





引言
AI 產業近期的發展,被一部分人視為第四次工業革命,大模型的出現顯著提升了各行各業的效率, 波士頓顧問認為 GPT 為美國提升了約 20% 的工作效率。同時大模型帶來的泛化能力被喻為新的軟體設計範式,過去軟體設計是精確的程式碼,現在的軟體設計是更泛化的大模型框架嵌入到軟體中,這些軟體能具備更好的表現和支援更廣泛模態輸入與輸出。深度學習技術確實為 AI 產業帶來了第四次繁榮,而這一股風潮也瀰漫到了 Crypto 產業。
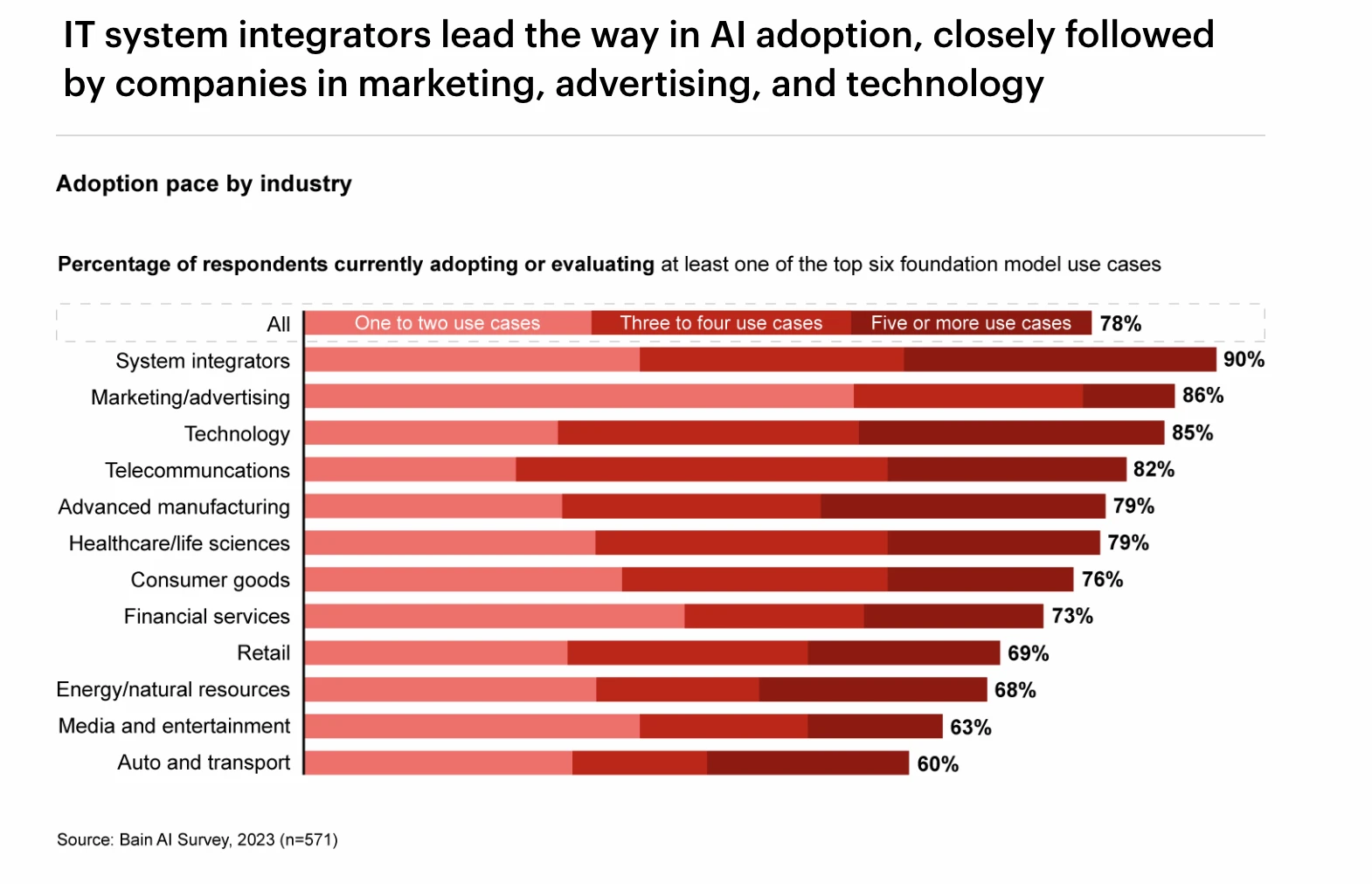
各行業 GPT 的採用率排名,Source: Bain AI Survey
在本報告中,我們將詳細探討 AI 產業的發展歷史、技術分類、以及深度學習技術的發明對產業的影響。然後深度剖析深度學習中 GPU、雲端運算、資料來源、邊緣設備等產業鏈上下游,以及其發展現況與趨勢。之後我們從本質上詳細探討了 Crypto 與 AI 產業的關係,對於 Crypto 相關的 AI 產業鏈的格局進行了整理。
AI 產業的發展歷史
AI 產業從 20 世紀 50 年代起步,為了實現人工智慧的願景,學術界和工業界在不同時代不同學科背景的情況下,發展了許多實現人工智慧的流派。
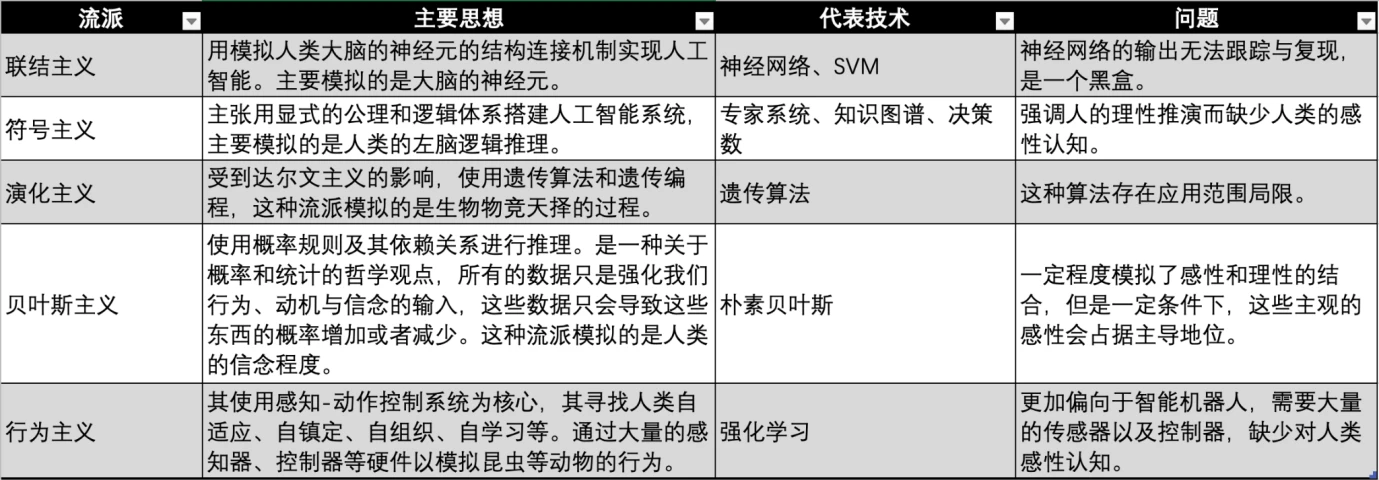
實現 AI 流派對比,圖源:Gate Ventures
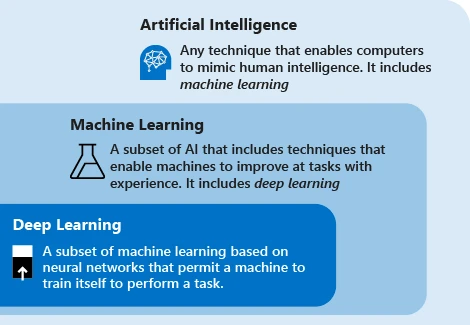
AI/ML/DL 關係,圖片來源: Microsoft
現代人工智慧技術使用的主要是「機器學習」這個術語,該技術的理念是讓機器依靠資料在任務中反覆迭代以改善系統的性能。主要的步驟是將資料送到演算法中,使用此資料訓練模型,測試部署模型,使用模型以完成自動化的預測任務。
目前機器學習有三大主要的學派,分別是聯結主義、符號主義和行為主義,分別模仿人類的神經系統、思考、行為。
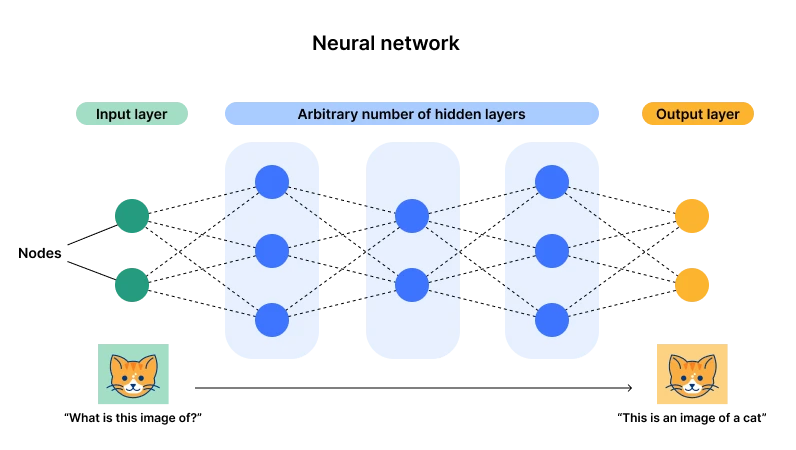
神經網路架構圖示,圖源: Cloudflare
而目前以神經網路為代表的聯結主義佔上風(也被稱為深度學習),主要原因是這種架構有一個輸入層一個輸出層,但是有多個隱藏層,一旦層數以及神經元(參數)的數量變得足夠多,那麼就有足夠的機會擬合複雜的通用型任務。透過數據輸入,可以一直調整神經元的參數,那麼最後經歷過多次數據,該神經元就會達到一個最佳的狀態(參數),這也就是我們說的大力出奇蹟,而這也是其“深度」兩字的由來-足夠的層數和神經元。
舉個例子,可以簡單理解就是構造了一個函數,我們輸入X= 2 時,Y= 3 ;X= 3 時,Y= 5 ,如果想要這個函數來應付所有的X,那麼就需要一直添加這個函數的度數及其參數,例如我此時可以建構滿足這個條件的函數為Y = 2 X -1 ,但是如果有一個資料為X= 2, Y= 11 時,就需要重構一個適合這三個數據點的函數,使用GPU 進行暴力破解發現Y = X 2 -3 X + 5 ,比較合適,但是不需要完全和數據重合,只需要遵守平衡,大致相似的輸出即可。這裡面 X 2 以及 X、X 0 都是代表不同的神經元,而 1、-3、 5 就是其參數。
此時如果我們輸入大量的資料到神經網路時,我們可以增加神經元、迭代參數來擬合新的資料。這樣就能擬合所有的數據。
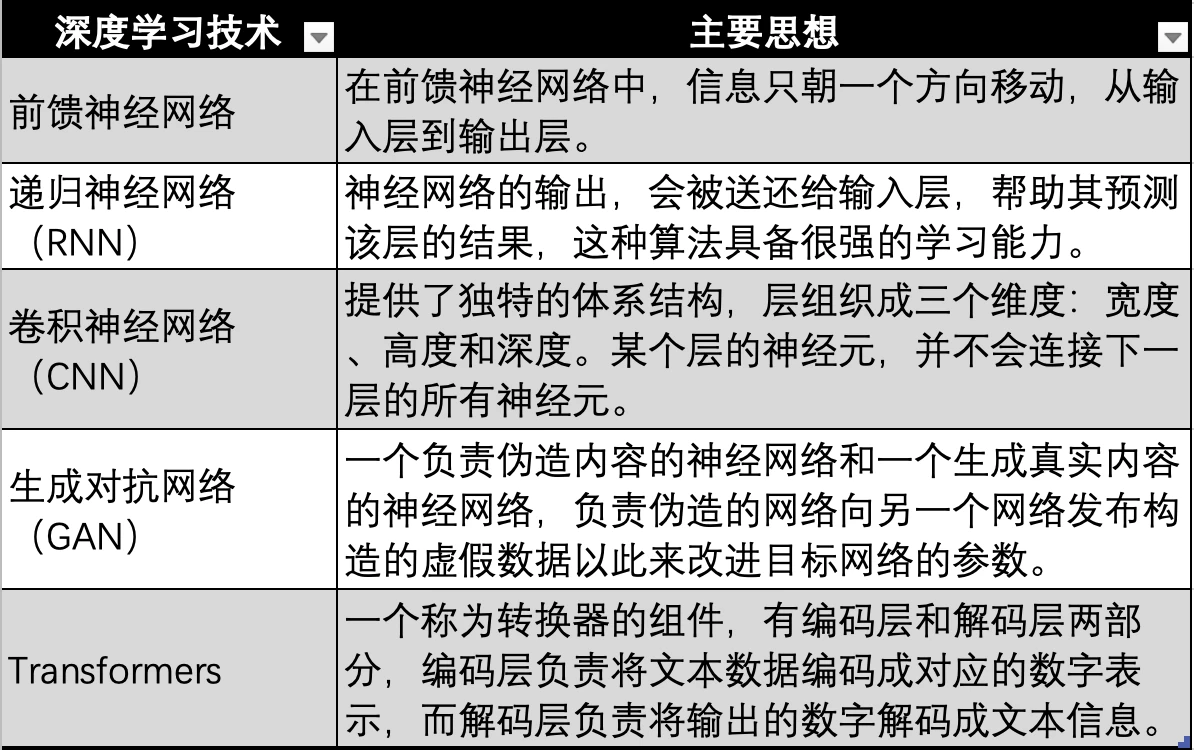
深度學習技術演進,圖源:Gate Ventures
而基於神經網路的深度學習技術,也有多個技術迭代與演進,分別如上圖的最早期的神經網絡,前饋神經網路、RNN、CNN、GAN 最後演進到現代大模型如GPT 等所使用的Transformer 技術,Transformer 技術只是神經網路的一個演進方向,多加了一個轉換器(Transformer),用於把所有模態(如音頻,視頻,圖片等)的數據編碼成對應的數值來表示。然後再輸入到神經網路中,這樣神經網路就能擬合任何類型的數據,也就是實現多模態。
AI 發展經歷了三次技術浪潮,第一次浪潮是20 世紀60 年代,是AI 技術提出的十年後,這次浪潮是符號主義技術發展引起的,該技術解決了通用的自然語言處理以及人機對話的問題。同時期,專家系統誕生,這個是史丹佛大學在美國國家航天局的督促下完成的DENRAL 專家系統,該系統具備非常強的化學知識,通過問題進行推斷以生成和化學專家一樣的答案,這個化學專家系統可以被視為化學知識庫以及推論系統的結合。
在專家系統之後, 20 世紀 90 年代以色列裔的美國科學家和哲學家朱迪亞·珀爾(Judea Pearl)提出了貝葉斯網絡,也被稱為信念網絡。同時期,Brooks 提出了基於行為的機器人學,標誌著行為主義的誕生。
1997 年,IBM 深藍「Blue」以3.5: 2.5 擊敗了國際象棋冠軍卡斯帕羅夫(Kasparov),這場勝利被傳視為人工智慧的一個里程碑,AI 技術迎來了第二次發展的高潮。
第三次 AI 科技浪潮發生在 2006 年。深度學習三巨頭 Yann LeCun、Geoffrey Hinton 以及 Yoshua Bengio 提出了深度學習的概念,一種以人工神經網路為架構,對資料進行表徵學習的演算法。之後深度學習的演算法逐漸演進,從 RNN、GAN 到 Transformer 以及 Stable Diffusion,這兩個演算法共同塑造了這第三次技術浪潮,而這也是聯結主義的鼎盛時期。
許多標誌性的事件也伴隨著深度學習技術的探索與演進逐漸湧現,包括:
● 2011 年,IBM 的沃森(Watson)在《危險邊緣》(Jeopardy)回答測驗節目中擊敗人類、獲得冠軍。
● 2014 年,Goodfellow 提出 GAN(生成式對抗網絡,Generative Adversarial Network),透過讓兩個神經網路相互博弈的方式進行學習,能夠生成以假亂真的照片。同時 Goodfellow 也寫了一本書《Deep Learning》,稱為花書,是深度學習領域重要入門書籍之一。
● 2015 年,Hinton 等人在《自然》雜誌提出深度學習演算法,該深度學習方法的提出,立即在學術界以及工業界引起巨大反響。
●2015 年,OpenAI 創建,Musk、YC 總裁 Altman、天使投資人彼得·泰爾(Peter Thiel)等人宣布共同註資 10 億美元。
● 2016 年,以深度學習技術為基礎的 AlphaGo 與圍棋世界冠軍、職業九段棋手李世石進行圍棋人機大戰,以 4 比 1 的總比分獲勝。
● 2017 年,中國香港的漢森機器人技術公司(Hanson Robotics)開發的類人機器人索菲亞,其稱為歷史上首個獲得一等公民身份的機器人,具備豐富的面部表情以及人類語言理解能力。
●2017 年,在人工智慧領域有豐富人才、技術儲備的 Google 發布論文《Attention is all you need》提出 Transformer 演算法,大規模語言模型開始出現。
●2018 年,OpenAI 發布了基於 Transformer 演算法建構的 GPT(Generative Pre-trained Transformer),這是當時最大的語言模型之一。
●2018 年,Google 團隊 Deepmind 發佈基於深度學習的 AlphaGo,能夠進行蛋白質的結構預測,被視為人工智慧領域的巨大進步性標誌。
● 2019 年,OpenAI 發布 GPT-2 ,該模型具備 15 億個參數。
●2020 年,OpenAI 開發的GPT-3 ,具有1, 750 億個參數,比以前的版本GPT-2 高100 倍,該模型使用了570 GB 的文本來訓練,可以在多個NLP(自然語言處理)任務(答題、翻譯、寫文章)上達到最先進的效能。
● 2021 年,OpenAI 發布 GPT-4 ,該模型具備 1.76 兆個參數,是 GPT-3 的 10 倍。
● 2023 年 1 月基於 GPT-4 模型的 ChatGPT 應用程式推出, 3 月 ChatGPT 達到一億用戶,成為史上最快達到一億用戶的應用程式。
●2024 年,OpenAI 推出 GPT-4 omni。
深度學習產業鏈
目前大模型語言使用的都是基於神經網路的深度學習方法。以GPT 為首的大模型造就了一波人工智慧的熱潮,大量的玩家湧入這個賽道,我們也發現市場對於數據、算力的需求大量迸發,因此在報告的這一部分,我們主要是探索深度學習演算法的產業鏈,在深度學習演算法主導的AI 產業,其上下游是如何組成的,而上下游的現況與供需關係、未來發展又是如何。

GPT 訓練 Pipeline 圖源: WaytoAI
首先我們需要明確的是,在進行基於 Transformer 技術的 GPT 為首的 LLMs(大模型)訓練時,總共分為三個步驟。
在訓練之前,因為是基於 Transformer,因此轉換器需要將文字輸入轉換為數值,這個過程被稱為“Tokenization”,之後這些數值被稱為 Token。在一般的經驗法則下,一個英文單字或字元可以粗略視為一個 Token,而每個漢字可以被粗略視為兩個 Token。這個也是 GPT 計價使用的基本單位。
第一步,預訓練。透過給輸入層足夠多的數據對,類似於報告第一部分所舉例的(X,Y),來尋找該模型下各個神經元最佳的參數,這個時侯需要大量的數據,而這個過程也是最耗費算力的過程,因為要重複迭代神經元嘗試各種參數。一批資料對訓練完成之後,一般會使用同一批資料進行二次訓練以迭代參數。
第二步,微調。微調是給予一批量較少,但是質量非常高的數據,來訓練,這樣的改變就會讓模型的輸出有更高的質量,因為預訓練需要大量數據,但是很多數據可能存在錯誤或者低質量。微調步驟能夠透過優質資料提升模型的品質。
第三步,強化學習。首先會建立一個全新的模型,我們稱之為“獎勵模型”,這個模型目的非常簡單,就是對輸出的結果進行排序,因此實現這個模型會比較簡單,因為業務場景比較垂直。之後用這個模型來判定我們大模型的輸出是否是高品質的,這樣就可以用一個獎勵模型來自動迭代大模型的參數。 (但是有時候也需要人為參與來評判模型的輸出品質)
簡而言之,在大模型的訓練過程中,預訓練對資料的量有非常高的要求,所需耗費的GPU 算力也是最多的,而微調需要更高品質的資料來改進參數,強化學習可以透過一個獎勵模型來反覆迭代參數以輸出更高品質的結果。
在訓練的過程中,參數越多那麼其泛化能力的天花板就越高,例如我們以函數舉例的例子裡,Y = aX + b,那麼實際上有兩個神經元X 以及X 0 ,因此參數如何變化,其能夠擬合的數據都極為有限,因為其本質仍然是一條直線。如果神經元越多,那麼就能迭代更多的參數,那麼就能擬合更多的數據,這就是為什麼大模型大力出奇蹟的原因,並且這也是為什麼通俗取名大模型的原因,本質就是巨量的神經元以及參數、巨量的數據,同時需要巨量的算力。
因此,影響大模型表現主要由三個面向決定,參數數量、資料量與品質、算力,這三個共同影響了大模型的結果品質與泛化能力。我們假設參數數量為p,資料量為n(以Token 數量計算),那麼我們能夠透過一般的經驗法則計算所需的計算量,這樣就可以預估我們需要大致購買的算力情況以及訓練時間。
算力一般以Flops 為基本單位,代表了一次浮點運算,浮點運算是非整數的數值加減乘除的統稱,如2.5+ 3.557 ,浮點代表著能夠帶小數點,而FP 16 代表了支持小數的精度,FP 32 是一般較常見的精度。根據實踐下的經驗法則,預訓練(Pre-traning)一次(一般會訓練多次)大模型,大概需要 6 np Flops, 6 被稱為行業常數。而推理(Inference,就是我們輸入一個數據,等待大模型的輸出的過程),分成兩部分,輸入 n 個 token,輸出 n 個 token,那麼大約一共需要 2 np Flops。
在早期,使用的是 CPU 晶片進行訓練提供算力支持,但之後開始逐漸使用 GPU 替代,如 Nvidia 的 A 100、H 100 晶片等。因為 CPU 是作為通用運算存在的,但是 GPU 可以作為專用的運算,在能耗效率上遠遠超過 CPU。 GPU 運作浮點運算主要是透過一個叫做 Tensor Core 的模組進行。因此一般的晶片有 FP 16 / FP 32 精度下的 Flops 數據,這代表了其主要的運算能力,也是晶片的主要衡量指標之一。
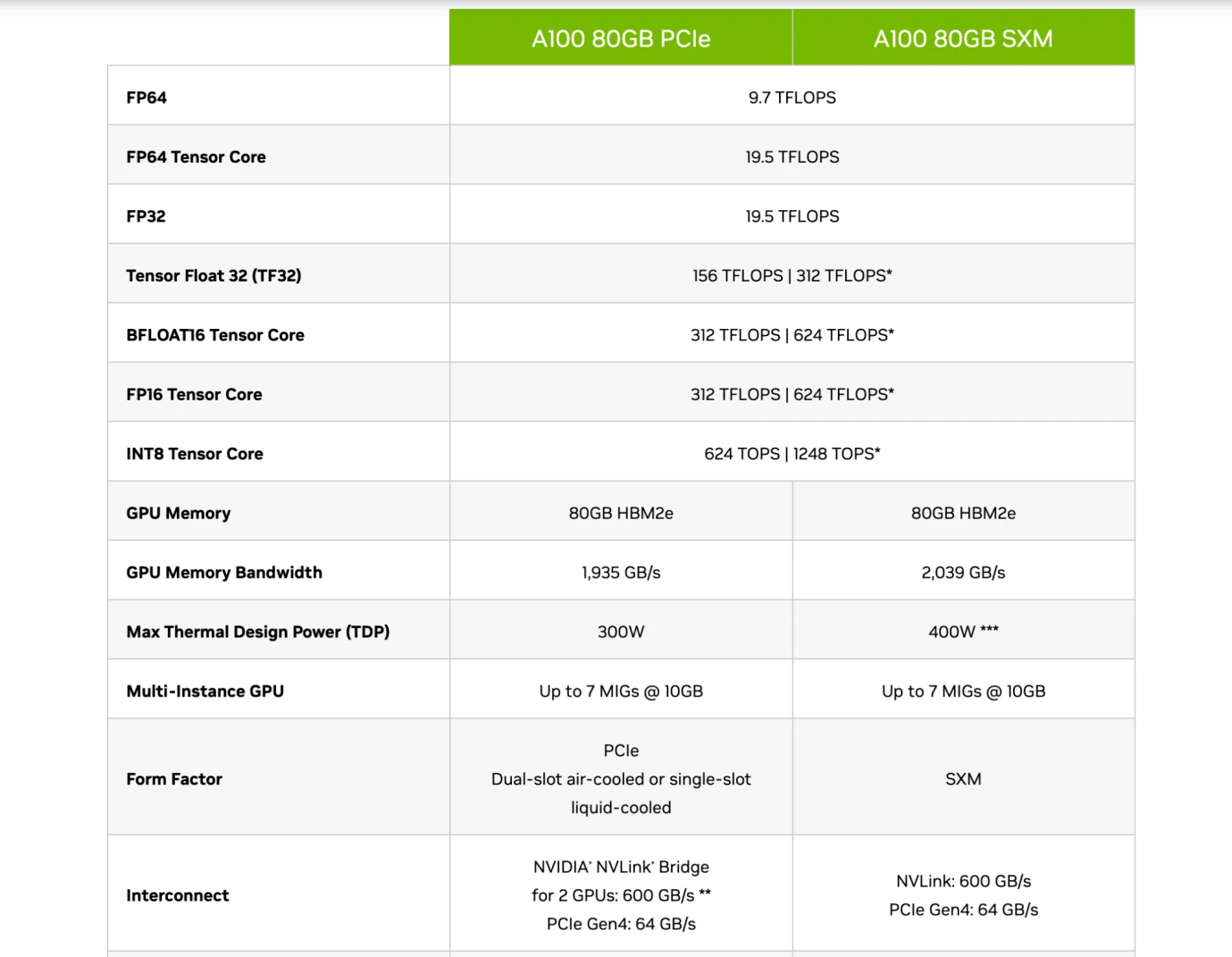
Nvidia A 100 晶片的 Specification,Source: Nvidia
因此讀者應該能夠看懂這些企業的晶片介紹,如上圖所示,Nvidia 的A 100 80 GB PCIe 和SXM 型號的對比中,看出PCIe 和SXM 在Tensor Core(專門用於計算AI 的模組)下,在FP 16 精準度下,分別是312 TFLOPS 和624 TFLOPS(Trillion Flops)。
假設我們的大模型參數以GPT 3 為例,有1750 億個參數, 1800 億個Token 的資料量(大約為570 GB),那麼在進行一次預訓練時,就需要6 np 的Flops,大約為3.15 * 1022 Flops,如果以TFLOPS(Trillion FLOPs)為單位大約為3.15* 1010 TFLOPS,也就是說一張SXM 型號的晶片預訓練一次GPT 3 大約需要50480769 秒, 841346 分鐘, 14022 小時, 584 天。
我們能夠看到這個及其龐大的計算量,需要多張最先進的晶片共同計算才能夠實現一次預訓練,並且GPT 4 的參數量又是GPT 3 的十倍(1.76 trillion),意味著即使數據在不變的情況下,晶片的數量要多買十倍,GPT-4 的Token 數量為13 兆個,又是GPT-3 的十倍,最終,GPT-4 可能需要超過100 倍的晶片算力。
在大模型訓練中,我們的資料儲存也有問題,因為我們的資料如GPT 3 Token 數量為1800 億個,大約在儲存空間中佔據570 GB,大模型1750 億個參數的神經網絡,大約佔據700 GB的儲存空間。 GPU 的記憶體空間一般都較小(如上圖介紹的 A 100 為 80 GB),因此在記憶體空間無法容納這些資料時,就需要考察晶片的頻寬,也就是從硬碟到記憶體的資料的傳輸速度。同時由於我們不會只使用一張晶片,那麼就需要使用聯合學習的方法,在多個 GPU 晶片共同訓練一個大模型,就涉及到 GPU 在晶片之間傳輸的速率。所以在很多時候,限制最後模型訓練實踐的因素或成本,不一定是晶片的運算能力,更多時侯可能是晶片的頻寬。因為資料傳輸很慢,會導致運行模型的時間拉長,電力成本就會提高。

H 100 SXM 晶片 Specification,Source: Nvidia
這個時侯,讀者大致就能完全看懂晶片的 Specification 了,其中 FP 16 代表精度,由於訓練 AI LLMs 主要使用的是 Tensor Core 組件,因此只需要看這個組件下的計算能力。 FP 64 Tensor Core 代表了在 64 精度下每秒 H 100 SXM 能夠處理 67 TFLOPS。 GPU memory 意味著晶片的記憶體只有 64 GB,完全無法滿足大模型的資料儲存需求,因此 GPU memory bandwith 就意味著資料傳輸的速度,H 100 SXM 為 3.35 TB/s。
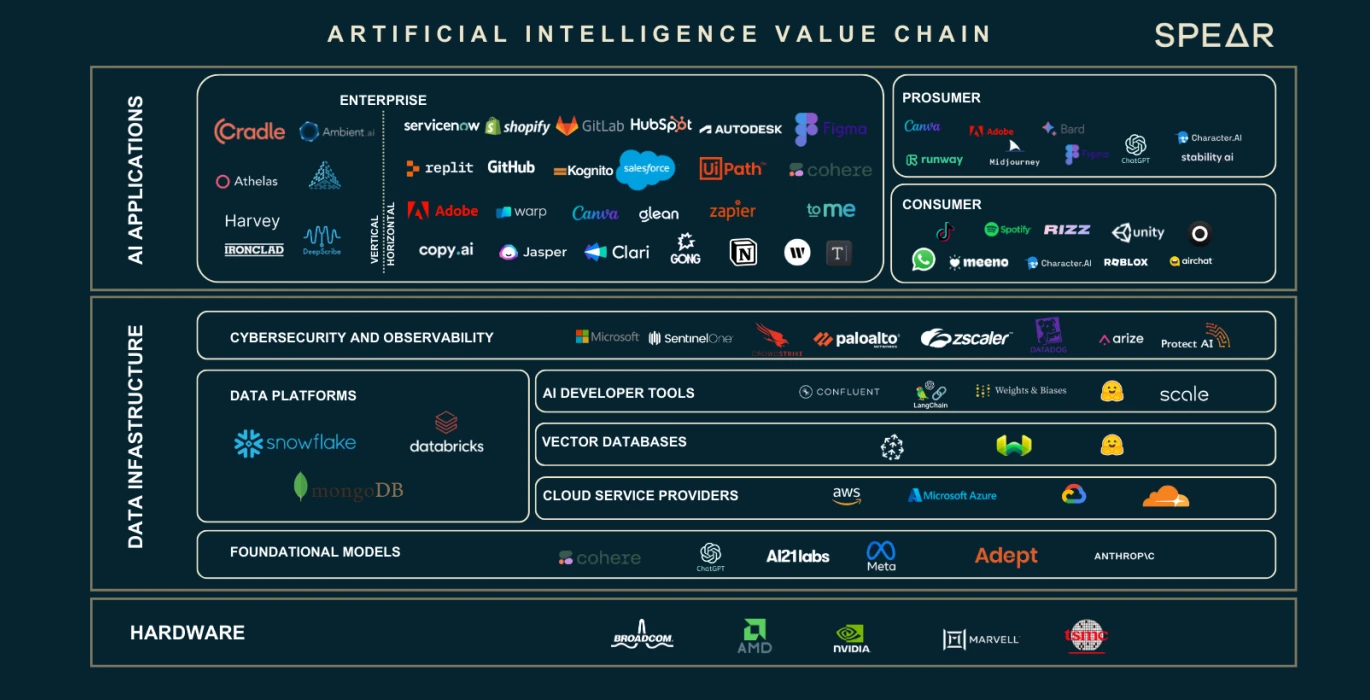
AI Value Chain,圖源:Nasdaq
我們看到了,數據、神經元參數數量的膨脹帶來的大量算力以及儲存需求的缺口。這三個主要的要素孵化了一整條的產業鏈。我們將根據上圖來介紹產業鏈中每一個部分在其中扮演的角色以及角色。
硬體 GPU 供應商
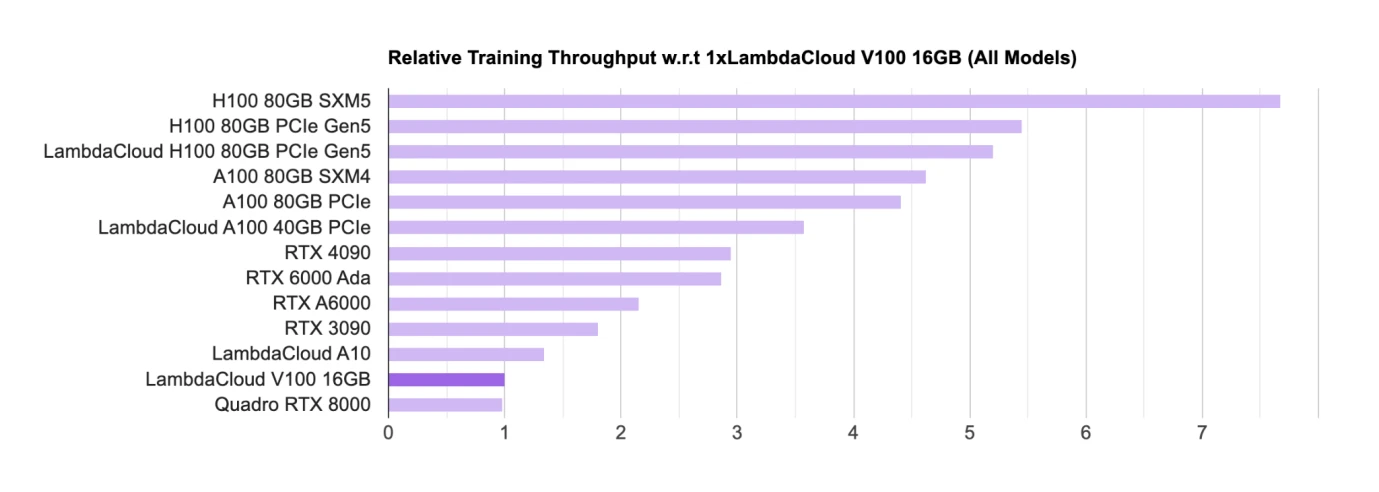
AI GPU 晶片 Rankings,Source: Lambda
硬體如GPU 是目前進行訓練和推理的主要晶片,對於GPU 晶片的主要設計商方面,目前Nvidia 處於絕對的領先地位,學術界(主要是高校和研究機構)主要是使用消費級的GPU(RTX,主要的遊戲GPU);工業界主要是使用H 100、 A 100 等用於大模型的商業化落地。
在榜單中,Nvidia 的晶片幾乎屠榜,所有晶片都來自 Nvidia。 Google 也有自己的 AI 晶片被稱為 TPU,但是 TPU 主要是 Google Cloud 在使用,為 B 端企業提供算力支持,自購的企業一般仍然傾向於購買 Nvidia 的 GPU。
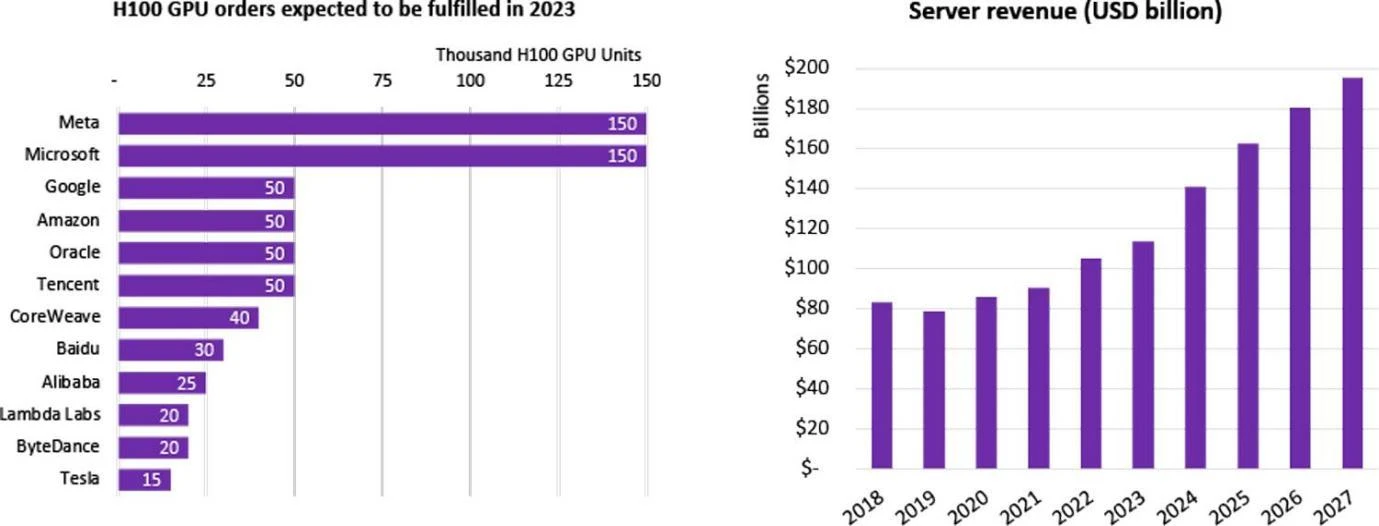
H 100 GPU Purchase Statistics by Company,Source: Omdia
大量的企業著手進行 LLMs 的研發,包括中國就有超過一百個大模型,而全球一共發行了超過 200 個大語言模型,許多互聯網巨頭都在參與這次 AI 熱潮。這些企業要不是自購大模型、就是透過雲端企業進行租賃。 2023 年,Nvidia 最先進的晶片 H 100 一發布,就獲得了多家公司的認購。全球對 H 100 晶片的需求遠大於供給,因為目前僅僅只有 Nvidia 一家在供給最高端的晶片,其出貨週期已經達到了驚人的 52 週之久。
鑑於 Nvidia 的壟斷情況,Google 作為人工智慧的絕對領頭企業之一,Google牽頭,英特爾、高通、微軟、亞馬遜共同成立了 CUDA 聯盟,希望共同研發 GPU 以擺脫Nvidia 對深度學習產業鏈的絕對影響力。
對於超大型科技公司/雲端服務供應商/國家實驗室來說,他們動則購買上千、上萬片H 100 晶片,用以組成HPC(高效能運算中心),例如Tesla 的CoreWeave 叢集購買了一萬片H 100 80 GB,平均購買價為44000 美元(Nvidia 成本約為1/10),總共花費4.4 億美元;而Tencent 更是購買5 萬片;Meta 狂買15 萬片,截至2023 年底, Nvidia 作為唯一高效能GPU 賣家,H 100 晶片的訂購量就超過了50 萬片。
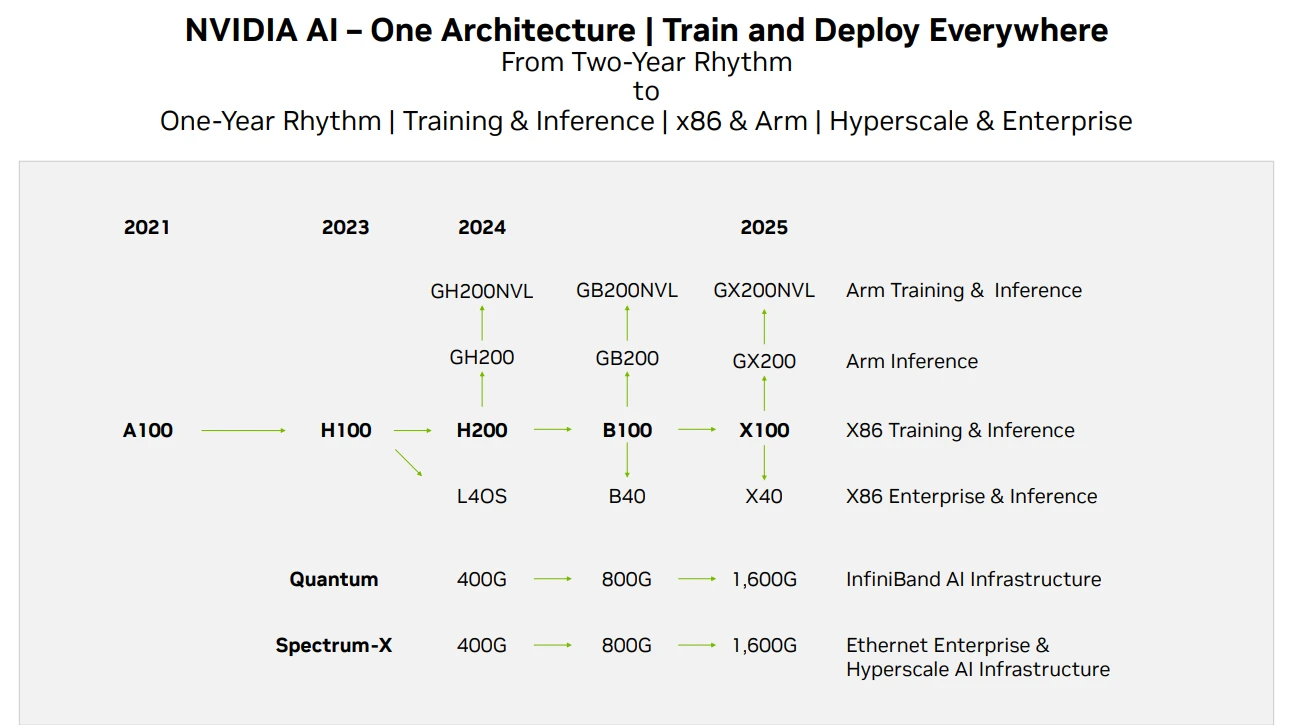
Nvidia GPU 產品路線圖,Source: Techwire
在Nvidia 的晶片供給方面,以上是其產品迭代路線圖,目前截至該報告,H 200 的消息已經發出,預計H 200 的性能是H 100 性能的兩倍,而B 100 將在2024 年底或2025 年初推出。目前 GPU 的發展仍滿足摩爾定律,效能每 2 年翻一倍,價格下降一半。
雲端服務供應商

Types of GPU Cloud, Source: Salesforce Ventures
雲端服務供應商在購買足夠的 GPU 組成 HPC 後,能夠為資金有限的人工智慧企業提供彈性的算力以及託管訓練解決方案。如上圖所示,目前市場主要分為三類雲端算力供應商,第一類是以傳統雲端廠商為代表的超大規模拓展的雲端算力平台(AWS、Google、Azure)。第二類是垂直賽道的雲端算力平台,主要是為AI 或高效能運算而佈置的,他們提供了更專業的服務,因此在與巨頭競爭中,仍然存在一定的市場空間,這類新興垂直產業雲端服務企業包括CoreWeave(C 輪獲得11 以美元融資,估值190 億美元)、Crusoe、Lambda(C 輪融資2.6 億美元,估值超過15 億美元)等。第三類雲端服務供應商是新出現的市場玩家,主要是推理即服務供應商,這些服務商從雲端服務商租用GPU,這類服務商主要為客戶部署已經預訓練完畢的模型,在之上進行微調或推理,這類市場的代表企業包括了Together.ai(最新估值12.5 億美元)、Fireworks.ai(Benchmark 領投,A 輪融資2500 萬美元)等。
訓練資料來源提供者
如同我們第二部分前面所述,大模型訓練主要經歷三個步驟,分別為預訓練、微調、強化學習。預訓練需要大量的數據,微調需要高品質的數據,因此對於 Google 這種搜尋引擎(擁有大量數據)和 Reddit(優質的對答數據)這種類型的數據公司就受到市場的廣泛關注。
有些開發廠商為了不與GPT 等通用型的大模型競爭,選擇在細分領域進行開發,因此對數據的要求就變成了這些數據是特定行業的,比如金融、醫療、化學、物理、生物、影像辨識等。這些是針對特定領域的模型,需要特定領域的數據,因此就存在為這些大模型提供數據的公司,我們也可以叫他們Data labling company,也就是為採集數據後為數據打標籤,提供更加優質與特定的資料類型。
對於模型研發的企業來說,大量資料、優質資料、特定資料是三種主要的資料訴求。
主要 Data Labeling 公司,Source: Venture Radar
微軟的一項研究認為對於 SLM(小語言模型)來說,如果他們的資料品質明顯優於大語言模型,那麼其效能不一定會比 LLMs 差。並且實際上 GPT 在原創力以及數據上並沒有明顯的優勢,主要是其對該方向的押注的膽量造就了其成功。紅杉美國也坦言,GPT 在未來不一定會保持競爭優勢,原因是目前這方面沒有太深的護城河,主要的限制來自算力獲取的限制。
對於資料量來說,根據 EpochAI 的預測,按照目前的模型規模成長情況, 2030 年所有的低品質和高品質資料都會耗盡。所以目前業界正在探索人工智慧合成數據,這樣就可以產生無限的數據,那麼瓶頸就只剩下算力,這個方向仍處於探索階段,值得開發者們注意。
資料庫提供者
我們有了數據,但是數據也需要儲存起來,一般是存放在資料庫中,這樣方便數據的增刪改查。在傳統的網路業務中,我們可能聽說過 MySQL,在以太坊客戶端 Reth 中,我們聽說過 Redis。這些都是我們存放業務資料或區塊鏈鏈上資料的本地資料庫。對於不同的資料類型或業務有不同的資料庫適配。
對於 AI 資料以及深度學習訓練推理任務,目前業界使用的資料庫稱為「向量資料庫」。向量資料庫旨在有效地儲存、管理和索引海量高維向量資料。因為我們的數據並不是單純的數值或文字,而是圖片、聲音等海量的非結構化的數據,向量資料庫能夠將這些非結構化的數據統一以「向量」的形式存儲,而向量資料庫適合這些向量的儲存和處理。

Vector Database Classification, Source: Yingjun Wu
目前主要的玩家有 Chroma(獲得 1,800 萬美元融資輪融資)、Zilliz(最新一輪融資 6,000 萬美元)、Pinecone、Weaviate 等。我們預計伴隨著資料量的需求增加,以及各種細分領域的大模型和應用的迸發,對 Vector Database 的需求將大幅增加。並且由於這一領域有很強的技術壁壘,在投資時更多考慮偏向成熟和有客戶的企業。
邊緣設備
在組成GPU HPC(高效能運算叢集)時,通常會消耗大量的能量,這就會產生大量的熱能,晶片在高溫環境下,會限制運行速度以降低溫度,這就是我們俗稱的“降頻” ,這就需要一些降溫的邊緣設備來確保HPC 持續運作。
所以這裡牽涉到產業鏈的兩個方向,分別是能源供應(一般是採用電能)、冷卻系統。
目前在能源供應側,主要採用電能,資料中心及支援網路目前佔全球電力消耗的 2% -3% 。 BCG 預計隨著深度學習大模型參數的成長以及晶片的迭代,截至 2030 年,訓練大模型的電力將增加三倍。目前國內外科技廠商正積極投資能源企業這條賽道,投資的主要能源方向包括地熱能、氫能、電池儲存和核能等。
在 HPC 群聚散熱方面,目前是以風冷為主,但是許多 VC 正在大力投資液冷系統,以維持 HPC 的平穩運作。例如 Jetcool 就聲稱其液冷系統能夠為 H 100 叢集的總功耗降低 15% 。目前液冷主要分成三個探索方向分別為冷版式液冷、浸沒式液冷、噴淋式液冷。這方面的企業有:華為、Green Revolution Cooling、SGI 等。
應用
目前 AI 應用的發展,類似於區塊鏈產業的發展,作為一個創新的產業,Transformer 是在 2017 年提出,OpenAI 是在 2023 年才證實大模型的有效性。所以現在許多 Fomo 的企業都擁擠在大模型的研發賽道,也就是基礎設施非常擁擠,但應用開發卻沒有跟上。

Top 50 月活用戶,Source: A16Z
目前前十月活的 AI 應用大多是搜尋類型的應用,實際走出來的 AI 應用程式還非常有限,應用程式類型較為單一,並沒有一些社交等類型的應用程式成功闖出來。
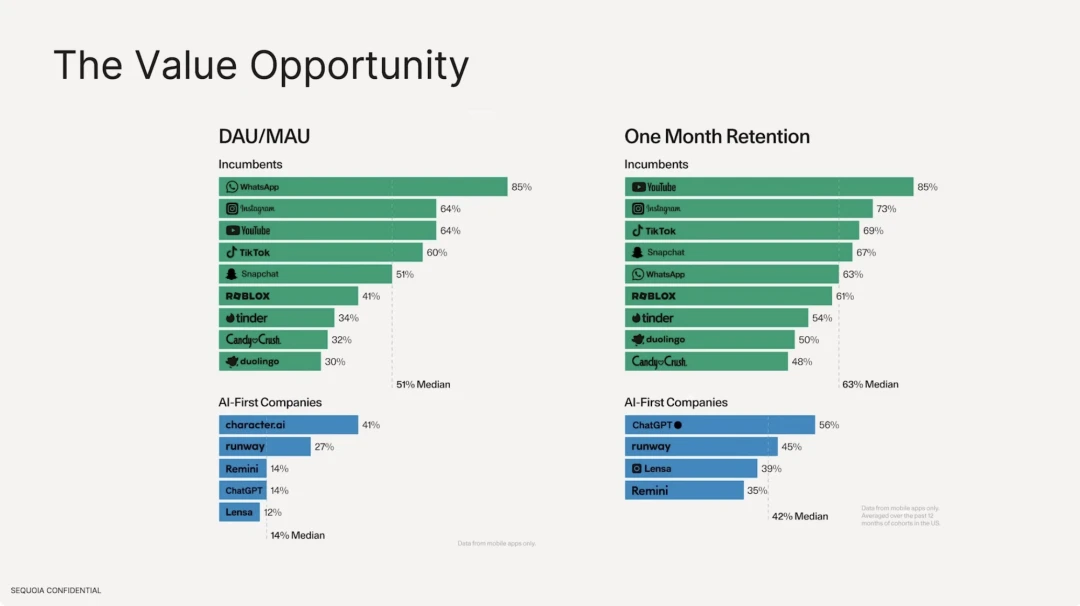
我們同時發現,基於大模型的 AI 應用,其留存率遠低於現有的傳統網路應用。活躍用戶數方面,傳統的網路軟體中位數在 51% ,最高的是 Whatsapp,具備很強的用戶黏性。但在 AI 應用程式側,DAU/MAU 最高的為 character.ai 僅為 41% ,DAU 佔據總用戶數的中位數 14% 。在用戶留存率方面,傳統網路軟體最好的是 Youtube、Instagram、Tiktok,前十名的留存率中位數為 63% ,相較之下 ChatGPT 留存率僅為 56% 。

AI Application Landscape, Source: Sequoia
根據紅杉美國的報告,將應用程式從面向的角色角度分為三類,分別為專業消費者、企業、一般消費者。
1. 面向消費者:一般用於提升生產力,如文字工作者使用GPT 進行問答,自動化的3D渲染建模,軟體剪輯,自動化的代理人,使用Voice 類型的應用進行語音對話、陪伴、語言練習等。
2. 面向企業:通常是 Marketing、法律、醫療設計等行業。
雖然現在有很多人批評,基礎設施遠大於應用,但其實我們認為現代世界已經廣泛的被人工智慧技術所重塑,只不過使用的是推薦系統,包括字節跳動旗下的tiktok、今日頭條、汽水音樂等,以及小紅書和微信影片號碼、廣告推薦技術等都是為個人進行客製化的推薦,這些都屬於機器學習演算法。所以目前蓬勃發展的深度學習不完全代表 AI 產業,有許多潛在的有機會實現通用人工智慧的技術也在並行發展,並且其中一些技術已經被廣泛的應用於各行各業。
那麼,Crypto x AI 之間發展出怎樣的關係呢? Crypto 產業 Value Chain 又有哪些值得關注的項目?我們將在《Gate Ventures:AI x Crypto 從入門到精通(下)》為大家一一解讀。
免責聲明:
以上內容僅供參考,不應被視為任何建議。在進行投資之前,請務必尋求專業建議。
關於Gate Ventures
Gate Ventures是Gate.io 旗下的創投部門,專注於對去中心化基礎設施、生態系統和應用程式的投資,這些技術將在Web 3.0 時代重塑世界。 Gate Ventures與全球產業領袖合作,賦予那些擁有創新思維和能力的團隊和新創公司,重新定義社會和金融的互動模式。
Twitter: https://x.com/gate_ventures
Medium: https://medium.com/gate_ventures





