




FHE là gì
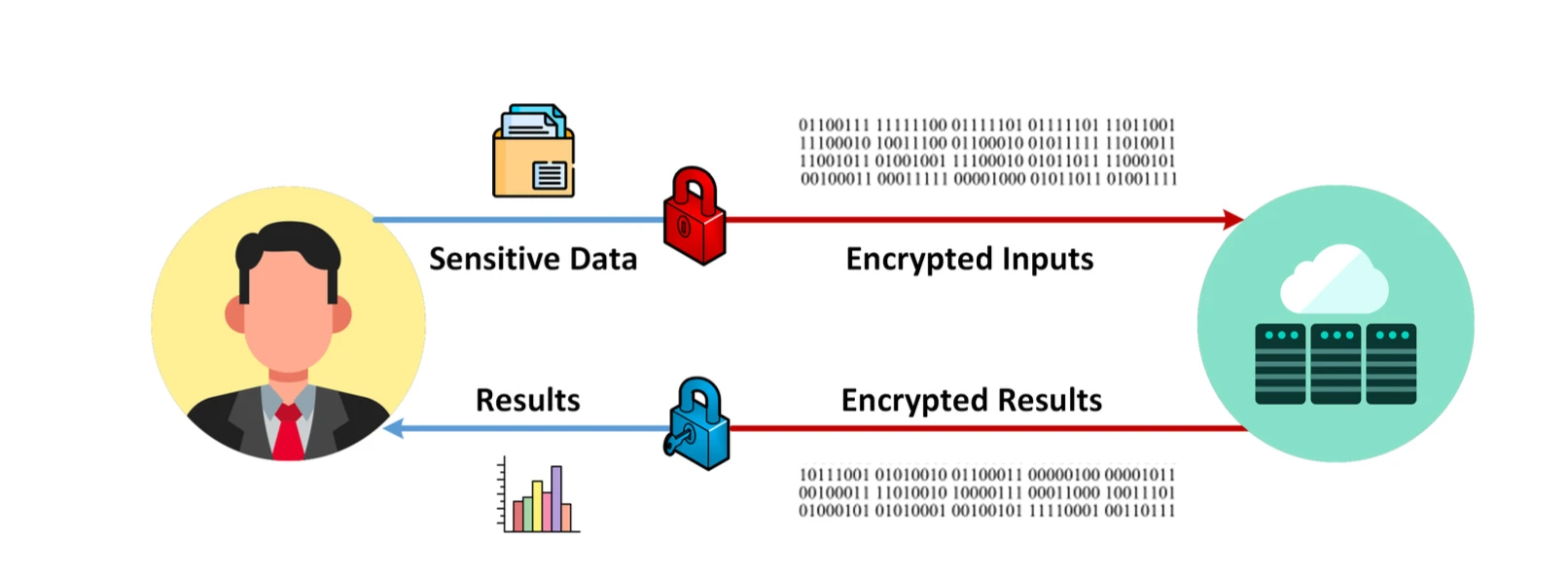
Quy trình FHE, nguồn hình ảnh: Bảo mật dữ liệu được thực hiện dễ dàng
FHE (Fully homomorphic Encryption) là công nghệ mã hóa tiên tiến hỗ trợ tính toán trực tiếp trên dữ liệu được mã hóa. Điều này có nghĩa là dữ liệu có thể được xử lý đồng thời bảo vệ quyền riêng tư. FHE có nhiều tình huống có thể áp dụng, đặc biệt là xử lý và phân tích dữ liệu trong điều kiện bảo vệ quyền riêng tư, chẳng hạn như tài chính, y tế, điện toán đám mây, học máy, hệ thống bỏ phiếu, Internet of Things, bảo vệ quyền riêng tư bằng blockchain và các lĩnh vực khác. Tuy nhiên, việc thương mại hóa vẫn cần một khoảng thời gian nhất định. Vấn đề chính là chi phí tính toán và bộ nhớ do thuật toán của nó gây ra là cực kỳ lớn và khả năng mở rộng của nó kém. Tiếp theo, chúng ta sẽ tìm hiểu ngắn gọn các nguyên tắc cơ bản của toàn bộ thuật toán và tập trung vào các vấn đề mà thuật toán mật mã này gặp phải.
Nguyên tắc cơ bản
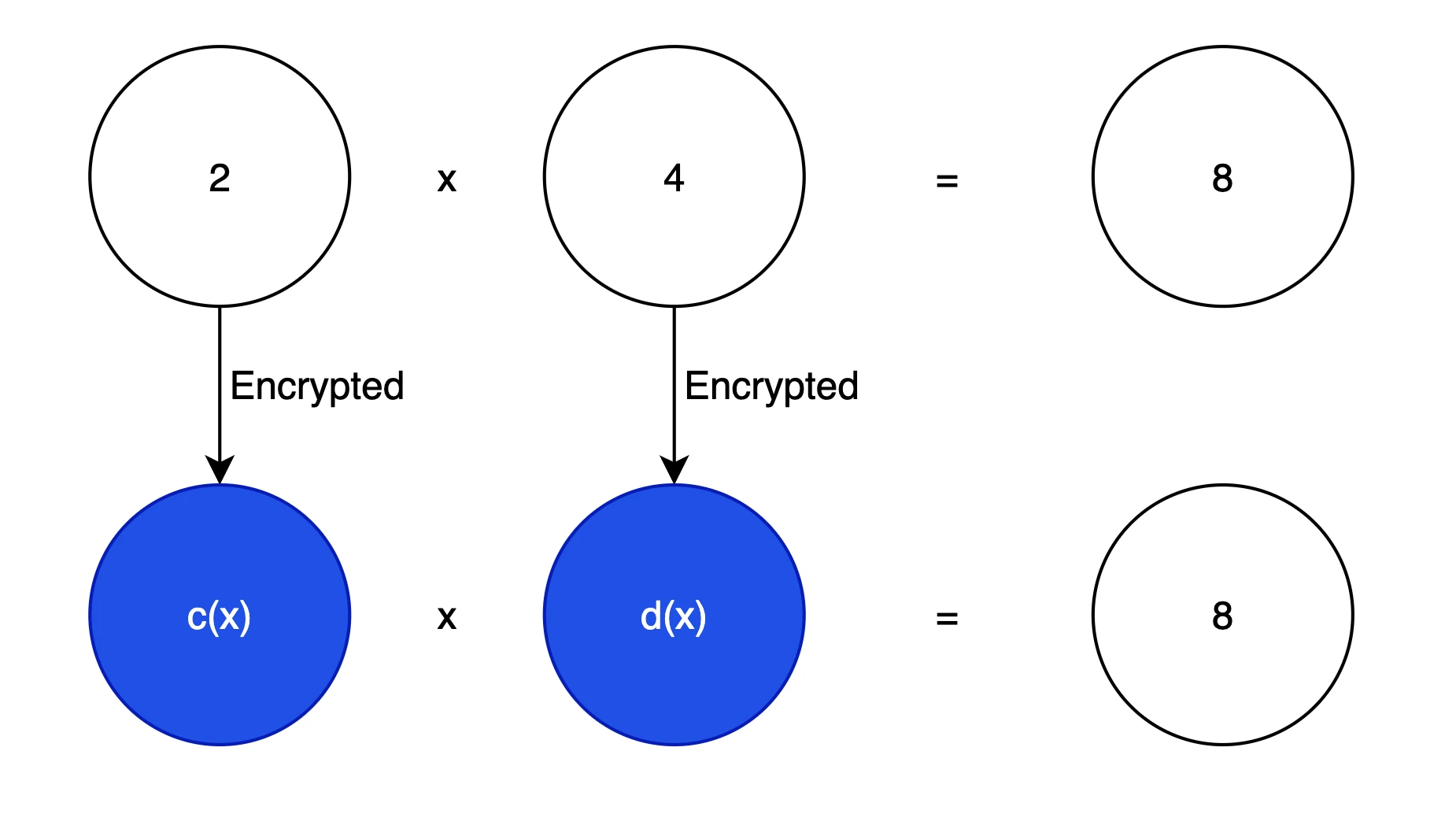
Biểu tượng mã hóa đồng hình
Đầu tiên, chúng ta cần thực hiện các phép tính trên dữ liệu được mã hóa mà vẫn nhận được kết quả tương tự mà chúng ta hình dung như trong hình trên. Đây là mục tiêu cơ bản của chúng tôi. Trong mật mã, đa thức thường được sử dụng để ẩn thông tin của văn bản gốc, bởi vì đa thức có thể được chuyển đổi thành các bài toán đại số tuyến tính và cũng có thể được chuyển đổi thành các bài toán tính toán vectơ, tạo điều kiện thuận lợi cho các máy tính hiện đại được tối ưu hóa cao cho vectơ để thực hiện các phép toán (chẳng hạn như như tính toán song song) ), ví dụ: 3 x 2 + 2 x + 1 có thể được biểu diễn dưới dạng vectơ [1, 2, 3].
Giả sử, chúng ta muốn mã hóa 2 , trong hệ thống HE đơn giản hóa, chúng ta có thể:
Chọn một đa thức khóa, chẳng hạn như s(x) = 3 x 2 + 2 x + 1
Tạo một đa thức ngẫu nhiên, chẳng hạn như a(x) = 2 x 2 + 5 x + 3
Tạo ra một đa thức sai nhỏ, giả sử e(x) = -1 x + 2
Mã hóa 2 -> c(x) = 2 + a(x)*s(x) + e(x)
Hãy nói về lý do tại sao chúng ta cần làm điều này. Bây giờ hãy giả sử rằng chúng ta đã thu được bản mã c(x). Nếu chúng ta muốn thu được bản rõ m, thì công thức là c(x) - e(x) - a(x) *s(x) = 2, ở đây đa thức ngẫu nhiên của chúng ta giả định rằng a(x) là công khai, thì chúng ta chỉ cần đảm bảo rằng khóa s(x) của chúng ta là bí mật nếu chúng ta biết s(x), cộng với c(x) như a Nếu lỗi rất nhỏ thì về mặt lý thuyết có thể bỏ qua và có thể thu được bản rõ m.
Đây là câu hỏi đầu tiên, có rất nhiều đa thức, làm thế nào để chọn một đa thức? Mức độ tốt nhất của đa thức là gì? Trong thực tế, bậc của đa thức được xác định bởi thuật toán được sử dụng để triển khai HE. Thông thường lũy thừa bằng 2, chẳng hạn như 1024/2048, v.v. Các hệ số của đa thức được chọn ngẫu nhiên từ trường hữu hạn q, chẳng hạn như mod 10000, sau đó được chọn ngẫu nhiên từ 0-9999. Có nhiều thuật toán để chọn ngẫu nhiên các hệ số như phân bố đều, phân bố Gaussian rời rạc, v.v. Các phương án khác nhau cũng có yêu cầu lựa chọn hệ số khác nhau, thường là nhằm đáp ứng nguyên tắc giải nhanh theo phương án.
Câu hỏi thứ hai, tiếng ồn là gì? Nhiễu được sử dụng để gây nhầm lẫn cho kẻ tấn công, vì giả sử rằng tất cả các số của chúng ta là s(x) và đa thức ngẫu nhiên nằm trong một miền, thì sẽ có một số quy tắc nhất định miễn là bản rõ m được nhập đủ số lần, tùy theo đầu ra. c(x), bạn có thể phán đoán thông tin của hai s(x) và c(x). Nếu nhiễu e(x) được đưa vào, đảm bảo rằng s(x) và c(x) không thể thu được thông qua phép liệt kê lặp lại đơn giản, vì có một lỗi nhỏ hoàn toàn ngẫu nhiên. Tham số này còn được gọi là Ngân sách tiếng ồn. Giả sử q = 2^32, nhiễu ban đầu có thể vào khoảng 2^3. Sau một số thao tác, độ ồn có thể tăng lên 2^20. Vẫn còn đủ dung lượng để giải mã tại thời điểm này, vì 2^20 << 2^32.
Sau khi đã thu được đa thức, bây giờ chúng ta cần chuyển đổi phép toán c(x) * d(x) thành một mạch. Điều này thường xuất hiện trong ZKP, chủ yếu là do khái niệm trừu tượng về mạch cung cấp một mô hình tính toán chung để biểu diễn bất kỳ Tính toán và mô hình mạch cho phép theo dõi và quản lý chính xác tiếng ồn do mỗi hoạt động tạo ra, đồng thời tạo điều kiện thuận lợi cho việc đưa vào phần cứng chuyên nghiệp sau đó như ASIC và FPGA để tính toán tăng tốc, chẳng hạn như mô hình SIMD. Bất kỳ hoạt động phức tạp nào cũng có thể được ánh xạ thành các phần tử mạch mô-đun đơn giản, chẳng hạn như phép cộng và phép nhân.

biểu diễn mạch số học
Phép cộng và phép nhân có thể biểu diễn phép trừ và phép chia, và do đó có thể biểu diễn bất kỳ phép tính nào. Các hệ số của đa thức được biểu diễn dưới dạng nhị phân và được gọi là đầu vào của mạch. Mỗi nút mạch đại diện cho một phép cộng hoặc phép nhân được thực hiện. Mỗi (*) đại diện cho một cổng nhân và mỗi (+) đại diện cho một cổng cộng. Đây là mạch thuật toán.
Điều này đặt ra một câu hỏi để không rò rỉ thông tin ngữ nghĩa, chúng tôi đưa vào e(x), được gọi là nhiễu. Trong phép tính của chúng ta, phép cộng sẽ biến hai đa thức e(x) thành đa thức cùng bậc. Trong phép nhân, phép nhân hai đa thức nhiễu sẽ tăng theo cấp số nhân bậc e(x) và kích thước của văn bản. Nếu nhiễu quá lớn thì không thể bỏ qua nhiễu trong quá trình tính toán kết quả và văn bản gốc m. không thể khôi phục được. Đây là lý do chính hạn chế khả năng của thuật toán HE trong việc thể hiện các phép tính tùy ý, vì nhiễu tăng theo cấp số nhân, nhanh chóng đạt đến ngưỡng không thể sử dụng được. Trong một mạch, đây được gọi là độ sâu của mạch và số phép nhân là giá trị độ sâu của mạch.
Nguyên lý cơ bản của mã hóa đồng cấu HE được thể hiện trên hình trên. Để giải quyết vấn đề nhiễu làm hạn chế mã hóa đồng cấu, một số giải pháp đã được đề xuất:
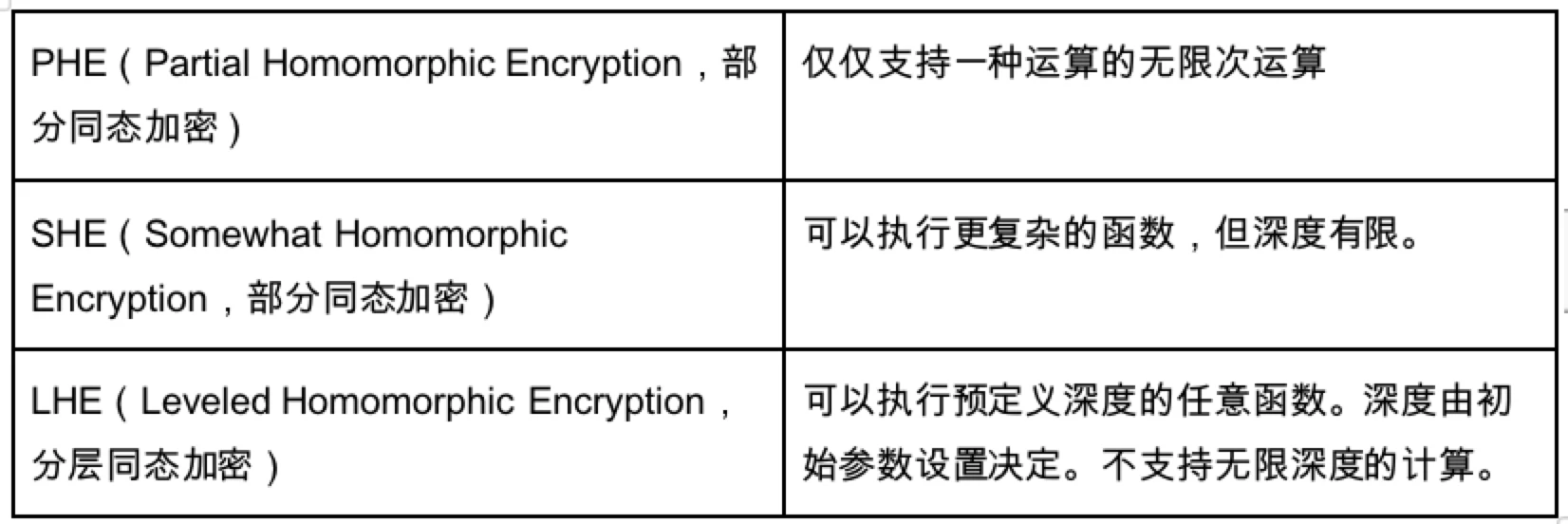
LHE là một thuật toán rất phù hợp ở đây, bởi vì theo thuật toán này, miễn là độ sâu được xác định, bất kỳ hàm nào cũng có thể được thực thi trong độ sâu, nhưng PHE và SHE không thể đạt được tính hoàn chỉnh của Turing. Do đó, trên cơ sở đó, các nhà mật mã học đã tiến hành nghiên cứu và đề xuất ba công nghệ để xây dựng mã hóa đồng cấu hoàn toàn FHE, với hy vọng hiện thực hóa tầm nhìn thực thi các chức năng tùy ý ở độ sâu vô hạn.
Chuyển khóa: Sau khi chúng ta nhân, kích thước của văn bản mã hóa sẽ tăng theo cấp số nhân, điều này sẽ đặt ra yêu cầu lớn về bộ nhớ và tài nguyên máy tính cho các hoạt động tiếp theo. Do đó, việc thực hiện Chuyển khóa sau mỗi lần nhân có thể nén văn bản mã hóa nhưng sẽ gây ra một chút nhiễu. .
Chuyển đổi mô-đun: Cho dù đó là phép nhân hay chuyển đổi khóa, độ nhiễu sẽ tăng theo cấp số nhân. Mô-đun q là Mod 10000 mà chúng ta đã nói trước đó. Các tham số chỉ có thể được lấy trong [0, 9999]. Sau nhiều lần tính toán, nhiễu cuối cùng vẫn nằm trong q và có thể được giải mã. Do đó, sau nhiều thao tác, để ngăn chỉ số tiếng ồn tăng vượt quá ngưỡng, Chuyển đổi mô-đun cần được sử dụng để giảm ngân sách tiếng ồn, để có thể ngăn chặn tiếng ồn. Ở đây chúng ta có thể hiểu một nguyên tắc cơ bản. Nếu các phép tính của chúng ta phức tạp và độ sâu mạch lớn thì cần có lượng nhiễu q mô đun lớn hơn để đáp ứng tính khả dụng sau nhiều lần tăng theo cấp số nhân.
Bootstrap: Nhưng nếu bạn muốn đạt được các phép tính có độ sâu vô hạn, Mô-đun chỉ có thể hạn chế sự gia tăng nhiễu, nhưng mỗi công tắc sẽ làm cho phạm vi q nhỏ hơn. Chúng tôi biết rằng một khi nó giảm đi, điều đó có nghĩa là độ phức tạp của phép tính cần phải giảm đi. giảm đi. Bootstrap là một công nghệ làm mới giúp thiết lập lại tiếng ồn về mức ban đầu thay vì giảm tiếng ồn. Bootstrap không cần giảm mô-đun nên có thể duy trì khả năng tính toán của hệ thống. Nhưng nhược điểm của nó là đòi hỏi nhiều tài nguyên máy tính.
Nói chung, đối với các phép tính theo các bước giới hạn, việc sử dụng Chuyển đổi mô-đun có thể giảm nhiễu, nhưng nó cũng sẽ làm giảm mô-đun, tức là quỹ nhiễu, dẫn đến khả năng tính toán bị nén. Vì vậy, đây chỉ là tính toán trong các bước giới hạn. Bootstrap có thể thực hiện noise reset nên dựa trên thuật toán LHE, nó có thể đạt được FHE thực sự, tức là tính toán vô hạn bất kỳ hàm nào, và đây cũng là ý nghĩa của Complete của FHE.
Tuy nhiên, nhược điểm cũng rõ ràng là nó đòi hỏi một lượng lớn tài nguyên máy tính. Do đó, trong trường hợp bình thường, hai công nghệ giảm tiếng ồn này được sử dụng kết hợp để quản lý tiếng ồn hàng ngày và độ trễ cần có thời gian khởi động. Bootstrap đắt tiền hơn về mặt tính toán được sử dụng khi chuyển đổi mô đun không thể kiểm soát nhiễu hiệu quả hơn nữa.
Giải pháp FHE hiện tại có các cách triển khai cụ thể sau, tất cả đều sử dụng công nghệ lõi Bootstrap:
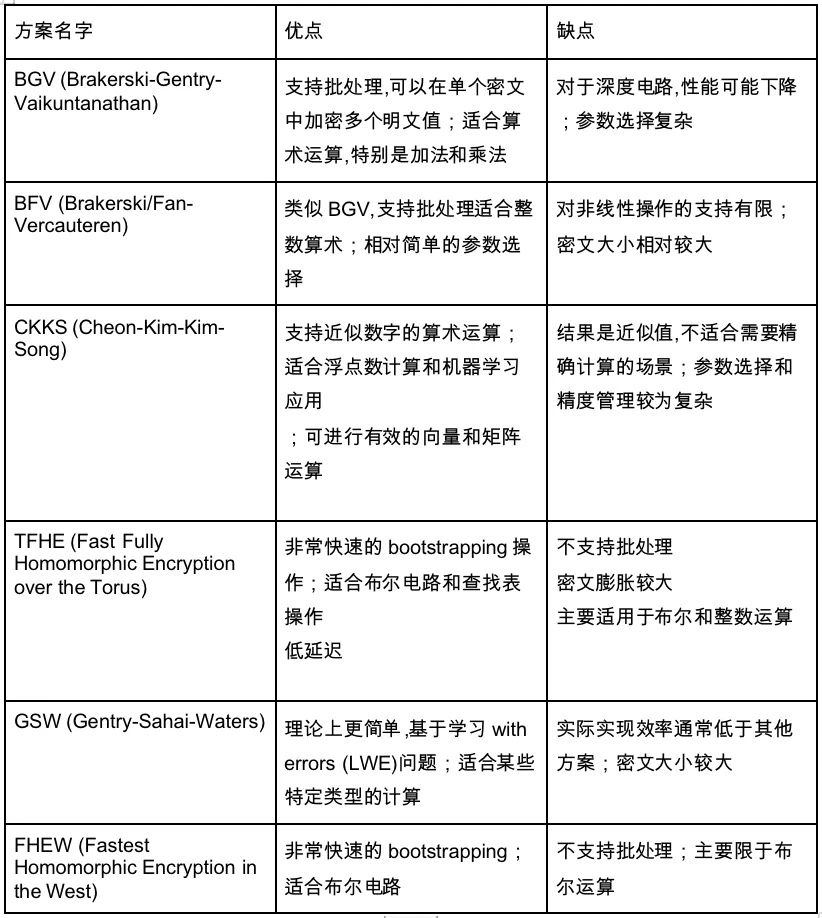
Điều này cũng dẫn đến các loại mạch mà chúng tôi chưa nói đến. Những loại mạch chính mà chúng tôi đã giới thiệu ở trên là các mạch số học. Nhưng có một loại mạch khác - mạch Boolean. Mạch số học tương đối trừu tượng như 1+1. Các nút cũng là phép cộng hoặc phép chia, trong khi tất cả các số trong mạch Boolean được chuyển đổi thành cơ số 01 và tất cả các nút đều là các phép toán bool, bao gồm các phép toán NOT, OR và AND, tương tự như việc thực hiện mạch máy tính của chúng tôi. Mạch số học là một mạch trừu tượng.
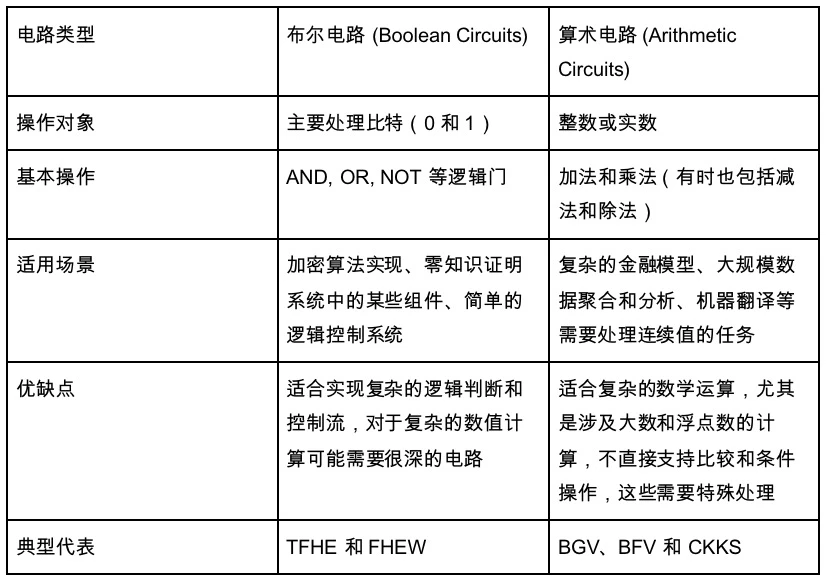
Do đó, chúng ta có thể nghĩ một cách đại khái về các phép toán Boolean là quá trình xử lý linh hoạt, sử dụng ít dữ liệu hơn, trong khi các phép toán số học là giải pháp cho các ứng dụng sử dụng nhiều dữ liệu.
Những vấn đề FHE phải đối mặt
Vì các phép tính của chúng tôi cần được mã hóa và sau đó được chuyển đổi thành mạch, và vì phép tính đơn giản chỉ tính toán 2+4, nhưng sau khi mã hóa, một số lượng lớn quy trình tính toán gián tiếp bằng mật mã được giới thiệu, cũng như một số công nghệ tiên tiến như as Bootstrap để giải quyết vấn đề nhiễu, do đó dẫn đến chi phí tính toán cao hơn N bậc so với các phép tính thông thường.
Chúng tôi sử dụng một ví dụ thực tế để giúp người đọc cảm nhận được chi phí hoạt động của các quy trình mã hóa bổ sung này đối với tài nguyên máy tính. Giả sử rằng quá trình tính toán thông thường mất 200 chu kỳ xung nhịp trên bộ xử lý 3 GHz thì quá trình giải mã AES-128 thông thường mất khoảng 67 nano giây (200/3 GHz). Phiên bản FHE mất 35 giây, dài hơn khoảng 522.388.060 lần so với phiên bản thông thường (35/67 e-9). Nghĩa là, sử dụng cùng một tài nguyên máy tính, cùng một thuật toán thông thường và thuật toán theo tính toán FHE, yêu cầu về tài nguyên máy tính là khoảng 500 triệu lần.

Chương trình dprive của DARPA, nguồn: DARPA
Vì mục đích bảo mật dữ liệu, DARPA tại Hoa Kỳ đã đặc biệt xây dựng chương trình Dprive vào năm 2021, mời nhiều nhóm nghiên cứu bao gồm Microsoft, Intel, v.v. Mục tiêu của họ là tạo ra bộ tăng tốc FHE và ngăn xếp phần mềm hỗ trợ để tăng tốc độ tính toán FHE phù hợp hơn với các thao tác tương tự trên dữ liệu không được mã hóa đạt được mục tiêu tốc độ tính toán FHE xấp xỉ 1/10 so với tính toán thông thường. Tom Rondeau, giám đốc chương trình DARPA, cho biết: Người ta ước tính rằng trong thế giới FHE, các phép tính của chúng tôi chậm hơn khoảng một triệu lần so với thế giới văn bản thuần túy.
Dprive chủ yếu tập trung vào các khía cạnh sau:
Tăng độ dài từ của bộ xử lý: Các hệ thống máy tính hiện đại sử dụng độ dài từ 64 bit, nghĩa là một số có thể lên tới 64 bit, nhưng trên thực tế q thường là 1024 bit. Nếu muốn đạt được điều này, chúng ta phải chia q của mình. , điều này sẽ ảnh hưởng đến tài nguyên bộ nhớ và giảm tốc độ. Do đó, để đạt được q lớn hơn, người ta cần xây dựng bộ xử lý có kích thước từ 1024 bit trở lên. Trường hữu hạn q rất quan trọng. Như chúng tôi đã đề cập trước đó, trường này càng lớn thì càng có thể tính được nhiều bước hơn, do đó mức tiêu thụ tài nguyên máy tính tổng thể sẽ giảm. q đóng vai trò trung tâm trong FHE, ảnh hưởng đến hầu hết mọi khía cạnh của sơ đồ, bao gồm bảo mật, hiệu suất, số lượng tính toán có thể được thực hiện và tài nguyên bộ nhớ cần thiết.
Xây dựng bộ xử lý ASIC: Như chúng tôi đã đề cập trước đó, để dễ dàng song song hóa và các lý do khác, chúng tôi đã xây dựng các đa thức và xây dựng các mạch thông qua đa thức. Điều này tương tự như ZK. Các CPU và GPU hiện tại không có khả năng này (tài nguyên máy tính và tài nguyên bộ nhớ) để chạy các mạch và cần phải xây dựng bộ xử lý ASIC chuyên dụng để cho phép thuật toán FHE.
Xây dựng kiến trúc song song MIMD. Không giống như kiến trúc song song SIMD, SIMD chỉ có thể thực hiện một lệnh duy nhất trên nhiều dữ liệu, tức là phân tách dữ liệu và xử lý song song, nhưng MIMD có thể phân chia dữ liệu và sử dụng các hướng dẫn khác nhau để tính toán. SIMD chủ yếu được sử dụng cho song song dữ liệu, đây cũng là kiến trúc chính để xử lý song song các giao dịch trong hầu hết các dự án blockchain. MIMD có thể xử lý nhiều loại nhiệm vụ song song khác nhau. MIMD phức tạp hơn về mặt kỹ thuật và đòi hỏi phải tập trung vào các vấn đề đồng bộ hóa và giao tiếp.
Chỉ còn một tháng nữa là chương trình DEPRIVE của DARPA hết hạn. Kế hoạch ban đầu của Dprvie là bắt đầu vào năm 2021 và kết thúc kế hoạch ba giai đoạn vào tháng 9 năm 2024. Tuy nhiên, có vẻ như tiến độ của nó còn chậm và vẫn chưa đạt được kỳ vọng. Chỉ tiêu hiệu quả đạt 1/10 so với tính toán thông thường.
Mặc dù tiến độ đột phá công nghệ FHE còn chậm, tương tự như công nghệ ZK, nhưng nó phải đối mặt với một vấn đề nghiêm trọng là việc triển khai phần cứng là điều kiện tiên quyết để triển khai công nghệ. Tuy nhiên, chúng tôi vẫn tin rằng về lâu dài, công nghệ FHE vẫn có ý nghĩa đặc biệt, đặc biệt trong việc bảo vệ quyền riêng tư của một số dữ liệu an toàn được liệt kê ở phần đầu. Đối với DARPA, Bộ Quốc phòng có một lượng lớn dữ liệu nhạy cảm. Nếu muốn cung cấp khả năng chung của AI cho quân đội, họ cần đào tạo AI dưới hình thức bảo mật dữ liệu. Không chỉ vậy, nó còn có thể áp dụng cho các dữ liệu nhạy cảm quan trọng như y tế và tài chính. Trên thực tế, FHE không phù hợp với tất cả các phép tính thông thường mà thiên về nhu cầu tính toán đối với dữ liệu nhạy cảm. Loại bảo mật này đặc biệt quan trọng. thời kỳ hậu lượng tử.
Đối với công nghệ tiên tiến này, phải tính đến sự khác biệt về thời gian giữa chu kỳ đầu tư và thương mại hóa. Vì vậy, chúng ta cần hết sức thận trọng về thời gian thực hiện FHE.
Sự kết hợp của chuỗi khối
Trong blockchain, FHE cũng chủ yếu được sử dụng để bảo vệ quyền riêng tư của dữ liệu, các lĩnh vực ứng dụng của nó bao gồm quyền riêng tư trên chuỗi, quyền riêng tư của dữ liệu đào tạo AI, quyền riêng tư bỏ phiếu trên chuỗi, đánh giá giao dịch quyền riêng tư trên chuỗi, v.v. Trong số đó, FHE còn được biết đến là một trong những giải pháp tiềm năng cho giải pháp MEV on-chain. Theo bài viết MEV của chúng tôi Chiếu sáng khu rừng tối - Khám phá bí ẩn của MEV , nhiều giải pháp MEV hiện tại chỉ là cách để xây dựng lại kiến trúc MEV chứ không phải là giải pháp trên thực tế, các cuộc tấn công sandwich gây ra vấn đề UX vẫn chưa được giải quyết. Giải pháp ban đầu chúng tôi nghĩ đến là mã hóa trực tiếp các giao dịch trong khi vẫn giữ trạng thái công khai.
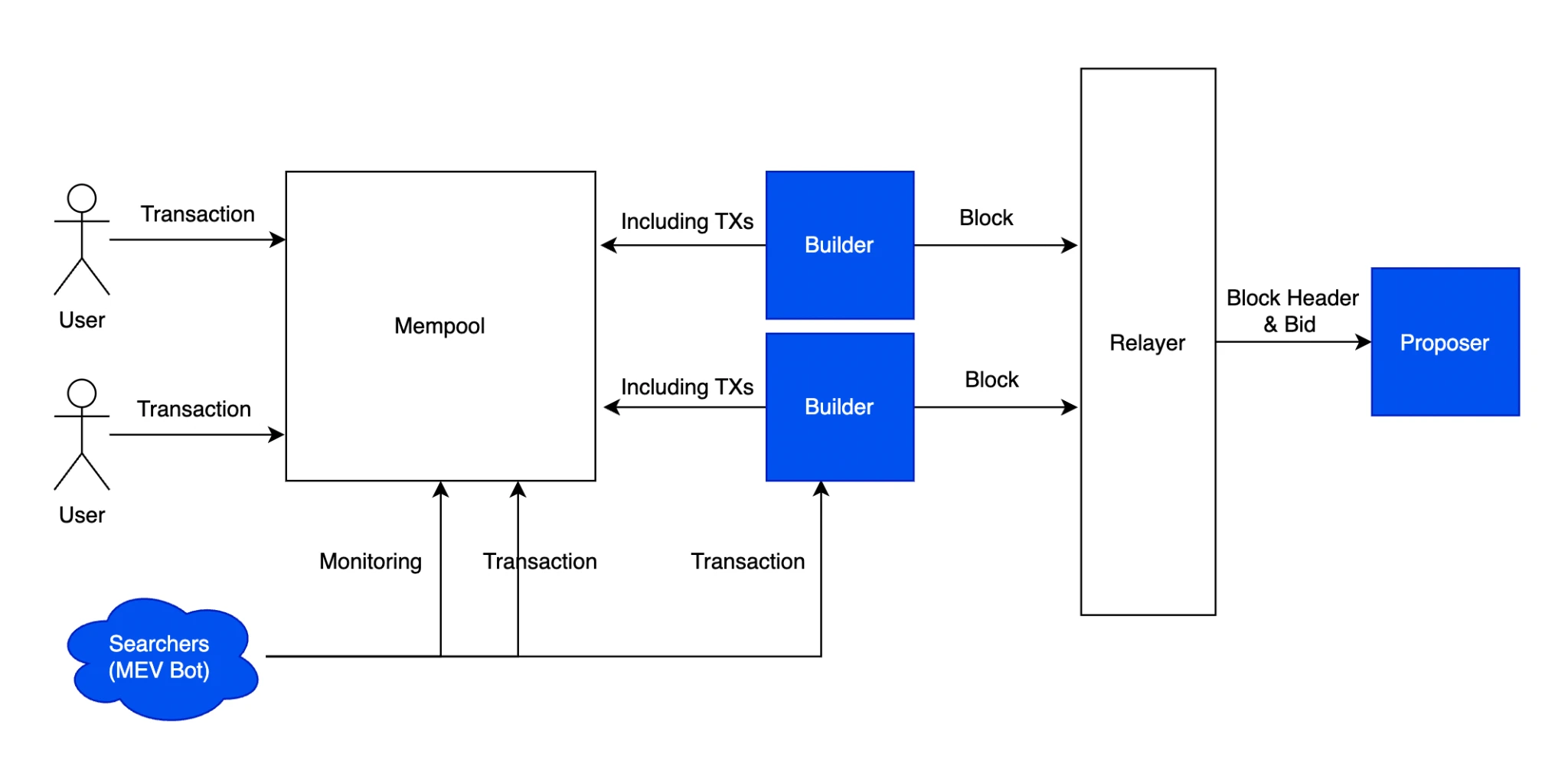
Quy trình MEV PBS
Nhưng cũng có một vấn đề là nếu chúng ta mã hóa hoàn toàn giao dịch, các tác động ngoại vi tích cực do bot MEV mang lại sẽ đồng thời biến mất. Trình xác minh cần chạy trên cơ sở máy ảo để thực hiện FHE và trình xác minh cũng cần. để xác minh giao dịch, việc xác định tính chính xác của trạng thái cuối cùng sẽ làm tăng đáng kể các yêu cầu đối với các nút đang chạy, làm chậm thông lượng của toàn bộ mạng theo hệ số một triệu.
Dự án chính
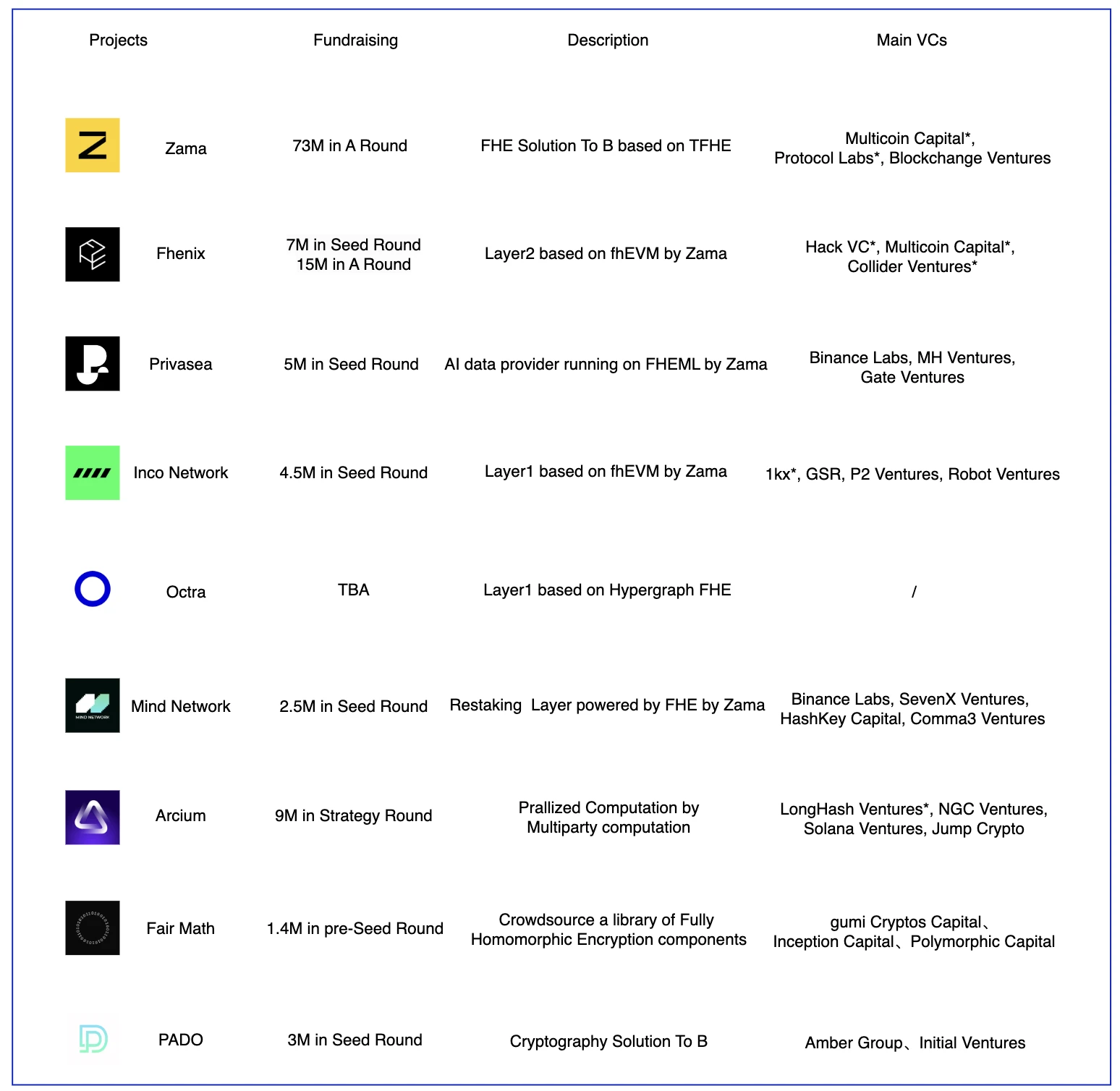
Cảnh Quan FHE
FHE là một công nghệ tương đối mới. Hầu hết các công nghệ FHE hiện đang được các dự án sử dụng đều do Zama xây dựng, như Fhenix, Privasea, Inco Network và Mind Network. Khả năng triển khai kỹ thuật FHE của Zama đã được công nhận trong các dự án này. Hầu hết các dự án trên đều được xây dựng dựa trên các thư viện do Zama cung cấp. Sự khác biệt chính nằm ở mô hình kinh doanh. Fhenix hy vọng sẽ xây dựng Lớp 2 lạc quan ưu tiên quyền riêng tư và Privasea hy vọng sẽ sử dụng khả năng của FHE để thực hiện các hoạt động dữ liệu LLM. Tuy nhiên, đây là một hoạt động rất nặng về dữ liệu, đòi hỏi yêu cầu phần cứng và kỹ thuật rất cao đối với FHE. dựa trên TFHE có thể không phải là lựa chọn tối ưu. Cả Inco Network và Fhenix đều sử dụng fhEVM, nhưng một cái được xây dựng trên Lớp 1 và cái còn lại ở Lớp 2. Arcium được xây dựng trên sự kết hợp của nhiều công nghệ mã hóa, bao gồm FHE, MPC và ZK. Mô hình kinh doanh của Mind Network khá khác biệt, việc chọn đường đua Reset để giải quyết các vấn đề về an ninh kinh tế và niềm tin biểu quyết ở lớp đồng thuận bằng cách cung cấp bảo mật thanh khoản và kiến trúc mạng con dựa trên FHE.
Zama
Zama là một giải pháp dựa trên TFHE, được đặc trưng bởi việc sử dụng công nghệ Bootstrap, tập trung vào xử lý các phép toán Boolean và các phép toán số nguyên có độ dài từ thấp. Mặc dù đây là cách triển khai kỹ thuật nhanh hơn trong giải pháp FHE của chúng tôi nhưng nó vẫn được so sánh với Vẫn còn đó. một khoảng cách rất lớn so với tính toán thông thường. Thứ hai, không thể thực hiện các phép tính tùy ý. Khi đối mặt với các tác vụ sử dụng nhiều dữ liệu, các thao tác này sẽ khiến độ sâu mạch quá lớn để có thể xử lý được. Đây không phải là giải pháp sử dụng nhiều dữ liệu và chỉ áp dụng cho một số bước quan trọng nhất định của quy trình mã hóa.
TFHE hiện có sẵn mã triển khai, công việc chính của Zama là viết lại TFHE bằng ngôn ngữ Rust, vốn là các thùng rs-TFHE của nó. Đồng thời, để hạ thấp ngưỡng cho phép người dùng sử dụng Rust, hãng cũng xây dựng công cụ biên dịch Concrate, có thể chuyển đổi Python thành rs-TFHE tương đương. Sử dụng công cụ này, bạn có thể dịch ngôn ngữ mô hình lớn dựa trên Python sang ngôn ngữ Rust dựa trên TFHE-rs. Bằng cách này, các mô hình lớn dựa trên mã hóa đồng cấu có thể chạy được, nhưng các tác vụ sử dụng nhiều dữ liệu tại thời điểm này thực sự không phù hợp với các kịch bản TFHE. Sản phẩm fhEVM của Zama là công nghệ sử dụng mã hóa đồng hình hoàn toàn (FHE) để triển khai các hợp đồng thông minh bí mật trên EVM và có thể hỗ trợ các hợp đồng thông minh được mã hóa hai đầu được biên dịch dựa trên ngôn ngữ Solidity.
Nhìn chung, với tư cách là một sản phẩm To B, Zama đã xây dựng một nền tảng phát triển blockchain + AI tương đối hoàn chỉnh dựa trên TFHE. Nó có thể giúp các dự án web3 dễ dàng xây dựng cơ sở hạ tầng và ứng dụng FHE.
quãng tám
Điều đặc biệt ở Octra là nó sử dụng một công nghệ khác để triển khai FHE. Nó sử dụng một công nghệ gọi là siêu đồ thị để triển khai bootstrap. Nó cũng dựa trên các mạch Boolean, nhưng Octra tin rằng công nghệ dựa trên siêu đồ thị có thể đạt được FHE hiệu quả hơn. Đây là công nghệ ban đầu của Octra để triển khai FHE và nhóm có khả năng kỹ thuật và mật mã rất mạnh.
Octra đã xây dựng ngôn ngữ hợp đồng thông minh mới được phát triển bằng các thư viện mã như OCaml, AST, ReasonML (ngôn ngữ được thiết kế đặc biệt cho các hợp đồng thông minh và ứng dụng tương tác với mạng chuỗi khối Octra) và C++. Thư viện Hyperghraph FHE mà nó xây dựng tương thích với mọi dự án.
Kiến trúc của nó cũng tương tự như các dự án như Mind Network, Bittensor và Allora. Nó xây dựng một mạng chính, sau đó các dự án khác trở thành mạng con để xây dựng một môi trường hoạt động tách biệt lẫn nhau. Đồng thời, tương tự như các dự án này, họ đã xây dựng các giao thức đồng thuận mới nổi phù hợp hơn với chính kiến trúc. Octra đã xây dựng một giao thức đồng thuận ML-consensus dựa trên machine learning, về cơ bản dựa trên DAG (Directed Acycle Graph). .
Các nguyên tắc kỹ thuật của sự đồng thuận này vẫn chưa được tiết lộ, nhưng chúng ta có thể suy đoán đại khái. Có thể giao dịch được gửi tới mạng và sau đó thuật toán SVM (Máy vectơ hỗ trợ) được sử dụng để xác định nút xử lý tốt nhất, chủ yếu dựa trên tải mạng hiện tại của mỗi nút. Hệ thống sẽ xác định đường dẫn đồng thuận nút cha tốt nhất dựa trên dữ liệu lịch sử (học thuật toán ML). Chỉ cần 1/2 số nút được thỏa mãn thì có thể đạt được sự đồng thuận về cơ sở dữ liệu đang phát triển.
trông chờ
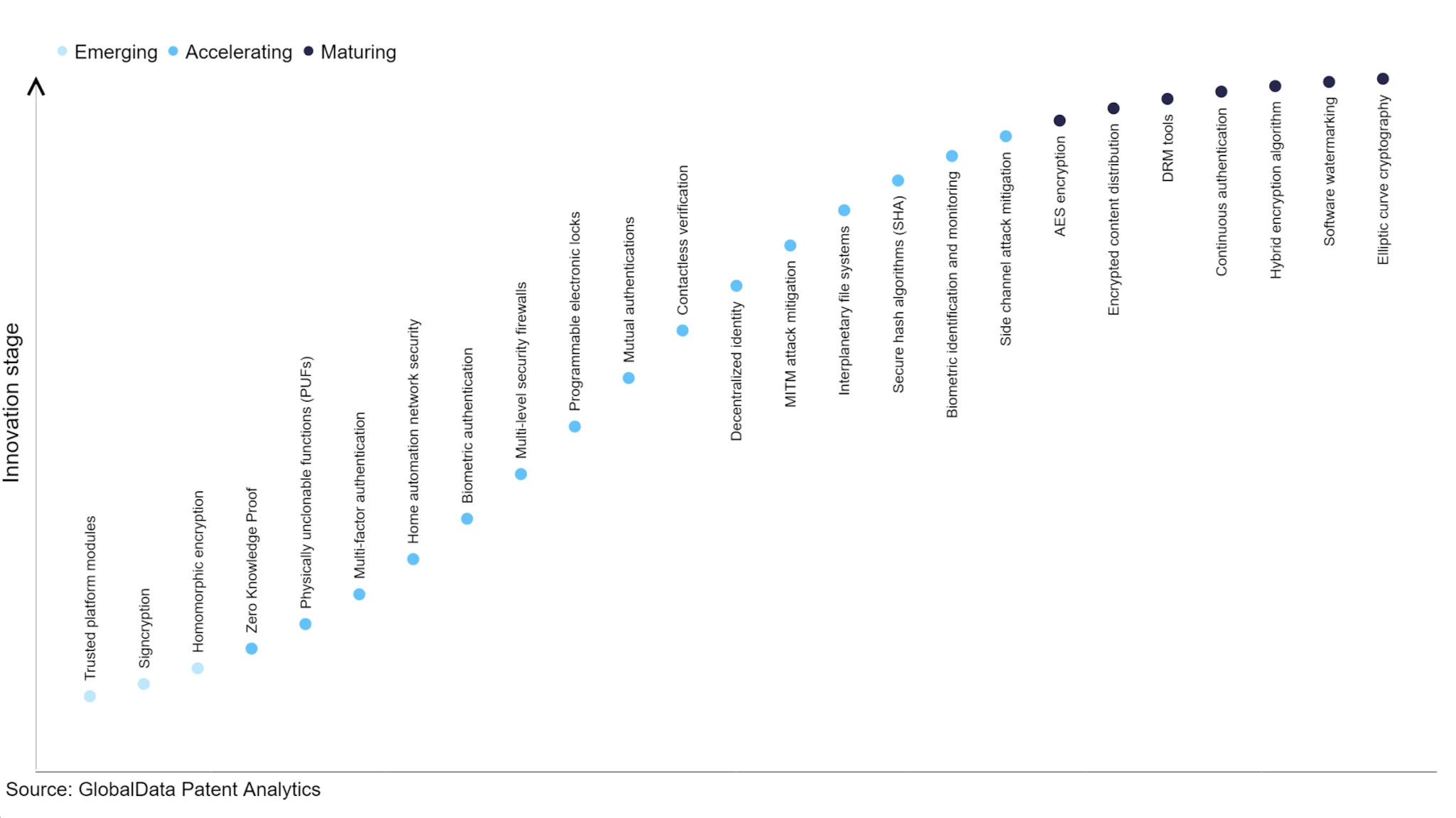
Tình trạng phát triển của công nghệ mật mã tiên tiến, nguồn: Verdict
Công nghệ FHE là công nghệ hướng tới tương lai. Tình trạng phát triển của nó vẫn kém hơn công nghệ ZK và thiếu vốn đầu tư. Do hiệu quả thấp và chi phí cao do bảo vệ quyền riêng tư nên hầu hết các tổ chức thương mại không có đủ động lực. Sự phát triển của công nghệ ZK đã trở nên nhanh hơn nhờ sự đầu tư của Crypto VC. FHE vẫn đang ở giai đoạn đầu và ngay cả bây giờ, vẫn còn ít dự án trên thị trường do chi phí cao, độ khó kỹ thuật cao và triển vọng thương mại hóa không rõ ràng. Vào năm 2021, DAPRA đã hợp tác với nhiều công ty như Intel và Microsoft để triển khai kế hoạch tấn công FHE kéo dài 42 tháng. Mặc dù đã đạt được một số tiến bộ nhưng vẫn còn lâu mới đạt được mục tiêu hiệu suất đạt được. Khi Crypto VC chú ý đến hướng đi này, nhiều quỹ sẽ đổ vào ngành này hơn, dự kiến sẽ có nhiều dự án FHE xuất hiện hơn trong ngành và cũng sẽ có nhiều dự án có năng lực nghiên cứu và kỹ thuật mạnh mẽ như Zama và Octra A. đội ngũ có năng lực đứng ở trung tâm của sân khấu. Sự kết hợp giữa công nghệ FHE với tình trạng thương mại hóa và phát triển của blockchain vẫn đáng để khám phá. Hiện tại, ứng dụng tốt nhất là ẩn danh biểu quyết nút xác minh, nhưng phạm vi ứng dụng vẫn còn hẹp.
Giống như ZK, việc triển khai chip FHE là một trong những điều kiện tiên quyết để thương mại hóa FHE. Hiện tại, nhiều nhà sản xuất như Intel, Chain Reaction, Optalysys, v.v. đang khám phá khía cạnh này. Mặc dù FHE phải đối mặt với nhiều trở ngại về mặt kỹ thuật, nhưng việc triển khai chip FHE, mã hóa đồng hình hoàn toàn, như một công nghệ có nhiều hứa hẹn và nhu cầu chính xác, sẽ mang lại những thay đổi sâu sắc cho các ngành như quốc phòng, tài chính và chăm sóc y tế, giải phóng tiềm năng của việc kết hợp những dữ liệu riêng tư này với các công nghệ như thuật toán lượng tử trong tương lai cũng sẽ mở ra thời điểm bùng nổ của nó.
Chúng tôi sẵn sàng khám phá công nghệ tiên tiến đầu tiên này nếu bạn đang xây dựng một sản phẩm FHE có thể thương mại hóa hoặc có sự đổi mới công nghệ tiên tiến hơn, vui lòng liên hệ với chúng tôi!





