




Coprocessor History
In the traditional computer field, a coprocessor is a processing unit responsible for handling other complicated things for the CPU brain. Coprocessing is very common in the computer field. For example, Apple launched the M7 motion coprocessor in 2013, which greatly improved the motion sensitivity of smart devices. The well-known GPU is a coprocessor proposed by Nvidia in 2007, which is responsible for processing tasks such as graphics rendering for the CPU. The GPU accelerates applications running on the CPU by offloading some computationally intensive and time-consuming code parts. This architecture is called heterogeneous / hybrid computing.
The coprocessor can offload some complex codes with single performance requirements or extremely high performance requirements, allowing the CPU to handle more flexible and changeable parts.
There are two serious problems that hinder the development of applications on the Ethereum chain:
Since the operation requires a high Gas Fee, a normal transfer is hard-coded as 21,000 Gas Limit, which shows the bottom line of the Gas Fee of the Ethereum network. Other operations including storage will cost more Gas, which will in turn limit the scope of development of on-chain applications. Most contract codes are only written around asset operations. Once complex operations are involved, a large amount of Gas will be required, which is a serious obstacle to the Mass Adoption of applications and users.
Since smart contracts exist in virtual machines, they can actually only access data from the most recent 256 blocks. Especially with the introduction of the EIP-4444 proposal in next years Pectra upgrade, full nodes will no longer store past block data. The lack of data has led to the delay in the emergence of innovative data-based applications. After all, apps like Tiktok, Instagram, multi-data Defi applications, and LLM are all built based on data. This is why data-based social protocols such as Lens are launching Layer 3 Momoka, because we believe that blockchain has a very smooth data flow, after all, everything on the chain is open and transparent. But in reality, this is not the case. Only token asset data flows smoothly, but data assets are still greatly hindered by the imperfections of the underlying infrastructure, which will also severely limit the emergence of Mass Adoption products.
Through this fact, we found that both computing and data are the reasons that limit the emergence of the new computing paradigm Mass Adoption. However, this is a drawback of the Ethereum blockchain itself, and it was not designed to handle large-scale computing and data-intensive tasks. But how to achieve compatibility with these computing and data-intensive applications? Here we need to introduce coprocessors. The Ethereum chain itself is a CPU, and the coprocessor is similar to the GPU. The chain itself can process some non-computational, data-intensive asset data and simple operations, and applications that want to flexibly use data or computing resources can use coprocessors. With the exploration of ZK technology, in order to ensure that the coprocessor does not need to trust the calculation and data use under the chain, it is natural that most coprocessors are developed based on ZK as the underlying layer.
For ZK Coporcessor, its application boundaries are so broad that it can cover any real dapp application scenarios, such as social networking, games, Defi building blocks, risk control systems based on on-chain data, Oracle, data storage, large model language training and reasoning, etc. In theory, anything that Web2 applications can do can be achieved with the ZK coprocessor, and Ethereum is used as the final settlement layer to protect the security of the application.
In the traditional world, there is no clear definition of coprocessors. Any single chip that can assist in completing tasks is called a coprocessor. The current industry definition of ZK coprocessors is not exactly the same. For example, ZK-Query, ZK-Oracle, ZKM, etc. are all coprocessors that can assist in querying complete data on the chain, trusted data off the chain, and off-chain calculation results. From this definition, layer 2 is actually a coprocessor of Ethereum. We will also compare the similarities and differences between Layer 2 and general ZK coprocessors in the following text.
Coprocessor Project List
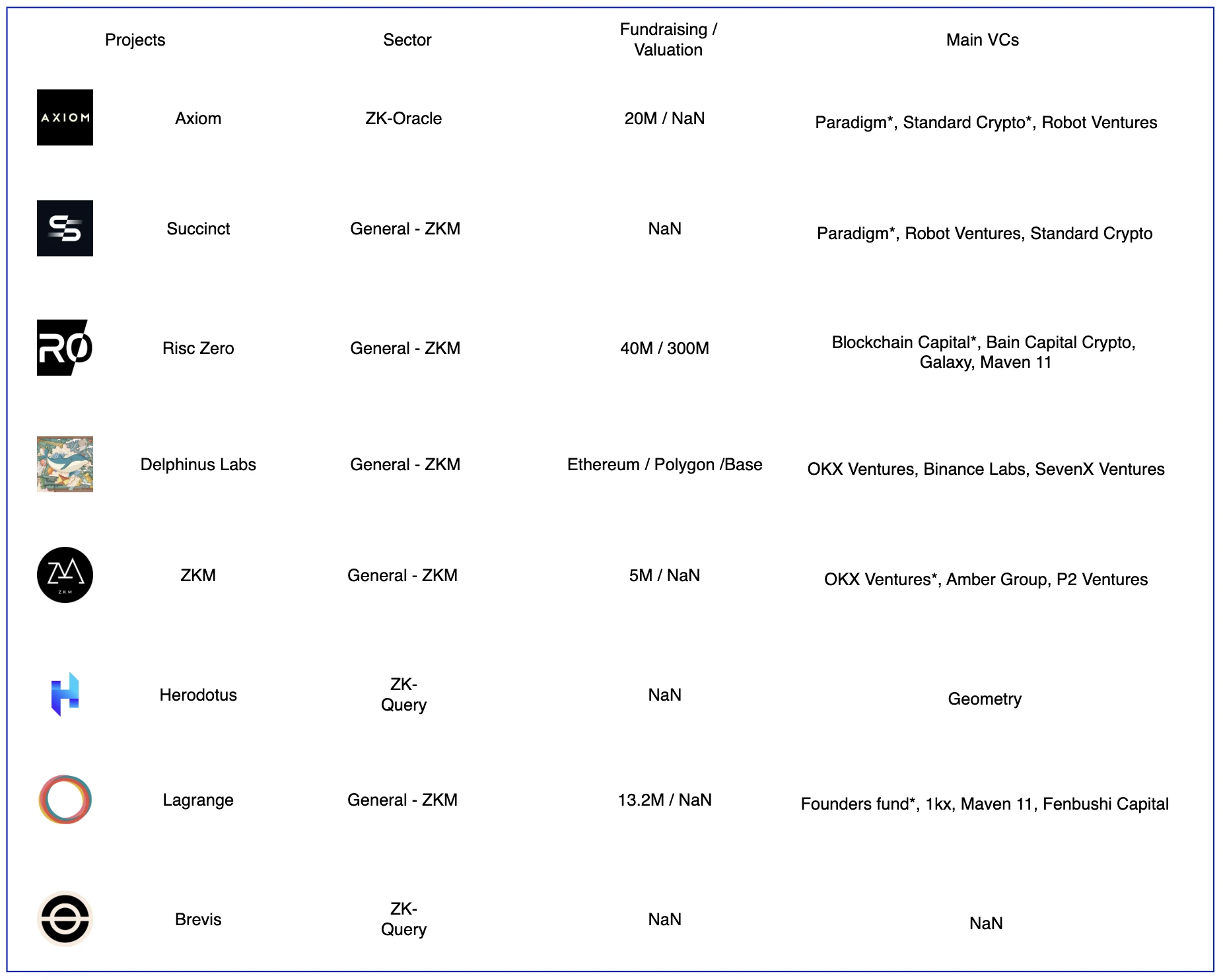
Some of the ZK coprocessor projects. Image source: Gate Ventures
Currently, the more well-known co-processors in the industry are divided into three parts, namely on-chain data indexing, oracle, and ZKML, which are the three application scenarios. The project that includes all three scenarios is General-ZKM. The virtual machines running off-chain are different. For example, Delphinus focuses on zkWASM, while Risc Zero focuses on Risc-V architecture.
Coprocessor Technology Architecture
We take the General ZK coprocessor as an example to analyze its architecture, so that readers can understand the similarities and differences in technology and mechanism design of this general-purpose virtual machine, and to judge the development trend of coprocessors in the future. The analysis mainly focuses on the three projects of Risc Zero, Lagrange, and Succinct.
Risc Zero
In Risc Zero, its ZK coprocessor is named Bonsai.
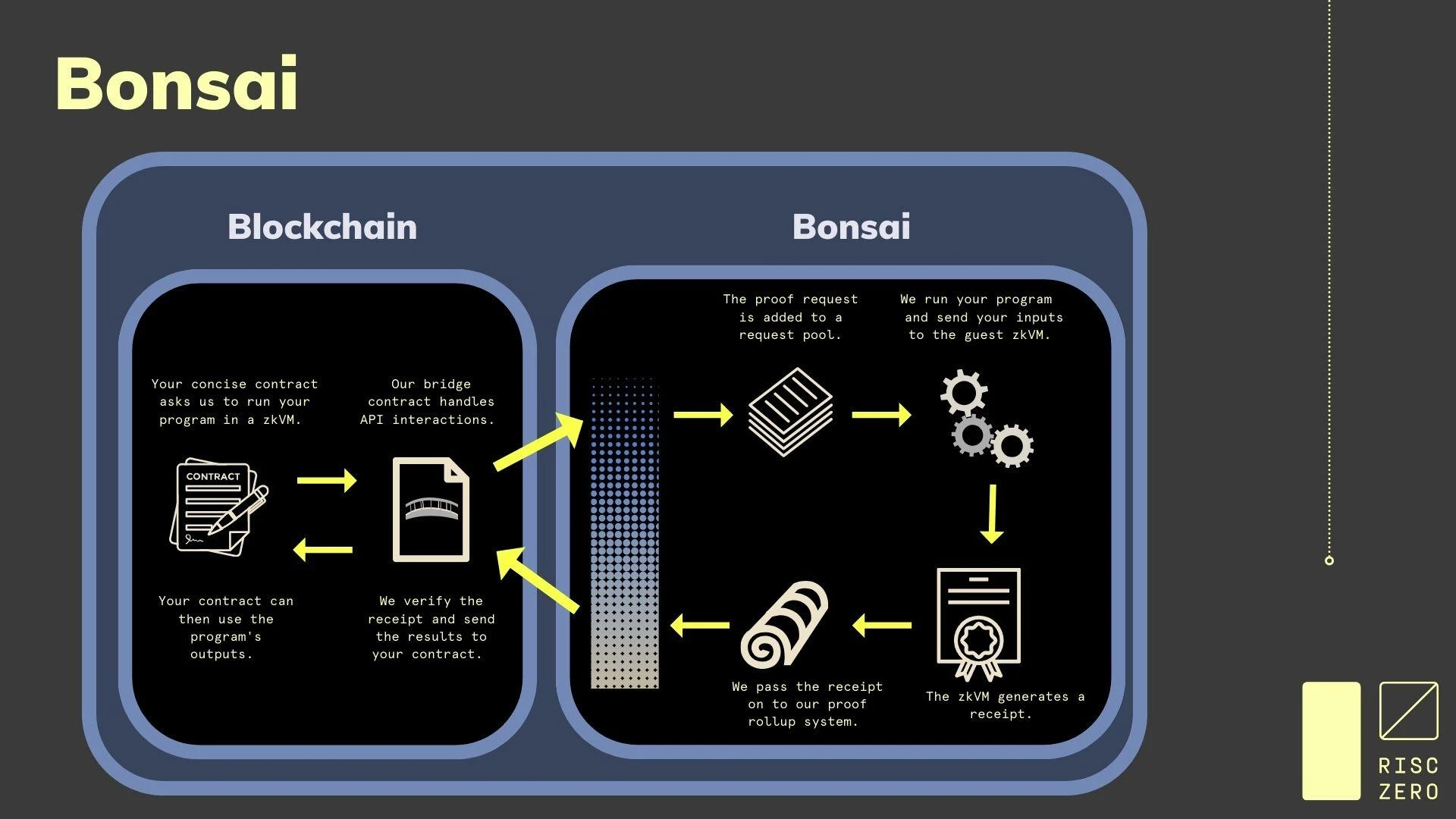
Bonsai architecture, source: Risc Zero
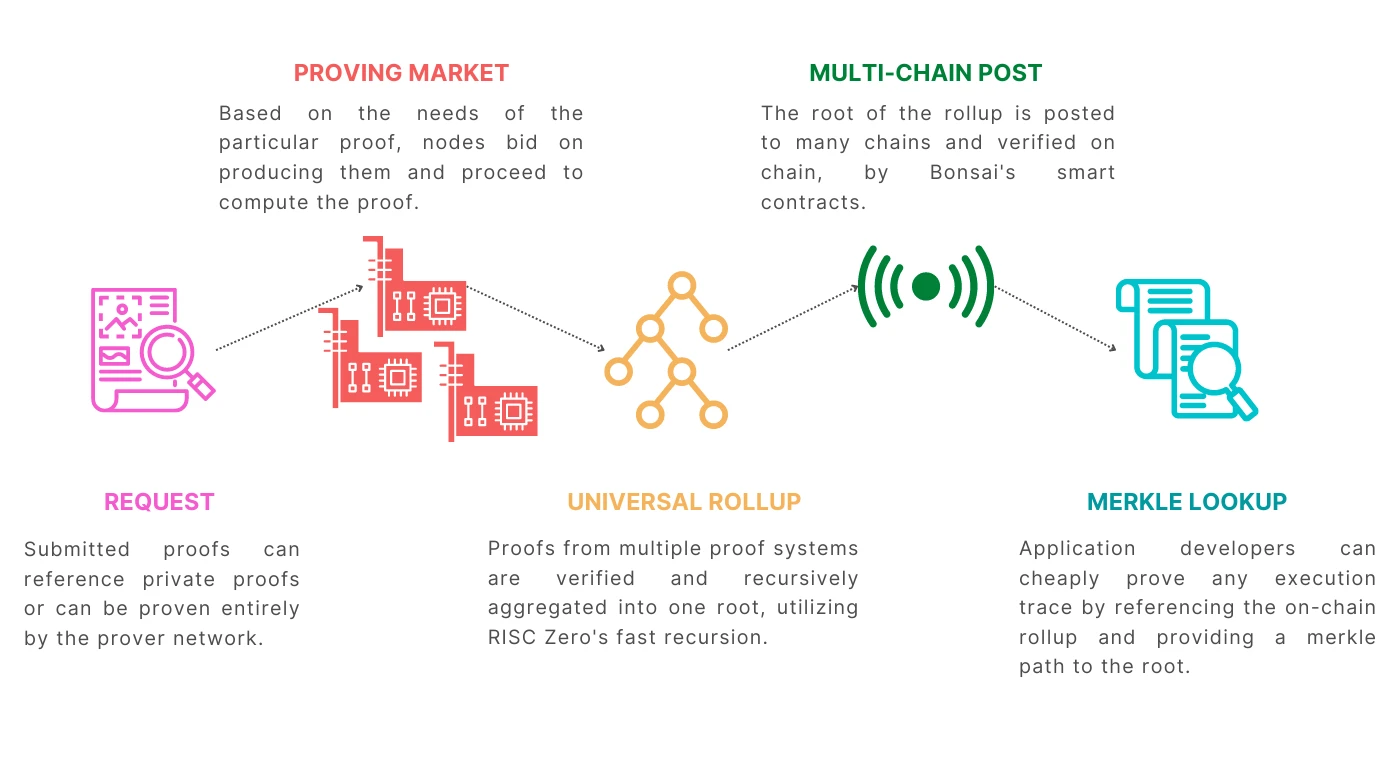
Bonsai component, source: Risc Zero
In Bonsai, a complete set of chain-independent zero-knowledge proof components is built, with the goal of becoming a chain-independent coprocessor based on the Risc-V instruction set architecture, with great versatility, and supporting languages including Rust, C++, Solidity, Go, etc. Its main functions include:
A general-purpose zkVM capable of running any virtual machine in a zero-knowledge/verifiable environment.
A ZK proof generation system that can be directly integrated into any smart contract or chain
A general rollup that distributes any computation proved on Bonsai to the chain, allowing network miners to generate proofs.
Its components include:
Prover network: Through the Bonsai API, the prover receives the ZK code that needs to be verified in the network, and then runs the proof algorithm to generate the ZK proof. This network will be open to everyone in the future.
Request Pool: This pool stores proof requests initiated by users (similar to Ethereums mempool, which is used to temporarily store transactions). Then the Request Pool will be sorted by the Sequencer to generate blocks, and many of the proof requests will be split to improve proof efficiency.
Rollup Engine: This engine collects the proof results collected from the prover network, packages them into Root Proof, and uploads them to the Ethereum mainnet so that the validators on the chain can verify them at any time.
Image Hub: This is a visual developer platform that can store functions and complete applications. Developers can call corresponding APIs through smart contracts, so on-chain smart contracts have the ability to call off-chain programs.
State Store: Bonsai also introduced off-chain state storage, which is stored in the database in the form of key-value pairs. This can reduce on-chain storage costs and, in conjunction with the ImageHub platform, reduce the complexity of smart contracts.
Proving Marketplace: The upper and middle reaches of the ZK proof industry chain, the computing power market is used to match the supply and demand of computing power.
Lagrange
Lagrange’s goal is to build a coprocessor and verifiable database that includes historical data on the blockchain, which can be used to build trustless applications. This will meet the development of computing and data-intensive applications.
This involves two functions:
Verifiable database: By indexing the storage of the smart contract on the chain, the on-chain state generated by the smart contract is put into the database. In essence, it is to rebuild the storage, state and blocks of the blockchain, and then store them in an updated way in an easy-to-retrieve off-chain database.
Computation based on the MapReduce principle: The MapReduce principle is to use data separation and multi-instance parallel computing on a large database, and finally integrate the results together. This architecture that supports parallel execution is called zkMR by Lagrange.
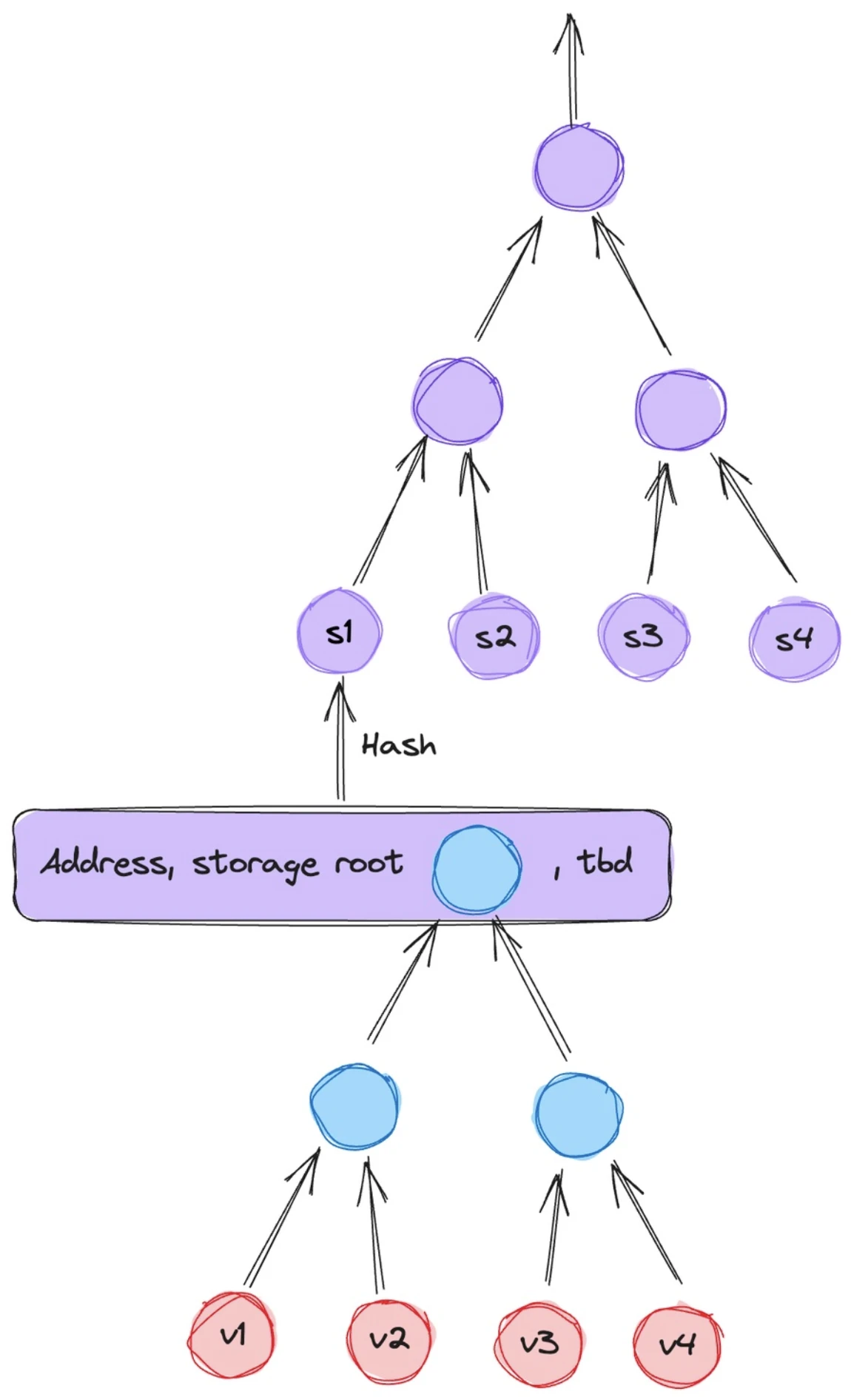
In the design of the database, there are three parts of on-chain data, namely contract storage data, EOA status data and block data.
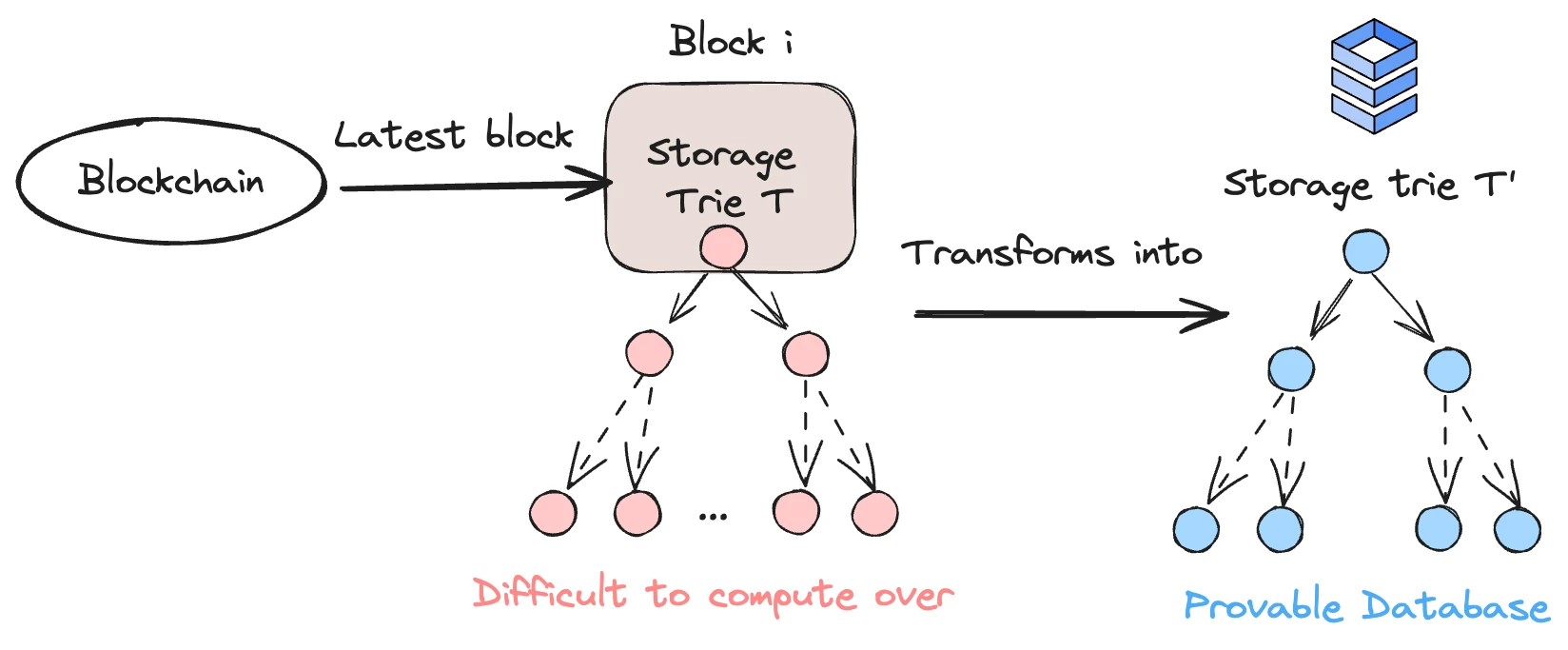
Lagrange database structure, source: Lagrange
The above is the mapping structure of the data stored in the contract. The state variables of the contract are stored here, and each contract has an independent Storage Trie, which is stored in the form of MPT tree in Ethereum. Although the MPT tree is simple, its efficiency is very low, which is why the core developers of Ethereum promote the development of Verkel tree. In Lagrange, each node can use SNARK/STARK for proof, and the parent node contains the proof of the child node, which requires the use of recursive proof technology.
Account status, source: Lagrange
The accounts are EOA and contract accounts, and both can be stored in the form of Account/Storage Root (storage space for contract variables) to represent the account status, but it seems that Lagrange has not fully designed this part. In fact, the root of State Trie (state storage space for external accounts) needs to be added.
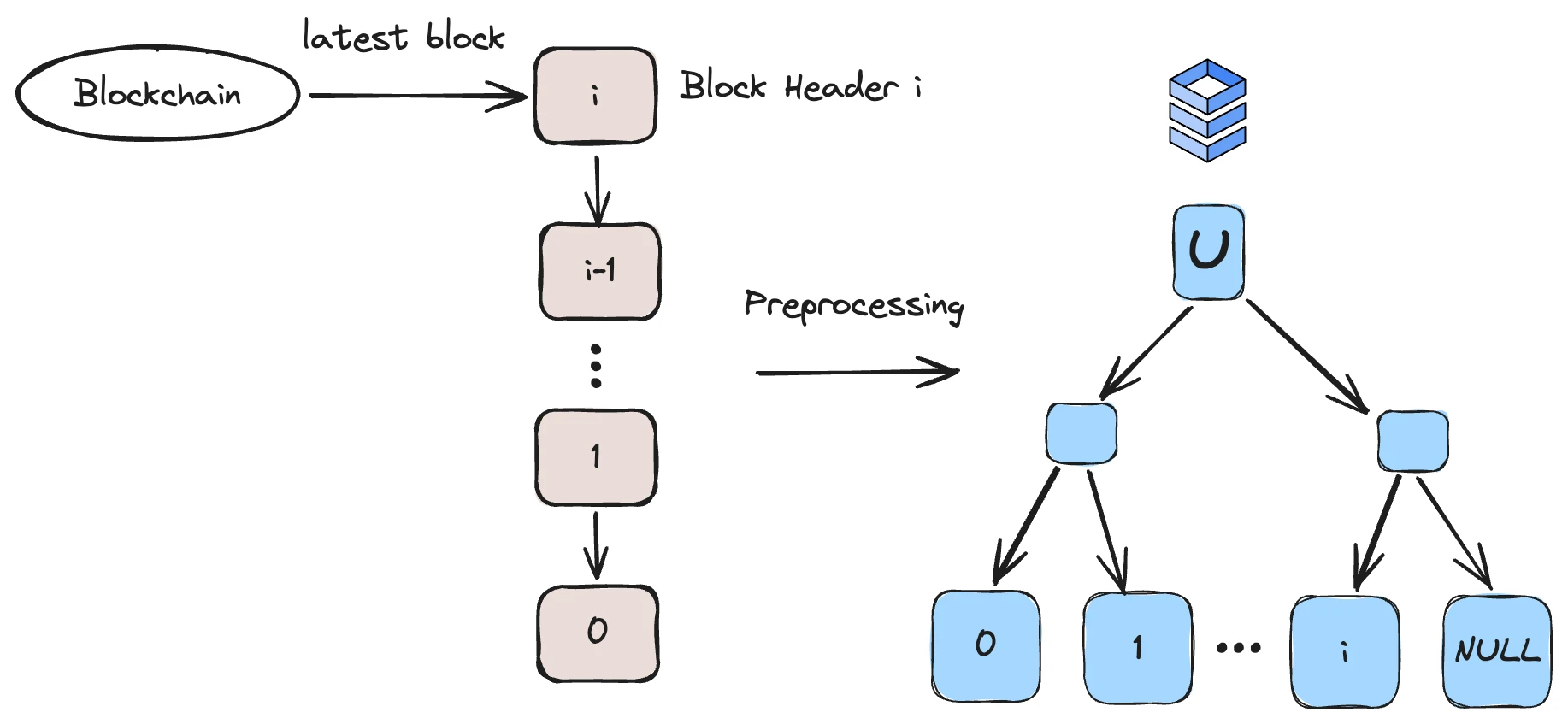
Block data structure, source: Lagrange
In the new data structure, Lagrange created a block data structure that is friendly to SNARKs proofs. Each leaf of this tree is a block header, and the size of this number is fixed. If Ethereum produces a block once every 12 seconds, then this database can be used for approximately 25 years.
In Lagrange’s ZKMR virtual machine, the calculation has two steps:
Map: Distributed machines map the entire data and generate key-value pairs.
Reduce: Distributed computers calculate the proofs separately and then combine all the proofs together.
In short, ZKMR can combine proofs of smaller computations to create a proof of the entire computation. This allows ZKMR to scale efficiently to perform complex computational proofs on large data sets that require multiple steps or multiple layers of computation. For example, if Uniswap is deployed on 100 chains, then if you want to calculate the TWAP price of a token on 100 chains, it will require a lot of computation and integration. At this time, ZKMR can calculate each chain separately and then combine them into a complete computational proof.
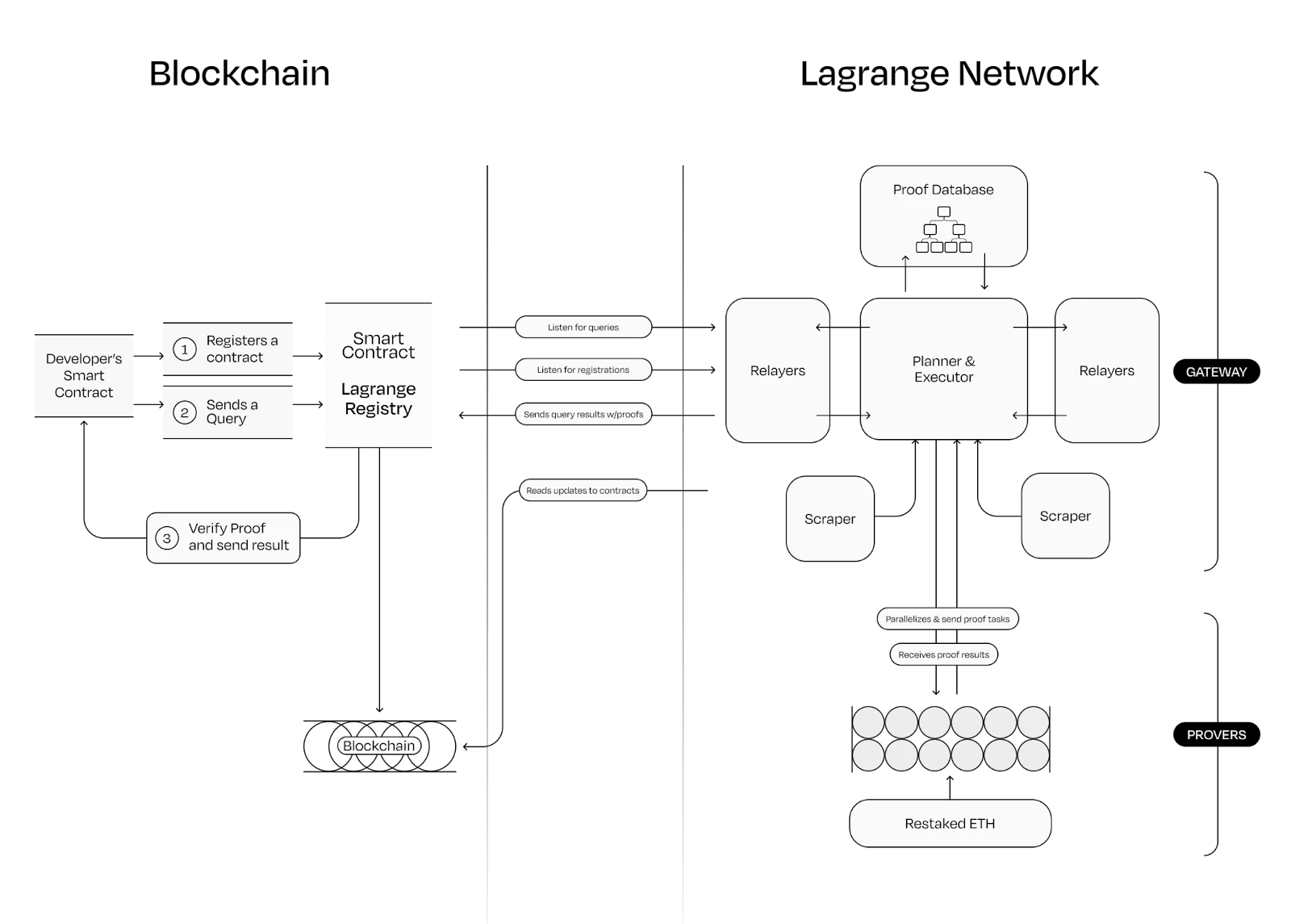
Lagrange coprocessor operation process, source: Lagrange
The above is its execution process:
The developers smart contract is first registered on Lagrange, and then submits a proof request to Lagranges on-chain smart contract. At this time, the proxy contract is responsible for interacting with the developers contract.
The off-chain Lagrange jointly verifies by breaking down requests into small parallelizable tasks and distributing them to different attesters.
The prover is actually also a network, and the security of the network is guaranteed by EigenLayers Restaking technology.
Succinct
Succinct Network aims to integrate programmable facts into every part of the blockchain development Stack (including L2, coprocessors, cross-chain bridges, etc.).
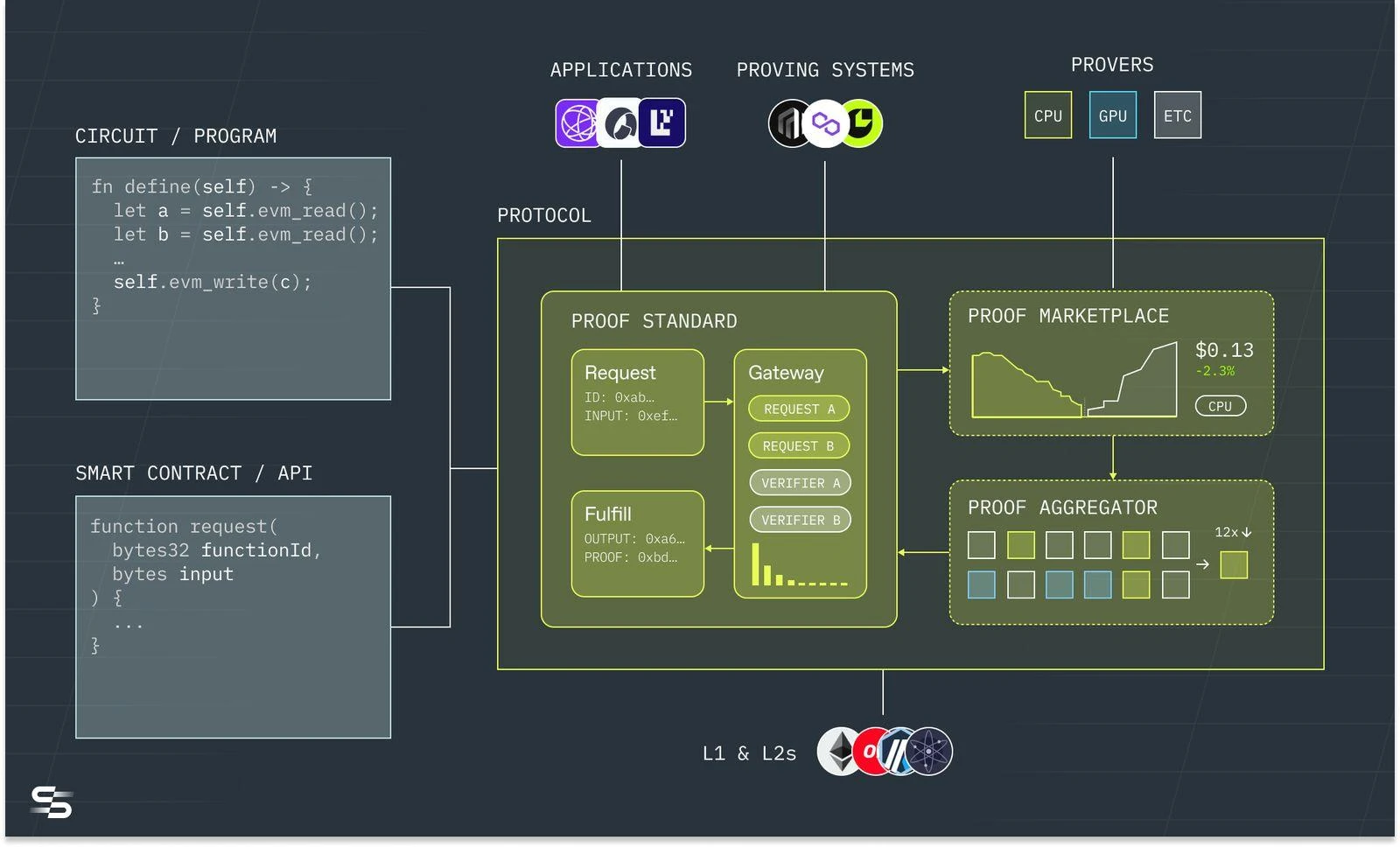
Succinct operation process, source: Succinct
Succinct can accept codes including Solidity and specialized languages (DSL) in the zero-knowledge domain, and pass them to the Succinct coprocessor under the chain. Succinct completes the data index of the target chain, and then sends the proof application to the proof market, which can support CPU, GPU, and ETC chips such as mining machines to submit proofs in the proof network. Its feature is that the proof market is compatible with various proof systems, because there will be a long period of coexistence of various proof systems in the future.
Succincts off-chain ZKVM is called SP (Succinct Processor), which can support Rust and other LLVM languages. Its core features include:
Recursion + Verification: Recursive proof technology based on STARKs technology can exponentially enhance ZK compression efficiency.
Support for SNARKs to STARKs wrappers: Able to take advantage of both SNARKs and STARKs, solving the trade-off between proof size and verification time.
Precompilation-centric zkVM architecture: For some common algorithms such as SHA 256, Keccak, ECDSA, etc., they can be compiled in advance to reduce the proof generation time and verification time at runtime.
Compare
When comparing general-purpose ZK coprocessors, we will focus on comparing them based on the first principles of Mass Adoption, and we will also explain why it is important:
Data indexing/synchronization issues: Only complete on-chain data and synchronization indexing functions can meet the requirements of big data-based applications, otherwise its application scope is relatively limited.
Based on technology: SNARKs and STARKs technologies have different decision points. In the medium term, SNARKs technology will be the main technology, and in the long term, STARKs technology will be the main technology.
Whether to support recursion: Only by supporting recursion can data be compressed to a greater extent and parallel proof of calculation be realized. Therefore, realizing full recursion is the technical highlight of the project.
Proof system: The proof system directly affects the size and time of proof generation. This is the most costly part of ZK technology. Currently, the main approach is to build a self-built ZK cloud computing market and proof network.
Ecological cooperation: Ability to judge whether its technical direction is recognized by B-side users through third-party real demand parties.
Supporting VC and financing situation: may be able to indicate its subsequent resource support situation.
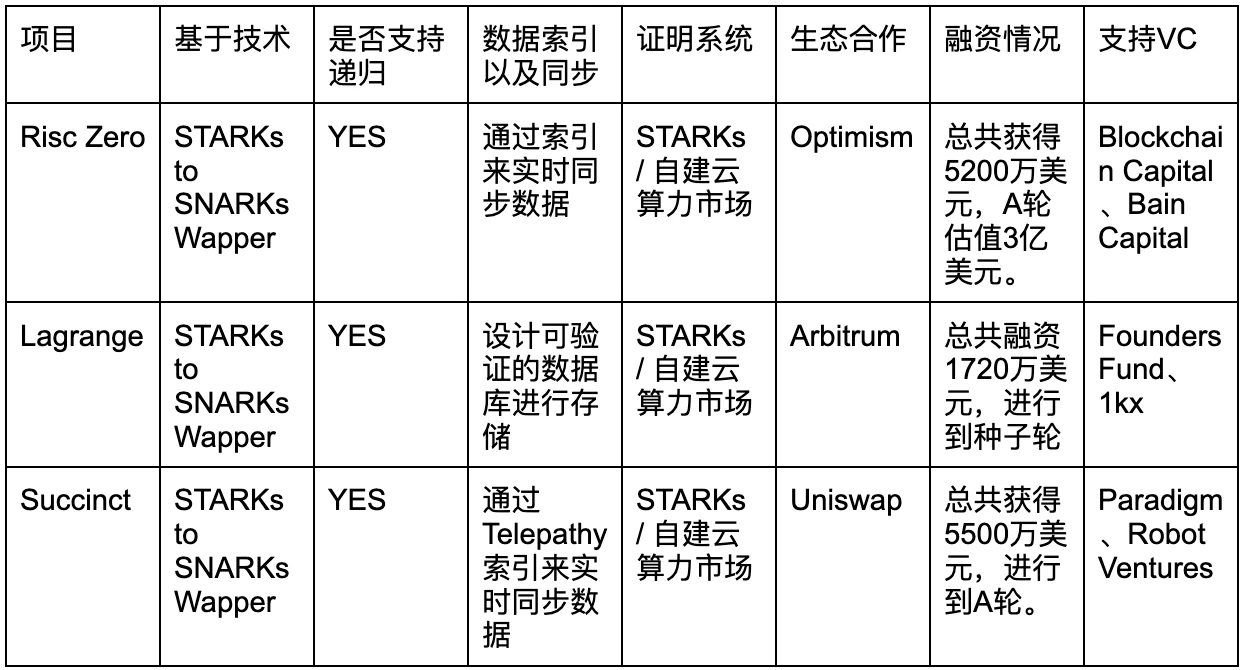
In fact, the overall technical path is already very clear, so most of the technologies are converging. For example, they all use STARKs to SNARKs wrappers, which can use the advantages of STARKs and SNARKs at the same time, reduce the proof generation time and verification time, and resist quantum attacks. Since the recursiveness of the ZK algorithm can greatly affect the performance of ZK, all three projects currently have recursive functions. The proof generation of the ZK algorithm is the most costly and time-consuming, so all three projects rely on their own strong demand for ZK computing power to build a prover network and cloud computing market. In view of this, with the current technical paths being very similar, it may be more necessary for the team and the VC behind it to assist in ecological cooperation resources in order to occupy market share.
Similarities and Differences between Coprocessors and Layer 2
Unlike Layer 2, coprocessors are application-oriented, while Layer 2 is still user-oriented. Coprocessors can be used as an acceleration component or a modular component to form the following application scenarios:
As the off-chain virtual machine component of ZK Layer 2, these Layer 2s can replace their own VMs with coprocessors.
As a co-processor that offloads computing power from public chain applications to the off-chain.
Acts as an oracle for applications on the public chain to obtain verifiable data from other chains.
Acts as a cross-chain bridge between two chains to transmit messages.
These application scenarios are just a partial list. For coprocessors, we need to understand their potential to bring real-time synchronization of data and high-performance, low-cost trusted computing to the entire chain, and to be able to safely reconstruct almost all blockchain middleware through coprocessors. Chainlink and The Graph are currently developing their own ZK oracles and queries; mainstream cross-chain bridges such as Wormhole and Layerzero are also developing cross-chain bridge technology based on ZK; training and trusted reasoning of LLMs (large model predictions) under the chain, etc.
Problems facing coprocessors
There are obstacles for developers to enter. ZK technology is theoretically feasible, but there are still many technical difficulties and it is difficult for outsiders to understand. Therefore, when new developers enter the ecosystem, they may face a greater obstacle because they need to master specific languages and developer tools.
The track is in its very early stages. The performance of zkVM is very complex and involves multiple dimensions (including hardware, single-node and multi-node performance, memory usage, recursion cost, hash function selection and other factors). Currently, there are projects being built in all dimensions. The track is in its very early stages and the landscape is still unclear.
Prerequisites such as hardware have not yet been implemented. From the hardware perspective, the current mainstream hardware is built in the form of ASIC and FPGA. Manufacturers include Ingonyama, Cysic, etc., which are still in the laboratory stage and have not yet been commercialized. We believe that hardware is a prerequisite for the large-scale implementation of ZK technology.
The technical paths are similar, and it is difficult to have a technological lead across generations. Currently, the main competition is based on the VC resources behind and the BD capabilities of the team, and whether they can seize the ecological niche of mainstream applications and public chains.
Summary and Outlook
ZK technology is extremely versatile and has helped the Ethereum ecosystem move from a decentralized value orientation to a trustless value orientation. Dont Trust, Verify it, this sentence is the best practice of ZK technology. ZK technology can reconstruct a series of application scenarios such as cross-chain bridges, oracles, on-chain queries, off-chain computing, virtual machines, etc., and the general-purpose ZK Coprocessor is one of the tools to implement ZK technology. For ZK Coporcessor, its application boundaries are so wide that any real dapp application scenario can be covered. In theory, anything that Web2 applications can do can be achieved with ZK coprocessors.
Technology Popularization Curve, Source: Gartner
Since ancient times, the development of technology has lagged behind human imagination of a better life (such as Change flying to the moon to Apollo setting foot on the moon). If something is truly innovative, subversive and necessary, then technology will definitely be realized, it is just a matter of time. We believe that the general ZK coprocessor follows this development trend. We have two indicators for the ZK coprocessor Mass Adoption: a real-time provable database for the entire chain and low-cost off-chain computing. If the amount of data is sufficient and real-time synchronization is combined with low-cost off-chain verifiable computing, then the software development paradigm can be completely changed, but this goal is slowly iterated, so we focus on finding projects that meet these two trends or value orientations, and the landing of ZK computing chips is the prerequisite for the large-scale commercial application of ZK coprocessors. This round of cycle lacks innovation, and it is a window period for truly building the next generation of Mass Adoption technology and applications. We expect that in the next round of cycles, the ZK industry chain can be commercialized, so now is the time to refocus on some technologies that can truly enable Web3 to carry 1 billion people to interact on the chain.
Disclaimer:
The above content is for reference only and should not be regarded as any advice. Please always seek professional advice before making any investment.
About Gate Ventures
Gate Ventures is the venture capital arm of Gate.io, focusing on investments in decentralized infrastructure, ecosystems, and applications that will reshape the world in the Web 3.0 era. Gate Ventures works with global industry leaders to empower teams and startups with innovative thinking and capabilities to redefine social and financial interaction models.
Website: https://ventures.gate.io/ Twitter: https://x.com/gate_ventures Medium: https://medium.com/gate_ventures





