





소개
최근 AI 산업의 발전을 4차 산업혁명으로 보는 이들도 있다. 대형 모델의 등장으로 미국에서는 GPT가 업무 효율성을 크게 높였다고 보스턴컨설팅그룹(Boston Consulting Group)은 전했다. 약 20% 정도. 동시에 대형 모델이 가져온 일반화 능력은 새로운 소프트웨어 설계 패러다임으로 환영받았습니다. 과거에는 소프트웨어 설계가 정밀한 코드에 관한 것이었지만 이제 소프트웨어 설계는 소프트웨어에 내장된 보다 일반화된 대형 모델 프레임워크에 관한 것입니다. 더 넓은 범위의 모달 입력 및 출력을 더 잘 표현하고 지원할 수 있습니다. 딥러닝 기술은 그야말로 AI 산업에 제4의 붐을 가져왔고, 이러한 추세는 암호화폐 산업에도 확산됐다.
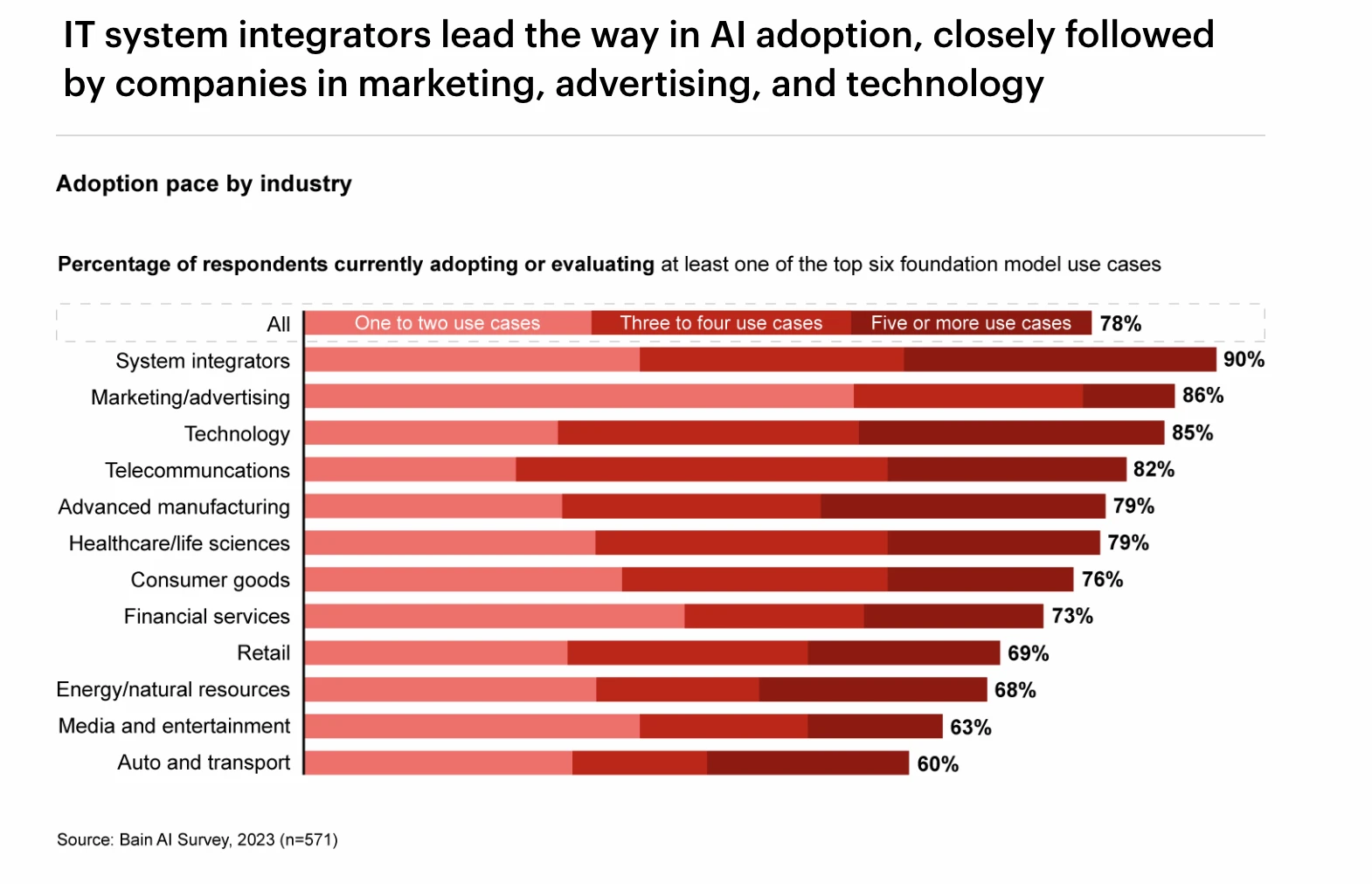
다양한 산업 분야의 GPT 도입률 순위, 출처: Bain AI Survey
본 보고서에서는 AI 산업의 발전 역사, 기술 분류, 딥러닝 기술의 발명이 산업에 미치는 영향을 자세히 살펴보겠습니다. 그런 다음 딥러닝 분야의 GPU, 클라우드 컴퓨팅, 데이터 소스, 엣지 디바이스 등 산업 체인의 업스트림과 다운스트림, 그리고 이들의 개발 현황과 동향을 심층 분석합니다. 이후, 본질적으로 Crypto와 AI 산업의 관계에 대해 자세히 논의하고 Crypto 관련 AI 산업 체인의 패턴을 정리했습니다.
AI 산업의 발전 역사
AI 산업은 1950년대부터 인공지능 비전을 실현하기 위해 학계와 산업계에서 다양한 시대와 학문적 배경을 바탕으로 인공지능을 실현하기 위한 많은 학파를 발전시켜 왔다.
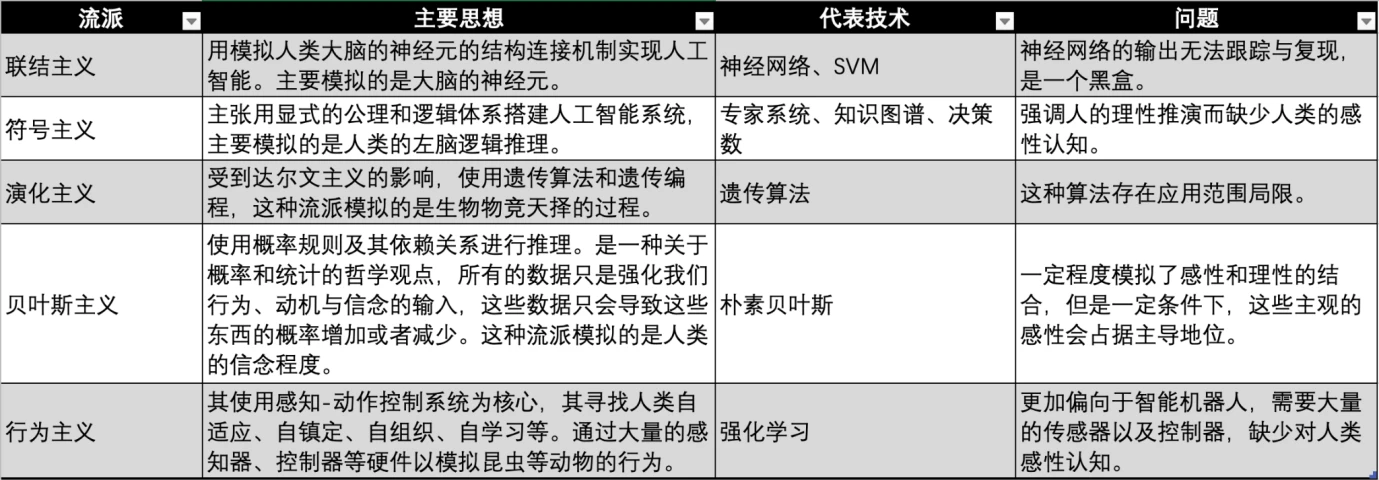
AI 장르 비교, 출처: Gate Ventures
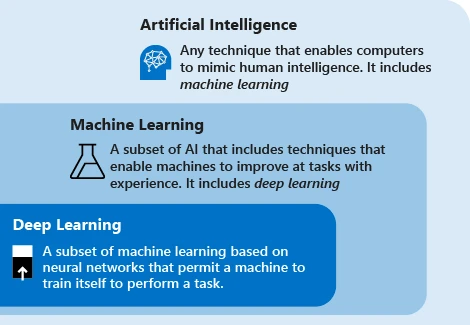
AI/ML/DL 관계, 출처: Microsoft
현대 인공 지능 기술은 주로 머신 러닝이라는 용어를 사용합니다. 이 기술의 아이디어는 기계가 데이터에 의존하여 작업을 반복하여 시스템 성능을 향상시키는 것입니다. 주요 단계는 데이터를 알고리즘에 공급하고, 이 데이터를 사용하여 모델을 훈련하고, 모델을 테스트 및 배포하고, 모델을 사용하여 자동화된 예측 작업을 완료하는 것입니다.
현재 기계 학습에는 세 가지 주요 학교, 즉 연결주의, 상징주의, 행동주의가 있으며 각각 인간의 신경계, 사고 및 행동을 모방합니다.
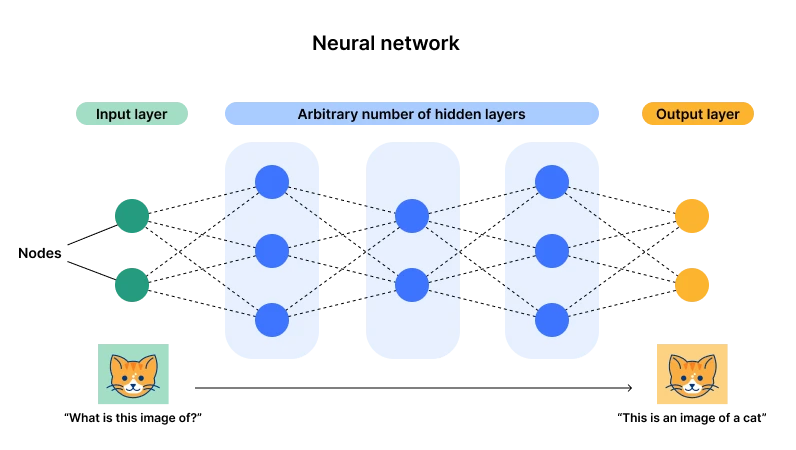
신경망 아키텍처 다이어그램, 출처: Cloudflare
현재는 신경망으로 대표되는 연결주의(딥러닝이라고도 함)가 우세합니다. 주된 이유는 이 아키텍처가 입력 레이어와 출력 레이어를 가지지만 일단 레이어와 뉴런의 수에 따라 여러 개의 은닉 레이어를 갖기 때문입니다. 매개변수) )가 충분히 커지면 복잡한 범용 작업에 적합한 충분한 기회가 있습니다. 데이터 입력을 통해 뉴런의 매개변수는 지속적으로 조정될 수 있으며, 이후 여러 데이터를 경험한 후 뉴런은 최적의 상태(매개변수)에 도달하게 됩니다. 이것이 바로 우리가 기적이라고 부르는 것이기도 합니다. 깊이라는 단어 - 충분한 레이어와 뉴런.
예를 들어, X= 2, Y= 3, X= 3, Y= 5를 입력하면 함수가 구성된다고 간단히 이해할 수 있습니다. 이 함수가 모든 X를 처리하려면 계속해서 추가해야 합니다. 이 함수와 그 매개변수의 정도는 다음과 같습니다. 예를 들어, 이 조건을 충족하는 함수를 Y = 2로 구성할 수 있습니다. 무차별 대입 크래킹을 위해 GPU를 사용하는 데이터 포인트 함수는 Y =라는 것을 발견했습니다. 여기서 X 2와 X, X 0은 모두 서로 다른 뉴런을 나타내며 1, -3, 5는 해당 매개변수입니다.
이때 신경망에 많은 양의 데이터를 입력하면 뉴런을 추가하고 새 데이터에 맞게 매개변수를 반복할 수 있습니다. 이것은 모든 데이터에 적합합니다.
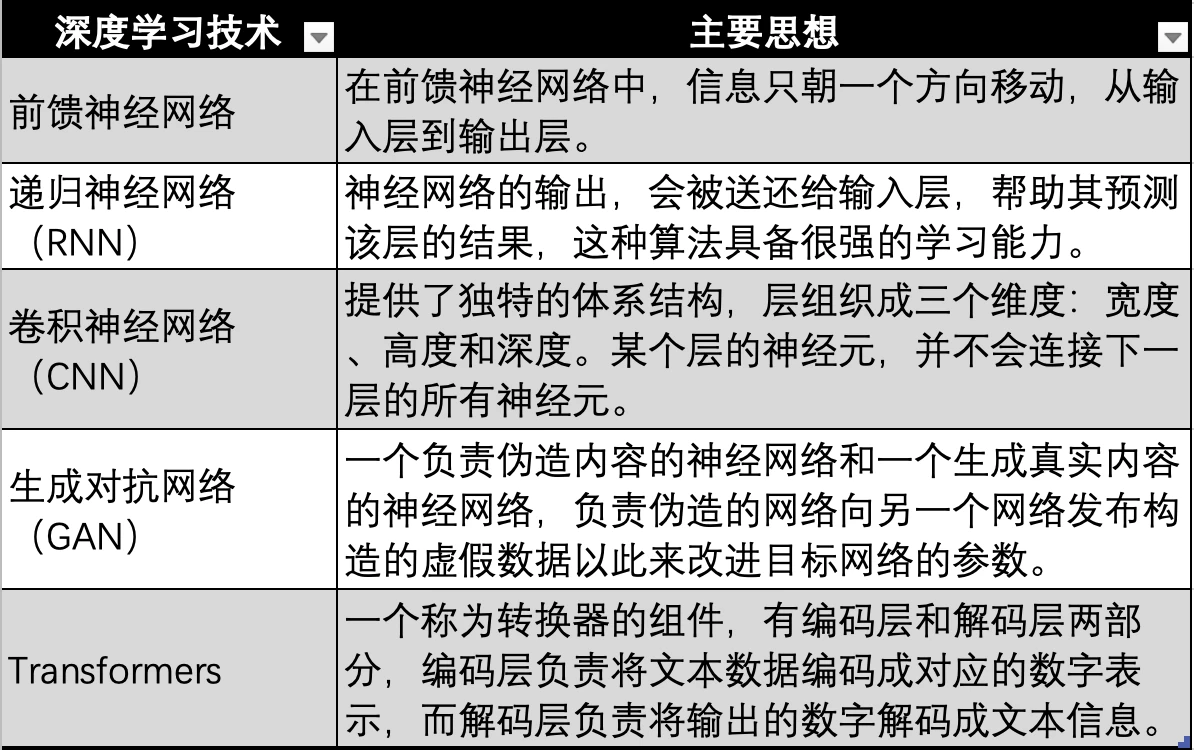
딥러닝 기술의 진화, 출처: Gate Ventures
신경망을 기반으로 한 딥러닝 기술 역시 위 그림의 초기 신경망, 피드포워드 신경망, RNN, CNN, GAN 등 여러 기술적 반복과 진화를 거쳐 마침내 현대 대형 모델에서 사용되는 Transformer 기술로 진화했습니다. GPT, Transformer 기술은 신경망의 진화 방향일 뿐입니다. 이는 모든 형식(예: 오디오, 비디오, 사진 등)의 데이터를 해당 숫자 값으로 인코딩하는 데 사용되는 추가 변환기(Transformer)를 추가하는 것입니다. 그런 다음 신경망에 입력되어 신경망이 모든 유형의 데이터에 적합할 수 있도록, 즉 다중 양식을 달성할 수 있습니다.
인공지능의 발전은 세 가지 기술적 물결을 겪었는데, 첫 번째 물결은 인공지능 기술이 제안된 지 10년 후인 1960년대에 일어났는데, 이 물결은 일반적인 자연어 처리와 인간-기계의 문제를 해결한 상징주의 기술의 발전으로 일어났다. 처리.대화 질문. 이와 동시에 전문가 시스템이 탄생했는데, 이는 NASA의 감독 하에 스탠포드 대학이 완성한 DENRAL 전문가 시스템으로, 이 시스템은 매우 강력한 화학 지식을 갖고 있으며 화학 전문가와 동일한 답변을 생성하기 위해 질문을 추론합니다. 이 시스템은 화학적 지식 기반과 추론 시스템의 조합으로 볼 수 있습니다.
전문가 시스템 이후, 이스라엘계 미국인 과학자이자 철학자인 Judea Pearl은 1990년대에 베이지안 네트워크를 제안했는데, 이는 신념 네트워크라고도 알려져 있습니다. 동시에 브룩스는 행동 기반 로봇공학을 제안하여 행동주의의 탄생을 알렸습니다.
1997년 IBM Deep Blue Blue는 체스 챔피언 Kasparov를 3.5:2.5로 꺾었습니다. 이 승리는 인공 지능의 이정표로 간주되었으며 AI 기술은 발전의 두 번째 정점을 열었습니다.
AI 기술의 세 번째 물결은 2006년에 발생했습니다. 딥러닝의 세 거장 Yann LeCun, Geoffrey Hinton, Yoshua Bengio는 인공 신경망을 프레임워크로 사용하여 데이터 표현을 학습하는 알고리즘인 딥러닝의 개념을 제안했습니다. 이후 딥러닝 알고리즘은 RNN, GAN에서 Transformer, Stable Diffusion으로 점진적으로 진화했으며, 이 두 알고리즘이 함께 제3의 기술 물결을 형성했으며 이는 연결주의의 전성기이기도 했습니다.
딥러닝 기술의 탐구 및 발전과 함께 다음과 같은 많은 획기적인 이벤트가 점차 등장했습니다.
● 2011년 IBM의 Watson은 Jeopardy 퀴즈쇼에서 인간을 물리치고 우승을 차지했습니다.
● 2014년 Goodfellow는 두 개의 신경망이 서로 경쟁하여 학습하여 실제처럼 보이는 사진을 생성하는 GAN(Generative Adversarial Network)을 제안했습니다. 동시에 굿펠로우는 딥러닝 분야의 중요한 입문서 중 하나인 플라워북(Flower Book)이라는 책 딥러닝을 집필하기도 했습니다.
● 2015년 Hinton et al.은 Nature지에 딥러닝 알고리즘을 제안했으며, 이러한 딥러닝 방법의 제안은 학계와 업계에서 즉각적으로 큰 호응을 얻었습니다.
● 2015년 OpenAI가 탄생하고 머스크, YC 알트만 회장, 엔젤 투자자 피터 티엘 등이 10억 달러의 공동 투자를 발표했습니다.
● 2016년 딥러닝 기술을 기반으로 한 알파고는 바둑 세계챔피언이자 바둑 프로 9단 이세돌과 인간-기계 바둑 대결에서 총점 4대 1로 승리했습니다.
● 2017년 중국 홍콩 Hanson Robotics가 개발한 휴머노이드 로봇 Sophia는 역사상 최초로 일류 시민권을 획득한 로봇으로 평가받았습니다.
● 2017년 인공지능 분야에서 풍부한 인재와 기술 보유량을 보유한 구글이 Attention is all you need라는 논문을 발표하고 Transformer 알고리즘을 제안하면서 대규모 언어 모델이 등장하기 시작했습니다.
● 2018년 OpenAI는 당시 최대 규모의 언어 모델 중 하나였던 Transformer 알고리즘을 기반으로 GPT(Generative Pre-trained Transformer)를 출시했습니다.
● 2018년 구글팀 딥마인드는 단백질의 구조를 예측할 수 있는 딥러닝 기반의 알파고(AlphaGo)를 출시해 인공지능 분야의 큰 발전의 신호탄으로 평가받고 있다.
● 2019년 OpenAI는 15억 개의 매개변수를 갖춘 모델인 GPT-2를 출시했습니다.
● 2020년 OpenAI가 개발한 GPT-3은 이전 버전인 GPT-2보다 100배 많은 1,750억 개의 매개변수를 보유하고 있으며, 이 모델은 학습에 570GB의 텍스트를 사용하며 다중 NLP(자연어 처리)에 사용할 수 있습니다. 최고 수준의 성과를 달성하기 위한 과제(질문 답변, 번역, 기사 작성)를 수행합니다.
● 2021년 OpenAI는 GPT-4를 출시했습니다. 이 모델에는 GPT-3의 10배인 1조 7600억 개의 매개변수가 있습니다.
● GPT-4 모델을 기반으로 한 ChatGPT 애플리케이션은 2023년 1월에 출시되었습니다. 3월에는 ChatGPT가 사용자 1억 명을 달성하여 역사상 가장 빠르게 사용자 1억 명을 달성한 애플리케이션이 되었습니다.
● 2024년 OpenAI는 GPT-4 옴니를 출시합니다.
딥 러닝 산업 체인
현재 대형 모델 언어는 신경망 기반의 딥러닝 방법을 사용하고 있습니다. GPT가 주도하는 대형 모델은 인공 지능 열풍을 불러일으켰습니다. 또한 이 트랙에 많은 플레이어가 쏟아져 들어왔습니다. 따라서 보고서의 이 부분에서 우리는 데이터 및 컴퓨팅 성능에 대한 시장 수요가 폭발적으로 증가했다는 사실을 발견했습니다. 주로 학습 알고리즘의 산업 체인, 딥 러닝 알고리즘이 지배하는 AI 산업에서 업스트림 및 다운스트림 구성 요소가 어떻게 구성되어 있는지, 업스트림의 현재 상태, 공급 및 수요 관계 및 향후 개발은 무엇인지 탐구합니다. 그리고 하류.

GPT 훈련 파이프라인 출처: WaytoAI
우선 Transformer 기술 기반 GPT 기반 LLM(대형 모델)을 훈련할 때 세 단계가 있다는 점을 분명히 해야 합니다.
학습 전에 Transformer를 기반으로 하기 때문에 변환기는 텍스트 입력을 숫자 값으로 변환해야 하며, 이 프로세스를 토큰화라고 하며, 이러한 숫자 값을 토큰이라고 합니다. 일반적으로 영어 단어나 문자 하나는 대략 하나의 토큰으로 간주되고, 한자 하나는 대략 두 개의 토큰으로 간주됩니다. 이는 GPT 가격 책정에 사용되는 기본 단위이기도 합니다.
첫 번째 단계는 사전 훈련입니다. 보고서의 첫 번째 부분에 있는 (X, Y) 예제와 유사하게 입력 레이어에 충분한 데이터 쌍을 제공함으로써 모델 아래에 있는 각 뉴런의 최적 매개변수를 찾을 수 있습니다. 이를 위해서는 많은 양의 데이터가 필요하며 이 프로세스는 다음과 같습니다. 또한 다양한 매개변수를 시도하기 위해 뉴런을 반복적으로 반복해야 하기 때문에 계산 집약적인 프로세스이기도 합니다. 데이터 배치가 훈련된 후에는 일반적으로 매개변수를 반복하기 위한 보조 훈련에 동일한 데이터 배치가 사용됩니다.
두 번째 단계는 미세 조정입니다. Fine-tuning은 학습을 위해 매우 높은 품질의 작은 데이터 배치를 제공하는 것입니다. 사전 학습에는 많은 양의 데이터가 필요하지만 많은 데이터에 오류가 포함될 수 있으므로 이러한 변경으로 인해 모델의 출력 품질이 높아집니다. 또는 품질이 낮습니다. 미세 조정 단계는 좋은 데이터로 모델의 품질을 향상시킬 수 있습니다.
세 번째 단계는 학습을 강화하는 것입니다. 먼저, 우리가 보상 모델이라고 부르는 새로운 모델이 구축될 것입니다. 이 모델의 목적은 매우 간단합니다. 이는 출력 결과를 정렬하는 것입니다. 따라서 비즈니스 측면에서 이 모델을 구현하는 것이 상대적으로 간단합니다. 시나리오는 상대적으로 수직적입니다. 그런 다음 이 모델을 사용하여 대형 모델의 출력 품질이 높은지 여부를 결정하므로 보상 모델을 사용하여 대형 모델의 매개변수를 자동으로 반복할 수 있습니다. (그러나 때로는 모델의 출력 품질을 판단하기 위해 인간의 참여가 필요할 수도 있습니다)
즉, 대형 모델의 학습 과정에서 사전 학습은 데이터 양에 대한 요구 사항이 매우 높고 GPU 컴퓨팅 성능을 가장 많이 소비하는 반면, 미세 조정에는 매개 변수를 개선하고 학습을 강화하기 위해 더 높은 품질의 데이터가 필요합니다. 보상 모델을 통해 더 높은 품질의 결과를 출력합니다.
훈련 과정에서 매개변수가 많을수록 일반화 능력의 상한선이 높아집니다. 예를 들어 함수의 예에서는 Y = aX + b가 실제로 두 개의 뉴런 X와 X 0이 있으므로 매개변수는 어떻게 변하든 그 본질이 여전히 직선이기 때문에 맞출 수 있는 데이터는 극히 제한적입니다. 뉴런이 많으면 더 많은 매개변수를 반복할 수 있고, 더 많은 데이터를 맞출 수 있습니다. 이것이 대형 모델이 놀라운 효과를 발휘하는 이유이며, 대중적인 이름이 대형 모델인 이유이기도 합니다. 데이터에는 엄청난 양의 컴퓨팅 성능이 필요합니다.
따라서 대형 모델의 성능은 주로 매개변수 수, 데이터의 양과 품질, 컴퓨팅 성능이라는 세 가지 측면에 의해 결정됩니다. 이 세 가지는 대형 모델의 결과 품질과 일반화 능력에 공동으로 영향을 미칩니다. 매개변수의 개수를 p개, 데이터의 양을 n개(토큰 개수를 기준으로 계산)라고 가정하면, 일반적인 경험 법칙을 통해 필요한 계산량을 계산하여 대략적인 컴퓨팅 파워를 추정할 수 있습니다. 우리는 구매와 훈련 시간이 필요합니다.
컴퓨팅 성능은 일반적으로 부동 소수점 연산을 나타내는 기본 단위인 Flop을 기반으로 합니다. 부동 소수점 연산은 2.5+ 3.557과 같은 정수가 아닌 값의 덧셈, 뺄셈, 곱셈 및 나눗셈을 의미합니다. 소수점을 가질 수 있으며 FP 16은 소수점을 지원함을 의미하며 일반적으로 FP 32가 더 일반적인 정밀도입니다. 실제로 경험에 따르면 대규모 모델을 사전 훈련(보통 여러 번)하려면 약 6np 플롭이 필요하며 6을 업계 상수라고 합니다. 추론(Inference, 데이터를 입력하고 대형 모델의 출력을 기다리는 과정)은 n개의 토큰을 입력하고 n개의 토큰을 출력하는 두 부분으로 나누어져 총 약 2np의 Flop이 필요합니다.
초기에는 컴퓨팅 파워 지원을 제공하기 위한 훈련용으로 CPU 칩이 사용됐지만, 이후 점차 엔비디아의 A 100, H 100 칩 등 GPU로 대체되기 시작했다. CPU는 범용 컴퓨팅으로 존재하지만, GPU는 전용 컴퓨팅으로 사용할 수 있어 에너지 소비 효율성이 CPU를 훨씬 뛰어넘는다. GPU는 주로 Tensor Core라는 모듈을 통해 부동 소수점 연산을 실행합니다. 따라서 일반 칩은 FP 16 / FP 32 정밀도의 Flops 데이터를 가지고 있으며 이는 주요 컴퓨팅 성능을 나타내며 칩의 주요 측정 지표 중 하나이기도 합니다.
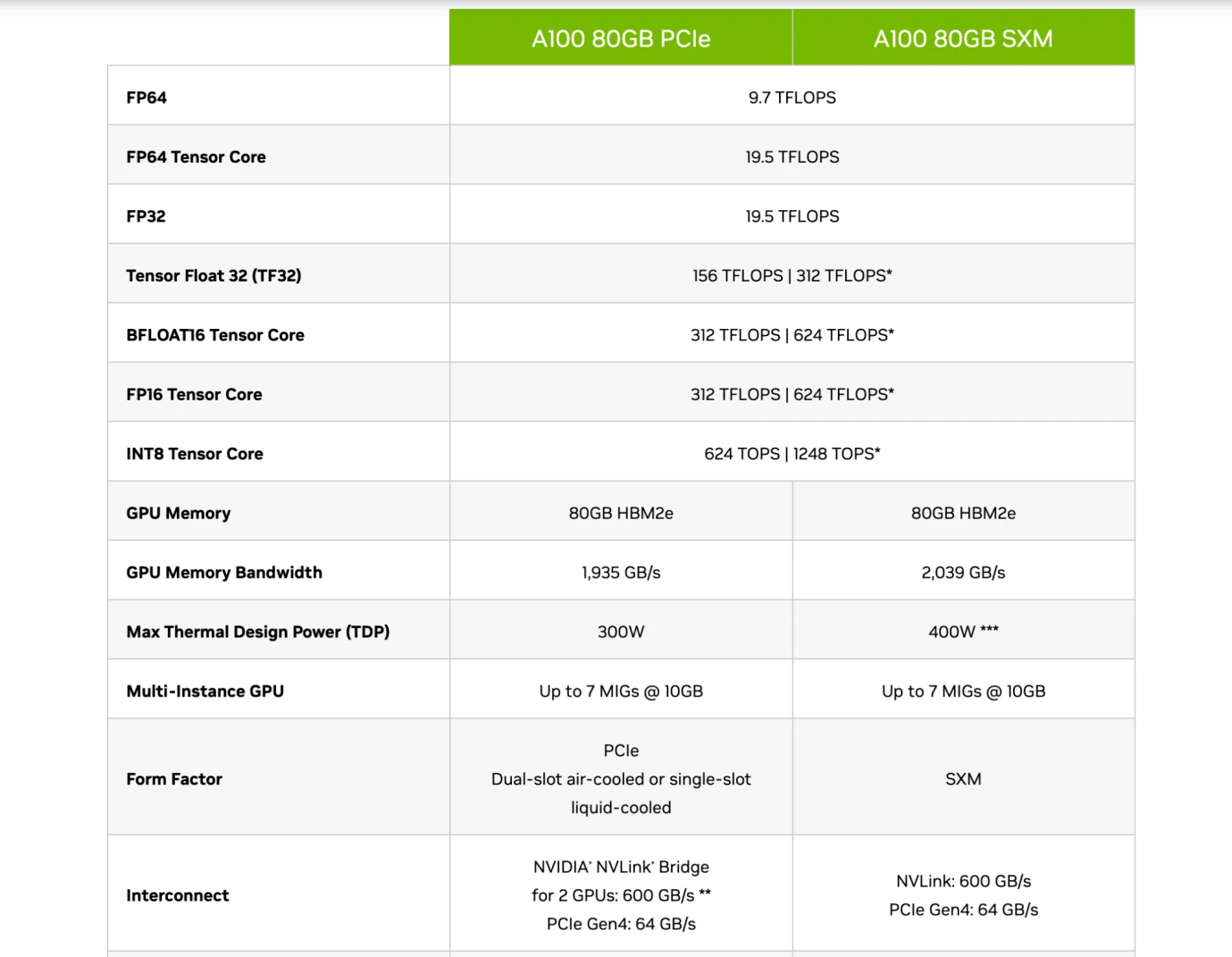
Nvidia A 100 칩 사양, 출처: Nvidia
따라서 독자들은 이들 기업의 칩 도입을 이해할 수 있어야 한다. 위 그림에서 볼 수 있듯이 Nvidia의 A 100 80GB PCIe와 SXM 모델을 비교하면 PCIe와 SXM이 Tensor Core(a) 하에 있음을 알 수 있다. AI 컴퓨팅 전용 모듈) FP 16 정밀도에서는 각각 312 TFLOPS 및 624 TFLOPS(Trillion Flops)입니다.
대규모 모델 매개변수가 1,750억 개의 매개변수와 1,800억 개의 토큰(약 570GB)의 데이터 볼륨을 갖춘 GPT 3을 예로 든다고 가정하면 사전 훈련 중에 6np 플롭이 필요하며 이는 약 3.15 * 1022입니다. 플롭을 TFLOPS(조 FLOP) 단위로 측정하면 약 3.15* 1010 TFLOPS입니다. 즉, SXM 모델 칩이 GPT 3을 한 번 사전 훈련하는 데 약 50480769초, 841346분, 14022시간, 584일이 소요됩니다.
이는 사전 훈련을 수행하기 위해 여러 개의 최첨단 칩이 필요한 계산량임을 알 수 있습니다. 게다가 GPT 4의 매개변수 양은 GPT 3(1조 7600억)의 10배에 달합니다. 즉, 데이터 수량이 변하지 않더라도 칩 수를 10배 더 구입해야 하며, GPT-4의 토큰 수는 결국 GPT-3의 10배인 13조 개가 됩니다. , GPT-4에는 100배 이상의 컴퓨팅 성능이 필요할 수 있습니다.
대규모 모델 훈련에서는 GPT 3 토큰 수와 같은 데이터가 1,800억 개로 약 570GB의 저장 공간을 차지하고, 1,750억 개의 매개변수를 가진 대규모 모델 신경망이 약 700GB를 차지하기 때문에 데이터 저장에 문제가 있습니다. 저장 공간. GPU의 메모리 공간은 일반적으로 작으므로(위 그림과 같이 A100은 80GB) 메모리 공간이 데이터를 수용할 수 없는 경우 칩의 대역폭, 즉 전송 속도를 검토해야 합니다. 하드디스크에서 메모리까지의 데이터 속도. 동시에, 우리는 하나의 칩만 사용하지 않을 것이기 때문에 공동 학습 방법을 사용하여 칩 간 GPU 전송 속도를 포함하는 여러 GPU 칩에서 대규모 모델을 공동으로 훈련해야 합니다. 따라서 많은 경우 최종 모델 훈련 실행을 제한하는 요소나 비용은 반드시 칩의 컴퓨팅 성능이 아니라 칩의 대역폭인 경우가 더 많습니다. 데이터 전송 속도가 느리기 때문에 모델을 실행하는 데 시간이 더 오래 걸리고 전력 비용도 증가합니다.

H 100 SXM 칩 사양, 출처: Nvidia
이때 독자는 FP 16이 정확도를 나타내는 칩의 사양을 대략적으로 완전히 이해할 수 있습니다. Tensor Core 구성 요소는 주로 AI LLM을 교육하는 데 사용되므로 이 구성 요소의 컴퓨팅 성능만 보면 됩니다. FP 64 Tensor Core는 64 정밀도로 초당 67 TFLOPS를 처리할 수 있는 H 100 SXM을 나타냅니다. GPU 메모리는 칩의 메모리가 64GB에 불과하여 대형 모델의 데이터 저장 요구 사항을 완전히 충족할 수 없음을 의미합니다. 따라서 GPU 메모리 대역폭은 데이터 전송 속도가 3.35TB/s임을 의미합니다.
AI 가치 사슬, 출처: Nasdaq
우리는 데이터 및 뉴런 매개변수 수의 확장으로 인해 컴퓨팅 성능 및 스토리지 요구 사항에 큰 격차가 발생했음을 확인했습니다. 이 세 가지 주요 요소는 전체 산업 체인을 배양했습니다. 위의 그림을 사용하여 산업 체인의 각 부분의 역할과 기능을 소개하겠습니다.
하드웨어 GPU 제공업체
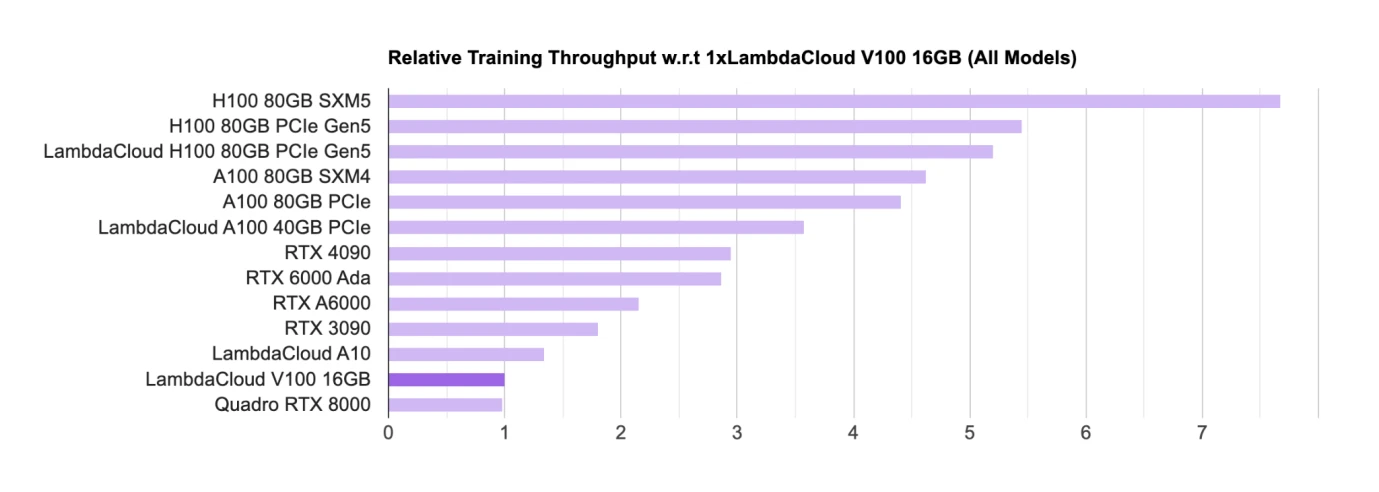
AI GPU 칩 순위, 출처: Lambda
GPU와 같은 하드웨어는 현재 훈련과 추론을 위한 주요 칩이다. GPU 칩의 주요 설계자는 현재 학계(주로 대학 및 연구 기관)가 소비자 수준의 GPU(RTX, Main)를 주로 사용하고 있다. 게이밍 GPU), 업계에서는 대형 모델의 상용화를 위해 주로 H 100, A 100 등을 사용합니다.
목록에서는 Nvidia의 칩이 거의 대부분을 차지하고 있으며 모든 칩은 Nvidia의 칩입니다. Google도 TPU라는 자체 AI 칩을 보유하고 있지만 TPU는 주로 Google Cloud에서 B측 기업에 컴퓨팅 성능 지원을 제공하는 데 사용됩니다. 일반적으로 자체 구매 기업은 여전히 Nvidia GPU를 구매하는 경향이 있습니다.
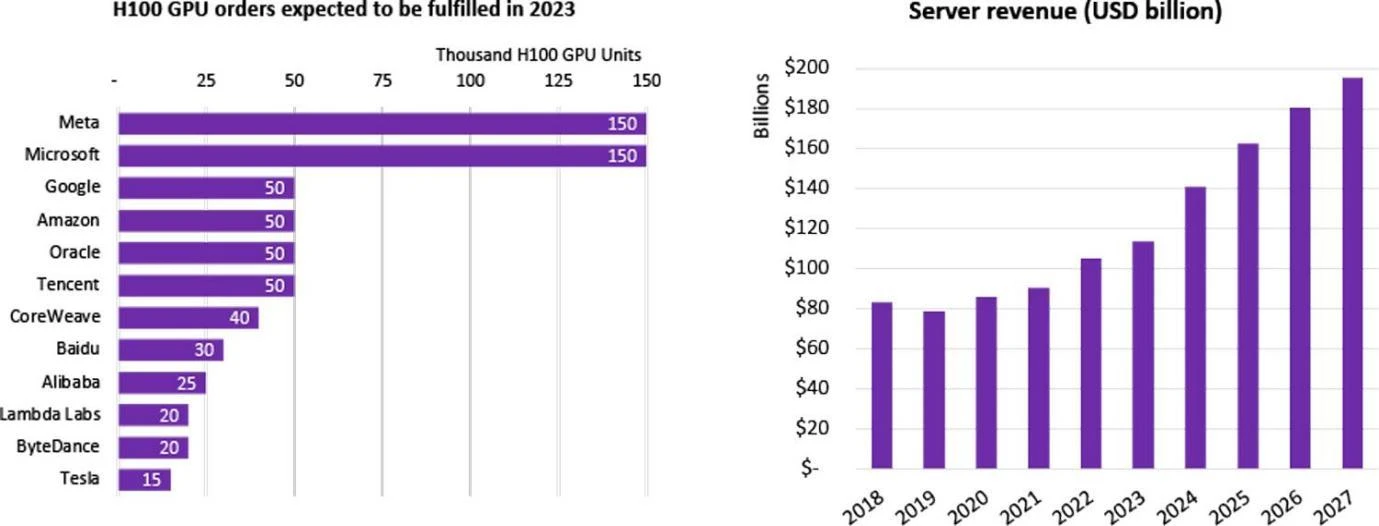
회사별 H 100 GPU 구매 통계, 출처: Omdia
중국에서는 100개 이상의 대형 모델을 포함하여 수많은 기업이 LLM 연구 개발에 착수했으며, 전 세계적으로 총 200개 이상의 대형 언어 모델이 출시되었습니다. 이 AI 붐에는 많은 인터넷 거대 기업이 참여하고 있습니다. 이들 기업은 대형 모델을 직접 구매하거나 클라우드 업체를 통해 임대하기도 한다. 2023년, 엔비디아의 가장 발전된 칩인 H 100은 출시되자마자 많은 기업에서 구독을 하게 되었습니다. H 100 칩에 대한 전 세계 수요는 공급을 훨씬 초과합니다. 현재 Nvidia만이 최고급 칩을 공급하고 있고 배송 주기가 놀랍게도 52주에 달했기 때문입니다.
엔비디아의 독점을 염두에 두고 인공지능 분야의 절대 강자 중 하나인 구글이 주도권을 잡았다. 인텔, 퀄컴, 마이크로소프트, 아마존이 공동으로 CUDA 얼라이언스를 설립해 엔비디아의 절대적인 영향력을 없애기 위해 GPU를 공동으로 개발하겠다는 뜻이었다. 딥 러닝 산업 체인.
대규모 기술 회사/클라우드 서비스 제공업체/국립 연구소의 경우 HPC(고성능 컴퓨팅 센터)를 구축하기 위해 수천 또는 수만 개의 H 100 칩을 구매하는 경우가 많습니다. 예를 들어 Tesla의 CoreWeave 클러스터는 H 100 80GB 1만 개를 구매합니다. 평균 구매 가격은 44,000달러(Nvidia 비용은 약 1/10)이며 총 비용은 4억 4천만 달러입니다. Tencent는 50,000개를 구매했으며 Meta는 2023년 말까지 유일한 고성능 제품으로 구매했습니다. GPU 판매자인 Nvidia는 500,000개 이상의 H 100 칩을 주문했습니다.
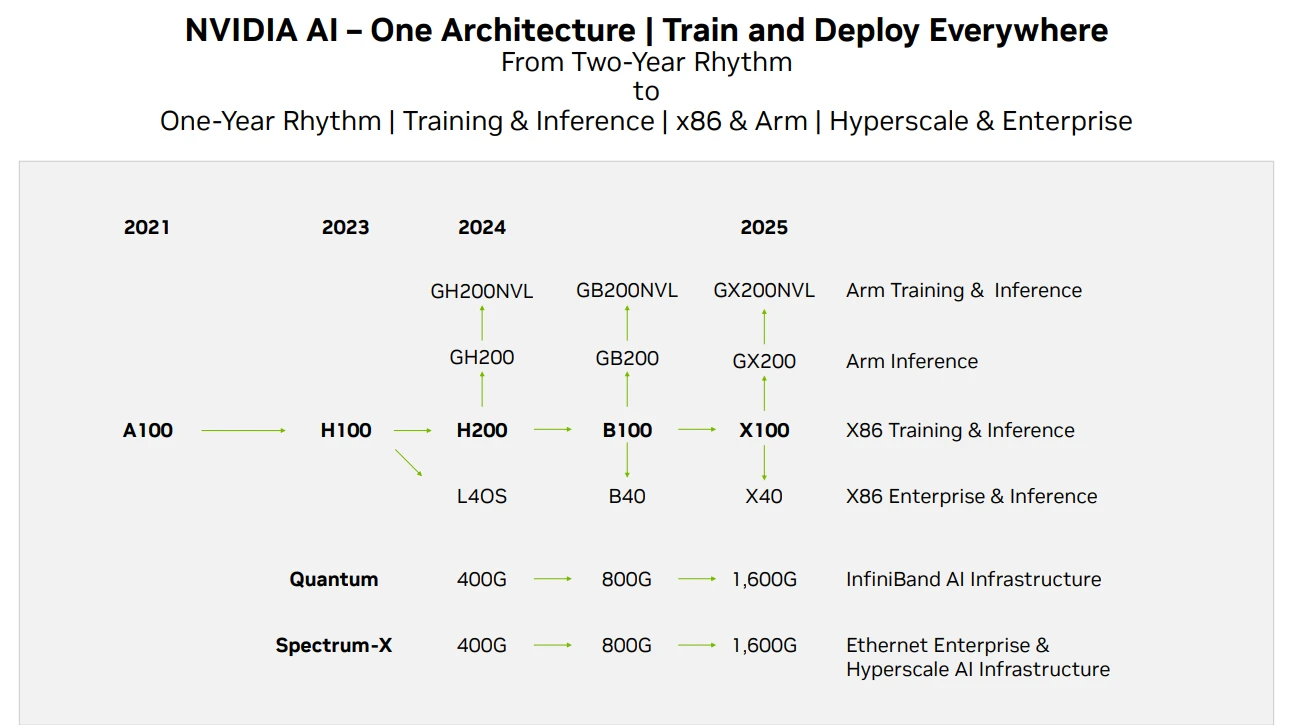
Nvidia GPU 제품 로드맵, 출처: Techwire
Nvidia의 칩 공급 측면에서는 위의 내용이 제품 반복 로드맵입니다. 이번 보고서를 기준으로 H 200의 성능이 H 100의 2배인 반면 B는 성능이 향상될 것으로 예상됩니다. 100은 2024년 말이나 2025년 초에 출시될 예정입니다. 현재 GPU의 개발은 2년마다 성능이 두 배로 증가하고 가격이 절반으로 떨어지는 무어의 법칙을 여전히 충족합니다.
클라우드 서비스 제공업체

GPU 클라우드 유형, 출처: Salesforce Ventures
클라우드 서비스 제공업체는 HPC를 설정하는 데 충분한 GPU를 구매한 후 제한된 자금으로 인공지능 기업에 탄력적인 컴퓨팅 성능과 관리형 교육 솔루션을 제공할 수 있습니다. 위 그림에서 볼 수 있듯이 현재 시장은 크게 3가지 유형의 클라우드 컴퓨팅 파워 제공업체로 구분됩니다. 첫 번째 유형은 전통적인 클라우드 벤더들로 대표되는 클라우드 컴퓨팅 파워 플랫폼(AWS, Google, Azure)의 초대형 확장입니다. . 두 번째 범주는 주로 AI 또는 고성능 컴퓨팅을 위해 설계된 수직형 클라우드 컴퓨팅 플랫폼으로, 보다 전문적인 서비스를 제공하므로 이러한 유형의 신흥 수직형 산업 클라우드 서비스 회사와 경쟁할 수 있는 시장 공간이 여전히 존재합니다. CoreWeave(시리즈 C 파이낸싱에서 11달러, 가치 190억 달러 상당), Crusoe, Lambda(시리즈 C 파이낸싱에서 2억 6천만 달러, 가치 15억 달러 이상) 등이 있습니다. 세 번째 유형의 클라우드 서비스 공급자는 주로 서비스형 추론 공급자인 새로운 시장 참가자입니다. 이러한 서비스 공급자는 주로 고객을 위해 사전 훈련된 모델을 배포하고 이를 기반으로 구축합니다. 미세 조정이나 추론을 통해 이런 시장의 대표적인 기업으로는 Together.ai(최신 가치 12억 5천만 달러), Fireworks.ai(벤치마크 주도 투자, Series A 파이낸싱 2,500만 달러) 등이 있습니다.
훈련 데이터 소스 제공자
Part 2에서 앞서 언급했듯이 대규모 모델 훈련은 주로 사전 훈련, 미세 조정, 강화 학습의 세 단계를 거칩니다. Pre-training에는 많은 양의 데이터가 필요하고, Fine-tuning에는 고품질의 데이터가 필요하므로 Google(데이터 양이 많음), Reddit(질이 좋은 답변 데이터가 있음) 등의 데이터 회사에서 널리 받아왔습니다. 시장의 관심.
GPT와 같은 범용 대형 모델과 경쟁하지 않기 위해 일부 개발자는 세분화된 분야에서 개발을 선택합니다. 따라서 데이터에 대한 요구 사항은 금융, 의료, 화학, 물리학 등 산업별로 특화되어야 합니다. 생물학 등 이미지 인식 등 특정 분야에 대한 모델이고 특정 분야의 데이터가 필요하기 때문에 이러한 대규모 모델에 대한 데이터를 제공하는 회사가 있습니다. 데이터를 수집한 후 레이블을 지정하여 더 나은 품질과 구체적인 제공을 의미하는 데이터 레이블링 회사라고도 합니다. 데이터 유형.
모델을 개발하는 기업의 경우 대용량 데이터, 고품질 데이터, 특정 데이터가 세 가지 주요 데이터 요구 사항입니다.
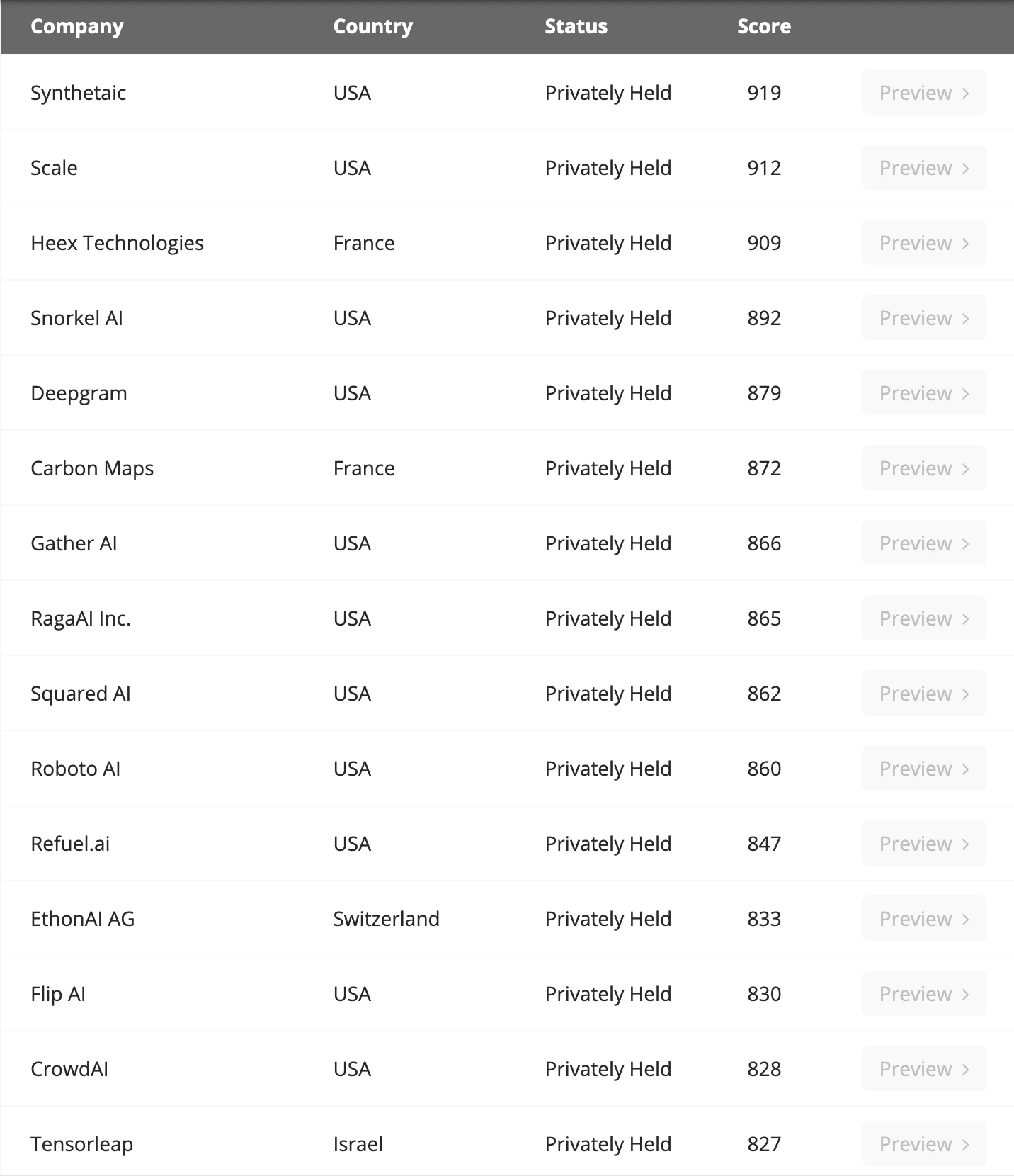
주요 데이터 라벨링 회사, 출처: Venture Radar
Microsoft의 연구에 따르면 SLM(소규모 언어 모델)의 경우 데이터 품질이 대규모 언어 모델보다 훨씬 뛰어나더라도 성능이 반드시 LLM보다 나쁘지는 않을 것입니다. 실제로 GPT는 독창성과 데이터 측면에서 뚜렷한 이점이 없습니다. 주로 이러한 방향으로 베팅하는 대담함이 성공에 기여합니다. Sequoia America도 현재 이 분야에 깊은 해자가 없기 때문에 GPT가 미래에 반드시 경쟁 우위를 유지하지 못할 수도 있고, 주된 한계는 컴퓨팅 파워 확보의 한계에서 비롯된다는 점을 인정했습니다.
데이터 양에 관해서는 EpochAI의 예측에 따르면 현재 모델 규모의 성장에 따라 2030년에는 저품질 데이터와 고품질 데이터가 모두 고갈될 것이라고 합니다. 따라서 업계에서는 현재 무제한의 데이터 생성이 가능하도록 인공지능 합성 데이터를 탐색하고 있는데, 병목 현상은 컴퓨팅 능력뿐이다. 이 방향은 아직 탐색 단계에 있어 개발자들의 관심을 받을 만하다.
데이터베이스 제공자
우리는 데이터를 가지고 있지만 데이터의 추가, 삭제, 수정 및 검색을 용이하게 하기 위해 일반적으로 데이터베이스에 데이터를 저장해야 합니다. 전통적인 인터넷 비즈니스에서는 MySQL에 대해 들어봤을 것이고, Ethereum 클라이언트 Reth에서는 Redis에 대해 들어본 적이 있을 것입니다. 이는 비즈니스 데이터나 데이터를 블록체인에 저장하는 로컬 데이터베이스입니다. 다양한 데이터 유형이나 비즈니스에 맞게 다양한 데이터베이스 적응이 있습니다.
AI 데이터와 딥러닝 훈련 추론 작업을 위해 현재 업계에서 사용되는 데이터베이스를 벡터 데이터베이스라고 부른다. 벡터 데이터베이스는 대량의 고차원 벡터 데이터를 효율적으로 저장, 관리 및 색인화하도록 설계되었습니다. 우리의 데이터는 단순한 숫자 값이나 텍스트가 아니라 그림, 소리 등의 대규모 비정형 데이터이기 때문에 벡터 데이터베이스는 이러한 비정형 데이터를 벡터 형태로 저장할 수 있으며, 이러한 벡터 저장 및 처리에는 벡터 데이터베이스가 적합합니다.

벡터 데이터베이스 분류, 출처: Yingjun Wu
현재 주요 플레이어로는 Chroma(1,800만 달러 펀딩 지원), Zilliz(최근 펀딩 6,000만 달러), Pinecone, Weaviate 등이 있습니다. 데이터 볼륨에 대한 수요가 증가하고 다양한 틈새 분야에서 대형 모델 및 애플리케이션이 폭발적으로 증가함에 따라 벡터 데이터베이스에 대한 수요가 크게 증가할 것으로 예상됩니다. 그리고 이 분야는 기술적 장벽이 강하기 때문에 성숙하고 고객이 있는 기업에 투자할 때 더 많은 배려를 하게 될 것입니다.
엣지 디바이스
GPU HPC(고성능 컴퓨팅 클러스터)를 구축할 때 일반적으로 많은 양의 에너지가 소비되어 많은 양의 열 에너지가 발생합니다. 고온 환경에서는 칩이 온도를 낮추기 위해 작동 속도를 제한합니다. 이는 우리가 일반적으로 주파수 감소라고 부르는 것으로, HPC의 지속적인 작동을 보장하기 위해 일부 냉각 엣지 장치가 필요합니다.
따라서 여기에는 산업 체인의 두 가지 방향, 즉 에너지 공급(일반적으로 전기 에너지 사용)과 냉각 시스템이 관련됩니다.
현재 에너지 공급 측면에서는 전기가 주로 사용되며, 데이터 센터와 지원 네트워크는 현재 전 세계 전력 소비의 2~3%를 차지합니다. BCG는 대규모 딥러닝 모델의 매개변수가 증가하고 칩이 반복됨에 따라 2030년까지 대형 모델을 훈련하는 데 필요한 전력이 3배가 될 것으로 예측합니다. 현재 국내외 기술제조업체들은 에너지 기업에 적극적으로 투자하고 있다. 주요 에너지 투자 방향으로는 지열에너지, 수소에너지, 배터리저장, 원자력에너지 등이 있다.
HPC 클러스터 냉각 측면에서는 현재 공랭 방식이 주요 방식이지만, HPC의 원활한 운영을 유지하기 위해 많은 VC들이 액체 냉각 시스템에 집중적으로 투자하고 있다. 예를 들어 Jetcool은 자사의 액체 냉각 시스템이 H 100 클러스터의 총 전력 소비를 15%까지 줄일 수 있다고 주장합니다. 현재 액체 냉각은 주로 콜드 형식 액체 냉각, 침지 액체 냉각, 스프레이 액체 냉각의 세 가지 탐색 방향으로 나뉩니다. 이 분야의 회사로는 Huawei, Green Revolution Cooling, SGI 등이 있습니다.
애플리케이션
현재 AI 애플리케이션의 발전은 블록체인 산업의 발전과 유사하다. 혁신적인 산업으로 Transformer가 2017년에 제안되었고, OpenAI는 2023년에야 대형 모델의 유효성을 확인했다. 따라서 이제 많은 Fomo 회사가 대형 모델의 RD 트랙에 붐비고 있습니다. 즉, 인프라는 매우 붐비지만 애플리케이션 개발은 따라가지 못하고 있습니다.

월간 활성 사용자 상위 50명, 출처: A16Z
현재, 처음 10개월 동안 활성화된 AI 애플리케이션의 대부분은 검색형 애플리케이션입니다. 실제 등장한 AI 애플리케이션은 여전히 매우 제한적이며, 소셜 및 기타 유형의 애플리케이션은 없습니다. 성공적으로 등장했습니다.
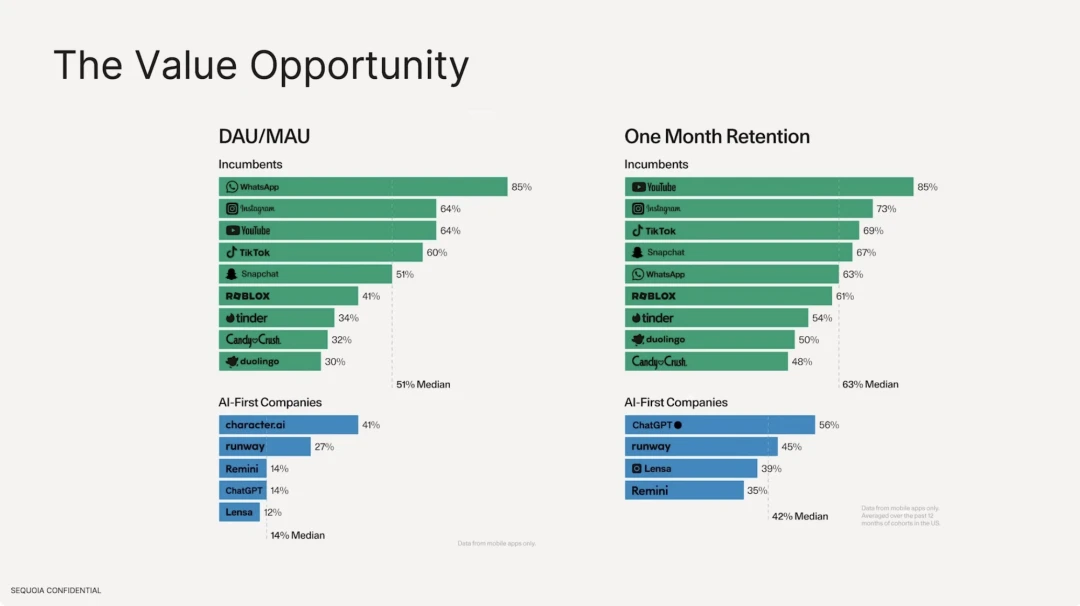
또한 대형 모델을 기반으로 한 AI 애플리케이션의 유지율은 기존의 전통적인 인터넷 애플리케이션에 비해 훨씬 낮은 것으로 나타났습니다. 활성 사용자 수 측면에서 기존 인터넷 소프트웨어의 중앙값은 51%이며, 가장 높은 것은 사용자 밀착성이 강한 Whatsapp입니다. 하지만 AI 애플리케이션 측면에서 DAU/MAU가 가장 높은 것은 Character.ai로 41%에 불과하며, DAU는 전체 사용자 수의 중앙값 14%를 차지한다. 사용자 유지율 측면에서 최고의 기존 인터넷 소프트웨어는 Youtube, Instagram 및 Tiktok입니다. 상위 10위권의 중간 유지율은 63%이며, ChatGPT의 유지율은 56%에 불과합니다.

AI 애플리케이션 환경, 출처: Sequoia
Sequoia America의 보고서에 따르면 역할 중심 관점에서 애플리케이션을 전문 소비자, 기업 및 일반 소비자의 세 가지 범주로 나눕니다.
1. 소비자 지향: 일반적으로 QA를 위해 GPT를 사용하는 텍스트 작업자, 자동화된 3D 렌더링 모델링, 소프트웨어 편집, 자동화 에이전트, 음성 대화, 교제, 언어 연습 등을 위한 음성 유형 애플리케이션 등 생산성 향상을 위해 사용됩니다.
2. 기업의 경우: 일반적으로 마케팅, 법률, 의료 디자인 및 기타 산업.
지금은 많은 사람들이 인프라가 애플리케이션보다 훨씬 크다고 비판하지만, 실제로 우리는 현대 세계가 인공지능 기술로 인해 광범위하게 재편되었다고 믿고 있지만, ByteDance Music의 TikTok, Toutiao, Soda 등을 포함한 추천 시스템을 사용합니다. Xiaohongshu 및 WeChat 비디오 계정, 광고 추천 기술 등은 모두 개인을 위한 맞춤형 추천이며 모두 기계 학습 알고리즘입니다. 따라서 현재 호황을 누리고 있는 딥러닝은 AI 산업을 완전히 대표하지 못하며, 일반 인공지능을 실현할 수 있는 기회를 갖고 병행적으로 발전하고 있는 잠재력 있는 기술이 많이 있으며, 이러한 기술 중 일부는 다양한 산업에서 널리 사용되고 있습니다. .
그렇다면 Crypto x AI 사이에는 어떤 관계가 전개되나요? 암호화폐 산업 가치 사슬에서 주목할만한 다른 프로젝트는 무엇입니까? Gate Ventures: AI x Crypto 초보부터 마스터까지(2부)에서 하나씩 설명하겠습니다.
부인 성명:
위 내용은 참고용일 뿐이며 조언으로 간주되어서는 안 됩니다. 투자하기 전에 항상 전문가의 조언을 구하십시오.
게이트벤처스 소개
Gate Ventures 는 Gate.io의 벤처 캐피털 계열사로 웹 3.0 시대에 세상을 재편할 분산형 인프라, 생태계 및 애플리케이션에 대한 투자에 중점을 두고 있습니다. Gate Ventures는 글로벌 업계 리더들과 협력하여 혁신적인 사고와 역량을 갖춘 팀과 스타트업에 힘을 실어 사회와 금융의 상호 작용 모델을 재정의합니다.
공식 홈페이지: https://ventures.gate.io/





