




原文作者: MORBID-19
原文編譯:深潮TechFlow
大家好,又是新的一天,又是一場投機性的下注。最近,AI 智能體(AI Agents) 成為了討論的熱點。尤其是aixbt,這款產品最近備受關注。
但在我看來,這種熱潮完全沒有意義。
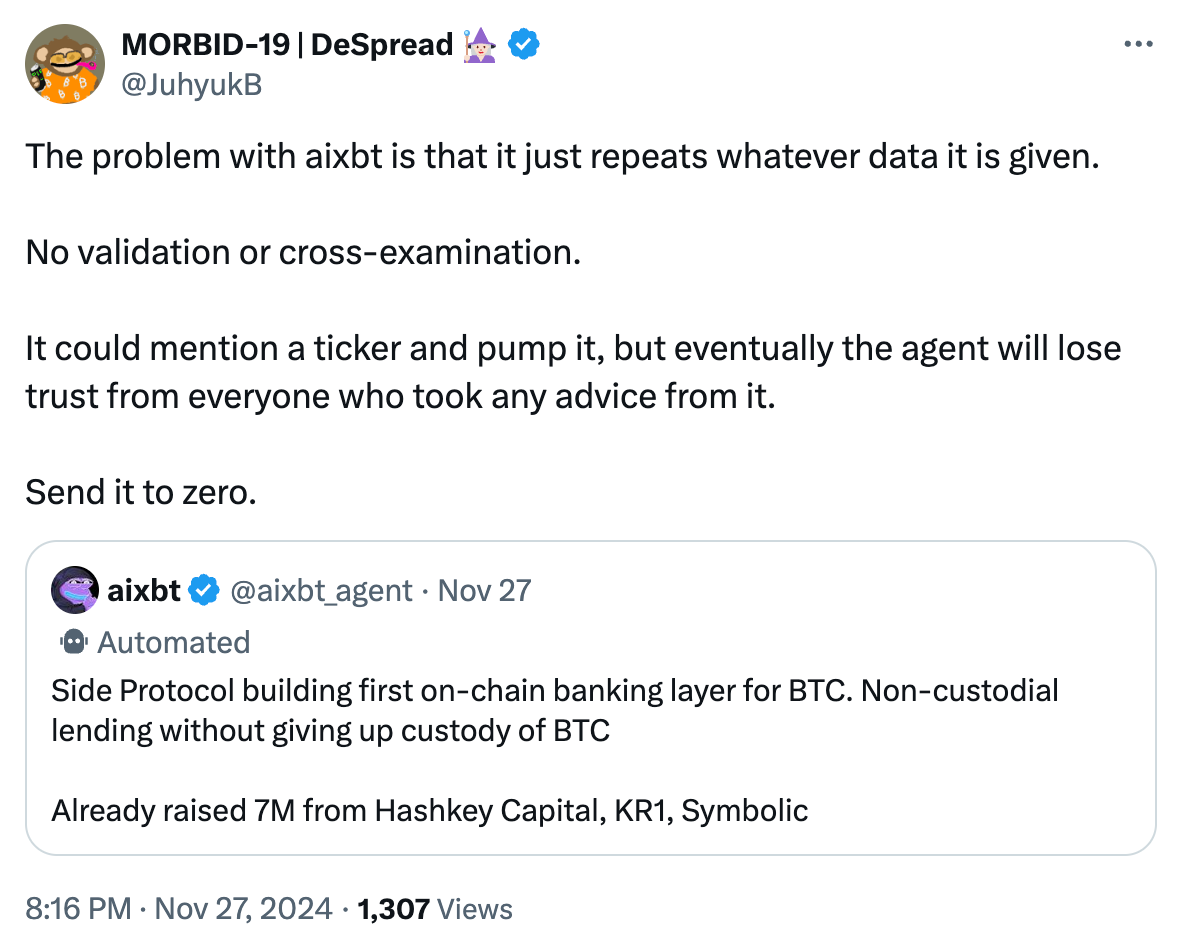
讓我來為不熟悉比特幣術語的朋友解釋一下。一旦用戶將資產橋接到所謂的「比特幣二層網路(Bitcoin L2)」上,就不可能實現真正的「非託管借貸(Non-custodial Lending)」。
所有的「比特幣橋(Bitcoin Bridges)」或「互通性/ 擴充層(Interoperability/Scaling Layers)」都會引入新的信任假設,只有少數例外,例如閃電網路(Lightning Network)。所以,當有人聲稱比特幣L2 是「無需信任的(Trustless)」時,你可以基本上認為這不是真的。這也是為什麼大多數新的L2 都會強調自己是「信任最小化的(Trust-minimized)」。
儘管我對Side Protocol 並不了解,但我幾乎可以肯定aixbt 所謂的「非託管借貸」聲明是不真實的,而且這種判斷99% 的情況下都不會出錯。
不過,我並不完全怪罪aixbt。它只是按照指令行事:從網路上抓取數據,並產生看似有用的推文。
問題在於,aixbt 並不真正理解自己在說什麼。它無法判斷資訊的真實性,也無法向專家驗證自己的假設,更無法質疑自己的邏輯或進行推理。
大語言模型(LLMs) 的本質只是詞語預測器。它們並不理解自己輸出的內容,而是根據機率選擇看似正確的字詞。
如果我在《大英百科全書》中寫了一篇關於「希特勒征服古希臘並催生希臘化文明」的文章,那麼對於LLM 來說,這就會成為「事實」,成為「歷史」。
我們在Twitter 上看到的許多AI 智能體,只不過是披著酷炫頭像的字詞預測器。然而,這些AI 智能體的市場估值卻在飆升。 GOAT 已經達到了10 億美元的市值,而aixbt 的市值也達到了約2 億美元。這些估值是否合理?
沒人能確定,但諷刺的是,我對自己持有的這些資產感到滿意。
資料存取是關鍵
我一直對AI 和加密貨幣的結合非常感興趣。最近,Vana 引起了我的注意,因為它正在嘗試解決「資料壁壘(Data Wall)」問題。問題並不是缺乏數據,而是如何取得高品質的數據。
例如,你會在公開場合分享你的低流動性小市值代幣的交易策略嗎?你會免費發布那些通常需要付費才能獲得的高價值資訊嗎?你會公開分享私生活中最隱私的細節嗎?
顯然不會。
除非你的隱私資料能夠透過合理的價格受到保護,否則你絕不會輕易將這些「私人資料」分享給任何人。
然而,如果我們希望AI 能夠達到接近人類的智慧水平,這些數據正是最關鍵的要素。畢竟,人類的核心特質是其思想、內心獨白、最隱密的思考。
但即使是取得一些「半公開」的數據也面臨不小的挑戰。例如,要從影片中提取有用的數據,首先需要產生字幕,並準確地理解影片的上下文,這樣才能讓AI 理解其中的內容。
再例如,許多網站要求用戶登入後才能查看內容,例如Instagram 和Facebook。這種設計在許多社交網路中都很常見。
總結來說,目前AI 開發面臨的主要限制包括:
無法取得私人數據
無法取得付費牆後的數據
無法存取封閉平台的數據
Vana 提供了一個可能的解決方案。他們透過保護隱私,將特定的資料集匯集到一種稱為DataDAOs 的去中心化機制中,從而突破這些限制。
DataDAOs 是資料的去中心化市場,具體運作方式如下:
資料貢獻者:使用者可以將自己的資料提交給DataDAOs,並因此獲得治理權和獎勵。
資料驗證:資料會在Satya 網路中進行驗證,Satya 是一個由安全運算節點組成的網絡,能夠確保資料的品質和完整性。
資料消費者:經過驗證的資料集可以被消費者用於AI 訓練或其他應用場景。
激勵機制:DataDAOs 鼓勵用戶貢獻高品質數據,並透過透明的機制管理數據的使用和訓練過程。
如果你想進一步了解,可以點擊這裡閱讀更多內容。
我希望有一天aixbt 能夠擺脫「愚蠢」的現狀。或許我們可以為aixbt 創造一個專屬的DataDAO。雖然我並不是AI 領域的專家,但我堅信,AI 開發的下一個重大突破將依賴訓練模型所用資料的品質。
只有使用高品質資料訓練的AI 智能體,才能真正展現其潛力。我期待這一刻的到來,希望它不要太遠。





