




協處理器歷史背景
在傳統的電腦領域,協處理器是負責為 CPU 大腦處理其它繁雜的事情的處理單元。協處理在電腦領域非常常見,如蘋果在 2013 年推出 M 7 運動協處理器,大幅提升了智慧型裝置的運動方面靈敏度。廣為人知的 GPU 便是 Nvidia 在 2007 年提出的協處理器,負責為 CPU 處理圖形渲染等任務。 GPU 透過卸載一些運算密集且耗時的程式碼部分來加速 CPU 上運行的應用程序,這種架構被稱為「異質」 / “混合”計算。
協處理器能夠卸載一些複雜且單一效能需求或效能要求極高的程式碼,讓 CPU 去處理更靈活多變的部分。
在以太坊鏈上,有兩個嚴重阻礙應用發展的問題:
由於操作需要高昂的Gas Fee,一筆普通的轉帳硬編碼為21000 Gas Limit,這個就展現以太坊網絡的Gas Fee 底線,其它操作包括存儲就會花費更多的Gas,進而就會限制鏈上應用的開發範圍,大多數的合約程式碼僅僅是圍繞資產操作而編寫,一旦涉及到複雜的操作就會需要大量Gas,這對於應用程式和用戶的「Mass Adoption」是嚴重阻礙。
由於智慧合約存在於虛擬機器中,智慧合約實際上只能存取近期的256 個區塊的數據,特別是在明年的Pectra 升級,引入的EIP-4444 提案,全節點將不會再儲存過去的區塊數據,那麼數據的缺失,導致了基於數據的創新應用遲遲無法出現,畢竟類似於Tiktok、Instagram、多數據的Defi 應用、LLM 等都是基於數據來進行構建,這也是為什麼Lens 這種基於數據的社交協議要推出Layer 3 Momoka 的原因,因為我們認為的區塊鏈是數據流向非常順暢的畢竟鏈上都是公開透明的,但是實際上不然,僅僅是代幣資產數據流通順暢,但是數據資產由於底層設施的不完善仍然阻礙很大,這也會嚴重限制「Mass Adoption」產品的出現。
我們透過這一事實,發現其計算和數據都是限制新的計算範式「Mass Adoption」出現的原因。然而這個是以太坊區塊鏈本身的弊病,並且在設計時本就不是為了處理大量計算以及數據密集型任務而設計的。但是想要相容這些運算與資料密集的應用該如何實現?這裡就需要引出協處理器,以太坊鏈本身作為CPU,協處理器就類似於GPU,鏈本身能處理一些非計算、數據密集型的資產數據和簡單操作,而應用想要靈活使用數據或計算資源可以使用協處理器。伴隨著 ZK 技術的探索,為了確保協處理器在鏈下進行運算和資料使用的無需信任,因此自然而然,協處理器大多都在以 ZK 為底層進行研發。
對於ZK Coporcessor,其應用邊界之廣,任何真實的dapp 應用場景均能覆蓋,如社交、遊戲、Defi 積木、基於鏈上數據的風控系統、Oracle、數據存儲、大模型語言訓練推理等等,從理論上來說,任何Web2的應用能做到的事情,有了ZK 協處理器就都能實現,而且還有以太坊來作為最終結算層保護應用安全性。
在傳統的世界中,協處理器也沒有一個明確的定義,只要能作為輔助協助完成任務的單獨晶片都叫協處理器。目前業界對ZK 協處理器的定義並不完全相同,如ZK-Query、ZK-Oracle、ZKM 等都是協處理器,能夠協助查詢鏈上完整資料、鏈下的可信任資料以及鏈下運算結果,從這個定義來看,其實layer 2 也算是以太坊的協處理器,我們也會在下文中比較Layer 2 與通用ZK 協處理器的異同。
協處理器專案一覽
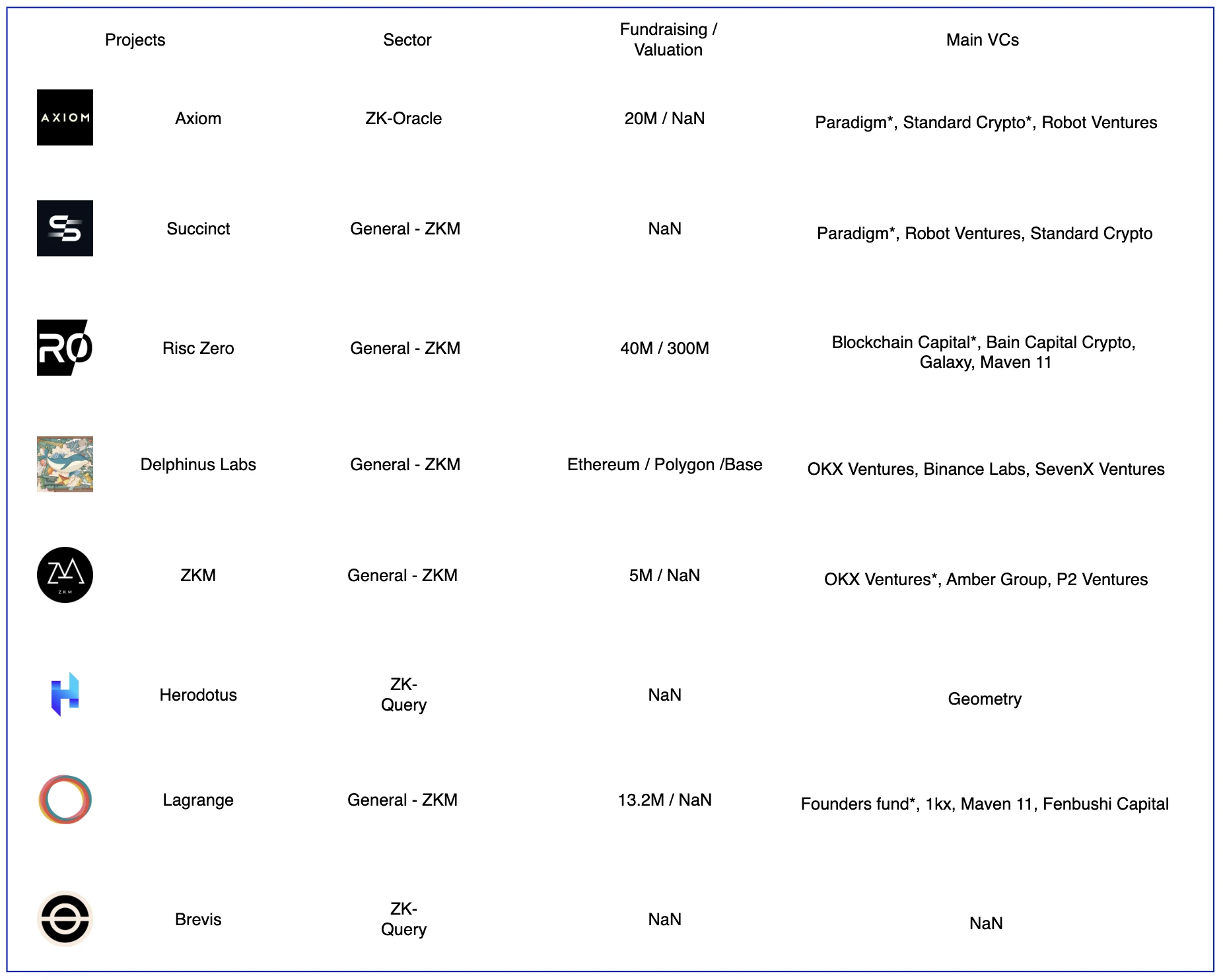
ZK 協處理器部分項目,圖源:Gate Ventures
目前業界較知名的協處理分成三大部分,分別是鏈上資料索引、預言機、ZKML 這三大應用場景,而三種場景都包含的項目為General-ZKM,在鏈下運作的虛擬機又各有不同,如Delphinus 專注於zkWASM,而Risc Zero 專注於Risc-V 架構。
協處理器技術架構
我們以General ZK 協處理器為例,進行其架構的分析,讓讀者明白,該通用型的虛擬機在技術以及機制設計上的異同,來判斷未來協處理器的發展趨勢,其中主要圍繞Risc Zero、Lagrange、Succinct 三個專案進行分析。
Risc Zero
在 Risc Zero 中,其 ZK 協處理器名為 Bonsai。
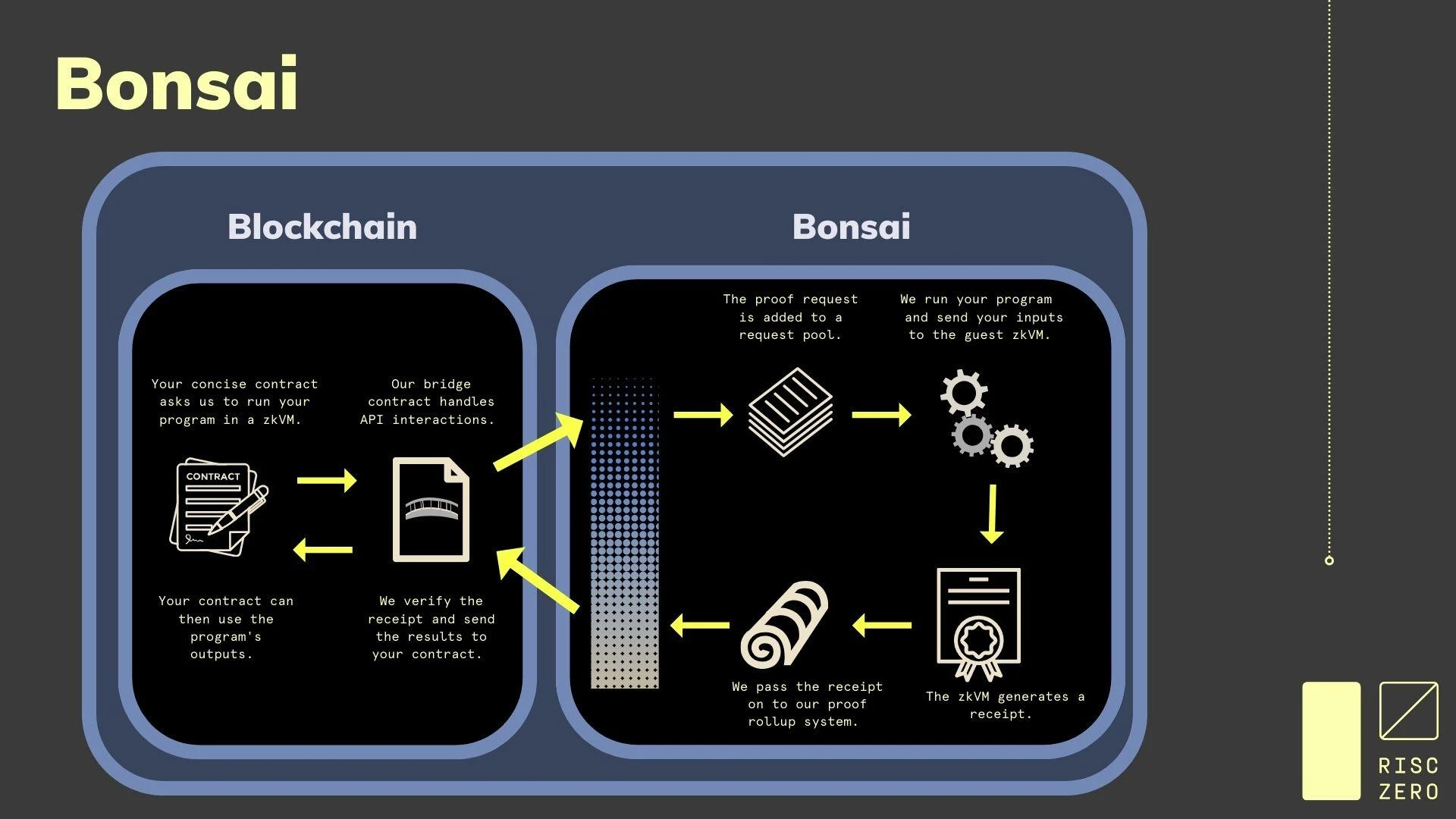
Bonsai 架構,圖源: Risc Zero
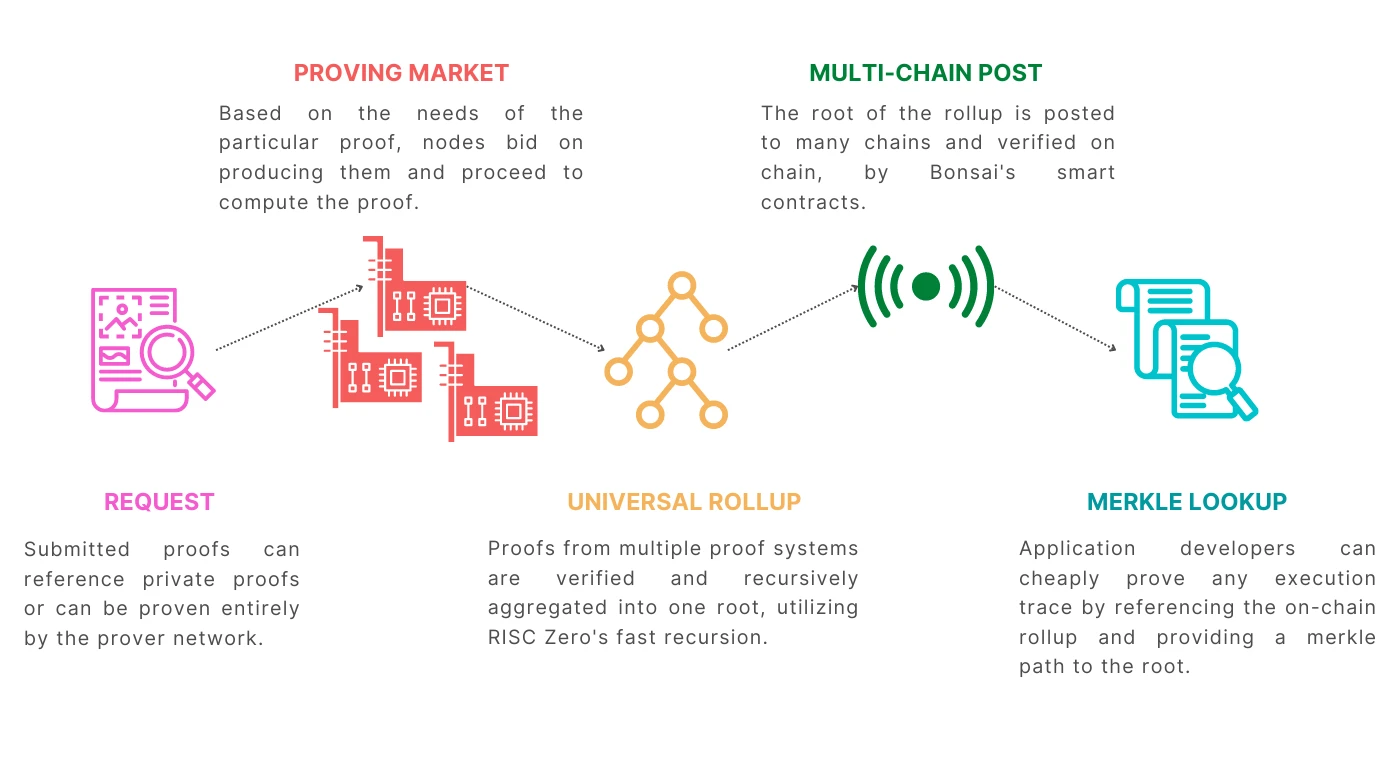
Bonsai 組件,圖源: Risc Zero
在Bonsai 中,建構了一整套的與鏈無關的零知識證明的組件,其目標是成為一個與鏈無關的協處理器,基於Risc-V 指令集架構,具備極大的通用性,支持的語言包括Rust、C++、Solidity、Go 等。其主要的功能包括:
通用zkVM,能夠在零知識/可驗證環境中執行任何虛擬機器。
可直接整合到任何智能合約或鏈中的 ZK 證明生成系統
一個通用的rollup,將Bonsai 上證明的任何計算分發到鏈上,讓網路礦工進行證明生成。
其組件包括:
證明者網路:透過 Bonsai API,證明者在網路中接受到需要驗證的 ZK 程式碼,然後運行證明演算法,產生 ZK 證明,這個網路未來會開放給所有人。
Request Pool:這個池是儲存用戶發起的證明請求的(類似以太坊的mempool,用於暫存交易),然後這個Request Pool 會經過Sequencer 的排序,產生區塊,其中的許多證明請求會被拆分以提高證明效率。
Rollup 引擎:這個引擎會收集證明者網路裡收集到的證明結果,然後打包成 Root Proof,上傳到以太坊主網,以讓鏈上的驗證者隨時驗證。
Image Hub:這個是一個可視化的開發者平台,在這個平台中可以存儲函數以及完整的應用程序,因此開發者可以通過智能合約調用對應的API,因此鏈上智能合約就具備了調用鏈下程序的能力。
State Store:Bonsai 也引入了鏈下的狀態存儲,在資料庫中以鍵值對的形式存儲,這樣就能夠減少鏈上的存儲費用,並且與 ImageHub 平台配合,能減少智能合約的複雜性。
Proving Marketplace: ZK 證明產業鏈的中上游,算力市場用於匹配算力的供需雙方。
Lagrange
Lagrange 的目標是建立一個協處理器和可驗證的資料庫,其中包括了區塊鏈上的歷史數據,可以順暢的使用這些數據來進行無需信任的應用建立。這就能滿足運算和資料密集型應用的開發。
這涉及到兩個功能:
可驗證資料庫:透過索引鏈上智慧合約的 Storage,將智慧合約產生鏈上狀態放入資料庫中。本質上就是重新建構區塊鏈的儲存、狀態和區塊,然後以一種更新的方式儲存在便於檢索的鏈下資料庫中。
MapReduce 原則的計算:MapReduce 原則就是在大型資料庫上,採用資料分離多實例並行計算,最後將結果整合在一起。而這種支援並行執行的架構被 Lagrange 稱為 zkMR。
在資料庫的設計中,其一共涉及鏈上資料的三個部分,分別為合約儲存的資料、EOA 狀態資料以及區塊資料。
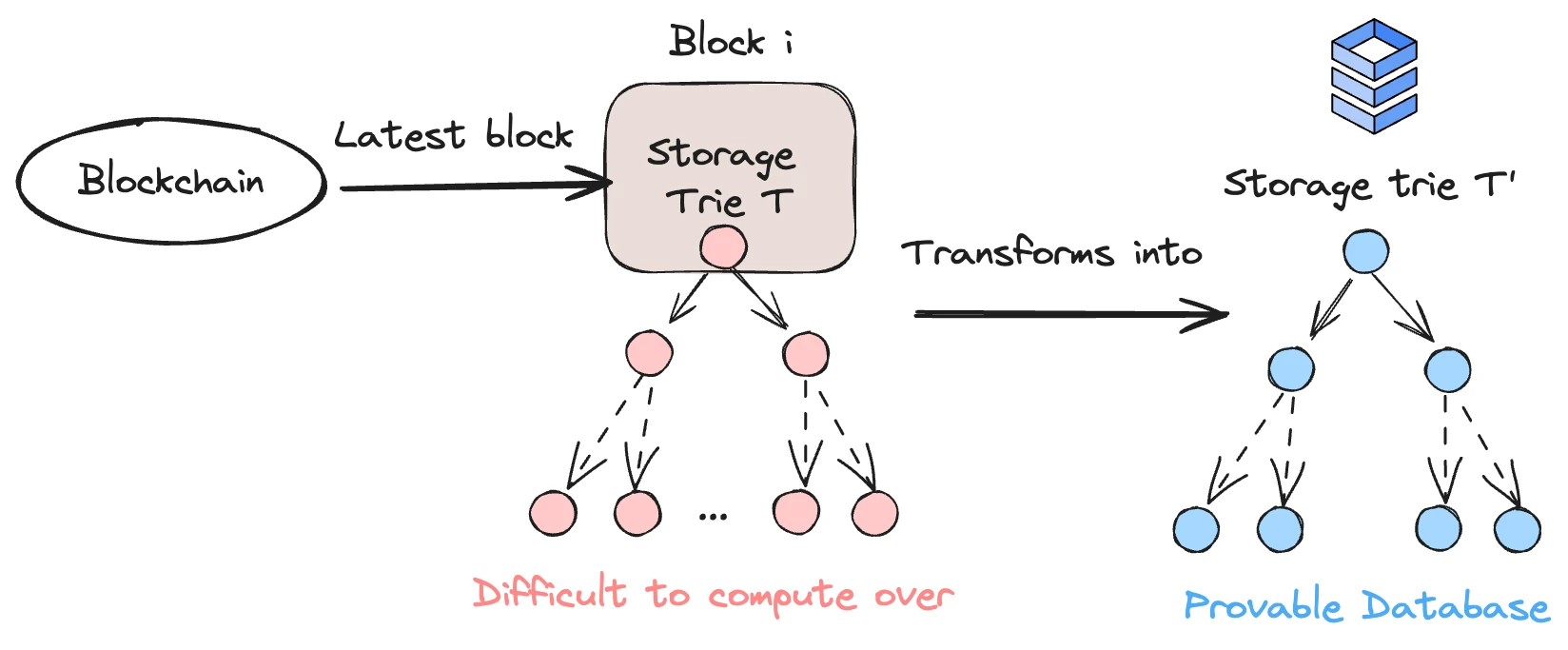
Lagrange 資料庫結構,圖源: Lagrange
以上是其合約儲存的資料的映射結構,在這裡儲存了合約的狀態變量,並且每個合約都有一個獨立的 Storage Trie,這個 Trie 在以太坊內是以 MPT 樹的形式儲存。 MPT 樹雖然簡單,但效率很低,這也是為什麼以太坊核心開發者推動 Verkel 樹開發的原因。在 Lagrange 內,每個節點都能使用 SNARK/STARK 進行“證明”,而父節點又包含了子節點的證明,這其中需要使用遞歸證明的技術。
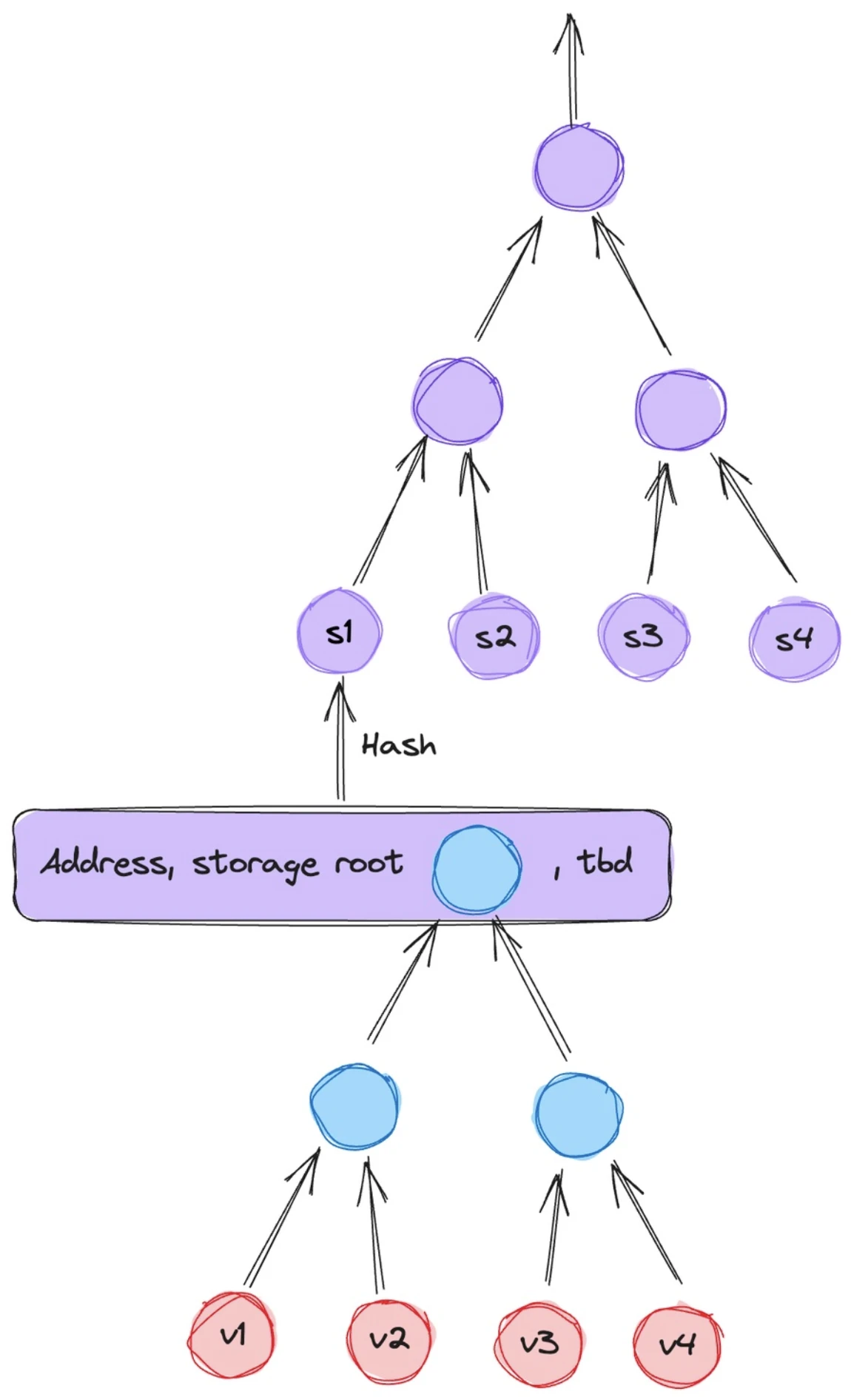
帳戶狀態,圖片來源: Lagrange
帳戶分別為EOA 和合約帳戶,都可以以帳戶/ Storage Root(合約變數的儲存空間)的形式儲存來代表帳戶狀態,但是似乎Lagrange 並沒有完全設計好這一部分,實際上還需要加上State Trie(外部帳戶的狀態儲存空間)的根。
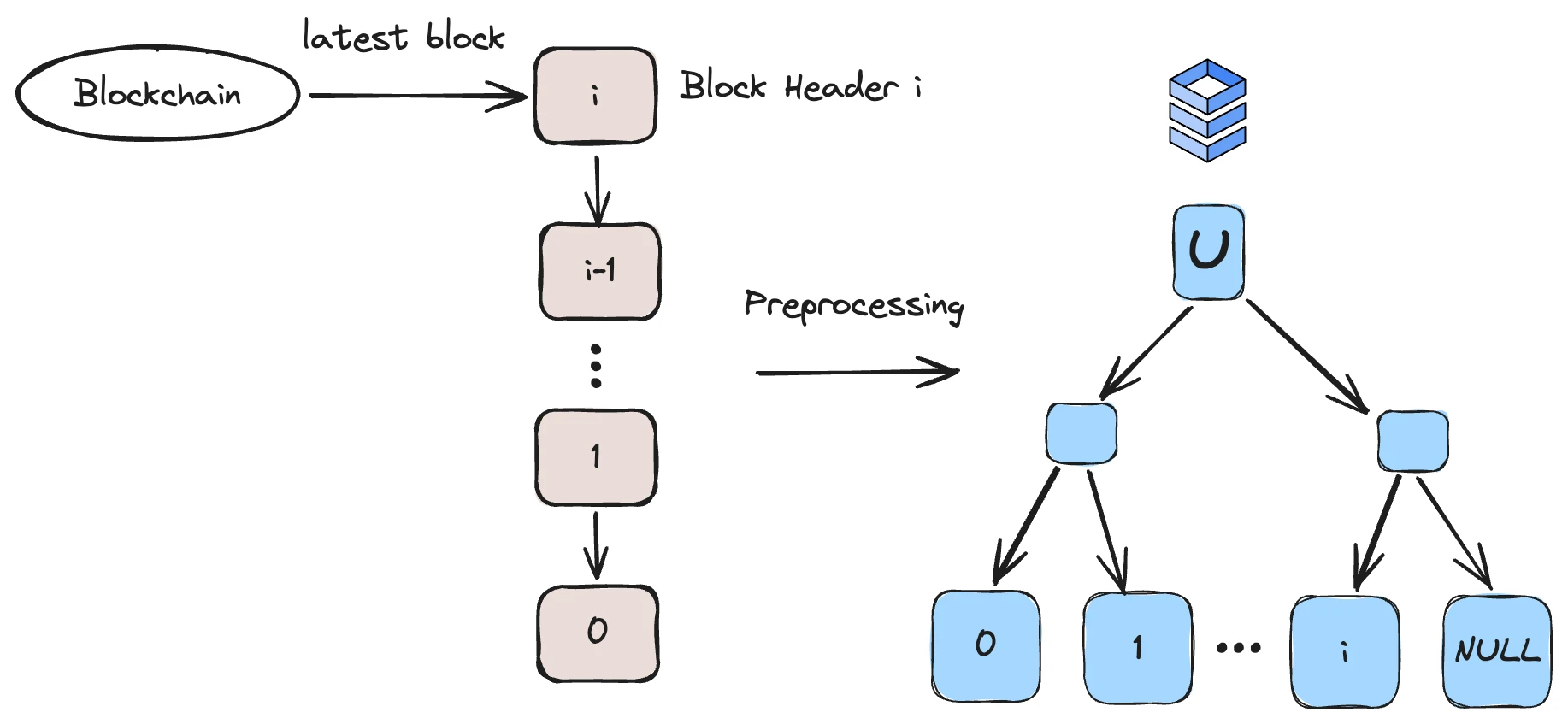
區塊資料結構,圖源: Lagrange
Lagrange 在新的資料結構中,創建了對於SNARKs 證明友好的區塊資料結構,這顆樹的每個葉子都是一個區塊頭,這個數的大小是固定的,如果以太坊12 秒出塊一次,那麼這個資料庫大約可以使用25 年。
在 Lagrange 的 ZKMR 虛擬機器中,其計算有兩個步驟:
Map:分散式的機器對一整個資料進行映射,產生鍵值對。
Reduce:分散式計算機分別計算證明,之後將證明全部合併。
簡而言之,ZKMR 可以將較小計算的證明組合起來以創建整個計算的證明。這使得ZKMR 能夠有效地擴展,以在需要多個步驟或多層計算的大型資料集上進行複雜的計算證明。例如,如果Uniswap 在100 條鏈上部署,那麼如果想要計算100 條鏈上的某個代幣的TWAP 價格,就需要大量的計算以及整合,這個時候ZKMR 就能夠分別計算每條鏈,然後組合起來一個完整計算證明。
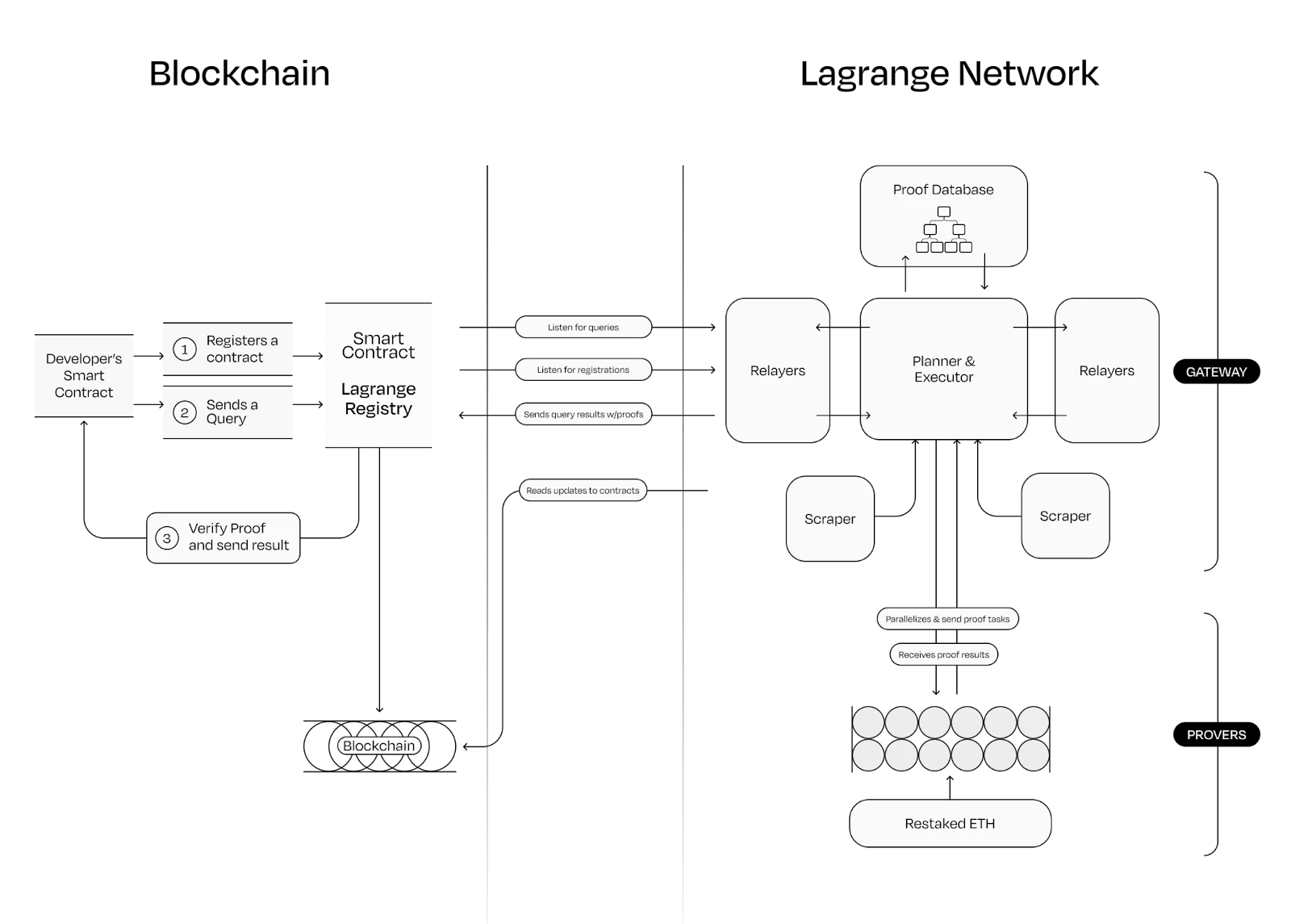
Lagrange 協處理器運作流程,圖源: Lagrange
以上是其執行流程:
開發者的智能合約,首先在 Lagrange 上註冊,然後向 Lagrange 的鏈上智能合約提交一個證明請求,這時,代理合約負責與開發者合約互動。
鏈下的 Lagrange 透過將請求分解為可並行的小任務並分發給不同的證明器來共同驗證。
該證明者實際上也是一個網絡,其網路的安全性由 EigenLayer 的 Restaking 技術保障。
Succinct
Succinct Network 的目標是將可編程事實整合到區塊鏈開發 Stack 的每個部分(包括L2、協處理器、跨鏈橋等)。
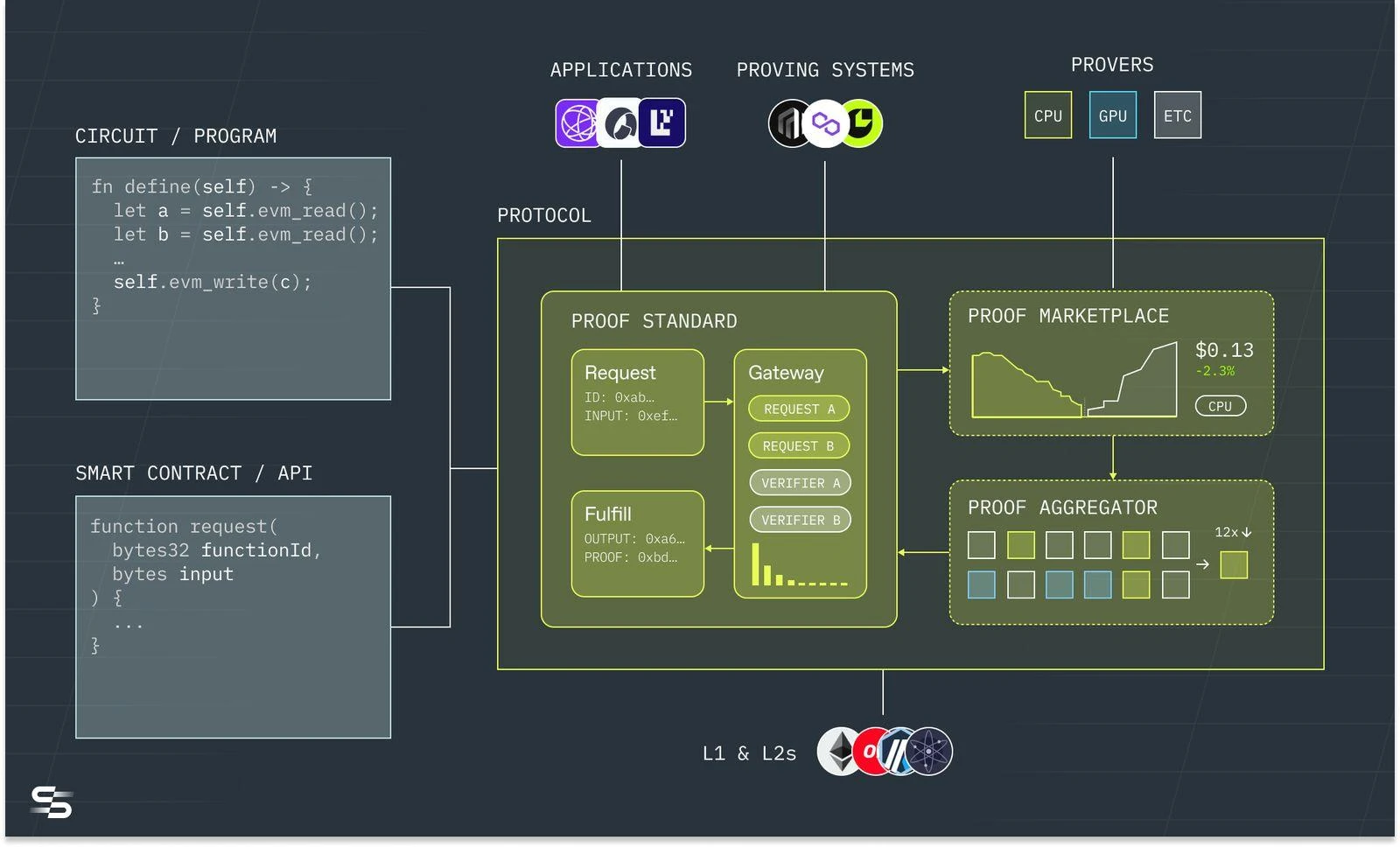
Succinct 運作流程,圖源: Succinct
Succinct 可以接受包括Solidity 和零知識領域的專門語言(DSL)等程式碼,傳入到鏈下的Succinct 協處理器,Succinct 完成目標鏈的資料索引,然後將證明申請發送給證明市場,能夠支援CPU、 GPU 以及ETC 等晶片的礦機在證明網路中提交證明。其特點在於證明市場對於各種證明系統都相容,因為未來會有很長一段各種證明系統並存的時期。
Succinct 的鏈下 ZKVM 稱為 SP(Succinct Processor),其能夠支援 Rust 語言以及其它的 LLVM 語言,其核心特性包括:
遞歸+驗證:基於 STARKs 技術的遞歸證明技術,能夠指數級增強 ZK 壓縮效率。
支援 SNARKs 到 STARKs 包裝器:能夠同時採納 SNARKs 和 STARKs 優點,解決證明大小和驗證時間的權衡問題。
預先編譯為中心的zkVM 架構:對於一些常見的演算法如 SHA 256、Keccak、ECDSA 等,能夠事先編譯以減少執行時間的證明產生時間和驗證時間。
比較
在進行通用 ZK 協處理器的比較時,我們主要以滿足 Mass Adoption 第一原理來進行比較,我們也會闡述為什麼很重要:
資料索引/同步問題:只有完整的鏈上資料以及同步索引功能才能滿足基於大數據的應用的要求,否則其應用範圍較為單一。
基於技術:SNARKs 與 STARKs 技術有不同的抉擇點,中期以 SNARKs 技術為主,長期以 STARKs 技術為主。
是否支援遞歸:只有支援遞歸才能更大程度的壓縮資料以及實現計算的並行證明,因此實現完全的遞歸是專案的技術亮點。
證明系統:證明系統直接影響了證明生成的大小、時間,這個是 ZK 技術中成本最高的地方,目前都是以自建 ZK 雲端算力市場和證明網路為主。
生態合作:能夠透過第三真實需求方來判斷其技術方向是否被 B 端使用者認可。
支援的 VC 以及融資情況:可能能夠表示其後續的資源支援情況。
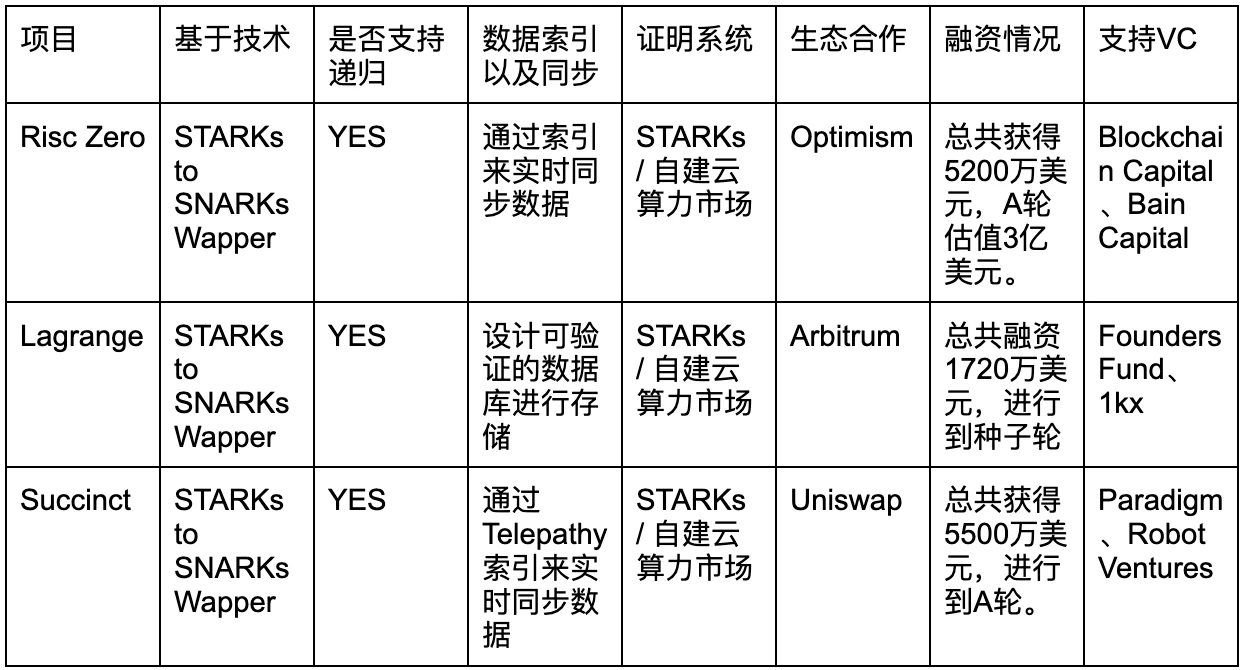
其實整體的技術路徑已經很明晰,因此大多數的技術都趨同,例如都使用 STARKs 到 SNARKs 的包裝器,能夠同時使用 STARKs 和 SNARKs 的優點,降低證明生成時間和驗證時間以及抗量子攻擊。由於 ZK 演算法的遞歸性能夠很大程度影響 ZK 的效能,目前三個項目都有遞歸功能。 ZK 演算法的證明產生是成本和時間耗費最多的地方,因此三個專案的都依賴於本身對 ZK 算力的強需求來建構了證明者網路和雲端算力市場。也有鑑於此,目前技術路徑非常相似的情況下,可能突圍更需要團隊以及背後的 VC 對於生態合作資源方面的協助以佔據市場份額。
協處理器與 Layer 2 的異同
與 Layer 2 不同的是,協處理器是面向應用的,而 Layer 2 仍然是面向使用者的。協處理器能作為加速組件或模組化的元件,構成以下幾種應用場景:
作為 ZK Layer 2 的鏈下虛擬機器元件,這些 Layer 2 可以將自己的 VM 換成協處理器。
作為公鏈上應用卸載算力到鏈下的協處理器。
作為公鏈上應用獲取其它鏈可驗證資料的預言機。
作為兩條鏈上的跨鏈橋進行訊息的傳遞。
這些應用場景只是羅列了一部分,對於協處理器,我們需要理解其帶來了全鏈的即時同步資料與高效能低成本可信任運算的潛力,能夠透過協處理器安全地重建幾乎區塊鏈的所有中間件。包括Chainlink、The Graph 目前也在開發自己的ZK 預言機和查詢;而主流的跨鏈橋如Wormhole、Layerzero 等也在研發基於ZK 的跨鏈橋技術;鏈下的LLMs(大模型預言)的訓練以及可信推理、等等。
協處理器面臨的問題
開發者進入有阻力,ZK 技術從理論上可行,但是目前技術難點仍然有很多,外部理解也晦澀難懂,因此當新的開發者進入到生態中時,由於需要掌握特定的語言與開發者工具,可能是一個較大的阻力。
賽道處於極早期,zkVM 效能非常複雜且涉及多個維度(包括硬體、單節點與多節點效能、記憶體使用、遞歸成本、雜湊函數選擇等因素),目前各個緯度都有在建構的項目,賽道處於非常早期,格局還不明朗。
硬體等先決條件仍未落地,從硬體來看,目前主流的硬體是ASIC 以及FPGA 方式構建,廠商包括Ingonyama、Cysic 等,也仍處於實驗室階段,仍未商業化落地,我們認為硬體是ZK 技術大規模落地前提。
技術路徑相似,很難有技術上的隔代領先,目前主要比拼背後的 VC 資源以及團隊 BD 能力,是否能拿下主流應用和公鏈的生態位。
總結與展望
ZK 技術具備極大通用性,也幫助以太坊生態從去中心化的價值取向走向了去信任化的價值。 “ Dont Trust, Verify it“,這句話是 ZK 技術的最佳實踐。 ZK 技術能夠重構跨鏈橋、預言機、鏈上查詢、鏈下運算、虛擬機器等等一系列應用場景,而通用型的 ZK Coprocessor 就是實現 ZK 技術落地的工具之一。對於 ZK Coporcessor,其應用邊界之廣,任何真實的 dapp 應用場景均能覆蓋,從理論上來說,任何Web2的應用能做到的事情,有了 ZK 協處理器就都能實現。
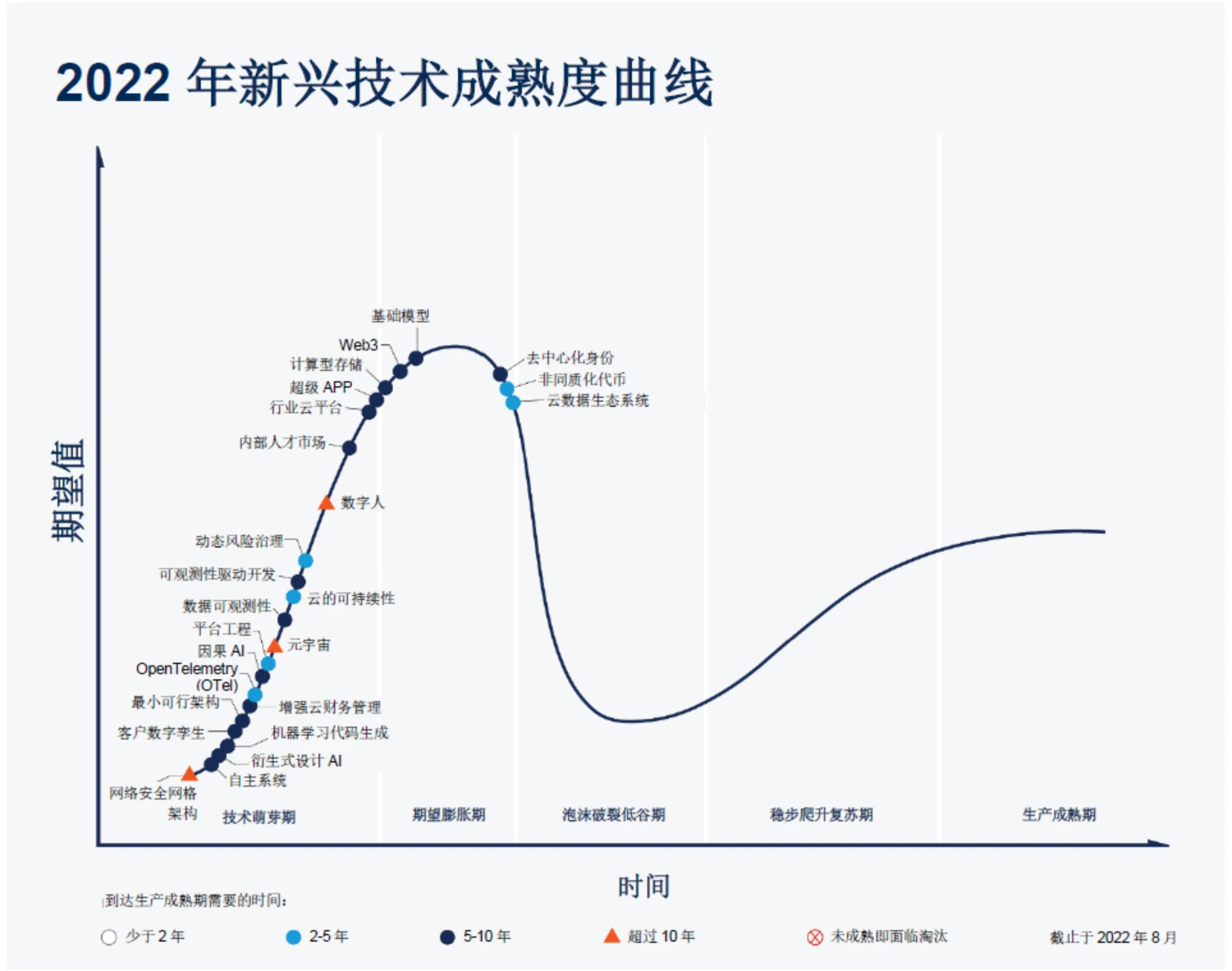
科技普及曲線,圖源: Gartner
自古以來,科技的發展都落後於人類對美好生活的想像(比如嫦娥奔月到阿波羅踏上月球),如果一個東西確實有創新性和顛覆性以及必要性,那麼技術一定會實現,只是時間問題。我們認為通用 ZK 協處理器遵循這一發展趨勢。我們對於 ZK 協處理器「Mass Adoption」有兩個指標:全鏈的即時可證明資料庫以及低成本鏈下計算。如果資料量足夠且即時同步加上低成本的鏈下可驗證計算,那麼軟體的開發範式便能夠徹底改變,但是這一目標是緩慢迭代的,因此我們著重去尋找符合這兩點趨勢或者價值取向的項目,而ZK 算力晶片的落地是ZK 協處理器大規模商業化應用的前提,本輪週期缺乏創新,是真正構建下一代“Mass Adoption”技術和應用的窗口期,我們預計在下一輪週期中,ZK 產業鏈能夠商業化落地,因此現在正是將目光重新放在一些真正能讓Web3承載10 億人鏈上互動的技術上面。
免責聲明:
以上內容僅供參考,不應被視為任何建議。在進行投資之前,請務必尋求專業建議。
關於Gate Ventures
Gate Ventures是Gate.io 旗下的創投部門,專注於對去中心化基礎設施、生態系統和應用程式的投資,這些技術將在Web 3.0 時代重塑世界。 Gate Ventures與全球產業領袖合作,賦予那些擁有創新思維和能力的團隊和新創公司,重新定義社會和金融的互動模式。
官方網站: https://ventures.gate.io/ Twitter: https://x.com/gate_ventures Medium: https://medium.com/gate_ventures





