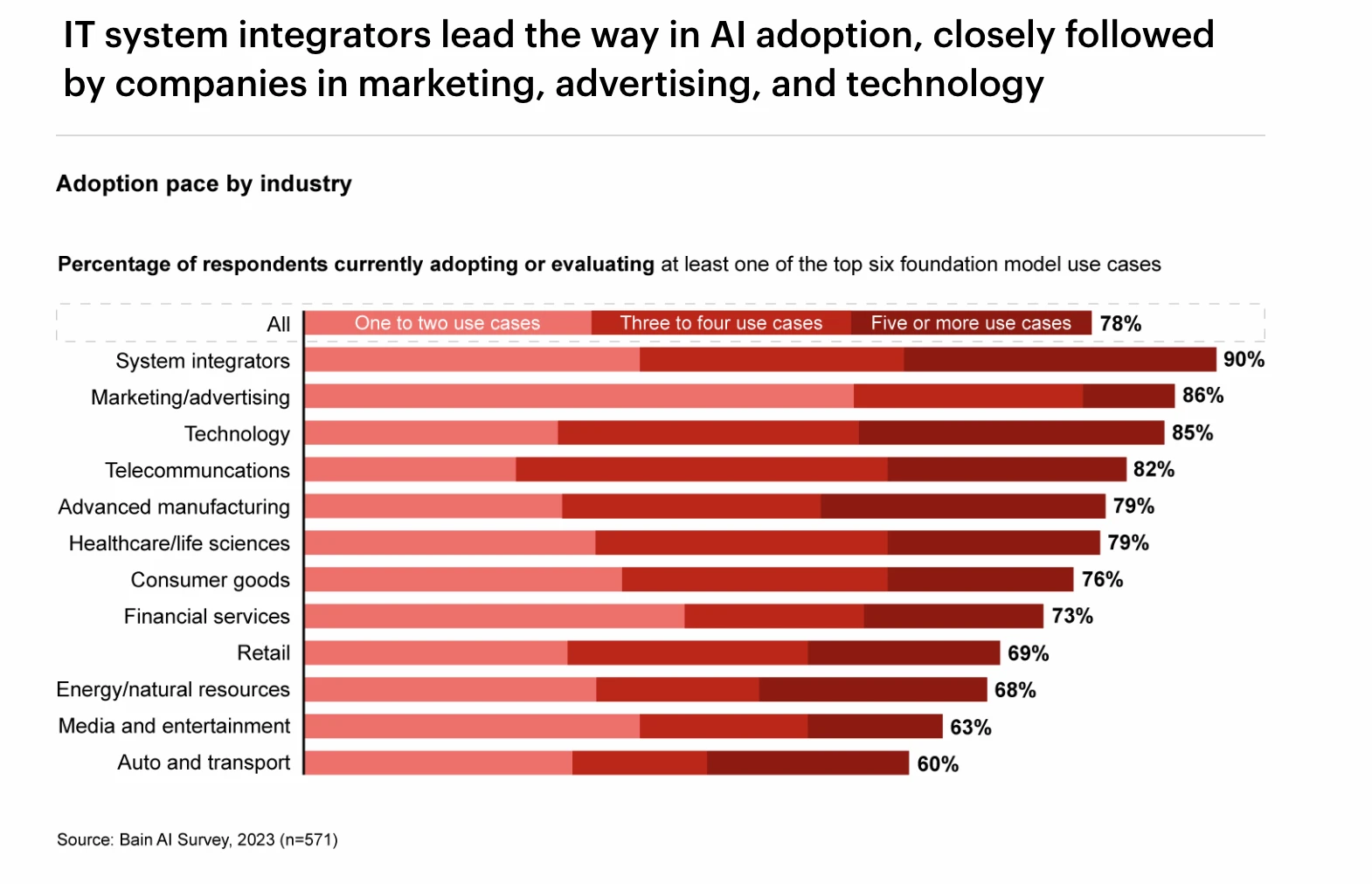
การจัดอันดับอัตราการนำ GPT มาใช้ในอุตสาหกรรมต่างๆ ที่มา: แบบสำรวจ Bain AI
ในรายงานนี้ เราจะสำรวจโดยละเอียดเกี่ยวกับประวัติการพัฒนาของอุตสาหกรรม AI การจำแนกประเภทเทคโนโลยี และผลกระทบของการประดิษฐ์เทคโนโลยีการเรียนรู้เชิงลึกต่ออุตสาหกรรม จากนั้นเราจะวิเคราะห์เชิงลึกต้นทางและปลายน้ำของห่วงโซ่อุตสาหกรรม เช่น GPU, การประมวลผลแบบคลาวด์, แหล่งข้อมูล และอุปกรณ์ Edge ในการเรียนรู้เชิงลึก รวมถึงสถานะและแนวโน้มการพัฒนาของพวกเขา หลังจากนั้น เราได้พูดคุยถึงความสัมพันธ์ระหว่าง Crypto และอุตสาหกรรม AI โดยละเอียด และแยกแยะรูปแบบของห่วงโซ่อุตสาหกรรม AI ที่เกี่ยวข้องกับ Crypto
ประวัติความเป็นมาของการพัฒนาอุตสาหกรรม AI
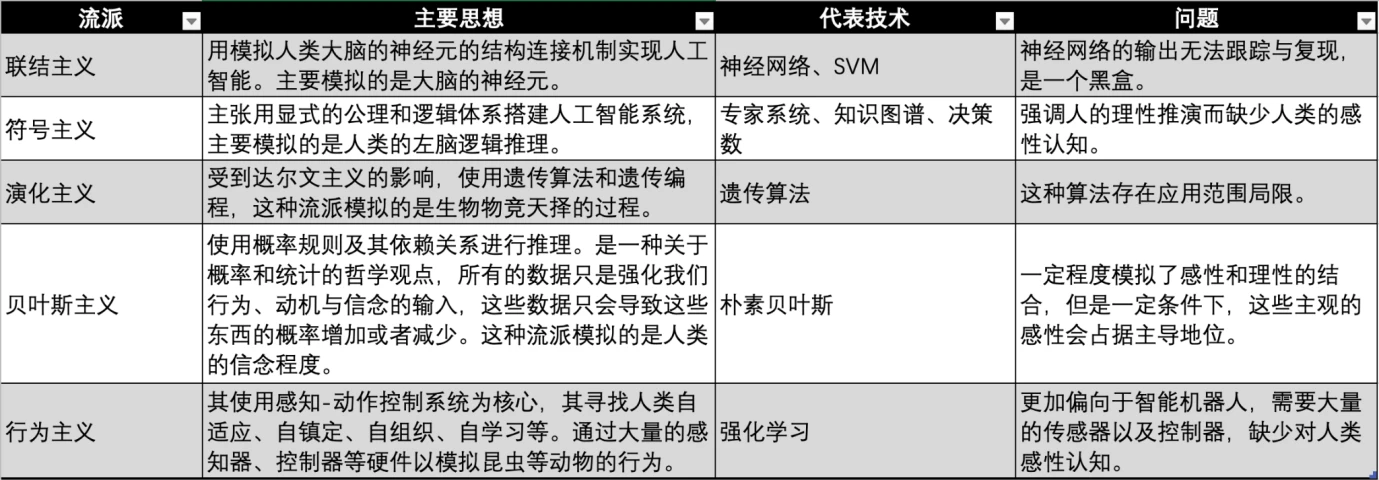
อุตสาหกรรม AI เริ่มต้นขึ้นในทศวรรษ 1950 เพื่อให้บรรลุวิสัยทัศน์ของปัญญาประดิษฐ์ นักวิชาการและอุตสาหกรรมได้พัฒนาสำนักความคิดหลายแห่งเพื่อตระหนักถึงปัญญาประดิษฐ์ในยุคต่างๆ และมีภูมิหลังทางวินัยที่แตกต่างกัน
การเปรียบเทียบประเภท AI ที่มา: Gate Ventures
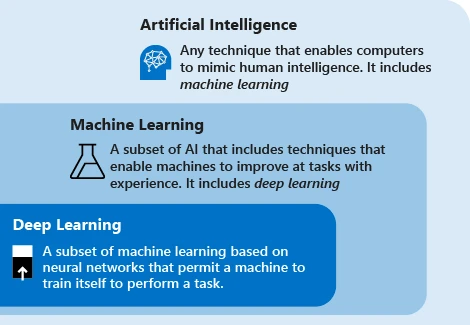
ความสัมพันธ์ AI/ML/DL แหล่งที่มา: Microsoft
เทคโนโลยีปัญญาประดิษฐ์สมัยใหม่ส่วนใหญ่ใช้คำว่า การเรียนรู้ของเครื่อง แนวคิดของเทคโนโลยีนี้คือการให้เครื่องจักรอาศัยข้อมูลเพื่อวนซ้ำงานต่างๆ เพื่อปรับปรุงประสิทธิภาพของระบบ ขั้นตอนหลักคือการป้อนข้อมูลไปยังอัลกอริธึม ใช้ข้อมูลนี้เพื่อฝึกโมเดล ทดสอบและปรับใช้โมเดล และใช้โมเดลเพื่อทำงานการคาดการณ์อัตโนมัติให้เสร็จสิ้น
ปัจจุบัน Machine Learning มี 3 สำนักหลัก ได้แก่ การเชื่อมโยง สัญลักษณ์และพฤติกรรมนิยม ซึ่งเลียนแบบระบบประสาท การคิด และพฤติกรรมของมนุษย์ตามลำดับ
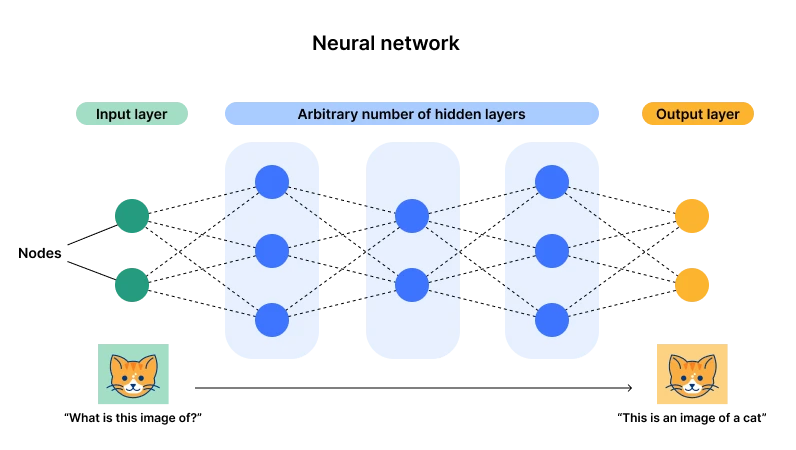
แผนภาพสถาปัตยกรรมเครือข่ายประสาทเทียม ที่มา: Cloudflare
ในปัจจุบัน การเชื่อมต่อที่แสดงโดยโครงข่ายประสาทเทียมมีความได้เปรียบ (หรือที่เรียกว่าการเรียนรู้เชิงลึก) เหตุผลหลักคือสถาปัตยกรรมนี้มีเลเยอร์อินพุตและเลเยอร์เอาต์พุต แต่มีหลายเลเยอร์ที่ซ่อนอยู่ เมื่อมีจำนวนเลเยอร์และเซลล์ประสาท ( พารามิเตอร์) ) มีขนาดใหญ่พอจึงมีโอกาสเพียงพอที่จะปรับให้เหมาะกับงานวัตถุประสงค์ทั่วไปที่ซับซ้อน ผ่านการป้อนข้อมูล พารามิเตอร์ของเซลล์ประสาทสามารถปรับได้อย่างต่อเนื่อง จากนั้นหลังจากประสบกับข้อมูลหลายรายการ เซลล์ประสาทจะเข้าสู่สถานะที่เหมาะสมที่สุด (พารามิเตอร์) นี่คือสิ่งที่เราเรียกว่าปาฏิหาริย์ที่มีความแข็งแกร่งและนี่ก็เป็น ต้นกำเนิดของ คำว่า ความลึก - เลเยอร์และเซลล์ประสาทเพียงพอ
ตัวอย่างเช่น สามารถเข้าใจง่ายๆ ว่าฟังก์ชันถูกสร้างขึ้น เมื่อเราป้อน X=2, Y=3; เมื่อ X=3, Y=5 หากคุณต้องการให้ฟังก์ชันนี้จัดการกับ X ทั้งหมด คุณต้องบวกต่อไป ระดับของฟังก์ชันนี้และพารามิเตอร์ของมัน ตัวอย่างเช่น ฉันสามารถสร้างฟังก์ชันที่ตรงตามเงื่อนไขนี้ได้ โดย Y = 2 ฟังก์ชันของจุดข้อมูลโดยใช้ GPU สำหรับการแคร็กแบบ bruteforce พบว่า Y = ในที่นี้ X 2 และ X, X 0 ล้วนเป็นตัวแทนของเซลล์ประสาทที่แตกต่างกัน และ 1, -3, 5 คือพารามิเตอร์ของพวกมัน
ในเวลานี้ หากเราป้อนข้อมูลจำนวนมากลงในโครงข่ายประสาทเทียม เราก็สามารถเพิ่มเซลล์ประสาทและวนซ้ำพารามิเตอร์เพื่อให้พอดีกับข้อมูลใหม่ได้ นี่จะพอดีกับข้อมูลทั้งหมด
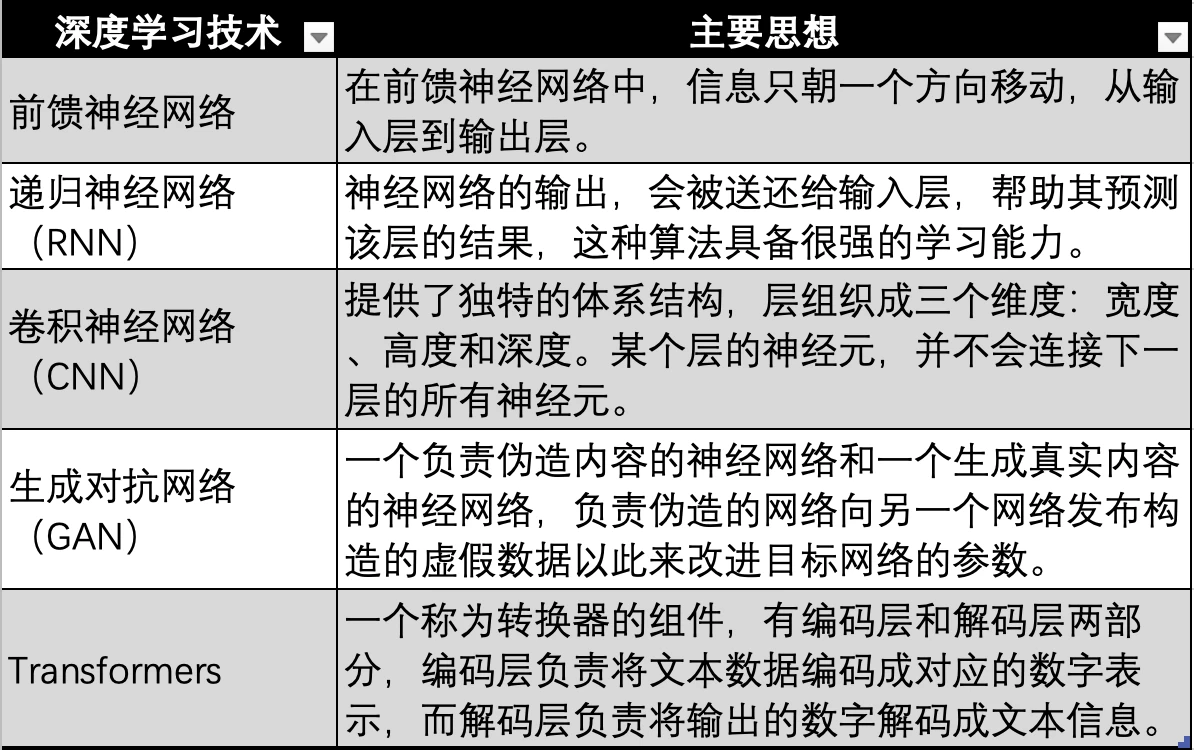
วิวัฒนาการของเทคโนโลยีการเรียนรู้เชิงลึก ที่มา: Gate Ventures
เทคโนโลยีการเรียนรู้เชิงลึกที่ใช้โครงข่ายประสาทเทียมยังมีการทำซ้ำทางเทคนิคและวิวัฒนาการหลายประการ เช่น โครงข่ายประสาทเทียมที่เก่าแก่ที่สุดในภาพด้านบน โครงข่ายประสาทเทียมแบบป้อนไปข้างหน้า, RNN, CNN, GAN และในที่สุดก็พัฒนาเป็นเทคโนโลยี Transformer ที่ใช้โดยโมเดลขนาดใหญ่สมัยใหม่ เช่น GPT เทคโนโลยี Transformer เป็นเพียงทิศทางวิวัฒนาการของโครงข่ายประสาทเทียม โดยจะเพิ่มตัวแปลงเพิ่มเติม (Transformer) ซึ่งใช้ในการเข้ารหัสข้อมูลในรูปแบบต่างๆ ทั้งหมด (เช่น เสียง วิดีโอ รูปภาพ ฯลฯ) ให้เป็นค่าตัวเลขที่สอดคล้องกัน จากนั้นจะถูกป้อนเข้าไปในโครงข่ายประสาทเทียม เพื่อให้โครงข่ายประสาทเทียมสามารถใส่ข้อมูลประเภทใดก็ได้ กล่าวคือ เพื่อให้ได้หลายรูปแบบ
การพัฒนา AI เกิดขึ้นมาแล้ว 3 คลื่นด้วยกัน คลื่นลูกแรกเกิดขึ้นในช่วงทศวรรษ 1960 สิบปีหลังจากที่มีการเสนอเทคโนโลยี AI คลื่นลูกนี้เกิดจากการพัฒนาเทคโนโลยีเชิงสัญลักษณ์ ซึ่งช่วยแก้ปัญหาการประมวลผลภาษาธรรมชาติทั่วไปและเครื่องจักรของมนุษย์ การประมวลผลคำถามสนทนา ในเวลาเดียวกัน ระบบผู้เชี่ยวชาญก็ถือกำเนิดขึ้น นี่คือระบบผู้เชี่ยวชาญ DENRAL ที่สร้างโดยมหาวิทยาลัยสแตนฟอร์ดภายใต้การดูแลของ NASA ผู้เชี่ยวชาญด้านเคมี ระบบนี้ถือเป็นการผสมผสานระหว่างฐานความรู้ทางเคมีและระบบอนุมาน
หลังจากระบบผู้เชี่ยวชาญ นักวิทยาศาสตร์และนักปรัชญาชาวอิสราเอล-อเมริกัน จูเดีย เพิร์ล ได้เสนอเครือข่ายแบบเบย์ในปี 1990 ซึ่งเป็นที่รู้จักในชื่อเครือข่ายความเชื่อ ในเวลาเดียวกัน Brooks ได้เสนอวิทยาการหุ่นยนต์ตามพฤติกรรม ซึ่งเป็นจุดกำเนิดของพฤติกรรมนิยม
ในปี 1997 IBM Deep Blue Blue เอาชนะแชมป์หมากรุก Kasparov 3.5: 2.5 ชัยชนะครั้งนี้ถือเป็นเหตุการณ์สำคัญในด้านปัญญาประดิษฐ์ และเทคโนโลยี AI ก็ได้นำไปสู่จุดไคลแม็กซ์ที่สองของการพัฒนา
คลื่นลูกที่ 3 ของเทคโนโลยี AI เกิดขึ้นในปี 2549 ยักษ์ใหญ่แห่งการเรียนรู้เชิงลึกทั้งสาม ได้แก่ Yann LeCun, Geoffrey Hinton และ Yoshua Bengio เสนอแนวคิดของการเรียนรู้เชิงลึก ซึ่งเป็นอัลกอริธึมที่ใช้เครือข่ายประสาทเทียมเป็นกรอบงานในการเรียนรู้การเป็นตัวแทนของข้อมูล หลังจากนั้น อัลกอริธึมการเรียนรู้เชิงลึกก็ค่อยๆ พัฒนา จาก RNN และ GAN ไปจนถึง Transformer และ Stable Diffusion อัลกอริธึมทั้งสองนี้ร่วมกันกำหนดรูปแบบคลื่นลูกที่สามของเทคโนโลยีนี้ และนี่ก็เป็นยุครุ่งเรืองของการเชื่อมต่อ
เหตุการณ์สำคัญต่างๆ มากมายได้ค่อยๆ เกิดขึ้นพร้อมกับการสำรวจและวิวัฒนาการของเทคโนโลยีการเรียนรู้เชิงลึก ได้แก่:
● ในปี 2011 Watson ของ IBM เอาชนะมนุษย์และคว้าแชมป์ในรายการตอบคำถาม Jeopardy
● ในปี 2014 Goodfellow เสนอ GAN (Generative Adversarial Network) ซึ่งเรียนรู้โดยการให้โครงข่ายประสาทสองเครือข่ายแข่งขันกันเพื่อสร้างภาพถ่ายที่ดูสมจริง ในเวลาเดียวกัน Goodfellow ยังได้เขียนหนังสือ Deep Learning ที่เรียกว่า Flower Book ซึ่งเป็นหนึ่งในหนังสือแนะนำที่สำคัญเกี่ยวกับการเรียนรู้เชิงลึก
● ในปี 2015 Hinton และคณะเสนออัลกอริทึมการเรียนรู้เชิงลึกในนิตยสาร Nature ข้อเสนอของวิธีการเรียนรู้เชิงลึกนี้ทำให้เกิดการตอบรับอย่างมากในแวดวงวิชาการและอุตสาหกรรม
● ในปี 2015 OpenAI ถูกสร้างขึ้น และ Musk, ประธาน YC Altman, Angel Investor Peter Thiel และคนอื่นๆ ได้ประกาศการร่วมลงทุนมูลค่า 1 พันล้านดอลลาร์สหรัฐ
● ในปี 2016 AlphaGo ซึ่งใช้เทคโนโลยีการเรียนรู้เชิงลึกได้แข่งขันกับแชมป์โลก Go และผู้เล่น 9-dan Go มืออาชีพ Lee Sedol ในการต่อสู้ระหว่างมนุษย์กับเครื่องจักร Go และชนะด้วยคะแนนรวม 4 ต่อ 1
● ในปี 2017 หุ่นยนต์ฮิวแมนนอยด์โซเฟียที่พัฒนาโดย Hanson Robotics ในฮ่องกง ประเทศจีน ได้รับการขนานนามว่าเป็นหุ่นยนต์ตัวแรกในประวัติศาสตร์ที่ได้รับสถานะพลเมืองชั้นหนึ่ง โดยมีการแสดงออกทางสีหน้าที่หลากหลายและความสามารถในการเข้าใจภาษาของมนุษย์
● ในปี 2017 Google ซึ่งมีความสามารถและทุนสำรองด้านเทคนิคมากมายในด้านปัญญาประดิษฐ์ ได้ตีพิมพ์บทความ Attention is all you need และเสนออัลกอริทึมของ Transformer และแบบจำลองภาษาขนาดใหญ่ก็เริ่มปรากฏให้เห็น
● ในปี 2018 OpenAI ได้เปิดตัว GPT (Generative Pre-trained Transformer) โดยใช้อัลกอริธึม Transformer ซึ่งเป็นหนึ่งในโมเดลภาษาที่ใหญ่ที่สุดในขณะนั้น
● ในปี 2018 ทีม Google Deepmind เปิดตัว AlphaGo โดยใช้การเรียนรู้เชิงลึก ซึ่งสามารถทำนายโครงสร้างของโปรตีนได้ และถือเป็นสัญญาณของความก้าวหน้าอย่างมากในด้านปัญญาประดิษฐ์
● ในปี 2019 OpenAI ได้เปิดตัว GPT-2 ซึ่งเป็นโมเดลที่มีพารามิเตอร์ 1.5 พันล้านพารามิเตอร์
● ในปี 2020 GPT-3 ที่พัฒนาโดย OpenAI มีพารามิเตอร์ 175 พันล้านพารามิเตอร์ ซึ่งสูงกว่า GPT-2 เวอร์ชันก่อนหน้าถึง 100 เท่า โมเดลนี้ใช้ข้อความ 570 GB ในการฝึกและสามารถนำไปใช้ในงาน NLP (การประมวลผลภาษาธรรมชาติ) ได้หลายงาน ( ตอบคำถาม แปล เขียนบทความ) เพื่อให้บรรลุผลการปฏิบัติงานที่ล้ำสมัย
● ในปี 2021 OpenAI เปิดตัว GPT-4 รุ่นนี้มีพารามิเตอร์ 1.76 ล้านล้านพารามิเตอร์ ซึ่งมากกว่า GPT-3 ถึง 10 เท่า
● แอปพลิเคชัน ChatGPT ที่ใช้รุ่น GPT-4 เปิดตัวในเดือนมกราคม 2023 ในเดือนมีนาคม ChatGPT มีผู้ใช้ถึง 100 ล้านคน กลายเป็นแอปพลิเคชันที่เร็วที่สุดในประวัติศาสตร์ในการเข้าถึงผู้ใช้ 100 ล้านคน
● ในปี 2024 OpenAI เปิดตัว GPT-4 omni
ห่วงโซ่อุตสาหกรรมการเรียนรู้เชิงลึก
ปัจจุบันภาษาโมเดลขนาดใหญ่ใช้วิธีการเรียนรู้เชิงลึกโดยใช้โครงข่ายประสาทเทียม โมเดลขนาดใหญ่ที่นำโดย GPT ได้สร้างคลื่นแห่งความคลั่งไคล้ปัญญาประดิษฐ์จำนวนมาก เรายังพบว่าความต้องการของตลาดสำหรับข้อมูลและพลังการประมวลผลจึงเพิ่มขึ้นอย่างมาก สำรวจเชิงลึกเป็นหลัก ห่วงโซ่อุตสาหกรรมของอัลกอริธึมการเรียนรู้ ในอุตสาหกรรม AI ที่ถูกครอบงำโดยอัลกอริธึมการเรียนรู้เชิงลึก องค์ประกอบต้นน้ำและปลายน้ำประกอบด้วยอย่างไร และสถานการณ์ปัจจุบัน ความสัมพันธ์ระหว่างอุปสงค์และอุปทาน และการพัฒนาต้นน้ำในอนาคต และปลายน้ำ

ไปป์ไลน์การฝึกอบรม GPT แหล่งที่มา: WaytoAI
ก่อนอื่น เราต้องชัดเจนว่าเมื่อมีการฝึกอบรม LLM (รุ่นขนาดใหญ่) ที่ใช้ GPT ที่ใช้เทคโนโลยี Transformer จะมีสามขั้นตอน
ก่อนการฝึกอบรม เนื่องจากใช้ Transformer ตัวแปลงจึงต้องแปลงการป้อนข้อความเป็นค่าตัวเลข กระบวนการนี้เรียกว่า Tokenization จากนั้นค่าตัวเลขเหล่านี้เรียกว่า Token ภายใต้กฎทั่วไป คำหรืออักขระภาษาอังกฤษหนึ่งคำสามารถถือเป็นโทเค็นหนึ่งรายการได้โดยประมาณ ในขณะที่อักขระจีนแต่ละตัวสามารถถือเป็นโทเค็นสองรายการโดยประมาณได้ นี่เป็นหน่วยพื้นฐานที่ใช้สำหรับการกำหนดราคา GPT ด้วย
ขั้นตอนแรกคือการฝึกอบรมล่วงหน้า ด้วยการให้คู่ข้อมูลที่เพียงพอแก่เลเยอร์อินพุต คล้ายกับตัวอย่าง (X, Y) ในส่วนแรกของรายงาน เราสามารถค้นหาพารามิเตอร์ที่เหมาะสมที่สุดของแต่ละเซลล์ประสาทภายใต้แบบจำลอง ซึ่งต้องใช้ข้อมูลจำนวนมากและกระบวนการนี้ เป็นกระบวนการที่ลำบากที่สุดเช่นกัน เป็นกระบวนการที่ต้องใช้การคำนวณมากเพราะจำเป็นต้องวนซ้ำเซลล์ประสาทซ้ำ ๆ เพื่อลองใช้พารามิเตอร์ต่างๆ หลังจากชุดข้อมูลได้รับการฝึกอบรมแล้ว โดยทั่วไปข้อมูลชุดเดียวกันจะถูกนำมาใช้สำหรับการฝึกอบรมรองเพื่อวนซ้ำพารามิเตอร์
ขั้นตอนที่สองคือการปรับแต่งอย่างละเอียด การปรับแต่งอย่างละเอียดคือการให้ข้อมูลชุดเล็กๆ ที่มีคุณภาพสูงมากสำหรับการฝึก การเปลี่ยนแปลงดังกล่าวจะทำให้เอาท์พุตของโมเดลมีคุณภาพสูงขึ้น เนื่องจากการฝึกล่วงหน้าต้องใช้ข้อมูลจำนวนมาก แต่ข้อมูลจำนวนมากอาจมีข้อผิดพลาด หรือคุณภาพต่ำ ขั้นตอนการปรับแต่งอย่างละเอียดสามารถปรับปรุงคุณภาพของโมเดลด้วยข้อมูลที่ดีได้
ขั้นตอนที่สามคือการเสริมสร้างการเรียนรู้ ประการแรก โมเดลใหม่จะถูกสร้างขึ้น ซึ่งเราเรียกว่า โมเดลรางวัล จุดประสงค์ของโมเดลนี้ง่ายมาก ซึ่งก็คือการจัดเรียงผลลัพธ์ ดังนั้น การใช้โมเดลนี้จึงค่อนข้างง่ายเนื่องจากธุรกิจ สถานการณ์ค่อนข้างเป็นแนวตั้ง จากนั้นแบบจำลองนี้จะใช้เพื่อตรวจสอบว่าผลลัพธ์ของแบบจำลองขนาดใหญ่ของเรามีคุณภาพสูงหรือไม่ เพื่อให้แบบจำลองรางวัลสามารถใช้เพื่อวนซ้ำพารามิเตอร์ของแบบจำลองขนาดใหญ่ได้โดยอัตโนมัติ (แต่บางครั้งการมีส่วนร่วมของมนุษย์ก็จำเป็นต้องตัดสินคุณภาพผลลัพธ์ของแบบจำลองด้วย)
กล่าวโดยสรุป ในกระบวนการฝึกอบรมของโมเดลขนาดใหญ่ การฝึกอบรมล่วงหน้ามีข้อกำหนดที่สูงมากเกี่ยวกับปริมาณข้อมูล และใช้พลังการประมวลผล GPU มากที่สุด ในขณะที่การปรับแต่งอย่างละเอียดต้องใช้ข้อมูลคุณภาพสูงกว่าเพื่อปรับปรุงพารามิเตอร์และเสริมสร้างการเรียนรู้ให้แข็งแกร่งยิ่งขึ้น ผ่านโมเดลการให้รางวัลเพื่อให้ได้ผลลัพธ์ที่มีคุณภาพสูงขึ้น
ในระหว่างกระบวนการฝึก ยิ่งมีพารามิเตอร์มากเท่าใด ความสามารถในการสรุปทั่วไปก็จะยิ่งสูงขึ้นเท่านั้น ตัวอย่างเช่น ในตัวอย่างฟังก์ชันของเรา Y = aX + b จริงๆ แล้วจะมีเซลล์ประสาทสองตัว X และ X 0 ดังนั้นพารามิเตอร์ ไม่ว่าจะเปลี่ยนแปลงไปอย่างไร ข้อมูลที่สามารถใส่ได้นั้นมีจำกัดอย่างมาก เนื่องจากสาระสำคัญของมันยังคงเป็นเส้นตรง หากมีเซลล์ประสาทมากขึ้น สามารถทำซ้ำพารามิเตอร์ได้มากขึ้น และสามารถติดตั้งข้อมูลได้มากขึ้น นี่คือสาเหตุที่แบบจำลองขนาดใหญ่ทำงานได้อย่างมหัศจรรย์ และนี่คือสาเหตุที่ชื่อยอดนิยมคือแบบจำลองขนาดใหญ่ สาระสำคัญคือเซลล์ประสาท พารามิเตอร์ และข้อมูลต้องใช้พลังการประมวลผลจำนวนมหาศาล
ดังนั้น ประสิทธิภาพของโมเดลขนาดใหญ่จึงถูกกำหนดโดยสามส่วนหลัก ได้แก่ จำนวนพารามิเตอร์ ปริมาณและคุณภาพของข้อมูล และพลังการประมวลผล ทั้งสามส่วนนี้ร่วมกันส่งผลต่อคุณภาพผลลัพธ์และความสามารถทั่วไปของโมเดลขนาดใหญ่ เราถือว่าจำนวนพารามิเตอร์คือ p และจำนวนข้อมูลคือ n (คำนวณตามจำนวนโทเค็น) จากนั้นเราสามารถคำนวณจำนวนการคำนวณที่ต้องการผ่านกฎทั่วไปทั่วไป เพื่อให้เราสามารถประมาณกำลังการคำนวณโดยประมาณได้ เราจำเป็นต้องซื้อและเวลาในการฝึกอบรม
โดยทั่วไปพลังการคำนวณจะขึ้นอยู่กับ Flops เป็นหน่วยพื้นฐาน ซึ่งแสดงถึงการดำเนินการจุดลอยตัวเป็นคำทั่วไปสำหรับการบวก ลบ คูณ และหารค่าที่ไม่ใช่จำนวนเต็ม เช่น 2.5+ 3.557 ซึ่งสามารถมีจุดทศนิยมได้ และ FP 16 หมายความว่ารองรับความแม่นยำของทศนิยม โดยทั่วไปแล้ว FP 32 จะเป็นความแม่นยำทั่วไปมากกว่า ตามกฎทั่วไปในทางปฏิบัติ การฝึกล่วงหน้าโมเดลขนาดใหญ่ (โดยปกติหลายครั้ง) ต้องใช้ประมาณ 6 np Flops และ 6 เรียกว่าค่าคงที่ของอุตสาหกรรม การอนุมาน (การอนุมานซึ่งเป็นกระบวนการที่เราป้อนข้อมูลและรอเอาต์พุตของโมเดลขนาดใหญ่) แบ่งออกเป็นสองส่วนคือการป้อนโทเค็น n และเอาต์พุตโทเค็น n ดังนั้นจึงต้องมีทั้งหมดประมาณ 2 np Flops
ในช่วงแรกๆ ชิป CPU ถูกใช้ในการฝึกอบรมเพื่อรองรับพลังการประมวลผล แต่ต่อมาเริ่มถูกแทนที่ด้วย GPU เช่น ชิป A 100 และ H 100 ของ Nvidia เนื่องจาก CPU มีอยู่ในรูปแบบการประมวลผลทั่วไป แต่ GPU สามารถใช้เป็นคอมพิวเตอร์เฉพาะได้ ซึ่งเกินกว่า CPU มากในด้านประสิทธิภาพการใช้พลังงาน GPU ดำเนินการจุดลอยตัวผ่านโมดูลที่เรียกว่า Tensor Core เป็นหลัก ดังนั้นชิปทั่วไปจึงมีข้อมูล Flops ที่ความแม่นยำ FP 16 / FP 32 ซึ่งแสดงถึงพลังการประมวลผลหลักและยังเป็นหนึ่งในตัวชี้วัดการวัดหลักของชิปอีกด้วย
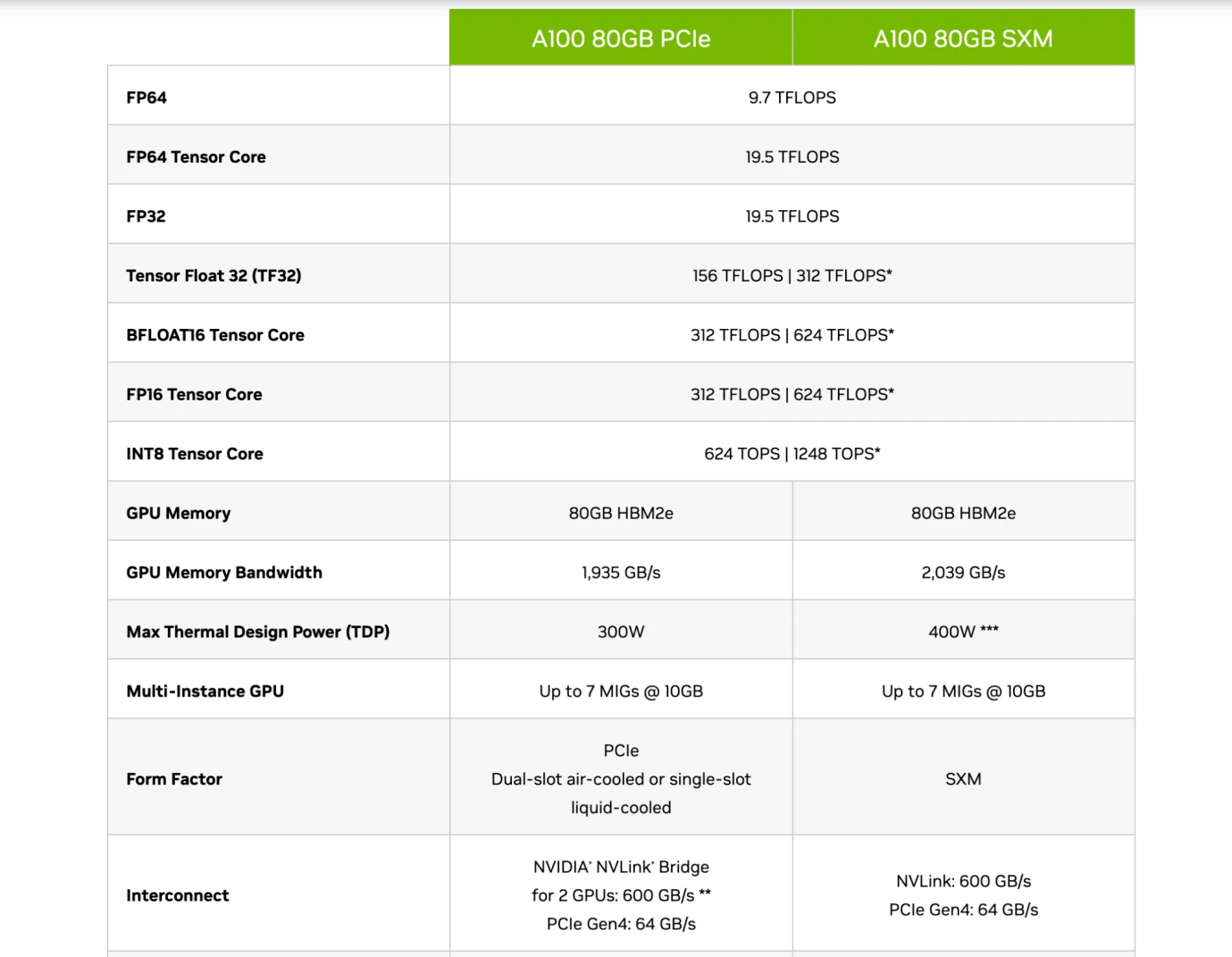
ข้อมูลจำเพาะของชิป Nvidia A 100 ที่มา: Nvidia
ดังนั้นผู้อ่านควรจะสามารถเข้าใจการแนะนำชิปของบริษัทเหล่านี้ได้ ดังแสดงในรูปด้านบน เมื่อเปรียบเทียบระหว่างรุ่น A 100 80 GB PCIe และ SXM ของ Nvidia จะเห็นได้ว่า PCIe และ SXM อยู่ภายใต้ Tensor Core (a โมดูลสำหรับการประมวลผล AI โดยเฉพาะ) ที่ความแม่นยำ FP 16 มีค่าเท่ากับ 312 TFLOPS และ 624 TFLOPS (Trillion Flops) ตามลำดับ
สมมติว่าพารามิเตอร์โมเดลขนาดใหญ่ของเราใช้ GPT 3 เป็นตัวอย่าง โดยมีพารามิเตอร์ 175 พันล้านพารามิเตอร์และปริมาณข้อมูล 180 พันล้านโทเค็น (ประมาณ 570 GB) จากนั้นในระหว่างการฝึกอบรมล่วงหน้า ต้องใช้ 6 np Flops ซึ่งมีค่าประมาณ 3.15 * 1,022 Flops หากวัดเป็น TFLOPS (ล้านล้าน FLOP) จะอยู่ที่ประมาณ 3.15* 1010 TFLOPS ซึ่งหมายความว่าชิปรุ่น SXM จะใช้เวลาประมาณ 50480769 วินาที, 841346 นาที, 14022 ชั่วโมง และ 584 วัน สำหรับชิปรุ่น SXM เพื่อฝึกฝน GPT 3 ล่วงหน้าหนึ่งครั้ง
เราจะเห็นได้ว่านี่เป็นการคำนวณจำนวนมหาศาล ต้องใช้ชิปที่ล้ำสมัยหลายตัวในการดำเนินการฝึกล่วงหน้า นอกจากนี้ จำนวนพารามิเตอร์ของ GPT 4 ยังเป็นสิบเท่าของ GPT 3 (1.76 ล้านล้าน) ซึ่งหมายความว่าแม้ว่าข้อมูลหากปริมาณยังคงไม่เปลี่ยนแปลงก็ต้องซื้อจำนวนชิปเพิ่มอีกสิบเท่าและจำนวนโทเค็นของ GPT-4 ก็คือ 13 ล้านล้านซึ่งมากกว่าสิบเท่าของ GPT-3 ในท้ายที่สุด GPT-4 อาจต้องใช้พลังประมวลผลมากกว่า 100 เท่า
ในการฝึกโมเดลขนาดใหญ่ เรายังมีปัญหากับการจัดเก็บข้อมูล เนื่องจากข้อมูลของเรา เช่น หมายเลขโทเค็น GPT 3 มีจำนวน 180 พันล้าน ครอบครองพื้นที่เก็บข้อมูลประมาณ 570 GB และโครงข่ายประสาทเทียมขนาดใหญ่ที่มีพารามิเตอร์ 175 พันล้านใช้พื้นที่ประมาณ 700 GB พื้นที่เก็บข้อมูล พื้นที่หน่วยความจำของ GPU โดยทั่วไปมีขนาดเล็ก (ดังแสดงในรูปด้านบน A 100 คือ 80 GB) ดังนั้นเมื่อพื้นที่หน่วยความจำไม่สามารถรองรับข้อมูลได้จึงจำเป็นต้องตรวจสอบแบนด์วิธของชิปนั่นคือการส่งผ่านข้อมูล ความเร็วของข้อมูลจากฮาร์ดดิสก์ไปยังหน่วยความจำ ในเวลาเดียวกัน เนื่องจากเราจะไม่ใช้ชิปเพียงตัวเดียว เราจึงต้องใช้วิธีการเรียนรู้ร่วมกันเพื่อร่วมกันฝึกโมเดลขนาดใหญ่บนชิป GPU หลายตัว ซึ่งเกี่ยวข้องกับอัตราการส่งข้อมูลของ GPU ระหว่างชิป ดังนั้น ในหลายกรณี ปัจจัยหรือต้นทุนที่จำกัดการฝึกโมเดลขั้นสุดท้ายจึงไม่จำเป็นต้องเป็นพลังการประมวลผลของชิป แต่มักจะเป็นแบนด์วิธของชิปมากกว่า เนื่องจากการส่งข้อมูลทำได้ช้า จึงอาจใช้เวลานานขึ้นในการรันโมเดลและเพิ่มต้นทุนด้านพลังงาน

ข้อมูลจำเพาะชิป H 100 SXM, ที่มา: Nvidia
ในเวลานี้ ผู้อ่านสามารถเข้าใจข้อมูลจำเพาะของชิปได้อย่างคร่าวๆ โดยที่ FP 16 แสดงถึงความแม่นยำ เนื่องจากส่วนประกอบ Tensor Core ส่วนใหญ่จะใช้เพื่อฝึก AI LLM คุณเพียงแค่ต้องดูพลังการประมวลผลของส่วนประกอบนี้เท่านั้น FP 64 Tensor Core แสดงถึง H 100 SXM ที่สามารถประมวลผล 67 TFLOPS ต่อวินาทีที่ความแม่นยำ 64 หน่วยความจำ GPU หมายความว่าหน่วยความจำของชิปมีขนาดเพียง 64 GB ซึ่งไม่สามารถตอบสนองความต้องการในการจัดเก็บข้อมูลของรุ่นใหญ่ได้อย่างสมบูรณ์ ดังนั้น แบนด์วิดท์หน่วยความจำ GPU จึงหมายถึงความเร็วในการส่งข้อมูล H 100 SXM
ห่วงโซ่มูลค่า AI ที่มา: Nasdaq
เราได้เห็นแล้วว่าการเพิ่มจำนวนข้อมูลและพารามิเตอร์ของเซลล์ประสาททำให้เกิดช่องว่างขนาดใหญ่ในด้านพลังการประมวลผลและข้อกำหนดในการจัดเก็บข้อมูล องค์ประกอบหลักทั้งสามนี้ได้บ่มเพาะห่วงโซ่อุตสาหกรรมทั้งหมด เราจะใช้รูปด้านบนเพื่อแนะนำบทบาทและหน้าที่ของแต่ละส่วนในห่วงโซ่อุตสาหกรรม
ผู้ให้บริการฮาร์ดแวร์ GPU
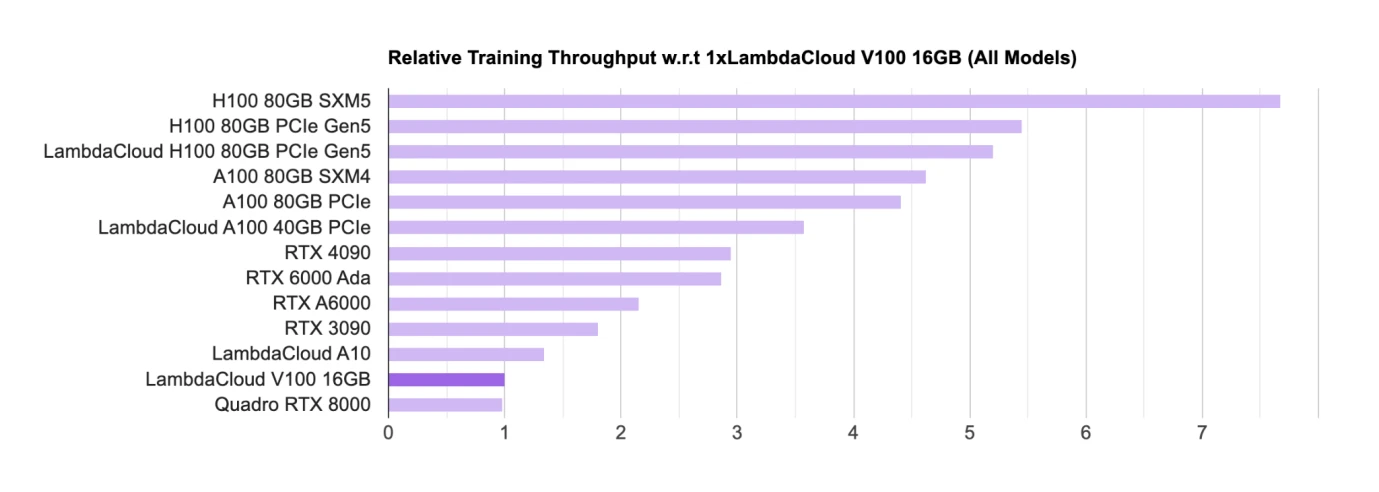
การจัดอันดับชิป AI GPU ที่มา: Lambda
ปัจจุบันฮาร์ดแวร์เช่น GPU เป็นชิปหลักสำหรับการฝึกอบรมและการอนุมาน สำหรับผู้ออกแบบชิป GPU หลัก ปัจจุบัน Nvidia อยู่ในตำแหน่งผู้นำอย่างแท้จริง GPU สำหรับเล่นเกม) อุตสาหกรรมส่วนใหญ่ใช้ H 100, A 100 ฯลฯ เพื่อการค้าโมเดลขนาดใหญ่
ในรายการ ชิปของ Nvidia เกือบจะครองรายการ และชิปทั้งหมดมาจาก Nvidia Google ยังมีชิป AI ของตัวเองที่เรียกว่า TPU แต่ Google Cloud ใช้ TPU เป็นหลักเพื่อให้การสนับสนุนด้านการประมวลผลสำหรับบริษัท B-side โดยทั่วไปแล้วมักจะซื้อ Nvidia GPU
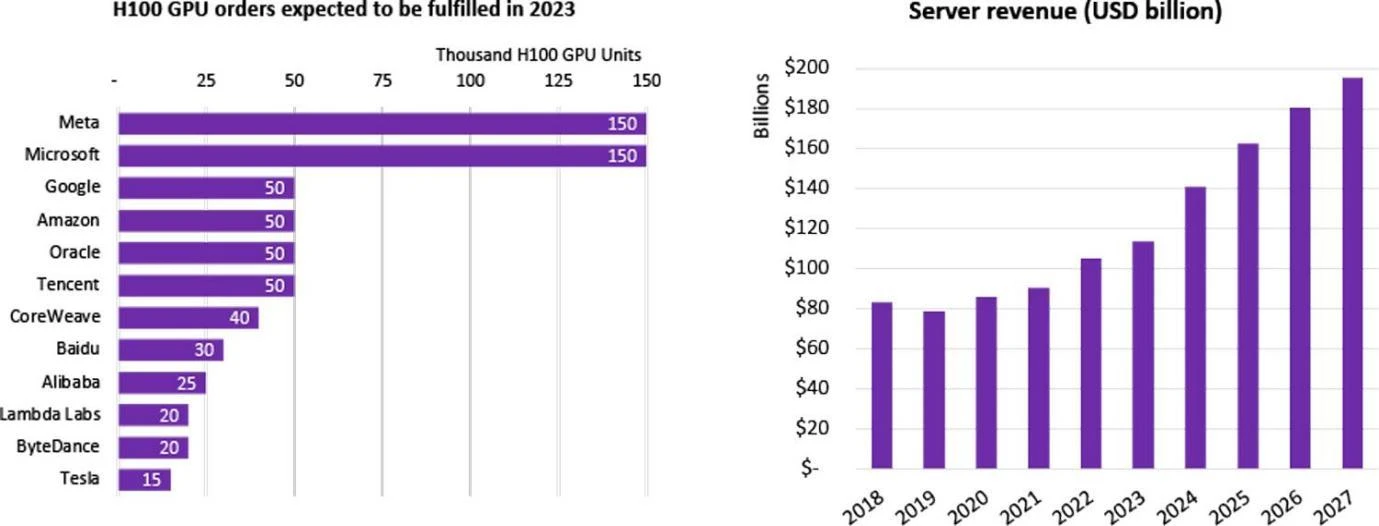
สถิติการซื้อ GPU H 100 โดยบริษัท ที่มา: Omdia
บริษัทจำนวนมากได้เริ่มดำเนินการวิจัยและพัฒนา LLM ซึ่งรวมถึงโมเดลขนาดใหญ่มากกว่า 100 แห่งในจีน และมีโมเดลภาษาขนาดใหญ่มากกว่า 200 โมเดลที่ได้รับการเผยแพร่ทั่วโลก บริษัทเหล่านี้ซื้อโมเดลขนาดใหญ่ด้วยตนเองหรือเช่าผ่านบริษัทคลาวด์ ในปี 2023 ชิป H 100 ที่ทันสมัยที่สุดของ Nvidia ได้รับการสมัครเป็นสมาชิกจากหลายบริษัททันทีที่เปิดตัว ความต้องการชิป H 100 ทั่วโลกมีมากกว่าอุปทาน เนื่องจากปัจจุบันมีเพียง Nvidia เท่านั้นที่จัดหาชิประดับสูงสุด และรอบการจัดส่งก็ยาวนานถึง 52 สัปดาห์อย่างน่าประหลาดใจ
ในมุมมองของการผูกขาดของ Nvidia นั้น Google ซึ่งเป็นหนึ่งในผู้นำด้านปัญญาประดิษฐ์อย่างแท้จริงได้เป็นผู้นำ Intel, Qualcomm, Microsoft และ Amazon ได้ร่วมกันก่อตั้ง CUDA Alliance โดยหวังที่จะร่วมกันพัฒนา GPU เพื่อกำจัดอิทธิพลที่แท้จริงของ Nvidia ที่มีต่อ ห่วงโซ่อุตสาหกรรมการเรียนรู้เชิงลึก
สำหรับบริษัทเทคโนโลยีขนาดใหญ่/ผู้ให้บริการคลาวด์/ห้องปฏิบัติการระดับชาติ พวกเขามักจะซื้อชิป H 100 หลายพันหรือหลายหมื่นตัวเพื่อสร้าง HPC (ศูนย์ประมวลผลประสิทธิภาพสูง) ตัวอย่างเช่น คลัสเตอร์ CoreWeave ของ Tesla ซื้อ H 100 80 GB จำนวนหนึ่งหมื่นชิ้น ราคาซื้อเฉลี่ยอยู่ที่ 44,000 เหรียญสหรัฐ (ราคา NVIDIA อยู่ที่ประมาณ 1/10) และมูลค่ารวมอยู่ที่ 440 ล้านเหรียญสหรัฐ Tencent ซื้อ 50,000 ชิ้น Meta ซื้อ 150,000 ชิ้น และภายในสิ้นปี 2566 เป็นเครื่องเดียวที่มีประสิทธิภาพสูง ผู้ขาย GPU, Nvidia สั่งซื้อชิป H 100 มากกว่า 500,000 ตัว
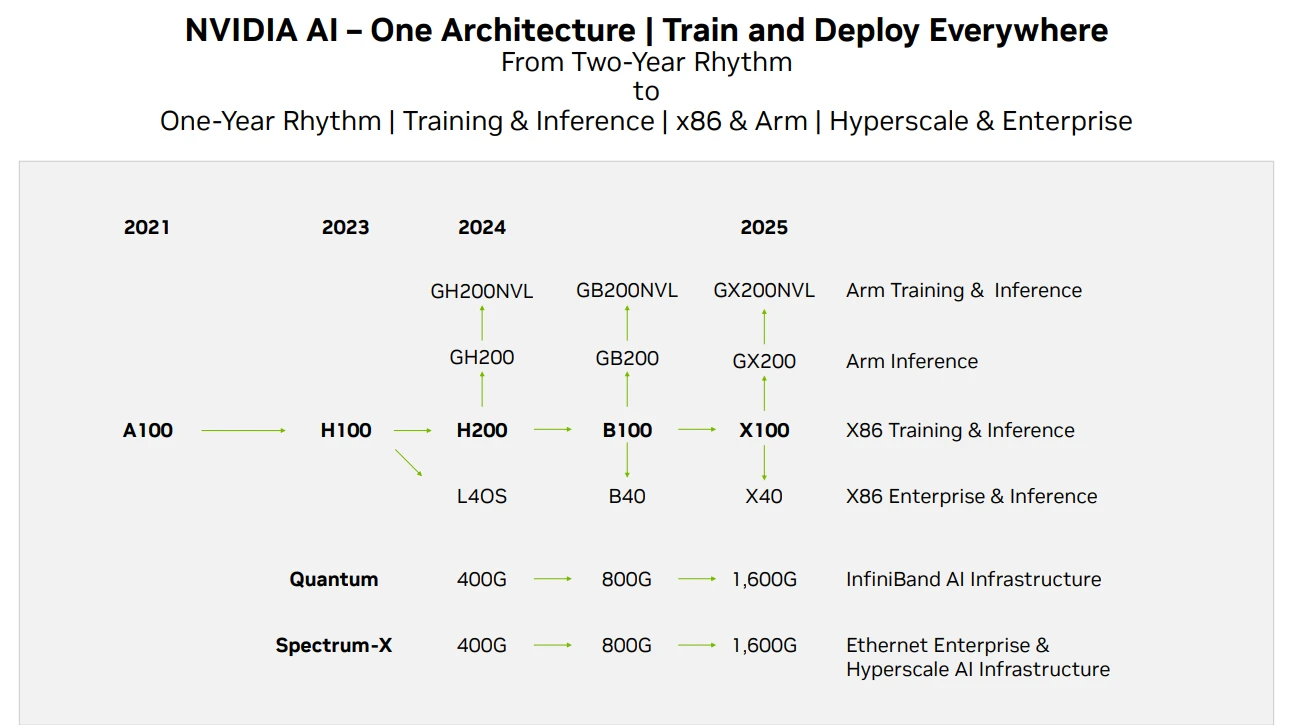
แผนงานผลิตภัณฑ์ Nvidia GPU ที่มา: Techwire
ในแง่ของการจัดหาชิปของ Nvidia ข้างต้นคือแผนงานการทำซ้ำผลิตภัณฑ์ ในรายงานนี้ ข่าวของ H 200 ได้รับการเผยแพร่ คาดว่าประสิทธิภาพของ H 200 จะเป็นสองเท่าของ H 100 ในขณะที่ B 100 จะเปิดตัวในช่วงปลายปี 2024 หรือต้นปี 2025 และจะเปิดตัว การพัฒนา GPU ในปัจจุบันยังคงเป็นไปตามกฎของมัวร์ โดยประสิทธิภาพจะเพิ่มขึ้นสองเท่าทุกๆ 2 ปีและราคาลดลงครึ่งหนึ่ง
ผู้ให้บริการคลาวด์

ประเภทของ GPU Cloud ที่มา: Salesforce Ventures
หลังจากที่ผู้ให้บริการระบบคลาวด์ซื้อ GPU เพียงพอที่จะตั้งค่า HPC พวกเขาสามารถมอบพลังการประมวลผลที่ยืดหยุ่นและโซลูชันการฝึกอบรมที่มีการจัดการให้กับบริษัทปัญญาประดิษฐ์ที่มีเงินทุนจำกัด ดังที่แสดงในรูปด้านบน ตลาดปัจจุบันแบ่งออกเป็นสามประเภทของผู้ให้บริการพลังงานการประมวลผลบนคลาวด์ ประเภทแรกคือการขยายแพลตฟอร์มพลังงานการประมวลผลบนคลาวด์ขนาดใหญ่พิเศษ (AWS, Google, Azure) ที่แสดงโดยผู้จำหน่ายระบบคลาวด์แบบดั้งเดิม . ประเภทที่สองคือแพลตฟอร์มการประมวลผลบนคลาวด์แนวตั้ง ซึ่งส่วนใหญ่ออกแบบมาสำหรับ AI หรือการประมวลผลประสิทธิภาพสูง พวกเขาให้บริการระดับมืออาชีพมากขึ้น ดังนั้นจึงยังมีพื้นที่ทางการตลาดที่แน่นอนในการแข่งขันกับบริษัทผู้ให้บริการคลาวด์อุตสาหกรรมแนวดิ่งประเภทนี้ ได้แก่ CoreWeave (ได้รับ 11 ดอลลาร์สหรัฐในการจัดหาเงินทุน Series C มูลค่า 19 พันล้านดอลลาร์สหรัฐ), Crusoe, Lambda (ได้รับ 260 ล้านดอลลาร์สหรัฐในการจัดหาเงินทุน Series C มูลค่ากว่า 1.5 พันล้านดอลลาร์สหรัฐ) เป็นต้น ผู้ให้บริการระบบคลาวด์ประเภทที่สามคือผู้เล่นในตลาดรายใหม่ โดยส่วนใหญ่เป็นผู้ให้บริการแบบอนุมาน ผู้ให้บริการเหล่านี้เช่า GPU จากผู้ให้บริการระบบคลาวด์เป็นหลัก การปรับแต่งหรือการให้เหตุผล บริษัทที่เป็นตัวแทนในตลาดประเภทนี้ ได้แก่ Together.ai (การประเมินมูลค่าล่าสุด 1.25 พันล้านดอลลาร์สหรัฐ), Fireworks.ai (การลงทุนที่นำโดยเกณฑ์มาตรฐาน, การจัดหาเงินทุน Series A มูลค่า 25 ล้านดอลลาร์สหรัฐ) เป็นต้น
ผู้ให้บริการ แหล่งข้อมูลการฝึกอบรม
ตามที่กล่าวไว้ก่อนหน้าในส่วนที่สองของเรา การฝึกอบรมโมเดลขนาดใหญ่ต้องผ่านสามขั้นตอนเป็นหลัก ได้แก่ การฝึกอบรมล่วงหน้า การปรับแต่งอย่างละเอียด และการเรียนรู้แบบเสริมกำลัง การฝึกอบรมล่วงหน้าต้องใช้ข้อมูลจำนวนมาก และการปรับแต่งอย่างละเอียดต้องใช้ข้อมูลคุณภาพสูง ดังนั้น บริษัทข้อมูลอย่าง Google (ซึ่งมีข้อมูลจำนวนมาก) และ Reddit (ซึ่งมีข้อมูลคำตอบคุณภาพสูง) จึงได้รับความนิยมอย่างแพร่หลาย ความสนใจจากตลาด
เพื่อไม่ให้แข่งขันกับโมเดลขนาดใหญ่ที่ใช้งานทั่วไป เช่น GPT นักพัฒนาบางรายจึงเลือกที่จะพัฒนาในสาขาย่อย ดังนั้นข้อกำหนดสำหรับข้อมูลจึงกลายเป็นข้อมูลที่ต้องเป็นข้อมูลเฉพาะอุตสาหกรรม เช่น การเงิน การแพทย์ เคมี ฟิสิกส์ ชีววิทยา ฯลฯ การจดจำภาพ ฯลฯ เหล่านี้เป็นโมเดลสำหรับฟิลด์เฉพาะและต้องการข้อมูลในฟิลด์เฉพาะ ดังนั้นจึงมีบริษัทที่ให้ข้อมูลสำหรับโมเดลขนาดใหญ่เหล่านี้ เรายังสามารถเรียกพวกเขาว่า Data labeling company ซึ่งหมายถึงการติดป้ายกำกับข้อมูลหลังจากรวบรวมข้อมูลเพื่อให้มีคุณภาพดีขึ้นและ ชนิดข้อมูลเฉพาะ
สำหรับบริษัทที่กำลังพัฒนาโมเดล ข้อมูลจำนวนมาก ข้อมูลคุณภาพสูง และข้อมูลเฉพาะคือความต้องการข้อมูลหลักสามประการ
บริษัทติดฉลากข้อมูลหลัก ที่มา: Venture Radar
การศึกษาโดย Microsoft เชื่อว่าสำหรับ SLM (โมเดลภาษาขนาดเล็ก) หากคุณภาพข้อมูลดีกว่าโมเดลภาษาขนาดใหญ่อย่างมาก ประสิทธิภาพก็ไม่จำเป็นต้องแย่กว่า LLM เสมอไป และในความเป็นจริง GPT ไม่มีข้อได้เปรียบที่ชัดเจนในด้านความคิดริเริ่มและข้อมูล ความกล้าหาญในการเดิมพันไปในทิศทางนี้เป็นหลักที่ก่อให้เกิดความสำเร็จ Sequoia America ยังยอมรับว่า GPT อาจไม่จำเป็นต้องรักษาความได้เปรียบทางการแข่งขันในอนาคต เหตุผลก็คือ ปัจจุบันไม่มีคูน้ำลึกในพื้นที่นี้ และข้อจำกัดหลักมาจากข้อจำกัดของการได้มาซึ่งพลังการประมวลผล
เกี่ยวกับปริมาณข้อมูล ตามการคาดการณ์ของ EpochAI ตามการเติบโตของขนาดแบบจำลองในปัจจุบัน ข้อมูลคุณภาพต่ำและคุณภาพสูงทั้งหมดจะหมดลงภายในปี 2573 ดังนั้น ปัจจุบันอุตสาหกรรมกำลังสำรวจข้อมูลสังเคราะห์ปัญญาประดิษฐ์ เพื่อให้สามารถสร้างข้อมูลได้ไม่จำกัด และคอขวดเป็นเพียงพลังในการคำนวณเท่านั้น ทิศทางนี้ยังอยู่ในขั้นตอนการสอบสวนและสมควรได้รับความสนใจจากนักพัฒนา
ผู้ให้บริการฐานข้อมูล
เรามีข้อมูล แต่ข้อมูลก็ต้องถูกจัดเก็บเช่นกัน ซึ่งโดยปกติจะอยู่ในฐานข้อมูล เพื่ออำนวยความสะดวกในการเพิ่ม ลบ ปรับเปลี่ยน และเรียกค้นข้อมูล ในธุรกิจอินเทอร์เน็ตแบบดั้งเดิม เราอาจเคยได้ยินเกี่ยวกับ MySQL และในไคลเอนต์ Ethereum Reth เราเคยได้ยินเกี่ยวกับ Redis เหล่านี้เป็นฐานข้อมูลท้องถิ่นที่เราจัดเก็บข้อมูลทางธุรกิจหรือข้อมูลบนบล็อกเชน มีการปรับฐานข้อมูลที่แตกต่างกันสำหรับประเภทข้อมูลหรือธุรกิจที่แตกต่างกัน
สำหรับงานข้อมูล AI และงานอนุมานการฝึกอบรมเชิงลึก ฐานข้อมูลที่ใช้ในอุตสาหกรรมในปัจจุบันเรียกว่า ฐานข้อมูลเวกเตอร์ ฐานข้อมูลเวกเตอร์ได้รับการออกแบบมาเพื่อจัดเก็บ จัดการ และจัดทำดัชนีข้อมูลเวกเตอร์มิติสูงจำนวนมหาศาลได้อย่างมีประสิทธิภาพ เนื่องจากข้อมูลของเราไม่ได้เป็นเพียงค่าตัวเลขหรือข้อความ แต่เป็นข้อมูลที่ไม่มีโครงสร้างจำนวนมาก เช่น รูปภาพและเสียง ฐานข้อมูลเวกเตอร์จึงสามารถจัดเก็บข้อมูลที่ไม่มีโครงสร้างเหล่านี้ในรูปแบบของ เวกเตอร์ และฐานข้อมูลเวกเตอร์เหมาะสำหรับการจัดเก็บและประมวลผลเวกเตอร์เหล่านี้

การจำแนกฐานข้อมูลเวกเตอร์ ที่มา: Yingjun Wu
ผู้เล่นหลักในปัจจุบัน ได้แก่ Chroma (ซึ่งได้รับเงินทุน 18 ล้านดอลลาร์), Zilliz (การระดมทุนรอบล่าสุดคือ 60 ล้านดอลลาร์), Pinecone, Weaviate เป็นต้น เราคาดหวังว่าด้วยความต้องการปริมาณข้อมูลที่เพิ่มขึ้นและการขยายตัวของโมเดลขนาดใหญ่และแอปพลิเคชันในสาขาเฉพาะต่างๆ ความต้องการฐานข้อมูลเวกเตอร์จะเพิ่มขึ้นอย่างมาก และเนื่องจากมีอุปสรรคทางเทคนิคที่แข็งแกร่งในสาขานี้ บริษัทที่เติบโตและมีลูกค้าในการลงทุนจึงควรพิจารณามากขึ้น
อุปกรณ์ขอบ
เมื่อสร้าง GPU HPC (คลัสเตอร์การประมวลผลประสิทธิภาพสูง) มักจะใช้พลังงานจำนวนมาก ซึ่งสร้างพลังงานความร้อนจำนวนมาก ในสภาพแวดล้อมที่มีอุณหภูมิสูง ชิปจะจำกัดความเร็วในการทำงานเพื่อลดอุณหภูมิ นี่คือสิ่งที่เรามักเรียกว่า การลดความถี่ ซึ่งต้องใช้อุปกรณ์ระบายความร้อนบางตัวเพื่อให้แน่ใจว่า HPC ทำงานอย่างต่อเนื่อง
ดังนั้นห่วงโซ่อุตสาหกรรมจึงเกี่ยวข้องกับสองทิศทาง ได้แก่ การจัดหาพลังงาน (โดยทั่วไปใช้พลังงานไฟฟ้า) และระบบทำความเย็น
ในปัจจุบัน ในด้านการจัดหาพลังงาน ไฟฟ้าส่วนใหญ่จะใช้ และศูนย์ข้อมูลและเครือข่ายสนับสนุนในปัจจุบันคิดเป็น 2% -3% ของการใช้ไฟฟ้าทั่วโลก BCG คาดการณ์ว่าเมื่อพารามิเตอร์ของโมเดลการเรียนรู้เชิงลึกขนาดใหญ่เพิ่มขึ้นและชิปถูกทำซ้ำ พลังงานที่จำเป็นในการฝึกโมเดลขนาดใหญ่จะเพิ่มขึ้นสามเท่าภายในปี 2573 ปัจจุบันผู้ผลิตเทคโนโลยีในประเทศและต่างประเทศกำลังลงทุนในบริษัทพลังงานอย่างจริงจัง ทิศทางการลงทุนหลักด้านพลังงาน ได้แก่ พลังงานความร้อนใต้พิภพ พลังงานไฮโดรเจน พลังงานสำรองแบตเตอรี่ และพลังงานนิวเคลียร์
ในแง่ของการทำความเย็นคลัสเตอร์ HPC การระบายความร้อนด้วยอากาศเป็นวิธีการหลักในปัจจุบัน แต่ VC จำนวนมากกำลังลงทุนอย่างมากในระบบทำความเย็นด้วยของเหลวเพื่อรักษาการทำงานของ HPC ที่ราบรื่น ตัวอย่างเช่น Jetcool อ้างว่าระบบระบายความร้อนด้วยของเหลวสามารถลดการใช้พลังงานทั้งหมดของคลัสเตอร์ H 100 ได้ถึง 15% ในปัจจุบัน การทำความเย็นด้วยของเหลวส่วนใหญ่แบ่งออกเป็นสามทิศทางการสำรวจ: การระบายความร้อนด้วยของเหลวในรูปแบบเย็น, การระบายความร้อนด้วยของเหลวแบบจุ่ม และการระบายความร้อนด้วยของเหลวแบบสเปรย์ บริษัทในพื้นที่นี้ ได้แก่: Huawei, Green Revolution Cooling, SGI เป็นต้น
แอปพลิเคชัน
การพัฒนาแอปพลิเคชัน AI ในปัจจุบันมีความคล้ายคลึงกับการพัฒนาของอุตสาหกรรมบล็อกเชน Transformer ได้รับการเสนอในฐานะอุตสาหกรรมที่เป็นนวัตกรรมในปี 2560 และ OpenAI ยืนยันประสิทธิภาพของโมเดลขนาดใหญ่เท่านั้นในปี 2566 ดังนั้นขณะนี้บริษัท Fomo จำนวนมากจึงหนาแน่นในการติดตามการวิจัยและพัฒนาของโมเดลขนาดใหญ่ นั่นคือโครงสร้างพื้นฐานมีความหนาแน่นมาก แต่การพัฒนาแอปพลิเคชันยังไม่สามารถก้าวทันได้

ผู้ใช้งานรายเดือน 50 อันดับแรก ที่มา: A16Z
ปัจจุบันแอปพลิเคชัน AI ที่ใช้งานอยู่ส่วนใหญ่ในช่วง 10 เดือนแรกเป็นแอปพลิเคชันประเภทการค้นหา แอปพลิเคชัน AI จริงที่เกิดขึ้นยังมีจำกัดมาก แอปพลิเคชันประเภทนี้ค่อนข้างจะเดี่ยว และไม่มีแอปพลิเคชันประเภทโซเชียลและประเภทอื่น ๆ ได้ออกมาสำเร็จแล้ว
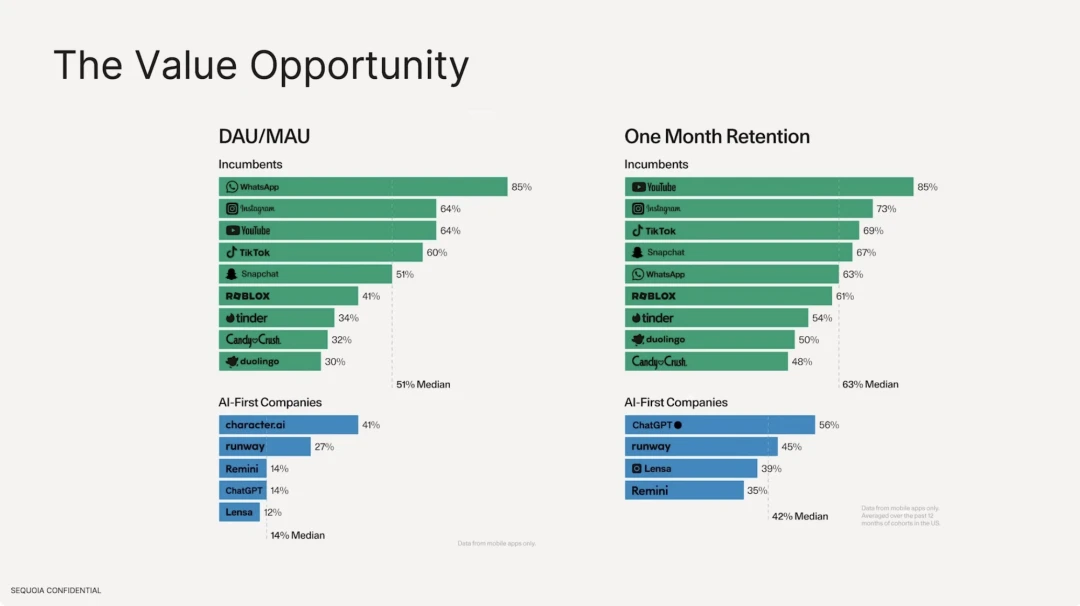
นอกจากนี้เรายังพบว่าอัตราการคงแอปพลิเคชัน AI ที่ใช้โมเดลขนาดใหญ่นั้นต่ำกว่าแอปพลิเคชันอินเทอร์เน็ตแบบเดิมที่มีอยู่มาก ในแง่ของจำนวนผู้ใช้งาน ค่ามัธยฐานของซอฟต์แวร์อินเทอร์เน็ตแบบเดิมคือ 51% โดยซอฟต์แวร์สูงสุดคือ Whatsapp ซึ่งมีผู้ใช้เหนียวแน่นมาก แต่ในด้านแอปพลิเคชัน AI นั้น DAU/MAU สูงสุดคือ character.ai ซึ่งมีเพียง 41% และ DAU คิดเป็นค่ามัธยฐาน 14% ของจำนวนผู้ใช้ทั้งหมด ในแง่ของอัตราการรักษาผู้ใช้ ซอฟต์แวร์อินเทอร์เน็ตแบบดั้งเดิมที่ดีที่สุดคือ Youtube, Instagram และ Tiktok อัตราการรักษาเฉลี่ยของสิบอันดับแรกคือ 63% เทียบกับอัตราการรักษาของ ChatGPT เพียง 56%

ภูมิทัศน์แอปพลิเคชัน AI ที่มา: Sequoia
ตามรายงานของ Sequoia America แบ่งการใช้งานออกเป็นสามประเภทจากมุมมองของการมุ่งเน้นตามบทบาท ได้แก่ สำหรับผู้บริโภคมืออาชีพ องค์กร และผู้บริโภคทั่วไป
1. มุ่งเน้นผู้บริโภค: โดยทั่วไปใช้เพื่อปรับปรุงประสิทธิภาพการทำงาน เช่น โปรแกรมส่งข้อความที่ใช้ GPT สำหรับการถามตอบ การสร้างแบบจำลองการเรนเดอร์ 3 มิติอัตโนมัติ การแก้ไขซอฟต์แวร์ เอเจนต์อัตโนมัติ และแอปพลิเคชันประเภทเสียงสำหรับการสนทนาด้วยเสียง มิตรภาพ แบบฝึกหัดภาษา ฯลฯ
2. สำหรับองค์กร: โดยทั่วไปแล้วการตลาด กฎหมาย การออกแบบทางการแพทย์ และอุตสาหกรรมอื่น ๆ
แม้ว่าหลายคนจะวิพากษ์วิจารณ์ว่าโครงสร้างพื้นฐานนั้นยิ่งใหญ่กว่าแอปพลิเคชันมาก แต่จริงๆ แล้วเราเชื่อว่าโลกสมัยใหม่ได้รับการเปลี่ยนแปลงอย่างกว้างขวางด้วยเทคโนโลยีปัญญาประดิษฐ์ แต่กลับใช้ระบบการแนะนำ เช่น TikTok, Toutiao และ Soda ภายใต้ ByteDance เป็นต้น เช่นเดียวกับบัญชีวิดีโอ Xiaohongshu และ WeChat เทคโนโลยีการแนะนำการโฆษณา ฯลฯ ล้วนเป็นคำแนะนำที่ปรับแต่งสำหรับบุคคล และทั้งหมดนี้ล้วนเป็นอัลกอริธึมการเรียนรู้ของเครื่อง ดังนั้นการเรียนรู้เชิงลึกที่กำลังเฟื่องฟูในปัจจุบันจึงไม่ได้เป็นตัวแทนของอุตสาหกรรม AI อย่างสมบูรณ์ มีเทคโนโลยีที่มีศักยภาพมากมายที่มีโอกาสที่จะตระหนักถึงปัญญาประดิษฐ์ทั่วไปและยังมีการพัฒนาควบคู่กันไปอีกด้วย และเทคโนโลยีเหล่านี้บางส่วนมีการใช้กันอย่างแพร่หลายในอุตสาหกรรมต่างๆ .
แล้วความสัมพันธ์แบบไหนที่พัฒนาขึ้นระหว่าง Crypto x AI? มีโครงการอื่นใดอีกบ้างที่ควรค่าแก่ความสนใจในห่วงโซ่คุณค่าของอุตสาหกรรม Crypto? เราจะอธิบายทีละเรื่องใน Gate Ventures: AI x Crypto from Beginner to Master (ตอนที่ 2)
ข้อสงวนสิทธิ์:
เนื้อหาข้างต้นมีไว้เพื่อการอ้างอิงเท่านั้นและไม่ควรถือเป็นคำแนะนำใดๆ ขอคำแนะนำจากผู้เชี่ยวชาญก่อนตัดสินใจลงทุนเสมอ
เกี่ยวกับ เกต เวนเจอร์
Gate Ventures เป็นบริษัทร่วมลงทุนของ Gate.io โดยมุ่งเน้นไปที่การลงทุนในโครงสร้างพื้นฐานแบบกระจายอำนาจ ระบบนิเวศ และแอปพลิเคชันที่จะเปลี่ยนโฉมโลกในยุค Web 3.0 Gate Ventures ทำงานร่วมกับผู้นำอุตสาหกรรมระดับโลกเพื่อเพิ่มศักยภาพให้กับทีมและสตาร์ทอัพด้วยความคิดสร้างสรรค์และความสามารถในการกำหนดรูปแบบปฏิสัมพันธ์ของสังคมและการเงินใหม่
เว็บไซต์อย่างเป็นทางการ: https://ventures.gate.io/
ทวิตเตอร์: https://x.com/gate_ventures





